Neuromorphic Architecture Optimization for Task-Specific Dynamic Learning
The ability to learn and adapt in real time is a central feature of biological systems. Neuromorphic architectures demonstrating such versatility can greatly enhance our ability to efficiently process information at the edge. A key challenge, however…
Authors: S, eep Madireddy, Angel Yanguas-Gil
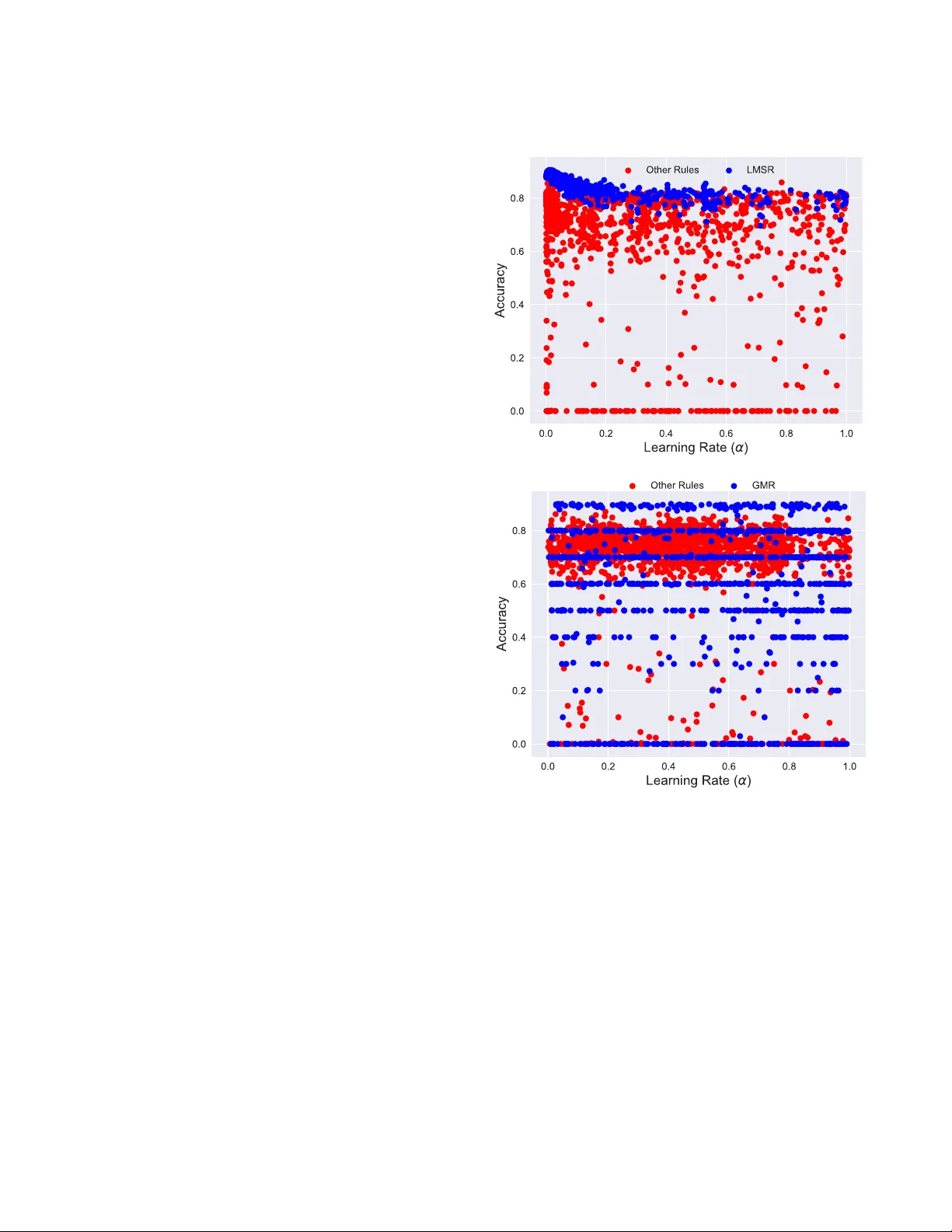
Neuromorphic Architecture Optimization for T ask-Specific Dynamic Learning Sandeep Madireddy smadireddy@mcs.anl.gov Mathematics and Computer Science Division, Argonne National Laboratory Lemont, Illinois Angel Y anguas-Gil ayg@anl.gov Applied Materials Division, Argonne National Laboratory Lemont, Illinois Prasanna Balaprakash pbalapra@mcs.anl.gov Mathematics and Computer Science Division, Argonne National Laboratory Lemont, Illinois Abstract The ability to learn and adapt in real time is a central feature of bi- ological systems. Neuromorphic architectures demonstrating such versatility can greatly enhance our ability to eciently process information at the edge. A key challenge, howev er , is to under- stand which learning rules are best suited for specic tasks and how the relevant hyperparameters can be ne-tuned. In this work, we introduce a conceptual frame work in which the learning pro- cess is integrate d into the network itself. This allows us to cast meta-learning as a mathematical optimization problem. W e employ DeepHyper , a scalable, asynchronous model-base d search, to si- multaneously optimize the choice of meta-learning rules and their hyperparameters. W e demonstrate our approach with two dierent datasets, MNIST and FashionMNIST , using a network architecture inspired by the learning center of the inse ct brain. Our results show that optimal learning rules can be dataset-dependent even within similar tasks. This dependency demonstrates the importance of introducing versatility and exibility in the learning algorithms. It also illuminates experimental ndings in insect neuroscience that have shown a heterogeneity of learning rules within the insect mushroom body . Ke ywords Meta-Learning, Neuromorphic Architecture , Optimization, Dy- namic Learning, Edge Processing 1 Introduction The challenges of designing smart systems for edge-processing applications are dierent from those of conventional machine learn- ing (ML) approaches. Usually , ML approaches r ely on large datasets and highly optimized training algorithms. The resulting architec- tures are specic to certain tasks, and their parameters are tradi- tionally xed once the training is over . In contrast, in edge-based applications, devices in the eld should be capable of learning and responding quickly , often from noisy and incomplete data, and should be capable of adapting to unforeseen changes in a safe, smart way . A promising approach for dynamic learning is to develop sys- tems that are based on biological systems. In particular , biological neural networks are both dynamic and plastic, with the capability to incorporate multiple functionalities depending on the context, and can carry out context and task-dependent learning. Insects in particular are ideal model systems for edge-processing applications: they display impressive capabilities despite their central neural system being composed of a small number of neurons, 100,000 in the case of Drosophila melanogaster and 1,000,000 in the case of the honeybee. Recently , researchers have e xpressed renew ed interest in dynamic learning, but the focus has been on spiking neurons. Several works have explor ed ways in which Hebbian-inspired rules, primarily based on spike-timing-dependent plasticity , can b e used to implement learning in spiking networks [ 4 ]. In a broader sense, howev er , dynamic learning has deep roots in articial neural net- works; and the question of batch size and its impact on a traine d network’s ability to learn and generalize is still an open research question. Here we focus on this problem from a dierent perspective: learn- ing can be viewed as a dynamic process that alters the network itself as it processes and assigns valence to certain inputs and create associations over time. The question then is, How can w e nd the optimum architecture and learning rules for a given task? Evolu- tion has pushed biological systems to nd highly ecient solutions within biochemical constraints. W e seek to develop an analogous approach to help us identify optimal architectures for dynamic neural networks. T o accomplish this goal, we hav e implemented netw orks capable of dynamic learning as recurrent neural networks where plastic synaptic weights are treated as layers of the netw ork. W e parame- terize the learning rules and expose them as hyperparamters. Doing so allows us to approach the problem of designing an eective dy- namic learning from an optimization perspective. W e then employ a scalable, asynchronous model-based search (AMBS) algorithm to simultaneously optimize learning rules and their hyperparameters. W e adopt the AMBS implementation in De epHyper [2], a scalable optimization package that is built to take advantage of leadership- class computing systems through parallel algorithms and ecient workow management systems and hence pro vides advantages in speed to solution in addition to accuracy . T o this end, we make the following contributions: (1) a new appr oach to designing and optimizing neuromorphic architectures for task-specic dynamic learning by combining asynchronous model-based search with modulated learning and (2) demonstration that task-specic meta- learning rules are essential to e xtract the maximum performance from the learning model using two widely used ML b enchmark problems in combination with mushroom body architecture. 2 Dynamic Learning The architectures and meta-learning rules considered in this study are described below 2.1 Architecture T o explore architecture optimization for dynamic learning applica- tions, we consider ar chitectures that are inspir ed by the insect brain and, in particular , one of its key centers for olfactory (and, in hy- menopterans, visual) memory: the mushr oom body . The mushroom body constitute the third and fourth layers of olfactive processing in insects: sensing information is pooled in a rst layer called the antennal lobe and then sparsely projecte d into the Kenyon cells in the mushroom body; see Figure 1( a). This projection creates a sparse representation of the input that helps enhance its dimensionality . This layer is then densely connected into a few output neurons, which are recurrently connected. A key aspect of the mushroom body is that learning takes place primarily in this last step. More- over , mo dulatory neurons innervating the mushroom body control when and where learning takes place[1, 5]. Modulatory neurons Kenyon cells Input MBONs Antennal lobe glomeruli Context input MB A W AAAB6HicbVBNS8NAEJ3Ur1q/qh69LBbBU0m0oMeCF48t2A9oQ9lsJ+3azSbsboQS+gu8eFDEqz/Jm//GbZuDtj4YeLw3w8y8IBFcG9f9dgobm1vbO8Xd0t7+weFR+fikreNUMWyxWMSqG1CNgktsGW4EdhOFNAoEdoLJ3dzvPKHSPJYPZpqgH9GR5CFn1Fip2RmUK27VXYCsEy8nFcjRGJS/+sOYpRFKwwTVuue5ifEzqgxnAmelfqoxoWxCR9izVNIItZ8tDp2RC6sMSRgrW9KQhfp7IqOR1tMosJ0RNWO96s3F/7xeasJbP+MySQ1KtlwUpoKYmMy/JkOukBkxtYQyxe2thI2poszYbEo2BG/15XXSvqp611W3WavU3TyOIpzBOVyCBzdQh3toQAsYIDzDK7w5j86L8+58LFsLTj5zCn/gfP4Ar3WMyw== x e AAAB6nicbVBNS8NAEJ3Ur1q/qh69LBbBU0m0oMeCF48V7Qe0oWy2k3bpZhN2N2IJ/QlePCji1V/kzX/jts1BWx8MPN6bYWZekAiujet+O4W19Y3NreJ2aWd3b/+gfHjU0nGqGDZZLGLVCahGwSU2DTcCO4lCGgUC28H4Zua3H1FpHssHM0nQj+hQ8pAzaqx0/9THfrniVt05yCrxclKBHI1++as3iFkaoTRMUK27npsYP6PKcCZwWuqlGhPKxnSIXUsljVD72fzUKTmzyoCEsbIlDZmrvycyGmk9iQLbGVEz0sveTPzP66YmvPYzLpPUoGSLRWEqiInJ7G8y4AqZERNLKFPc3krYiCrKjE2nZEPwll9eJa2LqndZde9qlbqbx1GEEziFc/DgCupwCw1oAoMhPMMrvDnCeXHenY9Fa8HJZ47hD5zPH1XAjcQ= x m AAAB6nicbVA9SwNBEJ2LXzF+RS1tFoNgFe5U0DJgYxnRxEByhL3NJFmyu3fs7onhyE+wsVDE1l9k579xk1yhiQ8GHu/NMDMvSgQ31ve/vcLK6tr6RnGztLW9s7tX3j9omjjVDBssFrFuRdSg4AoblluBrUQjlZHAh2h0PfUfHlEbHqt7O04wlHSgeJ8zap1099SV3XLFr/ozkGUS5KQCOerd8lenF7NUorJMUGPagZ/YMKPaciZwUuqkBhPKRnSAbUcVlWjCbHbqhJw4pUf6sXalLJmpvycyKo0Zy8h1SmqHZtGbiv957dT2r8KMqyS1qNh8UT8VxMZk+jfpcY3MirEjlGnubiVsSDVl1qVTciEEiy8vk+ZZNTiv+rcXlZqfx1GEIziGUwjgEmpwA3VoAIMBPMMrvHnCe/HevY95a8HLZw7hD7zPH2Hgjcw= x o AAAB6nicbVA9SwNBEJ2LXzF+RS1tFoNgFe5U0DJgYxnRxEByhL3NJFmyt3vs7onhyE+wsVDE1l9k579xk1yhiQ8GHu/NMDMvSgQ31ve/vcLK6tr6RnGztLW9s7tX3j9oGpVqhg2mhNKtiBoUXGLDciuwlWikcSTwIRpdT/2HR9SGK3lvxwmGMR1I3ueMWifdPXVVt1zxq/4MZJkEOalAjnq3/NXpKZbGKC0T1Jh24Cc2zKi2nAmclDqpwYSyER1g21FJYzRhNjt1Qk6c0iN9pV1JS2bq74mMxsaM48h1xtQOzaI3Ff/z2qntX4UZl0lqUbL5on4qiFVk+jfpcY3MirEjlGnubiVsSDVl1qVTciEEiy8vk+ZZNTiv+rcXlZqfx1GEIziGUwjgEmpwA3VoAIMBPMMrvHnCe/HevY95a8HLZw7hD7zPH2Tojc4= u AAAB6HicbVBNS8NAEJ3Ur1q/qh69LBbBU0m0oMeCF48t2A9oQ9lsJ+3azSbsboQS+gu8eFDEqz/Jm//GbZuDtj4YeLw3w8y8IBFcG9f9dgobm1vbO8Xd0t7+weFR+fikreNUMWyxWMSqG1CNgktsGW4EdhOFNAoEdoLJ3dzvPKHSPJYPZpqgH9GR5CFn1FipmQ7KFbfqLkDWiZeTCuRoDMpf/WHM0gilYYJq3fPcxPgZVYYzgbNSP9WYUDahI+xZKmmE2s8Wh87IhVWGJIyVLWnIQv09kdFI62kU2M6ImrFe9ebif14vNeGtn3GZpAYlWy4KU0FMTOZfkyFXyIyYWkKZ4vZWwsZUUWZsNiUbgrf68jppX1W966rbrFXqbh5HEc7gHC7Bgxuowz00oAUMEJ7hFd6cR+fFeXc+lq0FJ585hT9wPn8A3O2M6Q== B Figure 1: (A ) Architecture inspired by the insect mushroom body: input information is sparsely fanned out from the an- tennal lob e to the Kenyon cells and then densely fanned into the output neurons. Mo dulatory neurons provide con- textual information to carr y out both context-dependent l- tering and context-dependent learning. (B) Simple scheme of a recurrent implementation of dynamic learning via lo- cal learning rules: synaptic weights are treated as a separate layer of the network, receiving inputs from the presynaptic, postsynaptic, and modulatory layers. In this work, we have abstracted this architecture to explore the optimization and accuracy of dierent dynamic learning algorithms based on modulated learning and local learning rules. Since learning takes place primarily in the last layer , we can model the input lay ers as a functional transformation of our input, so that x e = f ( u ; , ) . Here u is our input, x e represents the population of K enyon cells in the mushroom b ody , and m is a vector of modulator y interac- tions providing a context-dependent input for conte xt-dependent ltering of the input stream. Such context-dependent processing has been experimentally observed in the rst layer of olfactive pro- cessing of insects. The output layer takes a linear combination of inputs that are densely connected with recurrent, cross-inhibitory interactions. In addition to this processing component, we have a set of mo d- ulatory neurons m providing context-dependent information. This can be externally determined either for supervised learning or as a reinforcement signal, and their activity can be mo died by the output of the neurons or by an independent modulatory component in our network, either as fe edback or for cases where the system has internally to decide among multiple tasks. Our goal is to explore dynamic learning using local learning rules. Instead of considering the network and the training algorithm as two separate entities, we consider that the evolution of the synaptic weights is given by the following general rule . Û W = f ( x e , x o , x m , W; β ) (1) Here x e , x o , and x m generally repr esent the activity of presynaptic, postsynaptic, and modulator y neurons, respe ctively , and β rep- resents a set of hyperparameters controlling how learning takes place. With this approach, the system’s ability to dynamically learn depends b oth on the sele ction of the actual learning rule and on the hyperparameters involved. T o b etter understand how dierent learning rules aect the system’s ability to dynamically learn dier- ent tasks, we propose a conceptual framework in which the learning process is integrated into the network itself. If w e tr eat the synaptic weights following Eq. 1 as rst-class citizens of our network, we now have a r ecurrent network that essentially modies itself based on the input and an external context, as shown in Figure 1( b) . The key advantage of this approach is that we can leverage the capabil- ities of existing ML frameworks as w ell as existing approaches for network architecture optimization. 2.2 Learning and Meta-Learning Rules Many dynamic learning rules have been discusse d in the literature in the context of unsuper vised, supervise d, and reinforcement learn- ing applications. Here we considered a subset of these rules and modied some of them to incorporate the presence of modulator y interactions regulating when and where learning takes place. W e have explored the following meta-(local)learning rules: • Modulate d covariance rule (MCR): ∆ W = α ReLU ( x m − x o ) x e ( x m − β 1 ) (2) • Nonlocal, stabilize d covariance rule (NSCR): ∆ W = α Õ m , o ReLU ( x m − x o ) x e ( x m − β 1 W ) (3) • Nonlocal, stabilize d correlation rule (NSCoR): ∆ W = α д ( x e x m − β 1 W ) , (4) where д = Í m , o ReLU ( x m − x o ) • Modulate d Oja’s rule (MOR): ∆ W = α д x e x m − β 1 x 2 o W , (5) where д = ReLU ( x m − x o ) . • Least mean square rule (LMSR): ∆ W = α x e ( x m − x o ) (6) • Self-limited rule (SLR): W = W + W 0 α д x e 1 + α д ( β 1 + x e ) , (7) 2 where д = ReLU ( x m − x o ) • General modulate d rule (GMR): ∆ W = α x m ( β 1 x o + β 2 ( x o − x e ) + β 3 ) (8) • General unsuper vised rule (GUR): ∆ W = α ( β 1 x o + β 2 ( x o − x e ) + β 3 ) (9) In all these examples α is a parameter that contr ols the overall learning rate. Both MCR and NSCR are learning rules where the change in the synaptic weight is proportional to the presynaptic input x e and to the dierence between the modulatory input x m and the activity of the output neuron x o . This pr ovides a natural fe edback loop that interrupts learning once the desired output is achieved. In both cases, the sign of the weight change is determined by the dier- ence between the mo dulatory input x m and a threshold variable. The key dierence b etween MCR and NSCR is that in the former learning takes place solely whenever the modulator y neuron is active, wher eas in the latter a general modulation term is applied to all output neurons. Also, in the case of NSRC the loss term is proportional to the synaptic weight to ensure the stability of the learning rule. NSCoR is similarly a normalized covariance term, where the synaptic weight increase is driven by the covariance between the pre- and postsynaptic activity x e and the target modulatory output x m . MOR is simply a modulated version of Oja’s learning rule, whereas LMSE can be derived from a gradient descent rule from a cost func- tion equal to the mean square error b etween the actual output and the expected output. SLM is a self-limited rule in which synaptic weights are allowed to change only between 0 and W 0 . The current expression has been obtained from a fully implicit discretization of the corresponding dierential equation. GMR and GMU are two general rules base d on the activity of pre- and postsynaptic neurons. In the former case the learning rate is modulated by the dierence between the expected and the actual output of the network, whereas in the latter case the evolution of the synaptic weight is fully unsuper vised. W e expect that GMR and GMU will perform better when the mo dulatory neurons in- put the postsynaptic neurons. They will also be sensitive to the cross-inhibition b etween the output layer , which provides a natural competition between the output neurons. 3 Architecture Optimization W e adopt a parallel asynchronous model-based search [ 2 ] to learn the optimal meta-learning rule and its corresponding hy- perparameters for a given architecture and dataset combination. Parallelization of the parameter congurations evaluation is critical for scaling the optimization algorithms to handle ar chitectures that are computationally intensive to evaluate or have a large number of tunable parameters. In the AMBS approach adopted, a surr ogate model is t between model parameters (such as the meta-learning rule choice and the hyperparameters within the rule) and validation accuracy (for a ML task on a given dataset) to guide the search. This surrogate is updated dynamically (and asynchronously ) during each iteration of V araible Search Space Ψ {GMR,MCR,NSCR,LMSR SLR,GUR,NSCoR,MOR} α [1e-03, 1e-00] β 1 [1e-05, 1] β 2 [1e-05, 1] β 3 [1e-05, 1] T able 1: Search space considered to jointly optimize over the eight meta-learning rules and their parameters. Dataset Meta-Learning Rule Accuracy MNIST LMSR 0.903 FashionMNIST GMR 0.900 T able 2: Best-performing meta-learning rule and corre- sponding testing accuracy with each dataset. the search process by including the newly e valuated congurations, but without waiting for e valuations from all the activ e processes to be complete. This updated surrogate model is used to obtain promising congurations to evaluate for the next iteration. Crucial to this approach are the choice of the surrogate model and the criterion used to choose the promising congurations (acquisi- tion function). W e use a random forest regressor [ 3 ] as the surrogate model since our search space consists of categorical parameters (choice of the meta-learning rule) and continuous variables (pa- rameters inside the learning rule). Random forest is an ensemble machine learning approach that uses bootstrap aggregation (or bagging), wherein an ensemble of decision tr ees are combined to produce a model with better predictive accuracy and lower variance. The acquisition functions originate from the Bayesian optimization literature [ 8 ] and are used as strategies to balance exploration and exploitation in the search space. W e use a hedging strategy [ 6 ], wherein at each iteration, the algorithm chooses from a portfo- lio of acquisition functions based on an online multiarmed bandit strategy . 4 Results and Discussions W e adopt two dier ent datasets to study the hypothesis that task- specic meta-learning rules need to be considered and optimized in order to obtain the best predictive accuracy . The rst dataset is the widely used benchmark MNIST (Modied National Institute of Standards and T echnology) [ 7 ], which consists of grey-scale digital images of handwritten digits (0–9) that have been hand labelled. This dataset comprises 60,000 training data and 10,000 testing data, with each image showing a hand-written digit at low resolution (28x28 px). The second dataset is FashionMNIST [ 9 ], which shares the same image size, number of classes, and structure of training and testing splits as the original MNIST . However , the FashionMNIST is a more challenging dataset that comprises ten classes of fashion products. W e consider a shallow architecture for dynamic learning, which consists of four layers of a recurrent neural net: input layer , hidden layer , modulatory layer , and output layer . The plasticity in the hidden to output layer weights is regulated by using the modulatory layer . The modulator y layer corresponds to one of the eight meta-learning rules described by Ψ . The optimization search space consists of a categorical variable Ψ that repr esents the choice of the meta-learning rule. In this work, 3 we considered eight dierent rules, hence eight options for Ψ . The continuous parameters consist of α , which represents the learning rate, and three continuous variables commonly dened for all the meta-learning rules— β 1 , β 2 , and β 3 , as describe d in Section 2.2. W e note that not all the meta-learning rules have all the parameters, in which case only the subset of these parameters are used to evaluate the learning rule. However , the search algorithm is agnostic of this. The search space for all these parameters is shown in T able 1. The optimization experiments are run by using an implementa- tion of AMBS available in DeepHyper . The compute resources on Theta, a 11.69-petaops leadership computing facility at Argonne, are used, where the experiments for each dataset are run on 128 Intel Xeon Phi (code-named Knights Landing) processor nodes. The shallow ar chitecture has an input size of 784 (corresponding to images of size 28X28) and 10 outputs (corresponding to 10 classes) for both datasets. A total of 20,000 randomly selecte d images (from training data of 60,000) are used to train the mo del for each param- eter choice, and the predictive accuracy is obtaine d on the testing data with 10,000 images for b oth datasets. The best-performing meta-learning rule and its corresponding classication accuracy for both the MNIST and FashionMNIST datasets are shown in T able 2. The corresponding scatter plots are shown in Figur e 2, where all the evaluations corresponding to the best-performing meta-learning rule are highlighted in blue while those corresponding to rest of the rules are highlighted in red. W e note that the LMSR meta-learning rule with one active parameters ( α ) works b est for the MNIST dataset and obtains a parameter conguration that gives a classi- cation accuracy of 0.903. On the other hand, the GMR rule has three active parameters α , β 1 , β 2 , β 3 and provides the parameter conguration that achieves a classication accuracy of 0.9 for the FashionMNIST dataset, which is known to be more complicate d to learn than is MNIST . Results show that LMSR meta-learning rule pro vides higher ac- curacy with the MNIST dataset for smaller learning rates, as is expected since the number of epo chs used for training is low (0.33). This dependence is not clear for the GMR rule performing best for the FashionMNIST data since its active search space is four dimensional compared with one dimensional for LMSR. W e also observe that the β 2 is close to zero and β 3 is greater than 0 . 6 for all the parameter congurations, producing an accuracy close to 0 . 9 for GMR on FashionMNIST data. 5 Conclusions W e have mo deled task-specic dynamic learning using insect brain-inspired mushroom body architecture implemented as a re- current neural network, where the plastic synaptic weights are treated as layers in the network. The plasticity in output layer weights is controlled by the modulator y layer , which we model using meta-learning rules. This approach allows us to treat task- specic architecture optimization as the selection of the optimal meta-learning rule and its parameters. W e employ a scalable, asyn- chronous mo del-based search approach to perform the optimization at scale on Theta, a leadership-class system at Argonne. W e used two dierent machine learning b enchmark datasets— MNIST and FashionMNIST —along with the proposed architecture and optimization to assess the predictive capability of the learning model. Because of the inherent dierences in the two datasets, (a) (b) Figure 2: T esting accuracy as a function of the learning rate for all the evaluated congurations of the meta-learning rules where the evaluations corresponding to the b est- performing rule is highlighted as oppose d to all the other rules for (a) MNIST data and ( b) Fashion-MNIST . our proposed approach identies dierent best-performing meta- learning rules for the datasets, thus emphasizing the nee d for task- specic dynamic learning. In this work we have focused on a sp ecic example to demon- strate our approach. Our goal is to apply this methodology to ex- plore more complex, de eper architectures, including the presence of heterogeneous learning rules at dierent points of our network. W e also want to apply the same approach to the optimization of neuromorphic hardware , either to e xplore meta-learning in existing architectures such as Loihi or to help design novel robust and versatile architectures for edge-processing applications. 4 Acknowledgments This work was supported through the Lifelong Learning Ma- chines (L2M) program from DARP A/MTO. The material is also based in part by work supported by the U.S. Department of Energy , Oce of Science, under contract DE- AC02-06CH11357. References [1] Y oshinori Aso, Daisuke Hattori, Y ang Yu, Rebecca M. Johnston, Nirmala A. Iyer , T eri-TB Ngo, Heather Dionne, L. F. Abbott, Richard Axel, Hiromu T animoto, and Gerald M. Rubin. 2014. The neuronal architecture of the mushroom body provides a logic for associative learning. eLife 3 (De c. 2014), e04577. https: //doi.org/10.7554/eLife.04577 [2] P. Balaprakash, M. Salim, T . Uram, V . Vishwanath, and S. Wild. 2018. De epHyper: Asynchronous hyperparameter search for deep neural networks. In 2018 IEEE 25th International Conference on High Performance Computing (HiPC) . 42–51. https: //doi.org/10.1109/HiPC.2018.00014 [3] Leo Breiman. 2001. Random forests. Machine Learning 45, 1 (2001), 5–32. [4] Nicolas Frémaux and Wulfram Gerstner. 2016. Neuromodulated spike-timing- dependent plasticity , and theor y of three-factor learning rules. Front. Neural Circuits 9 (2016). https://doi.org/10.3389/fncir.2015.00085 [5] T oshihide Hige, Y oshinori Aso, Mehrab N. Modi, Gerald M. Rubin, and Glenn C. T urner . 2015. Heterosynaptic plasticity underlies aversive olfactory learning in Drosophila. Neuron 88, 5 (Dec. 2015), 985–998. https://doi.org/10.1016/j.neuron. 2015.11.003 [6] Matthew D Homan, Eric Brochu, and Nando de Fr eitas. 2011. Portfolio allocation for Bayesian optimization.. In U AI . Citeseer, 327–336. [7] Y ann LeCun, Léon Bottou, Y oshua Bengio, Patrick Haner , et al . 1998. Gradient- based learning applied to document recognition. Proc. IEEE 86, 11 (1998), 2278– 2324. [8] Bobak Shahriari, Kevin Swersky , Ziyu W ang, Ryan P A dams, and Nando De Freitas. 2016. T aking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 104, 1 (2016), 148–175. [9] Han Xiao, Kashif Rasul, and Roland V ollgraf. 2017. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747 (2017). 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment