음향 이벤트 탐지를 위한 언어 모델링 교사 강제와 스케줄링 샘플링 적용
본 논문은 음향 이벤트 탐지(CRNN) 모델에 이전 프레임의 클래스 활동을 입력으로 제공하여 언어 모델을 학습하도록 설계하였다. 교사 강제와 스케줄링 샘플링을 결합해 학습‑추론 간 불일치를 완화하고, 실제 데이터셋에서 F1 점수와 오류율을 개선하였다.
저자: Konstantinos Drossos, Shayan Gharib, Paul Magron
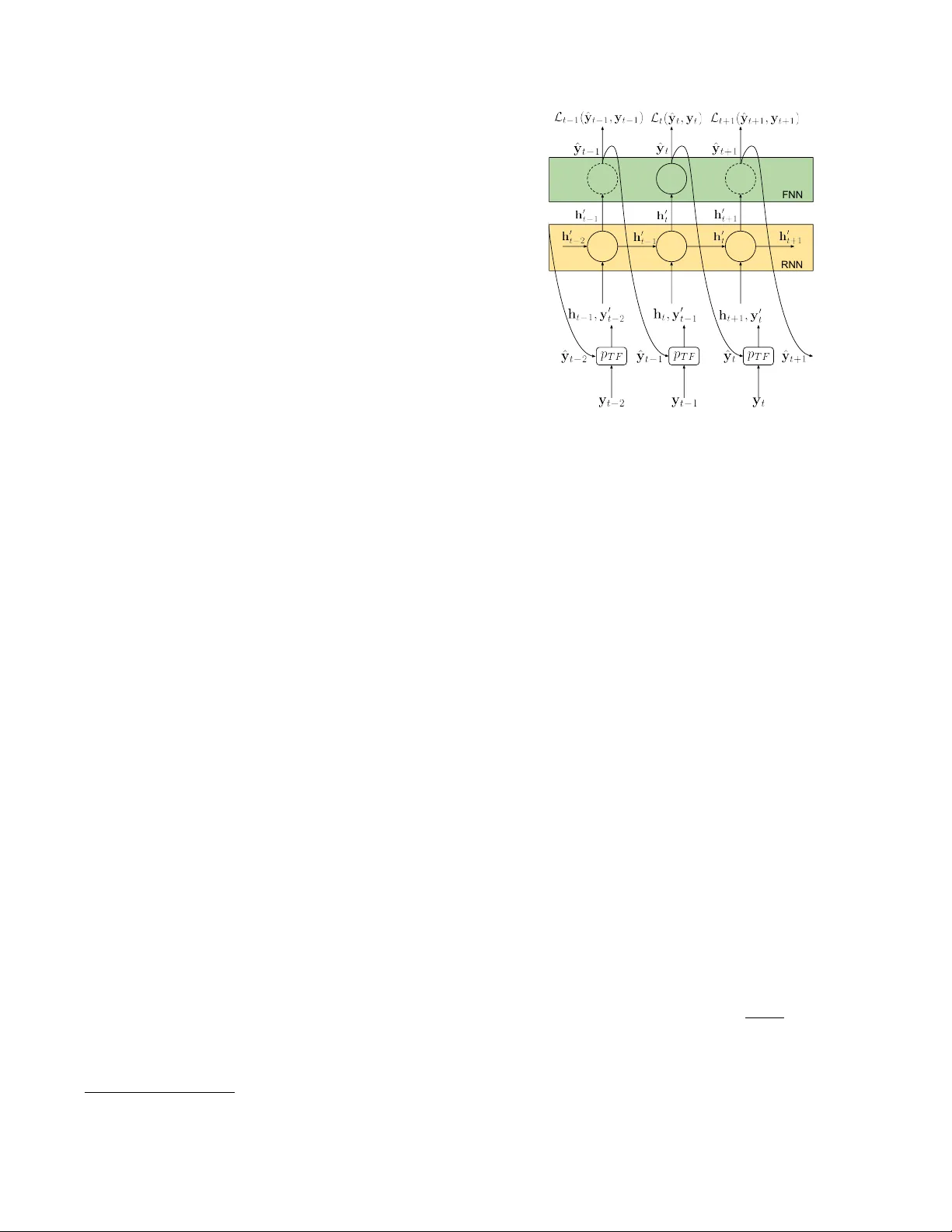
이 논문은 음향 이벤트 탐지(SED) 분야에서 시간적 구조를 효과적으로 활용하기 위해 언어 모델링 기법을 도입한다. 기존 SED 시스템은 프레임 단위의 오디오 특징을 입력으로 받아 각 프레임에서 이벤트 존재 여부를 예측하지만, 이벤트 간의 순차적 관계—예를 들어 “자동차 경적” 뒤에 “자동차 통과”가 나타나는 패턴—를 명시적으로 모델링하지 않는다. 저자는 이러한 한계를 극복하고자, RNN 기반 CRNN 구조에 교사 강제(teacher forcing)와 스케줄링 샘플링(scheduled sampling)이라는 두 가지 기법을 결합한다.
먼저, 기본 시스템은 40개의 로그 멜 밴드로 구성된 비중첩 시퀀스(길이 1024 프레임)를 입력으로, 3개의 CNN 블록을 통해 128 차원의 특징 H 를 추출한다. 이후 GRU 기반 RNN이 H 의 각 시간 단계와 이전 은닉 상태를 이용해 은닉 벡터 h₀ₜ 를 생성하고, 단일층 피드포워드 네트워크가 이를 통해 C 개 클래스 각각에 대한 존재 확률 ˆyₜ 를 출력한다. 손실 함수는 프레임별 바이너리 교차 엔트로피이며, Adam 옵티마이저와 배치 크기 8 로 학습한다.
교사 강제는 RNN 의 입력에 이전 시점의 실제 클래스 라벨 yₜ₋₁ 을 추가함으로써, RNN 이 출력 시퀀스 자체의 통계적 구조를 학습하도록 만든다. 그러나 학습 시에만 정답을 사용하고 추론 시에는 예측값 ˆyₜ₋₁ 로 대체해야 하는 불일치 문제가 발생한다. 이를 해결하기 위해 스케줄링 샘플링을 적용한다. 구체적으로 매 업데이트마다 정답을 사용할 확률 p_TF 를 지수적으로 감소시키며, 초기에는 p_TF 가 0.9 정도로 높아 정답을 주로 사용하고, 학습이 진행될수록 0.05 수준까지 낮춘다. 이렇게 하면 모델은 초기에는 깨끗한 라벨을 통해 언어 모델을 빠르게 습득하고, 후반에는 예측값에 대한 강인성을 기를 수 있다.
실험은 세 개의 공개 데이터셋을 대상으로 수행되었다. TUT‑SED Synthetic 2016 은 100개의 합성 오디오 파일로 구성돼 이벤트가 무작위로 배치되어 시간적 패턴이 거의 없으며, TUT Sound Events 2016 은 실내·실외 두 환경(각 11·7 클래스)에서 녹음된 실제 데이터, TUT Sound Events 2017 은 거리 환경(6 클래스)에서 수집된 데이터이다. 각 데이터셋은 DCASE 챌린지에서 제시한 교차 검증 방식으로 학습·검증·테스트를 나누었다. 평가 지표는 프레임 기반 F1 점수와 오류율(ER)이며, 4회 반복 실험을 통해 평균과 표준편차를 보고한다.
결과는 다음과 같다. 실제 녹음 데이터(TUT Sound Events 2016, 2017)에서는 제안 방법이 기존 CRNN 대비 F1 점수가 각각 9%와 2% 상승하고, ER 은 7%와 2% 감소하였다. 이는 RNN 이 이벤트 간 연관성을 학습함으로써 더 정확한 프레임 예측이 가능해졌음을 의미한다. 반면, 합성 데이터(TUT‑SED Synthetic 2016)에서는 F1 점수가 4% 감소하고 ER 이 7% 증가했다. 이는 시간적 구조가 거의 없는 데이터에 언어 모델을 강제하면 오히려 과적합이나 불필요한 제약이 발생한다는 점을 보여준다. 추가적으로, TUT Sound Events 2017 및 합성 데이터에서는 학습률을 5e‑4 로 낮추고, 그래디언트 L2‑노름을 0.5 로 클리핑함으로써 학습 안정성을 확보하였다. TUT Sound Events 2016 에서는 이전 출력 벡터를 이진화(y₀₀ₜ)해 노이즈를 감소시켰다.
본 연구의 주요 기여는 다음과 같다. (1) SED 에서 출력 시퀀스 자체의 언어 모델을 학습하도록 RNN 에 이전 클래스 정보를 직접 제공함으로써 시간적 구조를 명시적으로 활용한다. (2) 교사 강제와 스케줄링 샘플링을 결합해 학습‑추론 간 불일치를 최소화하고, 장기 시퀀스에서 오류 전파를 억제한다. (3) 별도의 HMM, CTC, N‑gram 등 복잡한 사전·후처리 없이 순수 DNN 기반으로 성능 향상을 달성한다. 한계점으로는 스케줄링 샘플링의 확률 스케줄링 파라미터가 데이터셋에 민감하게 작용한다는 점과, 시간적 구조가 거의 없는 데이터에서는 성능 저하가 발생한다는 점이다. 향후 연구에서는 다중 스케일 RNN, 어텐션 메커니즘, 혹은 사전학습된 언어 모델을 결합해 보다 일반화된 시간적 패턴 학습을 탐색하고, 데이터 증강 및 멀티태스크 학습을 통해 소규모 데이터셋에서도 안정적인 성능을 확보하는 방안을 모색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기