모든 데이터셋을 위한 로또 티켓 초기화 일반화
본 논문은 한 번 찾은 “winning ticket”(희소화된 서브네트워크) 초기화가 다른 이미지 데이터셋과 옵티마이저에서도 높은 성능을 유지하는지를 실험한다. 대규모 데이터셋(Imagenet, Places365)에서 얻은 티켓은 작은 데이터셋에서도 거의 동일한 정확도를 보였으며, 전역 프루닝, 늦은 리셋(late resetting) 등 최적화된 프루닝 기법이 핵심 역할을 한다. 결과적으로, 충분히 큰 데이터셋에서 학습된 티켓은 도메인 내 일반…
저자: Ari S. Morcos, Haonan Yu, Michela Paganini
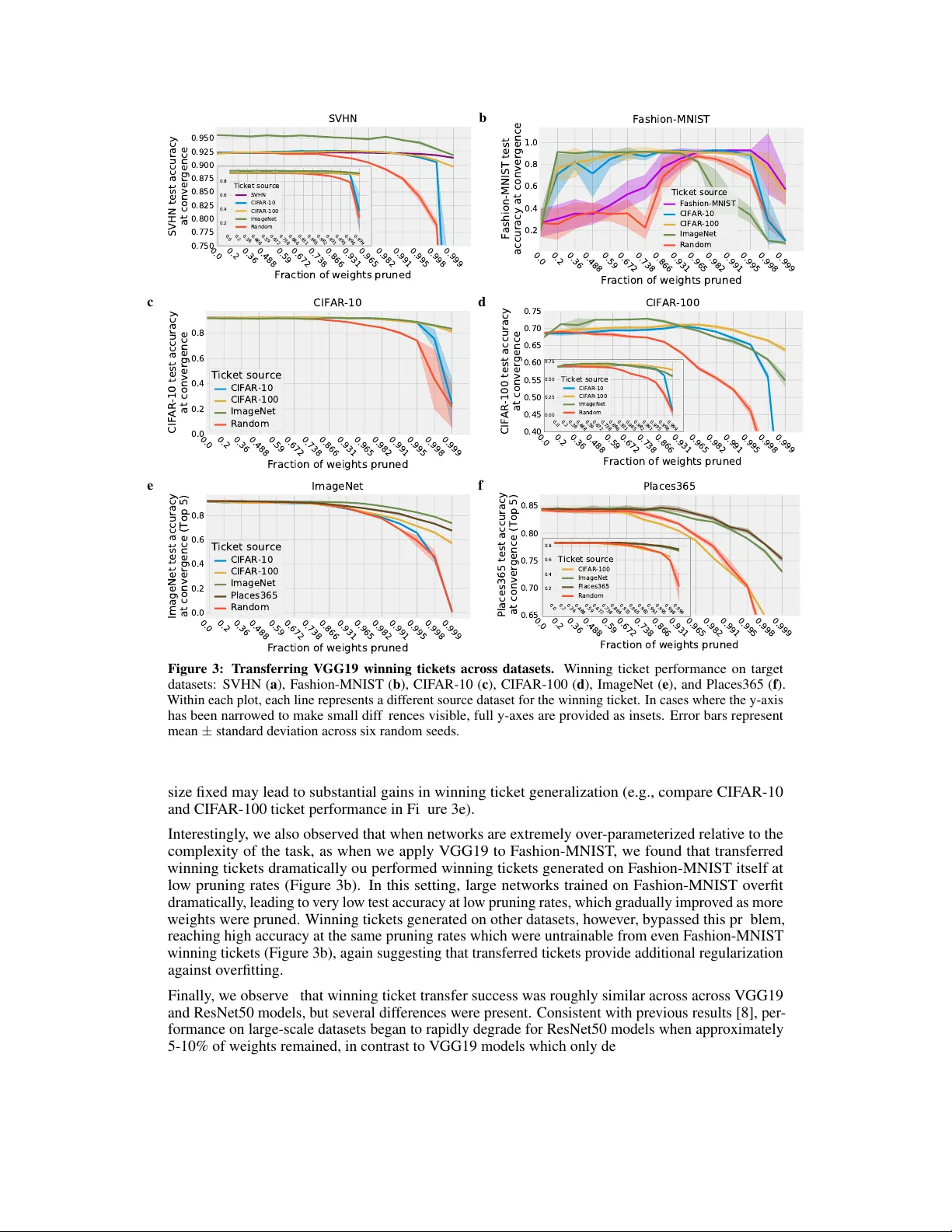
본 연구는 Lottery Ticket Hypothesis(LTH)의 실용성을 높이기 위해 “winning ticket”이라 불리는 희소화된 서브네트워크 초기화가 서로 다른 데이터셋과 옵티마이저에서도 재사용 가능한지를 체계적으로 조사한다. LTH는 과잉 파라미터화된 신경망 내부에 학습에 유리한 작은 서브네트워크가 존재한다는 가정하에, 반복적인 학습‑프루닝‑재설정 과정을 통해 이러한 서브네트워크를 찾아낸다. 그러나 이 과정은 전체 모델을 여러 번 학습해야 하므로 계산 비용이 매우 높다. 따라서 저자들은 한 번 찾은 티켓을 여러 상황에 적용함으로써 비용을 절감하고, 동시에 티켓이 내재하는 일반적인 inductive bias가 무엇인지 밝히고자 한다.
**관련 연구**에서는 LTH가 작은 모델·데이터셋에서 성공했으며, 대규모 모델·데이터셋에서는 “late resetting”과 같은 추가 기법이 필요함을 보고했다. 또한 프루닝 방법(전역 vs. 레이어별, 일회성 vs. 반복)과 마스크 구조가 티켓 성능에 미치는 영향도 논의되었다. 그러나 기존 연구는 모두 동일 데이터셋·옵티마이저 환경에서 티켓을 평가했으며, 전이 가능성에 대한 실험은 부족했다.
**방법론**은 크게 네 부분으로 구성된다. 첫째, **프루닝 전략**으로 전역 프루닝(global magnitude pruning)을 채택하고, 매 프루닝 단계마다 남은 파라미터의 20%를 순차적으로 제거한다. 전역 프루닝은 깊은 층에 더 많이 프루닝되는 경향이 있어 초기 층을 보존함으로써 표현력을 유지한다. 둘째, **늦은 리셋(late resetting)** 을 적용한다. 프루닝 후 가중치를 학습 초반(k < 전체 epoch) 시점의 값으로 되돌려, 초기 학습 단계에서 발생하는 급격한 변화에 대한 민감도를 낮춘다. 셋째, **마스크 무작위화**를 포함한 랜덤 티켓을 비교 대상으로 설정한다. 여기서는 가중치 값뿐 아니라 마스크 자체도 무작위로 섞어, 티켓이 제공하는 구조적 정보가 성능에 미치는 영향을 평가한다. 넷째, **모델 및 데이터셋**으로 VGG19 변형과 ResNet‑50을 사용하고, 자연 이미지 도메인 내 여섯 개 데이터셋(Fashion‑MNIST, SVHN, CIFAR‑10, CIFAR‑100, ImageNet, Places365)을 선택했다.
**실험 1: 동일 데이터 분포 내 전이**에서는 CIFAR‑10을 두 부분(a, b)으로 나누어 a에서 만든 티켓을 b에 적용했다. VGG19에서는 거의 동일한 정확도를 유지했으며, ResNet‑50은 극단적인 프루닝 비율(>90%)에서만 우수함을 보였다. 이는 모델 구조에 따라 티켓의 일반화 정도가 다를 수 있음을 시사한다.
**실험 2: 데이터셋 간 전이**에서는 각 데이터셋을 소스와 타깃으로 조합해 30여 개의 전이 실험을 수행했다. 대규모 데이터셋(Imagenet, Places365)에서 얻은 티켓은 다른 모든 데이터셋에 대해 99% 이상 프루닝된 상태에서도 원본 데이터셋에서 학습한 티켓과 비슷한 성능을 보였다. 반대로 작은 데이터셋(Fashion‑MNIST, SVHN)에서 만든 티켓은 대규모 타깃에 전이했을 때 성능 저하가 크게 나타났다. 이는 데이터 규모와 다양성이 티켓이 학습하는 일반적 편향을 결정한다는 결론을 뒷받침한다.
**실험 3: 옵티마이저 간 전이**에서는 동일 티켓을 SGD와 Adam 두 옵티마이저에 적용했다. 대부분의 프루닝 비율에서 두 옵티마이저 모두 비슷한 정확도를 기록했으며, 특히 높은 프루닝 비율(>80%)에서 차이가 거의 없었다. 이는 티켓이 특정 옵티마이저에 과도하게 의존하지 않음을 의미한다.
**결과 요약**은 다음과 같다. (1) 전역 프루닝과 늦은 리셋을 결합하면 99% 이상 프루닝된 극단적인 희소 모델에서도 안정적인 학습이 가능하다. (2) 대규모 데이터셋에서 학습된 티켓은 같은 도메인 내 다양한 데이터셋과 옵티마이저에 일반화될 수 있다. (3) 작은 데이터셋에서 만든 티켓은 일반화 능력이 제한적이며, 전이 효율이 낮다. (4) 랜덤 마스크를 포함한 비교 실험을 통해 티켓이 제공하는 구조적 정보가 성능 향상에 크게 기여한다는 점을 확인했다.
**의의 및 향후 연구**에서는 (i) “데이터‑독립적 초기화 분포”를 설계해 사전 학습된 티켓을 바로 사용할 수 있는 프레임워크 구축, (ii) 다양한 도메인(예: 자연어, 시계열)으로 일반화 가능성을 탐색, (iii) 프루닝 비율과 구조를 최적화해 메모리·연산 효율을 극대화하는 방법론 개발 등을 제안한다. 궁극적으로, 본 연구는 LTH가 단순한 이론적 현상이 아니라, 실제 시스템에서 비용을 절감하고 성능을 유지할 수 있는 실용적인 초기화 전략으로 확장될 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기