동적 학습을 위한 신경형태 최적화 곤충 뇌에서 영감을 얻다
본 논문은 곤충의 머쉬룸 바디 구조를 모방한 신경형태 아키텍처에 메타‑학습 규칙을 통합하고, DeepHyper 기반 비동기 모델 기반 탐색으로 학습 규칙과 하이퍼파라미터를 공동 최적화한다. MNIST와 FashionMNIST 두 데이터셋에서 최적 규칙이 데이터셋마다 다름을 확인해, 작업‑특화 메타‑학습 규칙의 필요성을 입증한다.
저자: S, eep Madireddy, Angel Yanguas-Gil
본 연구는 실시간 적응 학습이 가능한 신경형태(Neuromorphic) 시스템을 설계·최적화하기 위한 새로운 프레임워크를 제시한다. 인간·동물의 뇌가 환경 변화에 빠르게 대응하는 메커니즘을 모방하고자, 저자들은 곤충의 머쉬룸 바디(MB) 회로를 기반으로 한 네트워크 구조를 설계하였다. MB는 안테날 로브에서 케니온 세포(Kenyon cells)로 입력을 희소하게 전파하고, 이후 출력 뉴런(MBON)으로 밀집 연결되는 3~4단계의 계층을 갖는다. 이 구조는 입력 차원을 고차원으로 확장하면서도, 학습이 주로 마지막 단계에서 일어나도록 설계되어 있다.
논문은 학습 규칙 자체를 네트워크의 일부분으로 취급한다. 시냅스 가중치 W는 별도의 레이어로 구현되며, 전시냅스 활동 x_e, 후시냅스 활동 x_o, 그리고 조절 입력 x_m(예: 강화 신호 또는 외부 컨텍스트)으로부터 업데이트된다. 일반화된 업데이트 식은 ∂W = f(x_e, x_o, x_m, W; β) 로 표현되며, 여기서 β는 규칙별 하이퍼파라미터를 의미한다. 이러한 접근은 기존의 “학습‑추론 분리” 방식을 깨고, 네트워크가 자체적으로 구조를 변형하면서 학습을 수행하도록 만든다.
저자들은 8가지 메타‑학습(로컬 학습) 규칙을 정의하였다.
1) Modulated Covariance Rule (MCR) – 조절 입력과 출력 차이에 비례해 가중치를 업데이트.
2) Nonlocal Stabilized Covariance Rule (NSCR) – MCR에 가중치 자체에 대한 안정화 항을 추가.
3) Nonlocal Stabilized Correlation Rule (NSCoR) – 공분산 대신 상관을 이용.
4) Modulated Oja’s Rule (MOR) – Oja 규칙에 조절 신호를 곱함.
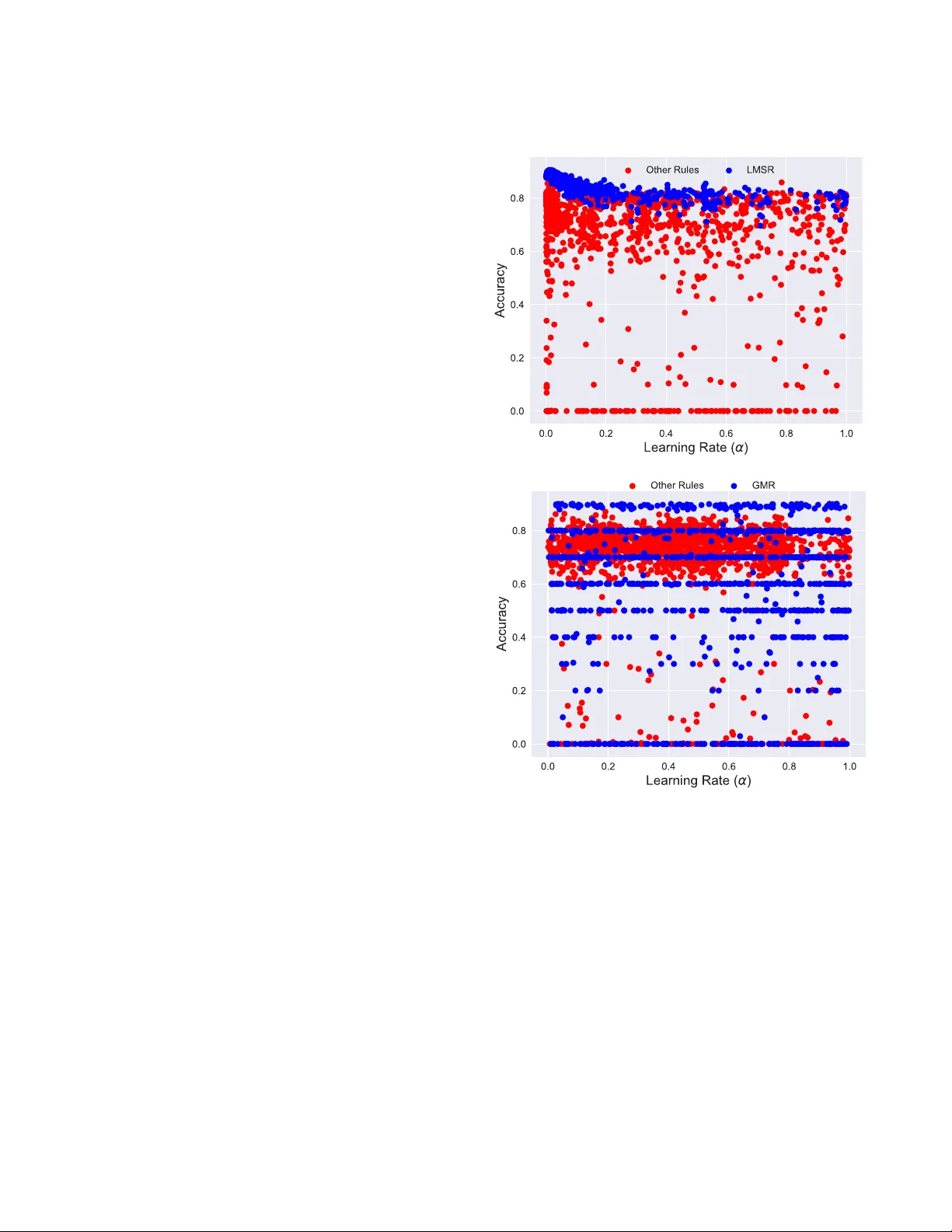
5) Least Mean Square Rule (LMSR) – 전통적인 최소제곱 기반 업데이트.
6) Self‑Limited Rule (SLR) – 가중치를 사전 정의된 범위 내에서 제한.
7) General Modulated Rule (GMR) – 조절 입력에 따라 학습률을 동적으로 조정.
8) General Unsupervised Rule (GUR) – 완전 비감독 방식.
각 규칙은 학습률 α와 β₁, β₂, β₃와 같은 연속 파라미터를 포함한다. 규칙마다 필요한 파라미터가 다를 수 있지만, 탐색 알고리즘은 이를 일관되게 처리한다.
이러한 복합 최적화 문제를 해결하기 위해 논문은 DeepHyper의 비동기 모델 기반 탐색(AMBS) 프레임워크를 활용한다. 탐색 공간 Ψ는 규칙 선택(범주형)과 연속 파라미터(α, β₁‑β₃)로 구성된다. 랜덤 포레스트 회귀 모델을 서러게이트로 사용해 현재까지 평가된 구성들의 검증 정확도를 예측하고, 헷지 전략 기반 다중 획득 함수를 통해 탐색‑활용 균형을 동적으로 조정한다. 이 과정은 Theta 슈퍼컴퓨터(11.69 PFLOPS)에서 수천 개의 구성 평가를 병렬로 수행하도록 설계되었다.
실험은 두 개의 표준 이미지 분류 데이터셋, MNIST와 FashionMNIST를 대상으로 진행되었다. 네트워크는 입력‑숨김‑조절‑출력의 4계층 RNN 구조이며, 플라스틱한 가중치는 숨김‑출력 연결에만 적용된다. 탐색 결과, MNIST에서는 LMSR이 0.903의 테스트 정확도를 달성했으며, FashionMNIST에서는 GMR이 0.900의 정확도를 기록했다. 이는 데이터셋의 특성(단순 손글씨 vs. 복잡한 패션 아이템)에 따라 최적의 학습 메커니즘이 달라짐을 보여준다. 또한, 각 규칙별 파라미터 민감도 분석을 통해 α와 β₁‑β₃가 학습 수렴 속도와 일반화 성능에 미치는 영향을 정량화하였다.
논문은 몇 가지 제한점을 인정한다. 현재 실험은 비교적 얕은 RNN 구조에 국한되어 있어, 더 깊은 계층이나 스파이킹 뉴런 기반 구현에 대한 일반화 가능성은 아직 검증되지 않았다. 조절 입력 x_m을 외부 레이블이나 강화 신호로 단순히 제공했으나, 실제 로봇 시스템에서 자율적으로 생성되는 조절 신호와의 통합은 추가 연구가 필요하다. 또한, 랜덤 포레스트 서러게이트가 고차원 연속 파라미터가 늘어날 경우 탐색 효율이 저하될 가능성이 있다.
결론적으로, 이 연구는 메타‑학습 규칙을 네트워크 내부에 직접 내재화하고, 자동화된 하이퍼파라미터 탐색을 통해 작업‑특화 동적 학습을 구현한다는 새로운 패러다임을 제시한다. 생물학적 영감을 받은 아키텍처와 최신 자동화 탐색 기법의 결합은 엣지 디바이스에서 실시간 적응 학습을 구현하는 데 중요한 전진을 의미한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기