Language Modelling for Sound Event Detection with Teacher Forcing and Scheduled Sampling
A sound event detection (SED) method typically takes as an input a sequence of audio frames and predicts the activities of sound events in each frame. In real-life recordings, the sound events exhibit some temporal structure: for instance, a "car hor…
Authors: Konstantinos Drossos, Shayan Gharib, Paul Magron
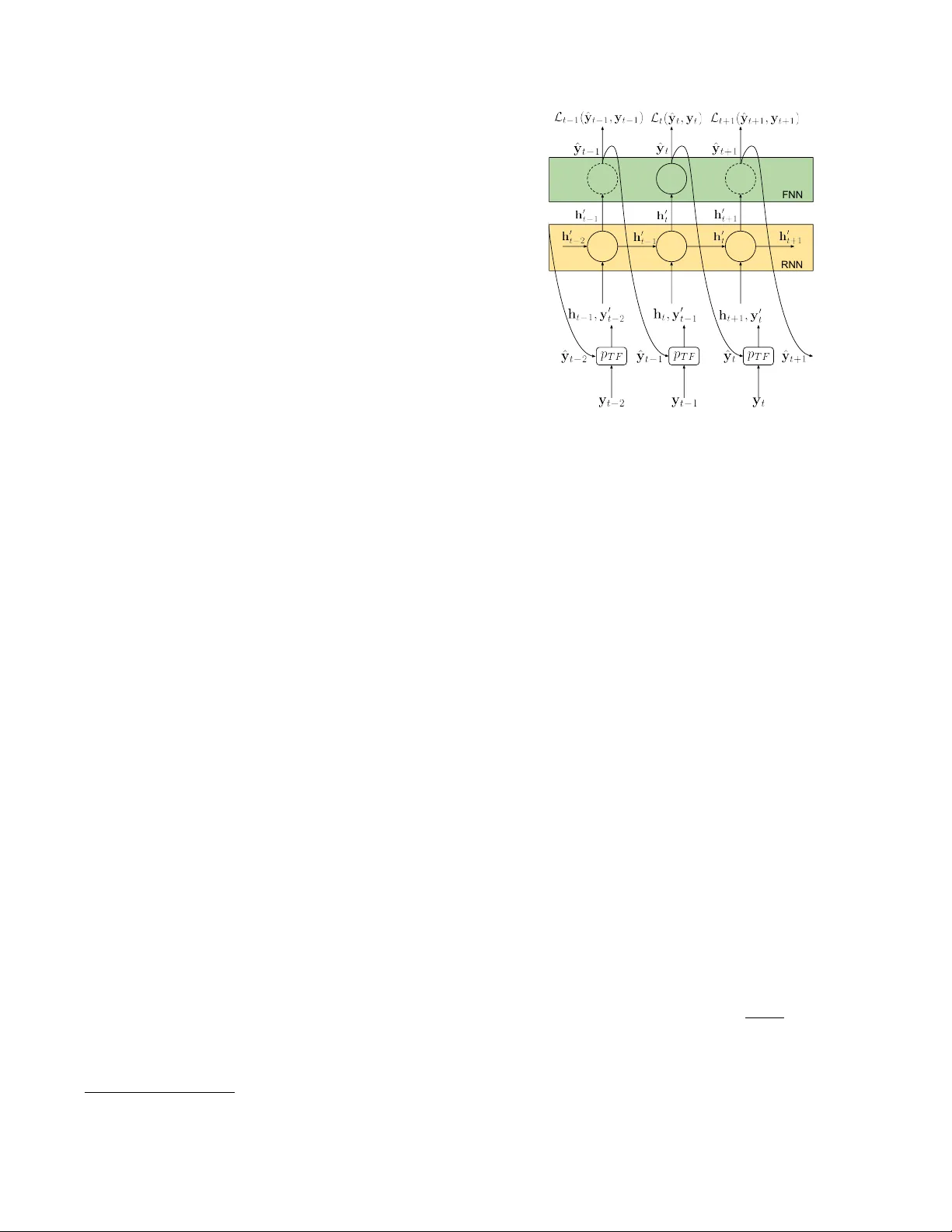
Detection and Classification of Acoustic Scenes and Events 2019 25–26 October 2019, New Y ork, NY , USA LANGU A GE MODELLING FOR SOUND EVENT DETECTION WITH TEA CHER FORCING AND SCHEDULED SAMPLING K onstantinos Dr ossos, Shayan Gharib, P aul Magr on, and T uomas V irtanen Audio Research Group, T ampere Univ ersity , T ampere, Finland { firstname.lastname } @tuni.fi ABSTRA CT A sound ev ent detection (SED) method typically takes as an input a sequence of audio frames and predicts the acti vities of sound ev ents in each frame. In real-life recordings, the sound e vents exhibit some temporal structure: for instance, a “car horn” will likely be followed by a “car passing by”. While this temporal structure is widely ex- ploited in sequence prediction tasks (e.g., in machine translation), where language models (LM) are exploited, it is not satisfactorily modeled in SED. In this w ork we propose a method which allo ws a recurrent neural network (RNN) to learn an LM for the SED task. The method conditions the input of the RNN with the acti vities of classes at the previous time step. W e e valuate our method using F 1 score and error rate ( E R ) o ver three dif ferent and publicly a vailable datasets; the TUT -SED Synthetic 2016 and the TUT Sound Events 2016 and 2017 datasets. The obtained results show an increase of 9% and 2% at the F 1 (higher is better) and a decrease of 7% and 2% at E R (lower is better) for the TUT Sound Events 2016 and 2017 datasets, respectively , when using our method. On the con- trary , with our method there is a decrease of 4% at F 1 score and an increase of 7% at E R for the TUT -SED Synthetic 2016 dataset. Index T erms — sound ev ent detection, language modelling, se- quence modelling, teacher forcing, scheduled sampling 1. INTR ODUCTION Sound e vent detection (SED) consists in detecting the activity of classes (onset and offset times) in an audio signal, where the classes correspond to different sound e vents. (e.g., “baby cry”, “glass shat- ter”). This task finds applications in many areas related to ma- chine listening, such as audio surveillance for smart industries and cities [1, 2], smart meeting room devices for enhanced telecom- munications [3, 4], or bio-div ersity monitoring in natural environ- ments [5, 6]. SED is a challenging research task since the sound ev ents are of very diverse nature, which might be unknown a pri- ori in real-life recordings. Besides, they often overlap in time, a problem termed as polyphonic SED. Significant advances in SED were made recently thanks to the advent of deep learning [7]. The recurrent neural network (RNN) hav e proven particularly promis- ing [8, 9] as they are able to model the temporal discriminant repre- sentations for sound e vents. More recently , these hav e been stack ed with conv olutional layers, resulting in conv olutional recurrent neu- ral networks (CRNN) which yield state-of-the-art results [10, 11]. In real-life recordings, the various sound events likely tempo- ral structures within and across ev ents. For instance, a “footsteps” ev ent might be repeated with pauses in between (intra-ev ent struc- ture). On the other hand, “car horn” is likely to follow or precede the “car passing by” sound ev ent (inter-ev ents structure). Although these temporal structures vary with the acoustic scene and the ac- tual sound ev ents classes, they exist and can be exploited in the SED task. Some previous studies focus on exploiting these tempo- ral structures. For example, in [9], the authors propose to use hidden Markov models (HMMs) to control the duration of each sound ev ent predicted with a deep neural network (DNN). Although the results show some improv ement with the usage of HMMs, the approach is a hybrid one and it requires a post processing step, which might be limited compared to an non-hybrid, DNN-based approach. In [12] and [13], the connectionist temporal classification (CTC) [14] loss function is used for SED: the output of the DNN is modified in or- der to be used with the CTC. Although the usage of CTC seems to be promising, CTC needs modification in order to be used for SED, it is a complicated criterion to employ , and it was dev eloped to solve the problem where there is no frame-to-frame alignment between the input and output sequences [14]. Thus, there might be the case that using a different method for SED language modelling could provide better results than CTC. Finally , in [13], the authors also employ N-grams, which require pre and post processing stages, and use the class acti vities as e xtra input features. Howe ver , the lat- ter approach did not perform better than a baseline which did not employ any language model. In this paper we propose an RNN-based method for SED that exploit the temporal structures within and across events of audio scenes without the aforementioned drawbacks of the previous ap- proaches. This method is based on established practices from other scientific disciplines that deal with sequential data (e.g., machine translation, natural language processing, speech recognition). It consists in using the output of the classifier as an extra input to the RNN in order to learn a model of the temporal structures of the output sequence (referred to as language model), a technique called teacher for cing [15]. Besides, this extra input of the RNN is chosen as a combination of the ground truth and predicted classes. This strategy , known as schedule sampling [16], consists in first using the ground truth activities and further replacing them by the pre- dictions. This allows the RNN to learn a robust language model from clean labels, without introducing any mismatch between the training and inference processes. The rest of the paper is organized as follows. In Section 2 we present our method. Section 3 details the experimental protocol and Section 4 presents the results. Section 5 concludes the paper . 2. PR OPOSED METHOD W e propose a system that consists of a DNN acting as a feature extractor , an RNN that learns the temporal structures withing and across events (i.e. a language model), and a feed-forward neural network (FNN) acting as a classifier . Since we focus on designing Detection and Classification of Acoustic Scenes and Events 2019 25–26 October 2019, New Y ork, NY , USA an RNN that is able to learn a language model ov er the sound ev ents, the RNN tak es as inputs the outputs of both the DNN and the FNN. The code for our method can be found online 1 . 2.1. Baseline system The DNN takes as an input a time-frequency representation of an audio signal denoted X ∈ R T × F ≥ 0 , where T and F respectiv ely de- note the number of time frames and features. It outputs a latent representation: H = DNN ( X ) , (1) where H ∈ R T × F 0 is the learned representation with F 0 features. Then, the RNN operates ov er the rows of H as h 0 t = RNN ( h t , h 0 t − 1 ) , (2) where t = 1 , 2 , . . . , T , h 0 0 = { 0 } F 00 , h 0 t ∈ [ − 1 , 1] F 00 , and F 00 is the amount of features that the RNN outputs at each time-step. Finally , the FNN takes h 0 t as an input and outputs the prediction ˆ y t for the time-step t as: ˆ y t = σ ( FNN ( h 0 t )) , (3) where σ is the sigmoid function, and ˆ y t ∈ [0 , 1] C is the predicted activity of each of the C classes. The DNN, the RNN, and the FNN are simultaneously opti- mized by minimizing the loss L ( ˆ Y , Y ) = P t L t ( ˆ y t , y t ) with: L t ( ˆ y t , y t ) = C X c =1 y t,c log( ˆ y t,c ) + (1 − y t,c ) log (1 − ˆ y t,c ) , (4) where y t,c and ˆ y t,c are the ground truth and predicted activities, respectiv ely , of the c -th class at the t -th time-step. 2.2. T eacher forcing The modeling in Eq. (2) shows that the RNN learns according to its input and its previous state [15, 16]. In order to allow the RNN to learn a language model over the output (i.e. the sound ev ents), we propose to inform the RNN of the acti vities of the classes of the sound events at the time step t − 1 . That is, we condition the input to the RNN as: h 0 t = RNN ( h t , h 0 t − 1 , y 0 t − 1 ) , (5) where y 0 t − 1 is the vector with the activities of the classes of the sound ev ents at time step t − 1 , and y 0 0 = { 0 } C . This technique is termed as teacher forcing [15], and is widely employed in sequence prediction/generation tasks where the output sequence has an in- herent temporal model/structure (e.g., machine translation, image captioning, speech recognition) [17, 18, 19]. By using this condi- tioning of the RNN, the RNN can learn a language model over the output tokens of the classifier [15, 16]. In SED, this results in letting the RNN learn a language model o ver the sound e vents, e.g., which sound e vents are more likely to happen together and/or in sequence, or how likely is a sound ev ent to keep being active, given the pre- vious acti vity of the sound e vents. T eacher forcing is dif ferent from what was proposed in [13], as the latter approach conditioned the DNN (not the RNN) with the class activities: such an approach yielded poor results, intuitiv ely explained by having y 0 t − 1 domi- nated by the information in X through the sequence of the CNN blocks. 1 https://github.com/dr- costas/SEDLM RNN FNN Figure 1: Proposed method of teacher forcing with scheduled sam- pling. 2.3. Scheduled sampling The activity vector y 0 t − 1 can be either the ground truth data (i.e., y t − 1 ), or the predictions of the classifier (i.e., ˆ y t − 1 ). In the for- mer case, the RNN is likely to start learning the desired language model from the first updates of the weights. At each time step t , the RNN will take as input the ground truth activities of the classes, thus being able to exploit this information from the v ery first weight up- dates. Howe ver , these ground truth values are not av ailable at the in- ference stage: these would be replaced by the estimates ˆ y t − 1 , which would create a mismatch between the training and testing processes. Besides, an RNN trained using only the true class activities is very likely to be sensitiv e to the prediction errors in ˆ y t − 1 . Finally , we empirically observed that using y t − 1 with the SED datasets, which are of relatively small size, results in a very poor generalization of the SED method. A countermeasure to the above is to use the predictions ˆ y t − 1 as y 0 t − 1 , which allows the RNN to compensate for the prediction errors. Howev er , during the first weight updates, the predicted ˆ y t − 1 is very noisy and any error created at a time step t is propag ated ov er time, which results in accumulating more errors down the line of the output sequence. This makes the training process v ery unstable and is likely to yield a poor SED performance. T o exploit the best of both approaches, we propose to use the scheduled sampling strategy [16]: the ground truth class activities are used during the initial epochs, and they are further gradually replaced by the predicted class activities. This gradual replacement is based on a probability p TF of picking y t − 1 ov er ˆ y t − 1 as y 0 t − 1 that decreases over epochs. Different functions can be used for the calculation of p TF (e.g., exponential, sigmoid, linear). Here, we employ a model of exponential decrease of p TF : p TF = min( p max , 1 − min(1 − p min , 2 1 + e β − 1)) , (6) where β = − iγ N − 1 b , i is the index of the weight update (i.e., how many weight updates have been performed), N b is the amount of batches in one epoch, and p max , p min , and γ are hyper-parameters to be tuned. p max and p min are the maximum and minimum prob- Detection and Classification of Acoustic Scenes and Events 2019 25–26 October 2019, New Y ork, NY , USA abilities of selecting ˆ y t , and γ controls the slope of the curve of p T F for a given N b and as i increases. W e use a minimum prob- ability p min because we experimentally observed that if we solely use y t − 1 as y 0 t − 1 ev en in the first initial weight updates, then the SED method overfits. The usage of p min counters this fact. On the other hand, we use a maximum probability p max in order to allow the usage of y t − 1 as y 0 t − 1 at the later stages of the learning process. W e do this because the length of a sequence in SED is usually over 1000 time-steps and an y error in ˆ y t is accumulated in this very long sequence, resulting in hampering the learning process. The usage of p max offers a counter measure to this, by allowing the usage of ground truth values y t instead of predicted and noisy values. This method is illustrated in Figure 1. 3. EV ALU A TION W e evaluate our method using the CRNN from [10], and we emplo y synthetic and real-life recordings datasets to illustrate the impact of the language model learned by our method. 3.1. Data and feature extraction The synthetic dataset is the TUT -SED Synthetic 2016, used in [10], and consisting of 100 audio files which are synthetically created out of isolated sound events of 16 dif ferent classes. These classes are: alarms and sir ens , baby crying , bird singing , bus , cat meow- ing , cr owd applause , crowd cheering , dog barking , footsteps , glass smash , gun shot , horse walk , mixer , motor cycle , rain , and thunder . Each audio file contains a maximum of N number of randomly se- lected tar get classes, where N is sampled from the discrete uniform distribution U (4 , 9) , and the maximum number of simultaneously activ e (polyphony) sound ev ents is 5. The audio files do not con- tain any background noise. The audio files amount to a total of 566 minutes of audio material, and according to the splits introduced by [10], roughly 60% of the data are dedicated to training, 20% to validation, and 20% to testing split. More information about the dataset can be found online 2 . W e employ two real-life recording datasets, which were part of the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge datasets for SED in real life audio task: the TUT Sound Events 2016 and the TUT Sound Events 2017 [20]. The TUT Sound Events 2016 dataset contains sound ev ents recorded in two en vironments: home (indoor), which contains 11 classes, and residential area (outdoor), which contains 7 classes. The classes for the home environment are: (object) rustling , (object) snapping , cup- boar d , cutlery , dishes , drawer , glass jingling , object impact , people walking , washing dishes , and water tap running . The classes for the residential area en vironment are: (object) banging , bir d singing , car passing by , childr en shouting , people speaking , people walking , and wind blowing . The TUT Sound Events 2017 dataset contains recordings in a street environment and contains 6 different classes. These classes are: brakes squeaking , car , childr en , large vehicle , people speaking , and people walking . For both datasets, we use the cross-fold validation split proposed in the DCASE 2016 and 2017 challenges. More information about the classes, the cross-fold set- ting, and the recordings of the datasets can be found online 3 4 . 2 http://www.cs.tut.fi/sgn/arg/taslp2017- crnn- sed/tut- sed- synthetic- 2016 3 http://www.cs.tut.fi/sgn/arg/dcase2016 4 http://www.cs.tut.fi/sgn/arg/dcase2017/ challenge Figure 2: The value of p TF with consecutiv e weight updates with p min = 0 . 05 , p max = 0 . 95 , and N b = 44 . The vertical dashed lines indicate steps of 25 epochs (i.e. 25, 50, 75 epochs). The synthetic dataset has randomly selected and placed sound ev ents, therefore not exhibiting any underlying temporal structure of sound events. W e thus expect the performance of our method to be similar to a method without language modeling on the synthetic dataset. Contrarily , the real-life recording datasets exhibit some un- derlying temporal structures in the sound events, therefore we ex- pect our method to perform better than a method without language modelling on these datasets. As input features X we use non-overlapping sequences of T = 1024 feature vectors. These consist of F = 40 log mel-bands, extracted using a short-time Fourier transform using a 22 ms Ham- ming windo w , 50% overlap and no zero padding. W e normalize the extracted feature vectors from each dataset to have zero mean and unit v ariance, emplo ying statistics calculated on the training split of each corresponding dataset. 3.2. System and hyper -parameters As our DNN we use the three conv olutional neural network (CNN) blocks from the system in [10], each consisting of a CNN, a batch normalization function, a max-pooling operation, a dropout func- tion, and a rectified linear unit (ReLU). The kernels of the CNNs are square with a width of 5, a stride of 1, and a padding of 2 in both directions. There are 128 filters for each CNN. The kernel and the stride for the first max-pooling operation are { 1 , 5 } , for the sec- ond { 1 , 4 } , and for the third { 1 , 2 } . These result in F 0 = 128 for H . All CNN blocks use a dropout of 25% at their input, and the last CNN block also uses a dropout of 25% at its output. As our RNN we use a gated recurrent unit (GRU) with F 00 = 128 and our FNN is a single-layer feed-forward network with the output size defined according to the amount of classes in each dataset: C = 16 for TUT -SED Synthetic 2016, C = 11 and C = 7 for the home and residential area scenes of the TUT Sound Events 2016, and C = 6 for the TUT Sound Events 2017. T o optimize the weights we em- ployed the Adam optimizer [21] with default values. W e employ a batch size of 8 and we stop the training when the loss for the vali- dation data is not decreasing for 50 consecuti ve epochs. Finally , we set the hyper-parameters for p TF at γ = 12 − 1 , p min = 0 . 05 , and p max = 0 . 9 . In Figure 2 is the value of p TF for consecutive weight updates of N b = 44 and for 100 epochs. Empirically we observed that when using the TUT Sound Detection and Classification of Acoustic Scenes and Events 2019 25–26 October 2019, New Y ork, NY , USA Events 2017, there are some irregular spikes of relatively high gra- dients in different batches during training. T o alleviate this issue, we clipped the ` 2 -norm of the gradient of all weights in each layer of our system to a v alue of 0.5. Additionally , we also observed that for the TUT Sound Events 2017 and TUT -SED Synthetic 2016 datasets, our method performed significantly better when we decreased the learning rate of the optimizer to 5 e − 4 . Therefore, we employed the abov e mentioned gradient clipping and modified learning rate for our method, when using the aforementioned datasets. Finally , for the TUT Sound Events 2016, we employed a binarized version of y 0 denoted y 00 , such that y 00 t,c = 1 if y 0 t,c ≥ 0 . 5 , and y 00 t,c = 0 otherwise. All the abov e hyper-parameters were tuned using the cross v al- idation set up for the TUT Sound Events 2016 and 2017 datasets provided by DCASE challenges, and the validation split provided in [10] for the TUT -SED Synthetic 2016 dataset. 3.3. Metrics W e measure the performance of our method using the frame based F 1 score and the error rate ( E R ), according to pre vious studies and the DCASE Challenge directions [10, 13]. For the real-life datasets, the F 1 and E R are the averages among the provided folds (and among the dif ferent acoustic scenes for the 2016 dataset), while for the synthetic dataset the F 1 and E R are obtained on the testing split. Finally , we repeat four times the training and testing process for all datasets, in order to obtain a mean and standard de viation (STD) for F 1 and E R . 3.4. Baseline As a baseline we employ the system presented in [10], that does not e xploit any language model. W e do not apply any data augmen- tation technique during training and we use the hyper-parameters presented in the corresponding paper . This system is referred to as “Baseline”. When using our method with the TUT Sound Events 2017 and TUT -SED Synthetic 2016 datasets, we employ a modified learning rate for the optimizer and we clip the ` 2 -norm of the gradient for all weights. T o obtain a thorough and fair assessment of the perfor- mance of our method, we utilize a second baseline for this dataset: we use again the system presented in [10], but we employ the above- mentioned gradient clipping and modified learning rate. W e denote this modified baseline as “modBaseline”. Finally , we compare our method to the best results presented in [13] which are obtained by employing N-grams as a post- processing to learn a language model. W e report the results of this method on the TUT Sound Events 2016 datasets, as these are the only ones in the corresponding paper that are based on a publicly av ailable dataset. It must be noted that in [13] was proposed the usage of y 0 t − 1 as extra input features and the usage of CTC, but the results were inferior to the N-grams approach. Specifically , the per frame F 1 score was 0 . 02 and 0 . 04 lo wer and E R was 0 . 02 and 0 . 15 higher with the usage of y 0 t − 1 as an e xtra input feature and the usage of CTC, respectiv ely , compared to the N-grams approach. 4. RESUL TS & DISCUSSION In T able 1 are the obtained results for all the employed datasets. W e remark that using the proposed language model improves the per- formance of SED in the real-life datasets. Specifically , for the TUT T able 1: Mean and STD (Mean/STD) of F 1 (higher is better) and E R (lower is better). F or the method [13] only the mean is av ail- able. Baseline modBaseline [13] Proposed TUT Sound Events 2016 dataset F 1 0 . 28 / 0 . 01 – 0 . 29 0 . 37 / 0 . 02 ER 0 . 86 / 0 . 02 – 0 . 94 0 . 79 / 0 . 01 TUT Sound Events 2017 dataset F 1 0 . 48 / 0 . 01 0 . 49 / 0 . 01 – 0 . 50 / 0 . 02 ER 0 . 72 / 0 . 01 0 . 70 / 0 . 01 – 0 . 70 / 0 . 01 TUT -SED Synthetic 2016 dataset F 1 0 . 58 / 0 . 01 0 . 62 / 0 . 01 – 0 . 54 / 0 . 01 ER 0 . 54 / 0 . 01 0 . 49 / 0 . 01 – 0 . 61 / 0 . 02 Sound Events 2016 dataset there is an improvement of 0 . 09 in the F 1 score and 0 . 07 for the E R . For the TUT Sound Events 2017, there is a 0 . 02 improvement in F 1 and 0 . 02 improv ement in E R . These results clearly show that the employment of language mod- elling was beneficial for the SED method, when a real life datset was used. This is expected, since in a real life scenario the sound e vents exhibit temporal relationships. For e xample, “people speaking” and “people walking” or “washing dishes” and “water tap running” are likely to happen together or one after the other . On the contrary , from T able 1 we observe that there is a decrease in performance with our method on the synthetic data. Specifically , there is a 0 . 04 (or 0 . 08 when compared to modBase- line) decrease in F 1 and 0 . 07 (or 0 . 12 when compared to modBase- line) increase in E R . This clearly indicates that using a language model has a negati ve impact when the synthetic dataset is used. The sound ev ents in the synthetic dataset do not exhibit any temporal re- lationships and, thus, the language model cannot provide any benefit to the SED method. W e suggest that in such a scenario, the network focuses on learning a language model that does not e xist in the data instead of solely trying to accurately predict the events on a frame- wise basis: this explains the drop in performance compared to the baseline method. Overall, this difference in performance between the two types of datasets strongly suggests that our method learns a language model ov er the activities of the sound e vents. Finally , our system significantly outperforms the previous method [13] on the TUT Sound Events 2016 dataset. This shows that learning a language model is more powerful than crafting it as a post-processing. 5. CONCLUSIONS In this paper we presented a method for learning a language model for SED. Our method focuses on systems that utilize an RNN before the the last layer of the SED system, and consists of conditioning the RNN at a time step t with the activities of sound events at the time step t − 1 . As activities for t − 1 we select the ground truth early on the training process, and we gradually switch to the predic- tion of the classifier as the training proceeds o ver time. W e e valuate our method with three dif ferent and publicly av ailable datasets, two from real life recordings and one synthetic dataset. The obtained re- sults indicate that with our method, the utilized SED system learned a language model over the activities of the sound events, which is beneficial when used on real life datasets. In future work, we will conduct a more in-depth analysis of the learned language model and of the SED performance per class. Detection and Classification of Acoustic Scenes and Events 2019 25–26 October 2019, New Y ork, NY , USA 6. REFERENCES [1] M. Crocco, M. Cristani, A. Trucco, and V . Murino, “ Au- dio surveillance: A systematic revie w , ” ACM Comput. Surv . , vol. 48, no. 4, pp. 52:1–52:46, Feb . 2016. [2] P . Foggia, N. Petkov, A. Saggese, N. Strisciuglio, and M. V ento, “ Audio surveillance of roads: A system for de- tecting anomalous sounds, ” IEEE T ransactions on Intelligent T ransportation Systems , v ol. 17, no. 1, pp. 279–288, Jan 2016. [3] T . Butko, F . G. Pla, C. Segura, C. Nadeu, and J. Hernando, “T wo-source acoustic e vent detection and localization: Online implementation in a smart-room, ” in Proc. European Signal Pr ocessing Confer ence , Aug 2011. [4] C. Busso, S. Hernanz, Chi-W ei Chu, Soon-il Kwon, Sung Lee, P . G. Georgiou, I. Cohen, and S. Narayanan, “Smart room: participant and speaker localization and identification, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP) , March 2005. [5] B. J. Furnas and R. L. Callas, “Using automated recorders and occupanc y models to monitor common forest birds across a large geographic region, ” The Journal of W ildlife Manage- ment , vol. 79, no. 2, pp. 325–337, 2015. [6] T . A. Marques, L. Thomas, S. W . Martin, D. K. Mellinger , J. A. W ard, D. J. Moretti, D. Harris, and P . L. T yack, “Es- timating animal population density using passive acoustics, ” Biological Reviews , v ol. 88, no. 2, pp. 287–309, 2013. [7] E. Benetos, D. Stowell, and M. D. Plumbley , Appr oaches to Complex Sound Scene Analysis . Springer International Pub- lishing, 2018, pp. 215–242. [8] G. Parascandolo, H. Huttunen, and T . V irtanen, “Recurrent neural networks for polyphonic sound ev ent detection in real life recordings, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , March 2016. [9] T . Hayashi, S. W atanabe, T . T oda, T . Hori, J. Le Roux, and K. T akeda, “Duration-controlled LSTM for polyphonic sound ev ent detection, ” IEEE/A CM T ransactions on Audio, Speech, and Language Processing , vol. 25, no. 11, pp. 2059–2070, Nov ember 2017. [10] E. C ¸ akir, G. Parascandolo, T . Heittola, H. Huttunen, and T . V irtanen, “Con volutional recurrent neural networks for polyphonic sound event detection, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 25, no. 6, pp. 1291–1303, June 2017. [11] S. Adavanne, P . Pertil ¨ a, and T . V irtanen, “Sound ev ent detec- tion using spatial features and con volutional recurrent neural network, ” in Pr oc. IEEE International Conference on Acous- tics, Speec h and Signal Pr ocessing (ICASSP) , March 2017. [12] Y . W ang and F . Metze, “ A first attempt at polyphonic sound ev ent detection using connectionist temporal classification, ” in Pr oc. IEEE International Conference on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , March 2017. [13] G. Huang, T . Heittola, and T . V irtanen, “Using sequential information in polyphonic sound event detection, ” in 2018 16th International W orkshop on Acoustic Signal Enhancement (IW AENC) , Sep. 2018, pp. 291–295. [14] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unseg- mented sequence data with recurrent neural networks, ” in Pr oceedings of the 23rd International Confer ence on Machine Learning , ser . ICML ’06. Ne w Y ork, NY , USA: ACM, 2006, pp. 369–376. [Online]. A vailable: http://doi.acm.org/10.1145/1143844.1143891 [15] R. J. Williams and D. Zipser, “ A learning algorithm for contin- ually running fully recurrent neural networks, ” Neural Com- putation , vol. 1, no. 2, pp. 270–280, June 1989. [16] S. Bengio, O. V inyals, N. Jaitly , and N. Shazeer, “Sched- uled sampling for sequence prediction with recurrent neural networks, ” in Pr oceedings of the 28th Interna- tional Confer ence on Neural Information Pr ocessing Systems - V olume 1 , ser . NIPS’15. Cambridge, MA, USA: MIT Press, 2015, pp. 1171–1179. [Online]. A vailable: http://dl.acm.org/citation.cfm?id=2969239.2969370 [17] D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine trans- lation by jointly learning to align and translate, ” in Interna- tional Confer ence on Learning Representations (ICLR) , 2015. [18] I. Sutskev er , O. V inyals, and Q. V . Le, “Sequence to sequence learning with neural networks, ” in Advances in Neural Information Pr ocessing Systems 27 , Z. Ghahramani, M. W elling, C. Cortes, N. D. La wrence, and K. Q. W einberger , Eds. Curran Associates, Inc., 2014, pp. 3104– 3112. [Online]. A vailable: http://papers.nips.cc/paper/5346- sequence- to- sequence- learning- with- neural- networks.pdf [19] O. V inyals, A. T oshev , S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator , ” in 2015 IEEE Con- fer ence on Computer V ision and P attern Reco gnition (CVPR) , June 2015, pp. 3156–3164. [20] A. Mesaros, T . Heittola, and T . V irtanen, “TUT database for acoustic scene classification and sound event detection, ” in 24th Eur opean Signal Pr ocessing Confer ence 2016 (EU- SIPCO 2016) , Budapest, Hung ary , 2016. [21] D. Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” in 3r d International Confer ence for Learning Rep- r esentations , May 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment