Mixture factorized auto-encoder for unsupervised hierarchical deep factorization of speech signal
Speech signal is constituted and contributed by various informative factors, such as linguistic content and speaker characteristic. There have been notable recent studies attempting to factorize speech signal into these individual factors without req…
Authors: Zhiyuan Peng, Siyuan Feng, Tan Lee
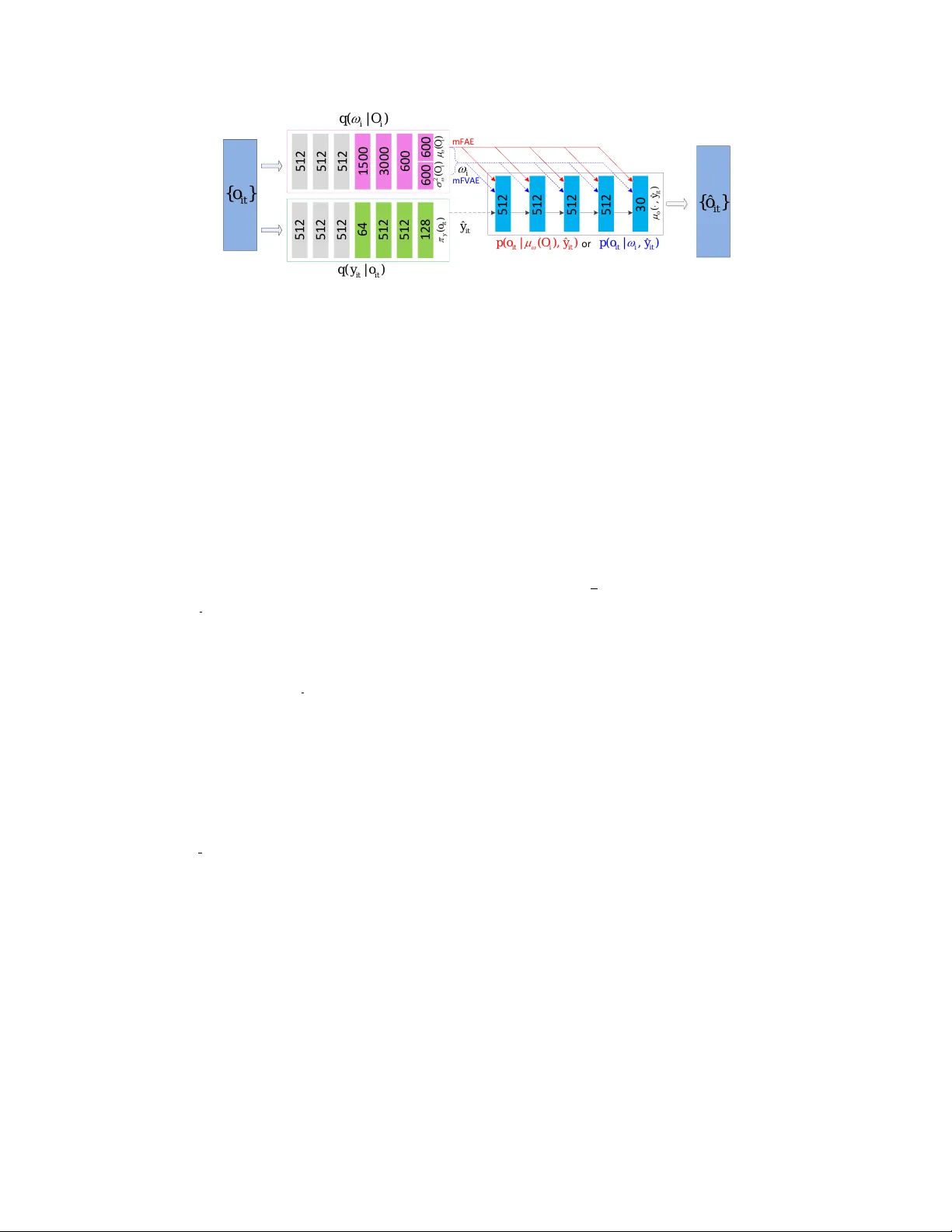
MIXTURE F A CTORIZED A UT O-ENCODER FOR UNSUPER VISED HIERARCHICAL DEEP F A CTORIZA TION OF SPEECH SIGNAL Zhiyuan P eng † , Siyuan F eng † , T an Lee † † Department of Electronic Engineering, The Chinese Uni versity of Hong K ong, Hong K ong SAR, China jerrypeng1937@gmail.com, siyuanfeng@link.cuhk.edu.hk, tanlee@ee.cuhk.edu.hk ABSTRA CT Speech signal is constituted and contributed by v arious infor- mativ e factors, such as linguistic content and speaker characteris- tic. There hav e been notable recent studies attempting to factorize speech signal into these individual factors without requiring any an- notation. These studies typically assume continuous representation for linguistic content, which is not in accordance with general lin- guistic knowledge and may make the extraction of speaker infor- mation less successful. This paper proposes the mixture factorized auto-encoder (mF AE) for unsupervised deep factorization. The en- coder part of mF AE comprises a frame tokenizer and an utterance embedder . The frame tokenizer models linguistic content of input speech with a discrete categorical distribution. It performs frame clustering by assigning each frame a soft mixture label. The utter- ance embedder generates an utterance-level vector representation. A frame decoder serves to reconstruct speech features from the en- coders’ outputs. The mF AE is e valuated on speaker verification (SV) task and unsupervised subword modeling (USM) task. The SV ex- periments on V oxCeleb 1 show that the utterance embedder is ca- pable of extracting speak er-discriminati ve embeddings with perfor - mance comparable to a x-vector baseline. The USM experiments on ZeroSpeech 2017 dataset verify that the frame tokenizer is able to capture linguistic content and the utterance embedder can acquire speaker -related information. Index T erms — unsupervised deep factorization, mixture factor- ized auto-encoder , speaker verification, unsupervised subword mod- eling 1. INTR ODUCTION Speech signal contains a rich array of information, including lin- guistic information, e.g., phonetic content, and paralinguistic infor- mation, e.g., speaker, emotion, channel distortion, etc. Research on extracting and identifying these information from speech has been abundant. In this paper, the above different aspects of information are regarded as the underlying factors that jointly contribute to the realization of speech. These informative factors are closely coupled such that the y can not be separated using a shallow model with ex- plicit formulations for factorization. Recently , deep encoders hav e shown effecti veness in factor extraction through a feature learning process. Examples of these features include linguistic features for unsupervised acoustic unit discov ery [1], affect-salient features for speech emotion recognition (SER) [2], noise-robust speak er embed- dings for speak er recognition (SRE) [3] and phonetically-a ware bot- tleneck features for language recognition (LRE) [4]. This moti vates in vestigations on deep f actorization of speech signal [5–9]. One of the representative ideas in realizing deep factorization is to infer multiple speech factors in a sequential manner, i.e., fac- S p e e c h f e a t u r e s {} it o () it it o U t t e r a n c e E m b e d d e r () it it o F r a m e T o k e n i z e r F r a m e D e c o d e r ( , ) i it y S a m p l i n g S p e e c h f e a t u r e s {} it o U t t e r a n c e E m b e d d e r F r a m e T o k e n i z e r F r a m e D e c o d e r S a m p l i n g R e c o n s t r u c t e d f e a t u r e s ˆ {} it o S p e e c h f e a t u r e s {} it o U t t e r a n c e E m b e d d e r F r a m e T o k e n i z e r F r a m e D e c o d e r S a m p l i n g R e c o n s t r u c t e d f e a t u r e s ˆ {} it o Fig. 1 : General frame work of mixture factorized auto-encoder tors previously inferred are used as conditional variables in subse- quent inference of other factors [5, 9]. In [5], speaker factor e xtrac- tor is trained based on the output of a pre-trained ASR system. The multiple-step training strategy is not efficient and may lead to sub- optimal factorization results. A follo w-up study adopted multi-task learning to jointly train factor extractors [6]. This approach requires multiple task-related speech datasets with annotations. In speech re- search, the amount of un-annotated data is much greater than that of annotated ones. T o leverage the massiv e un-annotated data, at- tempts to unsupervised deep factorization were made [7, 8]. There are two major assumptions made in these attempts. Under the first assumption, linguistic information in a speech utterance could be represented by a dynamic factor , while paralinguistic information is represented by a stationary factor . This led a hierarchical design of factor extractors, i.e., having one extractor operating at frame level (frame encoder) to generate the linguistic factor , and the other at ut- terance level (utterance embedder) to capture the paralinguistic fac- tor . The second assumption is that the linguistic factor can be de- scribed by a continuous representation. W e argue that this is not in accordance with general linguistic kno wledge. Linguistic represen- tation is discrete by nature. Phonetic units are cate gorically defined. Speech transcriptions are sequences of discrete words or phonetic units. In a preliminary experiment, we observed that assuming con- tinuous factor representation in the frame encoder would cause par - alinguistic information to be partly absorbed by the frame encoder , making the utterance embedder fail to learn informativ e representa- tion. It is kno wn as posterior collapse [10], meaning that the decoder learns to ignore a subset of encoded v ariables. A straightforward so- lution is to add a discriminative loss term [7] to obtain a more in- formativ e utterance embedder . Ho wever , this solution requires high computational cost and an additional hyper-parameter for tuning. In the present study , a nov el design of mixture factorized auto- encoder (mF AE) is proposed for unsupervised deep factorization. It follows the hierarchical design of factor extractors and assumes dis- crete representation of linguistic factor . As depicted in Figure 1, the mF AE consists of three components: frame tokenizer , utterance embedder and frame decoder . Given a sequence of speech features, the frame tokenizer assigns each frame a soft mixture label (mix- ture posterior), which constitutes the linguistic factor . The utterance embedder generates a vector representation of the whole sequence, which desirably captures the paralinguistic factor . The frame de- coder reconstructs a speech frame from the utterance embedding and the respecti ve frame representation. The frame representation is an appr oximation of the one-hot vector sampled from the mixture pos- terior . The sampling plays the key role in the proposed mF AE. It can be regarded as performing vector quantization of the mixture poste- rior and thus lays the discrete nature of linguistic factor . The three components are jointly trained with the mean-squared error loss. The mF AE is a simplified variant of mixture factorized varia- tional auto-encoder (mFV AE). The thoughts behind the simplifica- tions are rich as we will explain in the ne xt section. 2. MIXTURE F A CTORIZED A UTO-ENCODER 2.1. Formulation of mFV AE i it o i T N it y i it o i T N it y (a) Generativ e model 1 i it o i T N it y i it o i T N it y (b) Inference model Fig. 2 : Graphical illustration of the proposed mFV AE. The shaded circles represent observ ed speech features o it . The white circles rep- resent latent variables. Giv en a set of N i.i.d speech utterances D = { O i } N i =1 , where the i -th utterance O i = { o it } T i t =1 consists of T i frames, the mFV AE assumes that O i is generated by the following process: 1. A sequence vector ω i is generated from a Gaussian distrib u- tion p ( ω ) = N ( ω | 0 , I ) . 2. A sequence of i.i.d. one-hot mixture indicators Y i = { y it } T i t =1 is drawn from a Categorical distribution p ( y ) = Cat ( π ) , where π = { π k = 1 K } K k =1 . 3. Each frame o it in O i is generated from p ( o | ω i , y it ) = N ( o | µ o ( ω i , y it ) , I ) . The generativ e process is illustrated in Figure 2a. The joint proba- bility of { O i , Y i , ω i } is f actorized as, p ( O i , Y i , ω i ) = p ( ω i ) T i Y t =1 p ( y it ) p ( o it | ω i , y it ) . (1) Similar to the V AE framework [12], the mFV AE requires an infer- ence model q ( ω i , Y i | O i ) to approximate the intractable posterior p ( ω i , Y i | O i ) . W e consider the following inference model as illus- trated in Figure 2b, q ( ω i , Y i | O i ) = q ( ω i | O i ) T i Y t =1 q ( y it | o it ) , (2) 1 The generativ e model is almost the same as that of i-vector method [11], except that p ( o it | ω i , y it ) is parameterized by a neural network to charac- terize the non-linear relationship between ω i and y it . 2 The uniform regularization refers to D K L ( q ( y it ) || p ( y it )) . It can be proved that E p ( o it ) [ D K L ( q ( y it | o it ) || p ( y it ))] ≥ D K L ( q ( y it ) || p ( y it )) and min E p ( o it ) [ D K L ( q ( y it | o it ) || p ( y it ))] = min K L ( q ( y it ) || p ( y it )) . where q ( ω i | O i ) = N ( ω i | µ ω ( O i ) , σ 2 ω ( O i )) and q ( y it | o it ) = Cat ( π y ( o it )) . The functions { µ o ( · , · ) , µ ω ( · ) , σ 2 ω ( · ) , π y ( · ) } are all parameterized by neural networks. Similar to the Joint-V AE frame- work [13], the loss function for training mFV AE is the negati ve v ari- ational lower -bound, −L mFV AE ( D ) = N X i =1 E q ( ω i , Y i | O i ) [ − log p ( O i | ω i , Y i )] + β ω N X i =1 D K L [ q ( ω i | O i ) || p ( ω i )] + β y N X i =1 T i X t =1 D K L [ q ( y it | o it ) || p ( y it )] . (3) 2.2. From mFV AE to mF AE 2.2.1. Discard r egularization losses The loss function −L mFV AE ( D ) has tw o components: the reconstruc- tion loss E q ( ω i , Y i | O i ) [ − log p ( O i | ω i , Y i )] and the factor regular - ization losses D K L [ q ( ω i | O i ) || p ( ω i )] , D K L [ q ( y it | o it ) || p ( y it )] . The reconstruction loss measures the e xpectation of L 2 distance be- tween the input speech feature o it and the reconstructed one ˆ o it ov er the latent variables ω i , y it . W ith this loss, the encoders q ( y it | o it ) and q ( ω i | O i ) are forced to encode linguistic (frame level) and paralinguistic factors (utterance level) respectively . The factor reg- ularization losses measure the KL distances between the informa- tiv e posteriors q ( ω i | O i ) , q ( y it | o it ) and the non-informativ e priors p ( ω i ) , p ( y it ) . With these losses, the latent variables are forced to conform the following priors: Prior 1 ω i follows standar d Gaussian distribution; Prior 2 y it follows uniform Cate gorical distribution. As justified in the next tw o paragraphs, these two priors are incompatible with the intended function of mFV AE: to factorize speech into linguistic factor and paralinguistic factor . W e propose to remov e the regularization losses so as to get rid of the two incom- patible priors. For Prior 1: (1) Standard Gaussian distribution assumes the in- dependence between the dimensions of sequence vector ω i . This assumption is unnecessary for ω i to capture paralinguistic informa- tion; (2) Requiring ω i to conform Gaussian distribution may be ben- eficial to weak back-end classifiers. But a recent study [14] showed that the benefit vanishes when using strong discriminant back-ends like linear discriminant analysis (LD A) incorporated with Proba- bilistic LD A (PLDA); (3) The first regularization loss makes ω i less informativ e, which is against our goal; (4) A concern about removing the regularization loss is that ω i may contain dynamic linguistic in- formation, making the frame decoder ignore y it . This issue could be solved by using a feed-forw ard neural network as the frame decoder , because a feed-forward neural network is unable to reconstruct the whole utterance from only a sequence vector ω i . For Prior 2: (1) The second regularization loss serves as a soft constraint to pre vent q ( y it | o it ) being de viating too much from p ( y it ) and in this way it constraints the information y it con ve yed to the decoder p ( o it | ω i , y it ) . In our model, y it is a one-hot vector so that the amount of information being con veyed is constrained to be less than log 2 ( K ) bit. (2) A potential problem of discarding the regularization loss is that the uniform regularization of the mixture weight vector q ( y it ) is also remov ed 2 . This uniform regularization {} it o ( | ) ii qO ( | ) it it q y o i 2 () i O () i O () y it o ˆ ( , ) o it y 5 1 2 5 1 2 5 1 2 1 5 0 0 3 0 0 0 6 0 0 6 0 0 6 0 0 5 1 2 5 1 2 5 1 2 6 4 5 1 2 5 1 2 1 2 8 5 1 2 5 1 2 5 1 2 5 1 2 3 0 m F A E m F V A E ˆ ( | ( ) , ) it i it p o O y ˆ ( | , ) it i it p o y o r ˆ {} it o ˆ it y Fig. 3 : Network structure of mFV AE/mF AE. The numbers are the layer output dimensions. The dashed lines represent sampling ˆ y it and ω i from distribution parameterized by neural netw orks. The frame decoder is p ( o it | µ ω ( O i ) , ˆ y it ) for mF AE or p ( o it | ω i , ˆ y it ) for mFV AE. turns out to maximize the average amount of information (entropy) being con ve yed by q ( y it | o it ) . Keeping this uniform regularization may encourage a more informative q ( y it | o it ) . Ho wev er , no notice- able benefit to factorization is found in our preliminary experiments. 2.2.2. Replace N ( ω i | µ ω ( O i ) , σ 2 ω ( O i )) with δ µ ω ( O i ) ( ω i ) ω i can be represented as µ ω ( O i ) being corrupted by a Gaussian noise N ( 0 , σ 2 ω ( O i )) . The noise variance σ 2 ω ( O i ) parameterized by neural network tends to 0 when only the reconstruction loss is being minimized. This trend is resisted by heavy penalization of the factor regularization term D K L [ q ( ω i | O i ) || p ( ω i )] around σ 2 ω ( O i ) = 0 . As a consequence of discarding the regularization term, the pos- terior N ( µ ω ( O i ) , σ 2 ω ( O i )) becomes spiky . W e use an impulse δ µ ω ( O i ) ( ω i ) to approximate it. Thus the reconstruction loss can be simplified as L sim rec = E q ( Y i | O i ) [ − log p ( O i | µ ω ( O i ) , Y i )] . 2.2.3. Apply reparameterization for Cat ( π y ( o it )) The simplified reconstruction loss L sim rec is computational tractable for mini-batch stochastic gradient descent. Its computation complex- ity is O ( B LK 2 ) where B denotes the number of speech utterances in each batch and L is the av erage number of frames per utterance. W e attempt to reduce the computation complexity to O ( B LK ) in order to speed up the training on large-scale datasets. Sampling y it from q ( y it | o it ) is easy . A typical solution is to apply the Gumbel-Max trick [15], y it = one hot argmax k [log( π y ( o it )) + g ] , (4) where g = [ g 1 , · · · , g K ] . g 1 , · · · , g K are i.i.d. samples drawn from Gumbel (0 , 1) . The problem here is how to make the one-hot vector y it differentiable for gradient back-propagation through π y ( o it ) . W e adopt the Gumbel-Softmax distribution to draw differentiable sample ˆ y it to approximate y it as proposed in [16], ˆ y it = softmax ((log ( π y ( o it )) + g ) /τ ) , (5) where the softmax temperature τ is a positive hyper -parameter . The choice of τ is a trade-off between the v ariance of reparameterization gradients and the approximation of y it . A large τ provides smooth ˆ y it , poor approximation of y it , but small v ariance of the gradients. Whilst a small τ produces ˆ y it close to one-hot but large v ariance of the gradients. As τ → 0 , q ( ˆ y it | o it ) → Cat ( π y ( o it )) = q ( y it | o it ) . In summary , the loss function of mF AE is simplified as, −L mF AE ( D ) = N X i =1 E q ( ω i , Y i | O i ) [ − log p ( O i | ω i , Y i )] ≈ N X i =1 E q ( Y i | O i ) δ µ ω ( O i ) [ − log p ( O i | ω i , Y i )] = N X i =1 T i X t =1 E q ( y it | o it ) [ − log p ( o it | µ ω ( O i ) , y it )] ≈ N X i =1 T i X t =1 − log p ( o it | µ ω ( O i ) , ˆ y it ) = 1 2 N X i =1 T i X t =1 || o it − µ o ( µ ω ( O i ) , ˆ y it ) || 2 2 + const , (6) where the trainable parameters are { µ o ( · , · ) , µ ω ( · ) , π y ( · ) } . ˆ y it is generated by Equation (5). τ is set to 0 . 1 in our experiments. 2.3. Network structure of mFV AE/mF AE The network structure of mFV AE/mF AE is implemented as sho wn in Figure 3. It consists of three components: utterance em- bedder q ( ω i | O i ) , frame tokenizer q ( y it | o it ) and frame decoder p ( o it |· , ˆ y it ) . The utterance embedder consists of four TDNN layers with contexts of [ − 2 , − 2] , {− 2 , 2 } , {− 3 , − 3 } , { 0 } , a mean+std global pooling layer across time [17], tw o feed-forward layers, a lin- ear output layer parameterizing µ ω ( O i ) and a softplus output layer parameterizing σ 2 ω ( O i ) . The frame tokenizer has four TDNN layers with the same context as those in the utterance embedder , followed by two feed-forward layers and a softmax layer that parameterizes π y ( o it ) . The frame decoder has a TDNN input layer with a context of [ − 1 , 1] , followed by a four-layer feed-forward neural network. The sequence vect or ( ω i for mFV AE and µ ω ( O i ) for mF AE) is appended to the input of each layer of p ( o it |· , ˆ y it ) . Its output layer parameterizes µ o ( · , ˆ y it ) . All layers except output layers in the three components are followed by ReLU and batch normalization. 3. EXPERIMENTS The proposed approach of deep factorization is evaluated on two tasks, namely , speaker verification and unsupervised subword mod- eling. The speaker verification task is adopted for evaluating speaker identity , a major part of paralinguistic factor , from q ( ω i | O i ) . The task of unsupervised subword modeling is chosen to e xplore the pho- netic information, a type of linguistic factor , from q ( y it | o it ) . 3.1. Speaker verification on V oxCeleb 1 V oxCeleb 1 is a large-scale public speech corpus [18]. The training set consists of 148 , 642 utterances from 1211 speakers, with a total speech duration of about 300 hours. The test set has 4 , 874 utter- ances from 40 speakers. The performance of speaker verification is ev aluated in terms of equal error rate (EER) and the minimum of normalized detection cost function (mDCF). EER refers to the rate at which both false acceptance rate and false rejection rate are equal. mDCF is a weighted sum of false acceptance rate and false rejection rate that usually penalizes more on false acceptance rate. 30-dimensional MFCCs (without cepstrum truncation) with global mean variance normalization (GMVN) are used as input fea- tures for mFV AE and mF AE. The loss function is giv en by Equation (3) for mFV AE or by Equation (6) for mF AE. W e use the AD AM optimizer for training, with a learning rate exponentially decreased from 1e-3 to 1e-4 in 50 epochs. Each batch consists of 64 randomly- trimmed segments of 3-second long. After training, utterance embeddings µ ω ( O i ) are e xtracted, preprocessed by LDA to reduce the dimension from 600 to 150, followed by length-normalization and a two-cov ariance PLDA [19] classifier for similarity scoring between embeddings. The ev aluation metrics, EER and mDCF , are computed based on these scores. The i-vector [11] and x-vector [17] baselines are established for performance comparison. The i-vector front-end includes a 2048- mixture GMM-UBM model and a 600-dim i-vector extractor . The x-vector front-end follows the standard Kaldi x-vector architecture. Their back-ends are the same as those of mF AE and mFV AE. T able 1 : EER% and mDCF with P(tar)=0.01 on V oxCeleb 1. For simplicity , there is no data augmentation in all experiments. EER% mDCF mFV AE, β y = 0 β ω = 3 11 . 48 0 . 761 β ω = 1 9 . 42 0 . 698 β ω = 0 . 01 7 . 20 0 . 595 mFV AE, β ω = 0 β y = 1 19 . 40 0 . 892 β y = 0 . 1 9 . 17 0 . 697 β y = 0 . 01 7 . 25 0 . 579 mF AE 7 . 39 0 . 589 x-vector 7 . 49 0 . 650 i-vector 5 . 51 0 . 462 The results in T able 1 show that: (1) For mFV AE with β y = 0 , the decrease of β ω leads to consistent performance improv ement in terms of both EER and mDCF . This indicates that with less penalty on ω i , the utterance embedding contains richer speaker informa- tion. (2) The performance improvement is more obvious for mF- V AE with β ω = 0 as β y decreases. A high penalty on β y stops the frame decoder to extract dynamic linguistic information from y it . This leads to a trivial solution that the reconstructed feature o it equals to the mean vector of the i -th utterance and ω i fails to capture speaker information. (3) The proposed mF AE is capable of extracting speaker-discriminant embeddings with performance com- parable to the x-vector method that requires speaker labels for super- vision. (4) The i-vector method performs the best on this dataset. It is kno wn that neural network approaches are data-hungry . With data augmentation [20] and lar ger datasets like V oxCeleb 2 [21], neu- ral network approaches achie ve better performance than the i-v ector method. Nevertheless, for applications with limited training data, i-vector warrants in-depth investig ation. This classical method may serve as a guidance for the design of neural network models. 3.2. Unsupervised subword modeling on ZeroSpeech 2017 The goal of ZeroSpeech 2017 Track 1 is to construct a frame-wise feature representation of speech sounds, which is both phoneme- discriminativ e and speaker-in variant, under the assumption that only untranscribed data are av ailable. The dataset consists of three lan- guages, namely , English, French and Mandarin. The amount of training data for the three languages are 45, 24 and 2.5 hours re- spectiv ely . The subset of test data with 10-second segment length is adopted in our study . The ABX error rate is used as the e valuation metric for both within-/across-speaker conditions [22]. The input features to mF AE are 13-dimension MFCCs with the first and the second-order time deriv ativ es followed by cepstral mean normalization (CMN) with 3-second sliding window and GMVN are fed into mF AE. The feature vector is denoted as MFCC+GMVN . The training process is the same as mentioned in Section 3.1. After the mF AE training, the reconstructed feature ˆ o it is obtained from the frame decoder conditioned on two settings: (1) per-utt: π y ( o it ) and µ ω ( O i ) ; (2) unified: π y ( o it ) and µ ω = 1 |D| P O j ∈D µ ω ( O j ) . Here D denotes the training set. The recommended baseline set-up is to ev aluate the ABX er- ror rate on MFCC features post-processed by CMN [1]. Here we provide an additional baseline using the feature MFCC+GMVN to allow a f air comparison with mF AE. T able 2 : ABX% error rates on ZeroSpeech 2017. mF AE is trained separately on three languages. English 10s French 10s Mandarin 10s within-spk across-spk within-spk across-spk within-spk across-spk MFCC 10 . 52 20 . 83 11 . 19 23 . 08 9 . 66 15 . 39 + GMVN 8 . 16 18 . 95 10 . 23 21 . 74 8 . 76 14 . 92 mF AE, per-utt 10 . 00 16 . 80 12 . 89 19 . 26 14 . 06 16 . 86 mF AE, unified 9 . 88 15 . 21 12 . 66 18 . 03 13 . 94 15 . 62 The ABX error rates on both input MFCC and reconstructed MFCC across three languages are shown in T able 2. It is found that: (1) In within-speaker condition, features reconstructed by mF AE show slight performance degradation as compared to MFCC + GMVN. A potential problem is the insufficient training of mF AE as the number of epochs is fixed to 50 for all of the three language. The degradation is more noticeable on Mandarin, which only has 2 . 5 hours of training data. (2) As µ ω is computed from the train- ing set, it doesn’t contain the dynamic linguistic information in the test utterances. Thus, the performance of ( mF AE, unified ) in within-/across-speaker conditions prov es that q ( y it | o it ) captures linguistic information. (3) The performance improv es consistently in the across-speaker condition, comparing ( mF AE, per-utt ) with ( mF AE, unified ). This shows that q ( ω i | O i ) is capable of extracting paralinguistic information. 4. CONCLUSIONS In this paper , we propose mixture factorized auto-encoder (mF AE), a scalable unsupervised hierarchical deep factorization approach to decomposing speech into paralinguistic factor and linguistic factor . The two factors are represented by a sequence vector and a frame- wise mixture indicator respectiv ely . Experiments on speaker verifi- cation and unsupervised subword modeling show that the sequence vector contains rich speaker information and mixture indicator keeps linguistic content. mF AE can be applied to many down-stream tasks, like text-to-speech and query-by-e xample spoken term detection. 5. REFERENCES [1] J. Chorowski, R. J. W eiss, S. Bengio, and A. v . d. Oord, “Unsu- pervised speech representation learning using wavenet autoencoders, ” arXiv pr eprint arXiv:1901.08810 , 2019. [2] Q. Mao, M. Dong, Z. Huang, and Y . Zhan, “Learning salient features for speech emotion recognition using conv olutional neural networks, ” IEEE transactions on multimedia , vol. 16, no. 8, pp. 2203–2213, 2014. [3] D. Snyder , D. Garcia-Romero, D. Pov ey , and S. Khudanpur, “Deep neural network embeddings for text-independent speaker verification. ” in Interspeech , 2017, pp. 999–1003. [4] L. Ferrer , Y . Lei, M. McLaren, and N. Scheffer , “Study of senone- based deep neural network approaches for spoken language recogni- tion, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr o- cessing , vol. 24, no. 1, pp. 105–116, 2015. [5] L. Li, D. W ang, Y . Chen, Y . Shi, Z. T ang, and T . F . Zheng, “Deep factorization for speech signal, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 5094–5098. [6] Y . Liu, L. He, J. Liu, and M. T . Johnson, “Speaker em- bedding extraction with phonetic information, ” in Proc. In- terspeech 2018 , 2018, pp. 2247–2251. [Online]. A vailable: http://dx.doi.org/10.21437/Interspeech.2018-1226 [7] W .-N. Hsu, Y . Zhang, and J. Glass, “Unsupervised learning of disentangled and interpretable representations from sequential data, ” in Advances in Neural Information Processing Systems 30 , I. Guyon, U. V . Luxburg, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, Eds. Curran Associates, Inc., 2017, pp. 1878–1889. [Online]. A vailable: http://papers.nips.cc/paper/6784-unsupervised- learning-of-disentangled-and-interpretable-representations-from- sequential-data.pdf [8] Y . Li and S. Mandt, “Disentangled sequential autoencoder , ” in Proceed- ings of the 35th International Confer ence on Machine Learning, ICML 2018, Stockholmsm ¨ assan, Stockholm, Sweden, July 10-15, 2018 , 2018, pp. 5656–5665. [9] T . Stafylakis, J. Rohdin, O. Plchot, P . Mizera, and L. Bur- get, “Self-Supervised Speaker Embeddings, ” in Pr oc. In- terspeech 2019 , 2019, pp. 2863–2867. [Online]. A vailable: http://dx.doi.org/10.21437/Interspeech.2019-2842 [10] J. Lucas, G. Tuck er , R. B. Grosse, and M. Norouzi, “Understanding posterior collapse in generativ e latent variable models, ” in Deep Gen- erative Models for Highly Structur ed Data, ICLR 2019 W orkshop, New Orleans, Louisiana, United States, May 6, 2019 , 2019. [11] N. Dehak, P . Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front- end f actor analysis for speaker verification, ” IEEE T rans. Audio, Speech & Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [Online]. A vailable: https://doi.org/10.1109/T ASL.2010.2064307 [12] D. P . Kingma and M. W elling, “ Auto-encoding variational bayes, ” in 2nd International Confer ence on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Tr ack Pr oceedings , 2014. [Online]. A vailable: http://arxiv .org/abs/1312.6114 [13] E. Dupont, “Learning disentangled joint continuous and discrete rep- resentations, ” in Advances in Neural Information Processing Systems , 2018, pp. 710–720. [14] Y . Zhang, L. Li, and D. W ang, “V AE-Based Regularization for Deep Speaker Embedding, ” in Pr oc. Interspeec h 2019 , 2019, pp. 4020–4024. [Online]. A vailable: http://dx.doi.org/10.21437/Interspeech.2019-2486 [15] C. J. Maddison, D. T arlow , and T . Minka, “ A ∗ sampling, ” in Advances in Neural Information Processing Systems 27 , Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W einberger , Eds. Curran Associates, Inc., 2014, pp. 3086–3094. [Online]. A v ailable: http://papers.nips.cc/paper/5449-a-sampling.pdf [16] E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax, ” in 5th International Conference on Learning Repre- sentations, ICLR 2017, T oulon, F rance, April 24-26, 2017, Conference T rack Pr oceedings , 2017. [17] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey , and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition, ” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP) . IEEE, 2018, pp. 5329–5333. [18] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large-scale speaker identification dataset, ” arXiv pr eprint arXiv:1706.08612 , 2017. [19] A. Sizov , K. A. Lee, and T . Kinnunen, “Unifying probabilistic lin- ear discriminant analysis variants in biometric authentication, ” in Joint IAPR International W orkshops on Statistical T echniques in P attern Recognition (SPR) and Structural and Syntactic P attern Recognition (SSPR) . Springer , 2014, pp. 464–475. [20] D. Sn yder , D. Garcia-Romero, A. McCree, G. Sell, D. Pove y , and S. Khudanpur , “Spoken language recognition using x-vectors, ” in Odyssey 2018: The Speaker and Language Recognition W orkshop, 26- 29 J une 2018, Les Sables d’Olonne, F rance , 2018, pp. 105–111. [21] J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition, ” arXiv preprint , 2018. [22] E. Dunbar, X. N. Cao, J. Benjumea, J. Karadayi, M. Bernard, L. Be- sacier , X. Anguera, and E. Dupoux, “The zero resource speech chal- lenge 2017, ” in 2017 IEEE Automatic Speech Recognition and Under- standing W orkshop (ASR U) . IEEE, 2017, pp. 323–330.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment