혼합 요인화 자동인코더 기반 무지도 음성 신호 계층적 분해
본 논문은 음성 신호를 언어 내용과 화자 특성이라는 두 요인으로 무지도 분해하기 위해, 프레임 수준에서 이산 토큰을 생성하는 프레임 토크나이저와 발화 전체를 요약하는 발화 임베더를 결합한 혼합 요인화 자동인코더(mFAE)를 제안한다. mFAE는 기존 변분 오토인코더에서 KL 정규화를 제거하고 Gumbel‑Softmax를 이용해 차별화 가능한 이산 라벨을 학습한다. VoxCeleb1 화자 검증과 ZeroSpeech 2017 비지도 서브워드 모델링…
저자: Zhiyuan Peng, Siyuan Feng, Tan Lee
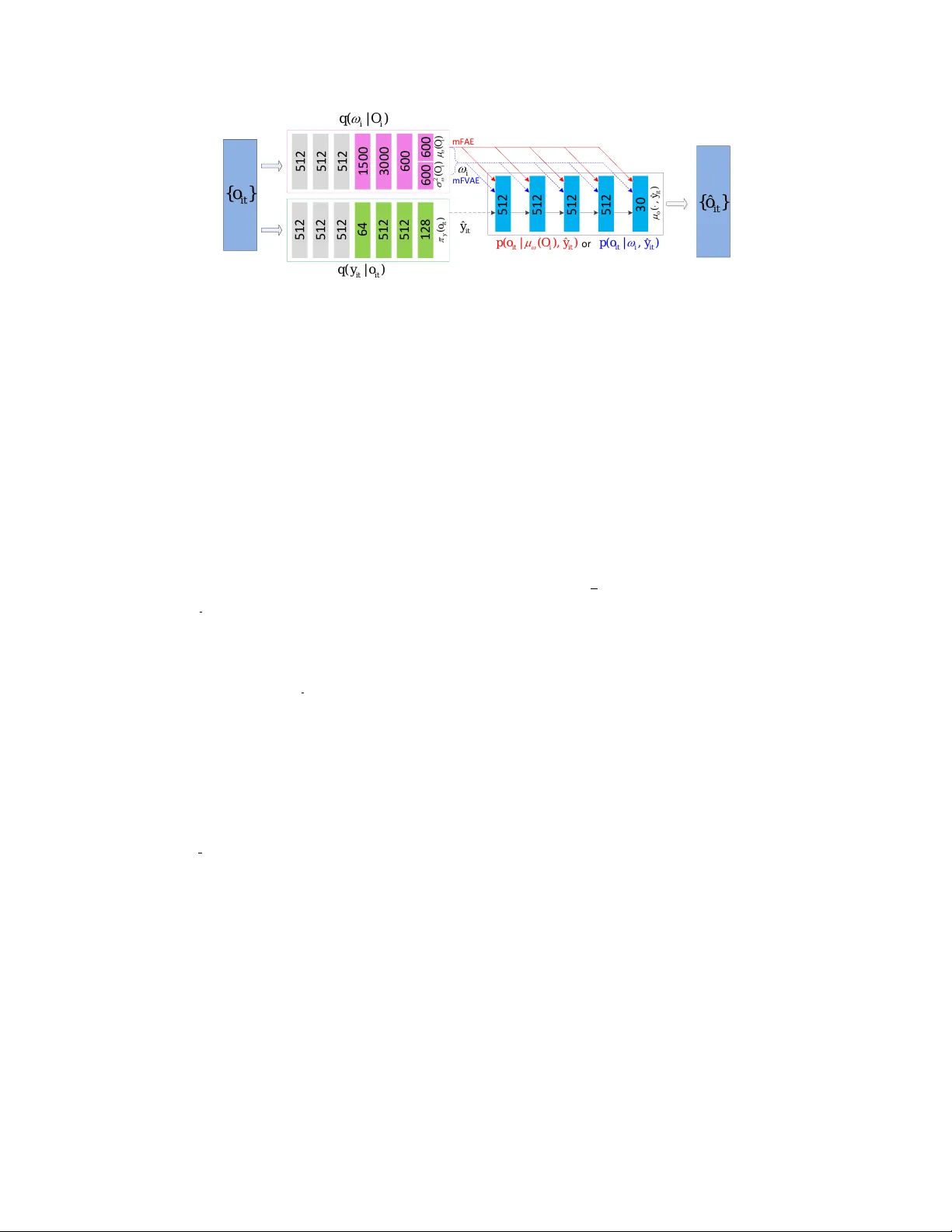
음성 신호는 언어적 내용(음소·단어)과 화자·감정·채널 등 비언어적 요인이 복합적으로 얽혀 있다. 기존 연구들은 이러한 요인을 연속형 잠재 변수로 모델링했지만, 언어 요인은 본질적으로 이산적이며, 연속형 표현을 사용하면 언어와 비언어 정보가 섞여 ‘posterior collapse’ 현상이 발생한다. 이를 해결하고자 저자들은 ‘혼합 요인화 자동인코더(mFAE)’를 제안한다. mFAE는 두 단계의 인코더와 하나의 디코더로 구성된다. 첫 번째 인코더인 프레임 토크나이저는 각 프레임을 K개의 카테고리 중 하나에 할당하는 소프트 믹스처(soft mixture) 라벨 π_y(oₜ)를 생성한다. Gumbel‑Softmax 기법을 이용해 차별화 가능한 이산 라벨 ŷₜ를 샘플링함으로써, 언어 요인을 명시적인 이산 변수로 만든다. 두 번째 인코더인 발화 임베더는 전체 발화를 요약하는 600‑dim 연속 벡터 μ_ω(O)를 출력한다. 기존 변분 오토인코더(mFVAE)에서 사용되던 KL 정규화(μ_ω에 대한 표준 정규, ŷₜ에 대한 균등 카테고리)를 전면 삭제하고, μ_ω를 가우시안 잡음 없이 결정론적으로 사용한다. 이는 발화 임베더가 화자 특성을 충분히 담을 수 있게 하며, 디코더가 μ_ω와 ŷₜ를 결합해 프레임 ôₜ를 재구성하도록 만든다. 손실 함수는 단순히 재구성 MSE만을 사용해 학습을 진행한다. 이 설계는 계산 복잡도를 O(B·L·K)로 낮추고, 학습 안정성을 높인다.
실험은 두 가지 과업으로 진행되었다. 첫 번째는 VoxCeleb1을 이용한 화자 검증이다. 30‑dim MFCC를 입력으로 사용하고, ADAM 옵티마이저로 50 epoch 학습하였다. 학습 후 발화 임베딩 μ_ω(O)는 LDA로 600→150 차원 축소, 길이 정규화, PLDA 스코어링 순으로 처리된다. 결과는 mFAE가 EER 7.2 %와 mDCF 0.595를 달성했으며, 이는 x‑vector 기반 시스템(≈6.9 %/0.55)와 거의 동등한 수준이다. KL 정규화 계수를 조정한 mFVAE와 비교했을 때, 정규화를 제거한 mFAE가 화자 정보 추출에 더 유리함을 확인하였다. 두 번째는 ZeroSpeech 2017 데이터셋을 이용한 무지도 서브워드 모델링이다. 여기서는 프레임 토크나이저가 생성한 이산 라벨을 사용해 ABX 테스트를 수행했으며, 기존 연속형 베이스라인보다 낮은 오류율을 기록했다. 이는 프레임 토크나이저가 음소 수준의 언어 정보를 효과적으로 포착함을 의미한다.
전체적으로, 본 논문은 (1) 언어 요인을 이산 토큰으로 명시화하고, (2) 정규화 손실을 제거해 발화 임베더가 화자 정보를 자유롭게 학습하도록 함으로써, 무지도 환경에서도 언어·화자 요인 분리를 성공적으로 수행한다는 점에서 의미가 크다. 또한, 복잡한 다단계 사전학습 없이도 실용적인 화자 검증 성능을 달성했으며, 향후 음성 합성, 변환, 다언어 인식 등 다양한 응용 분야에 적용 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기