One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers
The success of lottery ticket initializations (Frankle and Carbin, 2019) suggests that small, sparsified networks can be trained so long as the network is initialized appropriately. Unfortunately, finding these "winning ticket" initializations is com…
Authors: Ari S. Morcos, Haonan Yu, Michela Paganini
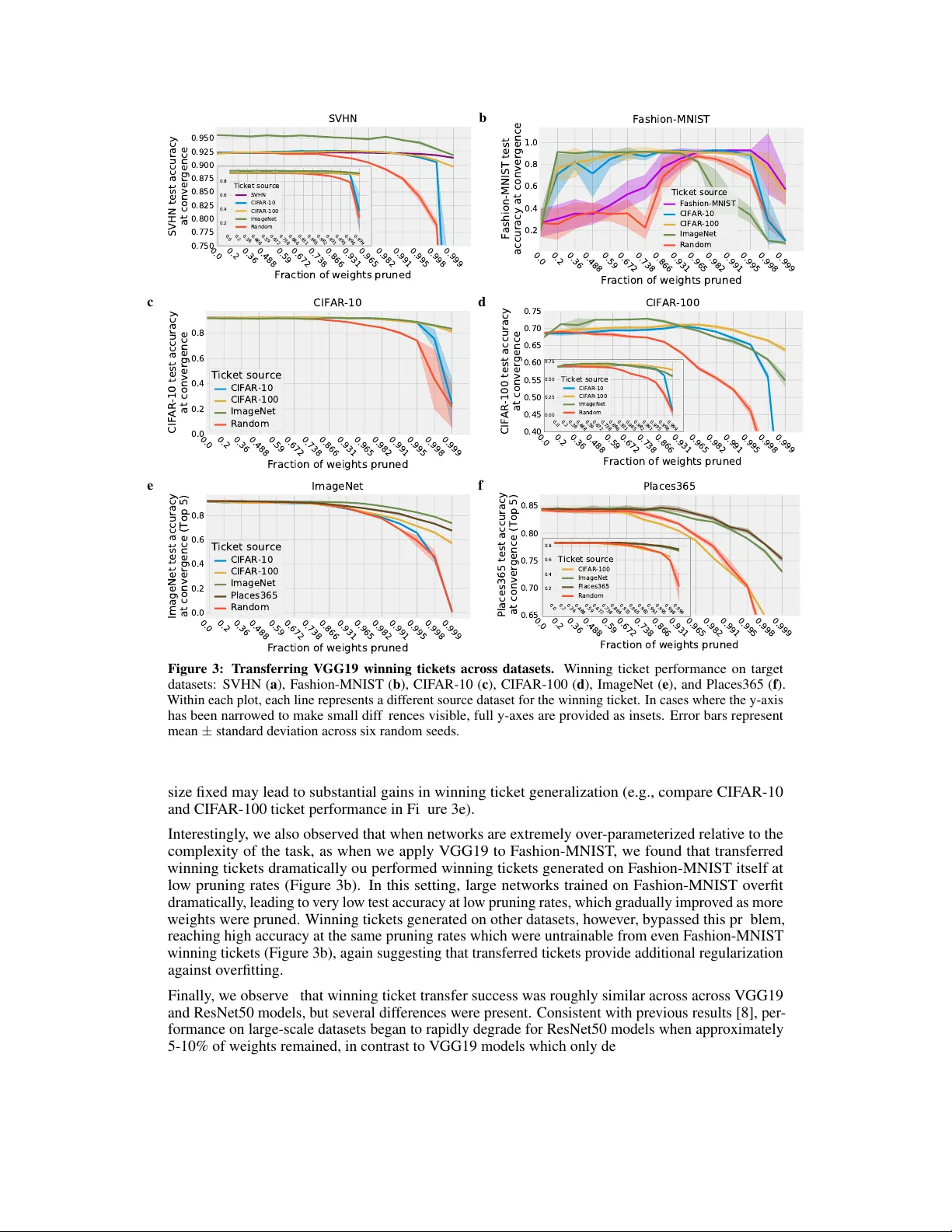
One ticket to win them all: generalizing lottery ticket initializations acr oss datasets and optimizers Ari S. Morcos ∗ Facebook AI Research arimorcos@fb.com Haonan Y u Facebook AI Research haonanu@gmail.com Michela Paganini Facebook AI Research michela@fb.com Y uandong Tian Facebook AI Research yuandong@fb.com Abstract The success of lottery tick et initializations [ 7 ] suggests that small, sparsified net- works can be trained so long as the network is initialized appropriately . Unfortu- nately , finding these “winning ticket” initializations is computationally e xpensi ve. One potential solution is to reuse the same winning tickets across a v ariety of datasets and optimizers. Howe ver , the generality of winning tick et initializations remains unclear . Here, we attempt to answer this question by generating winning tickets for one training configuration (optimizer and dataset) and e valuating their performance on another configuration. Perhaps surprisingly , we found that, within the natural images domain, winning ticket initializations generalized across a vari- ety of datasets, including Fashion MNIST , SVHN, CIF AR-10/100, ImageNet, and Places365, often achieving performance close to that of winning tick ets generated on the same dataset. Moreov er , winning tickets generated using larger datasets consistently transferred better than those generated using smaller datasets. W e also found that winning ticket initializations generalize across optimizers with high performance. These results suggest that winning ticket initializations generated by suf ficiently large datasets contain inducti ve biases generic to neural networks more broadly which impro ve training across many settings and provide hope for the dev elopment of better initialization methods. 1 Introduction The recently proposed lottery ticket hypothesis [ 7 , 8 ] argues that the initialization of ov er- parameterized neural networks contains much smaller sub-netw ork initializations, which, when trained in isolation, reach similar performance as the full network. The presence of these “lucky” sub-network initializations has se veral intriguing implications. First, it suggests that the most com- monly used initialization schemes, which ha ve primarily been disco vered heuristically [ 10 , 14 ], are sub-optimal and hav e significant room to improve. This is consistent with work which suggests that theoretically-grounded initialization schemes can enable the training of e xtremely deep networks with hundreds of layers [ 13 , 27 , 29 , 33 , 35 ]. Second, it suggests that o ver -parameterization is not necessary during the course of training as has been ar gued pre viously [ 1 , 2 , 5 , 6 , 24 , 25 ], but rather ov er-parameterization is merely necessary to find a “good” initialization of an appropriately parame- terized network. If this hypothesis is true, it indicates that by training and performing inference in networks which are 1-2 orders of magnitude lar ger than necessary , we are wasting lar ge amounts of ∗ T o whom correspondence should be addressed 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouver , Canada. computation. T aken together , these results hint to ward the de velopment of a better , more principled initialization scheme. Howe ver , the process to find winning tick ets requires repeated cycles of alternating training (poten- tially large) models from scratch to con vergence and pruning, making winning tickets computationally expensi ve to find. Moreov er , it remains unclear whether the properties of winning tick ets which lead to high performance are specific to the precise combination of architecture, optimizer , and dataset, or whether winning tickets contain inducti ve biases which improv e training more generically . This is a critical distinction for evaluating the future utility of winning ticket initializations: if winning tickets are ov erfit to the dataset and optimizer with which they were generated, a new winning tick et would need to be generated for each no vel dataset which w ould require training of the full model and iterativ e pruning, significantly blunting the impact of these winning tickets. In contrast, if winning tickets feature more generic inducti ve biases such that the same winning ticket generalizes across training conditions and datasets, it unlocks the possibility of generating a small number of such winning tickets and reusing them across datasets. Further , it hints at the possibility of parameterizing the distribution of such tick ets, allowing us to sample generic, dataset-independent winning tick ets. Here, we inv estigate this question by asking whether winning tick ets found in the conte xt of one dataset improve training of sparsified models on other datasets as well. W e demonstrate that individual winning tickets which impro ve training across many natural image datasets can be found, and that, for many datasets, these transferred winning tickets performed almost as well as (and in some cases, better than) dataset-specific initializations. W e also sho w that winning tickets generated by larger datasets (both with more training samples and more classes) generalized across datasets substantially better than those generated by small datasets. Finally , we find that winning tickets can also generalize across optimizers, confirming that dataset- and optimizer-independent winning tick et initializations can be generated. 2 Related work Our work is most directly inspired by the lottery ticket hypothesis, which argues that the probability of sampling a lucky , trainable sub-network initialization grows with netw ork size due to the com- binatorial explosion of a vailable sub-network initializations. The lottery tick et hypothesis was first postulated and examined in smaller models and datasets in [ 7 ] and analyzed in large models and datasets, leading to the de velopment of late resetting, in [ 8 ]. The lottery ticket hypothesis has recently been challenged by [ 20 ], which argued that, if randomly initialized sub-networks with structured pruning are scaled appropriately and trained for long enough, they can match performance from winning tickets. [ 9 ] also e valuated the lottery ticket hypothesis in the conte xt of large-scale models and were unable to find successful winning tickets, although, critically , they did not use iterati ve pruning and late resetting, both of which ha ve been found to be necessary to induce winning tick ets in large-scale models. Ho wev er , all of these studies have only in vestigated situations in which winning tickets are e valuated in an identical setting to that in which they generated, and therefore do not measure the generality of winning tickets. This work is also strongly inspired by the model pruning literature as well, as the choice of pruning methodology can hav e large impacts on the structure of the resultant winning tick ets. In particular , we use magnitude pruning, in which the lo west magnitude weights are pruned first, which was first proposed by [ 12 ]. A number of variants hav e been proposed as well, including structured v ariants [ 19 ] and those which enable pruned weights to recover during training [ 11 , 37 ]. Many other pruning methods hav e been proposed, including greedy methods [ 22 ], methods based on variational dropout [21], and those based on the similarity between the activ ations of feature maps [3, 28]. T ransfer learning has been studied extensiv ely with many studies aiming to transfer learned represen- tations from one dataset to another [ 17 , 31 , 34 , 38 ]. Pruning has also been analyzed in the context of transfer learning, primarily by fine-tuning pruned networks on no vel datasets and tasks [ 22 , 37 ]. These results ha ve demonstrated that training models on one dataset, pruning, and then fine-tuning on another datasets can often result in high performance on the transfer dataset. Ho we ver , in contrast to the present w ork, these studies in vestigate the transfer of learned r epr esentations , whereas we analyze the transfer of initializations across datasets. 2 a 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.70 0.75 0.80 0.85 0.90 CIFAR-10 test accuracy at convergence Global vs. layerwise Ticket source Global WT Layerwise WT Random b Figure 1: Global vs. lay erwise pruning. ( a ) CIF AR-10 winning ticket performance for global pruning (blue) vs. layerwise pruning (red) along with a random ticket (red). Error bars represent mean ± standard de viation across six random seeds. ( b ) Ratio of global pruning rate to layerwise pruning rate at each con volutional layer in VGG19. Level represents the pruning iteration such that lighter blues represent lower overall pruning rates, while the darkest blue represents a 0.999 ov erall pruning rate. 3 A pproach 3.1 The lottery ticket hypothesis The lottery ticket hypothesis proposes that "lucky" sub-netw ork initializations are present within the initializations of ov er-parameterized netw orks which, when trained in isolation, can reach the same or , in some cases, better test accurac y than the full model, e ven when over 99% of the parameters hav e been removed [ 7 ]. This effect is also present for large-scale models trained on ImageNet, suggesting that this phenomenon is not specific to small models [ 7 ]. In the simplest method to find and ev aluate winning tickets, models are trained to con vergence, pruned, and then the set of remaining weights are reset to their v alue at the start of training. This smaller model is then trained to con vergence again (“winning ticket”) and compared to a model with the same number of parameters but randomly dra wn initial parameter v alues (“random ticket”). A good winning ticket is one which significantly outperform random tickets. Ho we ver , while this straightforward approach finds good winning tickets for simple models and datasets (e.g., MLPs trained on MNIST), this method fails for more complicated architectures and datasets, which require several “tricks” to generate good winning tickets: Iterative pruning When models are pruned, they are typically pruned according to some criterion (see related work for more details). While these pruning criteria can often be effecti ve, they are only rough estimates of weight importance, and are often noisy . As such, pruning a large fraction of weights in one step (“one-shot pruning”) will often prune weights which were actually important. One strategy to combat this issue is to instead perform many iterations of alternately training and pruning, with each iteration pruning only a small fraction of weights [ 12 ]. By only pruning a small fraction of weights on each iteration, iterativ e pruning helps to de-noise the pruning process, and produces substantially better pruned models and winning tickets [ 7 , 8 ]. For this work, we used magnitude pruning with an iterativ e pruning rate of 20% of remaining parameters. Late resetting In the initial in vestigation of lottery tickets, winning ticket weights were reset to their values at the beginning of training (training iteration 0), and learning rate warmup was found to be necessary for winning tickets on large models [ 7 ]. Howe ver , in follow-up work, Frankle et al. [8] found that simply resetting the winning ticket weights to their v alues at training iteration k , with k much smaller than the number of total training iterations consistently produces better winning tickets and remov es the need for learning rate w armup. This approach has been termed “late resetting. ” In this work, we independently confirmed the importance of late resetting and used late resetting for all experiments (See Appendix A.1 for the precise late resetting v alues used for each experiment). Global pruning Pruning can be performed in two different ways: locally and globally . In local pruning, weights are pruned within each layer separately , such that ev ery layer will ha ve the same fraction of pruned parameters. In global pruning, all layers are pooled together prior to pruning, 3 allowing the pruning fraction to v ary across layers. Consistently , we observed that global pruning leads to higher performance than local pruning (Figure 1a). As such, global pruning is used throughout this work. Interestingly , we observed that global magnitude pruning preferentially prunes weights in deeper layers, leaving the first layer in particular relativ ely unpruned (Figure 1b; light blues represent early pruning iterations with lo w ov erall pruning fractions while dark blues represent late pruning iterations with high pruning fractions). An intuitiv e explanation for this result is that because deeper layers ha ve man y more parameters than early layers, pruning at a constant rate harms early layers more since the y ha ve fe wer absolute parameters remaining. For e xample, the first layer of VGG19 contains only 1792 parameters, so pruning this layer at a rate of 99% would result in only 18 parameters remaining, significantly harming the expressi vity of the network. Random masks In the sparse pruning setting, winning ticket initializations contain two sources of information: the values of the remaining weights and the structure of the pruning mask. In pre vious work [ 7 – 9 ], the structure of the pruning mask was maintained for the random tick et initializations, with only the values of the weights themselves randomized. Ho wev er , the structure of this mask contains a substantial amount of information and requires fore-knowledge of the winning ticket initialization (see Figure A1 for detailed comparisons of different random masks). For this work, we therefore consider random tickets to hav e both randomly drawn weight values (from the initialization distribution) and randomly permuted masks. For a more detailed discussion of the impact of dif ferent mask structures, see Appendix A.2. 3.2 Models Experiments were performed using two models: a modified form of VGG19 [ 30 ] and a ResNet50 [ 15 ]. For V GG19, structure is as in [ 30 ], except all fully-connected layers were remo ved such that the last layer is simply a linear layer from a global a verage pool of the last con volutional layer to the number of output classes (as in [ 7 , 8 ]). For details of model architecture and hyperparameters used in training, see Appendix A.1. 3.3 T ransferring winning tickets across datasets and optimizers In order to ev aluate the generality of winning tickets, we generate winning tickets in one training configuration (“source”) and ev aluate performance in a different configuration (“tar get”). For many transfers, this requires changing the output layer size, since datasets have dif ferent numbers of output classes. Since the winning ticket initialization is only defined for the source architecture and therefore cannot be transferred to dif ferent topologies, we simply excluded this layer from the winning tick et and randomly reinitialized it. Since the last con v olutional layer of our models was globally a verage pooled prior to the final linear layer , changes in input dimension did not require modification to the model. For standard lottery ticket e xperiments in which the source and target dataset are identical, each iteration of training represents the winning tick et performance for the model at the current pruning fraction. Howe ver , because the source and target dataset/optimizer are dif ferent for our experiments and because we primarily care about performance on the target dataset for this study , we must re-ev aluate each winning tick et’ s performance on the target dataset, adding an additional training run for each pruning iteration. W e therefore run two additional training runs at each pruning iteration: one for the winning ticket and one for the random ticket on tar get configuration. 4 Results For all experiments, we plot test accuracy at con ver gence as a function of the fraction of pruned weights. For each curve, 6 replicates with different random seeds were run, with shaded error regions representing ± 1 standard deviation. F or comparisons on a giv en target dataset or optimizer , models were trained for the same number of epochs (see Appendix A.1 for details). 4.1 T ransfer within the same data distribution As a first test of whether winning tick ets generalize, we in vestigate the simplest form of transfer: generalization across samples dra wn from the same data distrib ution. T o measure this, we di vided 4 a 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.2 0.4 0.6 0.8 CIFAR-10b test accuracy at convergence VGG19: CIFAR-10b Ticket source CIFAR-10b CIFAR-10a Random b 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 CIFAR-10b test accuracy at convergence ResNet50: CIFAR-10b Ticket source CIFAR-10b CIFAR-10a Random Figure 2: T ransferring winning tickets within the same data distribution. CIF AR-10 was di vided into two halves (“10a” and “10b”), each of which contained 25,000 total examples with 2,500 images per class. W inning tickets generated using CIF AR-10a generalized well to CIF AR-10b for both V GG19 ( a ) and ResNet50 ( b ). Error bars represent mean ± standard deviation across six random seeds. the CIF AR-10 dataset into two halves: CIF AR-10a and CIF AR-10b . Each half contained 25,000 training images with 2,500 images per class. W e then asked whether winning tickets generated using CIF AR-10a would produce increased performance on CIF AR-10b . T o ev aluate the impact of transferring a winning ticket, we compared the CIF AR-10a ticket to both a random ticket and to a winning ticket generated on CIF AR-10b itself (Figure 2). Interestingly , for ResNet50 models, while both CIF AR-10a and CIF AR-10b winning tickets outperformed random tick ets at extreme pruning fractions, both under-performed random tickets at lo w pruning fractions, suggesting that ResNet winning tickets may be particularly sensiti ve to smaller datasets at lo w pruning fractions. 4.2 T ransfer across datasets Our e xperiments on transferring winning tick ets across training data drawn from the same distrib ution suggest that winning tickets are not ov erfit to the particular data samples presented during training, but winning tickets may still be ov erfit to the data distrib ution itself. T o answer this question, we performed a lar ge set of e xperiments to assess whether winning tick ets generated on one dataset generalize to different datasets within the same domain (natural images). W e used six different natural image datasets of various comple xity to test this: Fashion-MNIST [ 32 ], SVHN [ 23 ], CIF AR-10 [ 18 ], CIF AR-100 [ 18 ], ImageNet [ 4 ], and Places365 [ 36 ]. These datasets vary across a number of axes, including grayscale vs. color , input size, number of output classes, and training set size. Since each pruning curve comprises the result of training six models (to capture v ariability due to random seed) from scratch at each pruning fraction, these e xperiments required extensi ve computation, especially for models trained on lar ge datasets such as ImageNet and Places365. W e therefore only ev aluated tickets from larger datasets on these datasets to best prioritize computation. For all comparisons, we performed e xperiments on both V GG19 (Figure 3) and ResNet50 (Figure 4). Across all comparisons, se veral k ey trends emer ged. First and foremost, indi vidual winning tickets which generalize across all datasets with performance close to that of winning tickets generated on the target dataset can be found (e.g., winning tickets sourced from ImageNet and Places365 datsets). This result suggests that a substantial fraction of the inductiv e bias provided by winning tickets is dataset-independent (at least within the same domain and for large source datasets), and provides hope that individual tick ets or distributions of such winning tick ets may be generated once and used across different tasks and en vironments. Second, we consistently observ ed that winning tickets generated on larger , more complex datasets generalized substantially better than those generated on small datasets. This is particularly noticeable for winning tickets generated on the ImageNet and Places365 source datasets, which demonstrated competitiv e performance across all datasets. Interestingly , this effect was not merely a result of training set size, b ut also appeared to be impacted by the number of classes. This is most clearly ex emplified by the differing performance of winning tickets generated on CIF AR-10 and CIF AR-100, both of which feature 50,000 total training e xamples, b ut dif fer in the number of classes. Consistently , CIF AR-100 tickets generalized better than CIF AR-10 tickets, e ven to simple datasets such as F ashion- MNIST and SVHN, suggesting that simply increasing the number of classes while keeping the dataset 5 a 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.750 0.775 0.800 0.825 0.850 0.875 0.900 0.925 0.950 SVHN test accuracy at convergence SVHN 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.2 0.4 0.6 0.8 Ticket source SVHN CIFAR-10 CIFAR-100 ImageNet Random b 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.2 0.4 0.6 0.8 1.0 Fashion-MNIST test accuracy at convergence Fashion-MNIST Ticket source Fashion-MNIST CIFAR-10 CIFAR-100 ImageNet Random c 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.0 0.2 0.4 0.6 0.8 CIFAR-10 test accuracy at convergence CIFAR-10 Ticket source CIFAR-10 CIFAR-100 ImageNet Random d 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.40 0.45 0.50 0.55 0.60 0.65 0.70 0.75 CIFAR-100 test accuracy at convergence CIFAR-100 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.00 0.25 0.50 0.75 Ticket source CIFAR-10 CIFAR-100 ImageNet Random e 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.0 0.2 0.4 0.6 0.8 ImageNet test accuracy at convergence (Top 5) ImageNet Ticket source CIFAR-10 CIFAR-100 ImageNet Places365 Random f 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.65 0.70 0.75 0.80 0.85 Places365 test accuracy at convergence (Top 5) Places365 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.2 0.4 0.6 0.8 Ticket source CIFAR-100 ImageNet Places365 Random Figure 3: T ransferring VGG19 winning tickets across datasets. W inning ticket performance on target datasets: SVHN ( a ), F ashion-MNIST ( b ), CIF AR-10 ( c ), CIF AR-100 ( d ), ImageNet ( e ), and Places365 ( f ). W ithin each plot, each line represents a different source dataset for the winning ticket. In cases where the y-axis has been narrowed to make small differences visible, full y-axes are provided as insets. Error bars represent mean ± standard deviation across six random seeds. size fixed may lead to substantial gains in winning ticket generalization (e.g., compare CIF AR-10 and CIF AR-100 ticket performance in Figure 3e). Interestingly , we also observed that when networks are e xtremely ov er-parameterized relati ve to the complexity of the task, as when we apply V GG19 to F ashion-MNIST , we found that transferred winning tickets dramatically outperformed winning tickets generated on Fashion-MNIST itself at low pruning rates (Figure 3b). In this setting, large networks trained on Fashion-MNIST ov erfit dramatically , leading to very lo w test accuracy at low pruning rates, which gradually improved as more weights were pruned. W inning tickets generated on other datasets, ho wever , bypassed this problem, reaching high accuracy at the same pruning rates which were untrainable from e ven Fas hion-MNIST winning tickets (Figure 3b), again suggesting that transferred tick ets provide additional re gularization against ov erfitting. Finally , we observed that winning tick et transfer success was roughly similar across across VGG19 and ResNet50 models, but se veral dif ferences were present. Consistent with pre vious results [ 8 ], per- formance on large-scale datasets began to rapidly degrade for ResNet50 models when approximately 5-10% of weights remained, in contrast to VGG19 models which only demonstrated small decreases in accuracy , ev en with 99.9% of weights pruned. In contrast, at e xtreme pruning fractions on small datasets, ResNet50 models consistently achiev ed similar or only slightly degraded performance relativ e to o ver -parameterized models (e.g., Figures 4c and 4d). These results suggest that ResNet50 models may hav e a sharper “pruning clif f ” than VGG19 models. 6 a 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.70 0.75 0.80 0.85 0.90 0.95 SVHN test accuracy at convergence SVHN 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.2 0.4 0.6 0.8 1.0 Ticket source SVHN CIFAR-10 CIFAR-100 ImageNet Random b 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.0 0.2 0.4 0.6 0.8 Fashion-MNIST test accuracy at convergence Fashion-MNIST Ticket source Fashion-MNIST CIFAR-10 CIFAR-100 ImageNet Random c 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 CIFAR-10 test accuracy at convergence CIFAR-10 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.2 0.4 0.6 0.8 Ticket source CIFAR-10 CIFAR-100 ImageNet Random d 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.0 0.1 0.2 0.3 0.4 0.5 0.6 CIFAR-100 test accuracy at convergence CIFAR-100 Ticket source CIFAR-10 CIFAR-100 ImageNet Random e 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.0 0.2 0.4 0.6 0.8 ImageNet test accuracy at convergence (Top 5) ImageNet Ticket source CIFAR-100 CIFAR-10 ImageNet Places365 Random f 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.65 0.70 0.75 0.80 0.85 Places365 test accuracy at convergence (Top 5) Places365 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.0 0.2 0.4 0.6 0.8 Ticket source ImageNet Places365 Random Figure 4: T ransferring ResNet50 winning tick ets acr oss datasets. W inning tick et performance on target datasets: SVHN ( a ), F ashion-MNIST ( b ), CIF AR-10 ( c ), CIF AR-100 ( d ), ImageNet ( e ), and Places365 ( f ). W ithin each plot, each line represents a different source dataset for the winning ticket. In cases where the y-axis has been narrowed to make small differences visible, full y-axes are provided as insets. Error bars represent mean ± standard deviation across six random seeds. 4.3 T ransfer across optimizers In the abov e sections, we demonstrated that winning tickets can be transferred across datasets within the same domain, suggesting that winning tickets learn generic inductiv e biases which improv e training. Howe ver , it is possible that winning tick ets are also specific to the particular optimizer that is used. The starting point provided by a winning tick et allo ws a particular optimum to be reachable, b ut extensions to standard stochastic gradient descent (SGD) may alter the reachability of certain states, such that a winning ticket generated using one optimizer will not generalize to another optimizer . T o test this, we generated winning tickets using two optimizers (SGD with momentum and Adam [ 16 ]), and e valuated whether winning tick ets generated using one optimizer increased performance with the other optimizer . W e found that, as with transfer across datasets, transferred winning tickets for VGG models achie ved similar performance as those generated using the source optimizer (Figure 5). Interestingly , we found that tickets transferred from SGD to Adam under -performed random tickets at lo w pruning fractions, b ut significantly outperformed random tickets at high pruning fractions (Figure 5b). Overall though, this result suggests that VGG winning tickets are not overfit to the particular optimizer used during generation, suggesting that VGG winning tickets are optimizer- independent . 7 a 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 CIFAR-10 with SGD test accuracy at convergence CIFAR-10 with SGD 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.0 0.2 0.4 0.6 0.8 Ticket source Adam SGD Random b 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 CIFAR-10 with Adam test accuracy at convergence CIFAR-10 with Adam 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 0.2 0.4 0.6 0.8 Ticket source SGD Adam Random Figure 5: T ransferring V GG winning tickets across optimizers. T icket performance when training using SGD w/ momentum ( a ) and Adam ( b ). W ithin each plot, each line represents a dif ferent source optimizer for the winning ticket. In cases where the y-axis has been narrowed to mak e small dif ferences visible, full y-axes are provided as insets. Error bars represent mean ± standard deviation across six random seeds. 5 Discussion In this work, we demonstrated that winning tickets are capable of transferring across a variety of training configurations, suggesting that winning tickets drawn from suf ficiently large datasets are not ov erfit to a particular optimizer or dataset, b ut rather feature inducti ve biases which improve training of sparsified models more generally (Figures 3 and 4). W e also found that winning tickets generated against datasets with more samples and more classes consistently transfer better , suggesting that larger datasets encourage more generic winning tickets. T ogether , these results suggest that winning ticket initializations satisfy a necessary precondition (generality) for the e ventual construction of a lottery ticket initialization scheme, and provide greater insights into the factors which make winning ticket initializations unique. 5.1 Cav eats and next steps The generality of lottery ticket initializations is encouraging, but a number of ke y limitations remain. First, while our results suggest that only a handful of winning tick ets need to be generated, generating these winning tickets via iterati ve pruning is v ery slo w , requiring retraining the source model as many as 30 times serially for extreme pruning fractions (e.g., 0.999). This issue is especially prev alent giv en our observation that larger datasets produce more generic winning tickets, as these models require significant compute for each training run. Second, we hav e only ev aluated the transfer of winning tickets across datasets within the same domain (natural images) and task (object classification). It is possible that winning ticket initializations confer inductiv e biases which are only good for a giv en data type or task structure, and that these initializations may not transfer to other tasks, domains, or multi-modal settings. Future work will be required to assess the generalization of winning tickets across domains and di verse task sets. Third, while we found that transferred winning tickets often achie ved roughly similar performance to those generated on the same dataset, there was often a small, but noticeable gap between the transfer ticket and the same dataset ticket, suggesting that a small fraction of the inducti ve bias conferred by winning tickets is dataset-dependent. This effect was particularly pronounced for winning tickets generated on small datasets. Ho wev er , it remains unclear which aspects of winning tickets are dataset-dependent and which aspects are dataset-independent. W orking to understand this dif ference, and in vestigating ways to close this gap will be important future work, and may also aid transfer across domains. Fourth, we only e v aluated situations where the network topology is fix ed in both the source and target training configurations. This is limiting since it means a ne w winning ticket must be generated for each and ev ery architecture topology , though our experiments suggest that a small number of layers may be re-initialized without substantially damaging the winning ticket. As such, the de velopment of methods to parameterize winning tickets for nov el architectures will be an important direction for future studies. Finally , a critical question remains unanswered: what mak es winning tick ets special? While our results shed a v ague light on this by suggesting that whate ver makes these winning tick ets unique is 8 somewhat generic, what precisely makes them special is still unclear . Understanding these properties will be critical for the future de velopment of better initialization strate gies inspired by lottery tickets. References [1] Zeyuan Allen-Zhu, Y uanzhi Li, and Y ingyu Liang. Learning and generalization in over - parameterized neural networks, going beyond two layers. Nov ember 2018. URL http: //arxiv.org/abs/1811.04918 . [2] Zeyuan Allen-Zhu, Y uanzhi Li, and Zhao Song. A con ver gence theory for deep learning via Over -Parameterization. November 2018. URL . [3] Babajide O A yinde, T amer Inanc, and Jacek M Zurada. Redundant feature pruning for acceler- ated inference in deep neural networks. Neural networks: the of ficial journal of the International Neural Network Society , May 2019. ISSN 0893-6080. doi: 10.1016/j.neunet.2019.04.021. URL http://www.sciencedirect.com/science/article/pii/S0893608019301273 . [4] J. Deng, W . Dong, R. Socher , L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009. [5] Simon S Du and Jason D Lee. On the power of ov er-parametrization in neural networks with quadratic activ ation. March 2018. URL . [6] Simon S Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent prov ably optimizes ov er-parameterized neural netw orks. October 2018. URL 02054 . [7] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations , 2019. URL http: //arxiv.org/abs/1803.03635 . [8] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M Roy , and Michael Carbin. The lottery ticket hypothesis at scale. March 2019. URL . [9] T re vor Gale, Erich Elsen, and Sara Hooker . The state of sparsity in deep neural networks. February 2019. URL . [10] Xavier Glorot and Y oshua Bengio. Understanding the dif ficulty of training deep feed- forward neural netw orks. Aistats , 9:249–256, 2010. ISSN 1532-4435. doi: 10. 1.1.207.2059. URL http://machinelearning.wustl.edu/mlpapers/paper_files/ AISTATS2010_GlorotB10.pdf . [11] Y iwen Guo, Anbang Y ao, and Y urong Chen. Dynamic network surgery for ef- ficient dnns. In D. D. Lee, M. Sugiyama, U. V . Luxb urg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems 29 , pages 1379–1387. Curran Associates, Inc., 2016. URL http://papers.nips.cc/paper/ 6165- dynamic- network- surgery- for- efficient- dnns.pdf . [12] Song Han, Jeff Pool, John T ran, and W illiam Dally . Learning both weights and connections for efficient neural network. In Advances in neural information processing systems , pages 1135–1143, 2015. [13] Boris Hanin and Da vid Rolnick. How to start training: The effect of initialization and architecture. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31 , pages 571–581. Curran Associates, Inc., 2018. URL http://papers.nips.cc/paper/ 7338- how- to- start- training- the- effect- of- initialization- and- architecture. pdf . [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-le vel performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015. 9 [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 770–778, 2016. [16] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2014. [17] Simon K ornblith, Jonathon Shlens, and Quoc V Le. Do better ImageNet models transfer better? May 2018. URL . [18] Alex Krizhe vsky and Geoffre y Hinton. Learning multiple layers of features from tiny images. T echnical report, Citeseer, 2009. [19] Hao Li, Asim Kadav , Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient con vnets. arXiv preprint arXi v:1608.08710, 2016. [20] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and T revor Darrell. Rethinking the value of network pruning. In International Conference on Learning Representations , 2019. URL http://arxiv.org/abs/1810.05270 . [21] Dmitry Molchanov , Arsenii Ashukha, and Dmitry V etrov . V ariational dropout sparsifies deep neural networks. In Proceedings of the 34th International Conference on Machine Learning-V olume 70, pages 2498–2507. JMLR. or g, 2017. [22] Pa vlo Molchanov , Stephen T yree, T ero Karras, Timo Aila, and Jan Kautz. Pruning con volutional neural networks for resource ef ficient inference. November 2016. URL abs/1611.06440 . [23] Y uval Netzer, T ao W ang, Adam Coates, Alessandro Bissacco, Bo W u, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011. [24] Behnam Neyshabur , Ryota T omioka, and Nathan Srebro. In search of the real inductiv e bias: On the role of implicit regularization in deep learning. December 2014. URL http: //arxiv.org/abs/1412.6614 . [25] Behnam Neyshabur , Zhiyuan Li, Srinadh Bhojanapalli, Y ann LeCun, and Nathan‘ Srebro. The role of ov er-parametrization in generalization of neural networks. In International Conference on Learning Representations , 2019. URL https://openreview.net/forum? id=BygfghAcYX¬eId=BygfghAcYX . [26] Adam Paszke, Sam Gross, Soumith Chintala, Gre gory Chanan, Edward Y ang, Zachary DeV ito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer . Automatic differentiation in pytorch. In NIPS-W, 2017. [27] Arnu Pretorius, Elan van Biljon, Stev e Kroon, and Herman Kamper . Critical initialisation for deep signal propagation in noisy rectifier neural networks. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 5717–5726. Curran Associates, Inc., 2018. [28] Zhuwei Qin, Fuxun Y u, Chenchen Liu, and Xiang Chen. INTERPRET ABLE CONV O- LUTION AL FIL TER PRUNING, 2019. URL https://openreview.net/forum?id= BJ4BVhRcYX . [29] Samuel S Schoenholz, Justin Gilmer , Surya Ganguli, and Jascha Sohl-Dickstein. Deep in- formation propagation. In International Conference on Learning Representations , 2016. URL http://arxiv.org/abs/1611.01232 . [30] Karen Simon yan and Andre w Zisserman. V ery deep conv olutional networks for large-scale image recognition. In International Conference on Learning Representations , 2015. URL https://arxiv.org/abs/1409.1556 . [31] Chuanqi T an, Fuchun Sun, T ao K ong, W enchang Zhang, Chao Y ang, and Chunfang Liu. A surve y on deep transfer learning. In ICANN , 2018. URL 01974 . 10 [32] Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017. [33] Greg Y ang and Sam S. Schoenholz. Deep mean field theory: Layerwise variance and width variation as methods to control gradient explosion. In International Conference on Learning Representations W orkshop Track , 2018. URL https://openreview.net/forum? id=rJGY8GbR- . [34] Jason Y osinski, Jeff Clune, Y oshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? In Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W einberger , editors, Advances in Neural Information Processing Systems 27 , pages 3320–3328. Curran Associates, Inc., 2014. URL http://papers.nips.cc/paper/ 5347- how- transferable- are- features- in- deep- neural- networks.pdf . [35] Hongyi Zhang, Y ann N. Dauphin, and T engyu Ma. Residual learning without normalization via better initialization. In International Conference on Learning Representations , 2019. URL https://openreview.net/forum?id=H1gsz30cKX . [36] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliv a, and Antonio T orralba. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. [37] Michael H Zhu and Suyog Gupta. T o prune, or not to prune: Exploring the efficac y of pruning for model compression. In International Conference on Learning Representations W orkshop T rack, February 2018. URL https://openreview.net/pdf?id=Sy1iIDkPM . [38] Barret Zoph, V ijay V asudev an, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. July 2017. URL 07012 . 11 A A ppendix A.1 Model details and hyperparameters General hyperparameters All models were trained in PyT orch [ 26 ]. For Fashion-MNIST , SVHN, CIF AR-10, and CIF AR-100, batch sizes of 512 parallelized across 2 GPUs were used. For ImageNet and Places365, batch sizes of 512 parallelized across 16 GPUs were used and trained using syn- chronous distributed training. For models trained with SGD, a learning rate of 0.1 was used with momentum of 0.9 and weight decay of 0.0001. For models trained with Adam, a learning rate of 0.0003 was used with betas of 0.9 and 0.999 and weight decay of 0.0001. V GG19 VGG19 was implemented as in [ 30 ], except all fully-connected layers were removed and replaced with an average pool layer , as in [ 7 , 8 ]. Precisely , filter sizes were as follo ws: {64, 64, max-pool, 128, 128, max-pool, 256, 256, 256, 256, max-pool, 512, 512, 512, 512, max-pool, 512, 512, 512, 512, global-av erage-pool}. ReLU non-linearities were applied throughout and batch normalization was applied after each con volutional layer . For all con volutional layers, kernel sizes of 3 with padding of 1 were used, and all con volutional layers were initialized using the Xavier normal initialization with biases initialized to 0, and batch normalization weight and bias parameters initialized to 1 and 0, respecti vely . All VGG19 models were trained for 160 epochs. Learning rates were annealed by a factor of 10 at 80 and 120 epochs. ResNet50 ResNet50 was implemented as in [ 15 ]. Precisely , blocks were structured as follo ws (stride, filter sizes, output channels): (1x1, 64, 64, 256) x 3, (2x2, 128, 128, 512) x 4, (2x2, 256, 256, 1024) x 6, (2x2, 512, 512, 2048) x 3, follo wed by an average pool layer and a linear classification layer . All ResNet50 models were trained for 90 epochs. Learning rates were annealed by a factor of 10 at 50, 65, and 80 epochs. Pruning parameters For all models, an iterativ e pruning rate of 0.2 was used and 30 pruning iterations were performed. Follo wing the sixth pruning iteration, model performance was e valuated e very third pruning iteration. Pruning was performed using magnitude pruning, such that the smallest magnitude weights were remov ed first, as in [ 12 , 19 ]. For Fashion-MNIST , SVHN, CIF AR-10 and CIF AR-100 winning tickets, late resetting of 1 epoch was used. For ImageNet and Places365 winning tickets, late resetting of 3 epochs was used. A.2 Randomized masks 0.0 0.2 0.36 0.488 0.59 0.672 0.738 0.866 0.931 0.965 0.982 0.991 0.995 0.998 0.999 Fraction of weights pruned 0.80 0.82 0.84 0.86 0.88 0.90 0.92 0.94 CIFAR-10 test accuracy at convergence Ticket type Winning ticket Preserved mask Globally permute mask Locally permute mask Figure A1: Comparison of different random masks. Performance of various random masks on CIF AR-10. Error bars represent mean ± standard deviation across six random seeds. When models are pruned in an unstructured manner , there are two aspects of the final pruned model that may be informativ e: the v alues of the weights themselves and the structure of the mask used for pruning. In the original lottery ticket study [ 7 ], bad tickets were compared with randomly drawn values, but the preserved winning ticket mask. This has the unintended consequence of transferring information from the winning ticket to the bad tick et, potentially inflating bad ticket performance. This issue seems particularly relev ant given that we observed that global pruning 12 results in substantially better performance and noticeably dif ferent layerwise pruning ratios relati ve to layerwise pruning (Figure 1), suggesting that the mask statistics likely contain important information. T o test this, we evaluated three types of masks: preserved masks, globally permuted masks, and locally permuted masks. In the preserved mask case, the same mask found by the winning ticket is used for the random tick et. In the locally permuted case, the mask is permuted within each layer , such that the exact structure of the mask is broken, b ut the layerwise statistics remain intact. Finally , in the globally permuted case, the mask is permuted across all layers, such that no information should be passed between the winning ticket and the bad ticket. Consistent with the lottery ticket hypotehsis, we found that the winning ticket outperformed all random tickets (Figure A1). Interestingly , we found that while locally permuting masks damaged performance somewhat (blue vs. green), globally permuting the mask results in dramatically worse performance (blue/green vs. yellow), suggesting that the layerwise statistics deri ved from training the ov er-parameterized model are v ery informati ve. As this information would not be a v ailable without going through the process of generating a winning ticket, we consider the purely random mask to be the most relev ant comparison to training an equiv alently parameterized model from scratch. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment