다중 억양 LSTM CTC 음성인식 향상을 위한 도메인 특화 학생 교사 학습
본 논문은 미국, 인도, 히스패닉 억양을 포함한 다중 억양 영어 데이터를 이용해 LSTM‑CTC 모델을 학습하고, 단일 다중 억양 교사 모델로부터 억양별 교사 모델을 정렬시킨 뒤, 이들을 활용해 학생 모델을 단계적으로 개선한다. 최종 다중 억양 학생 모델은 기준 모델 대비 문자 오류율(CER)에서 20.1 %의 상대적 감소를 달성했으며, 억양별 적응 단계에서도 교사 모델의 소프트 출력(KL 발산)을 이용해 추가 성능 향상을 얻었다.
저자: Shahram Ghorbani, Ahmet E. Bulut, John H.L. Hansen
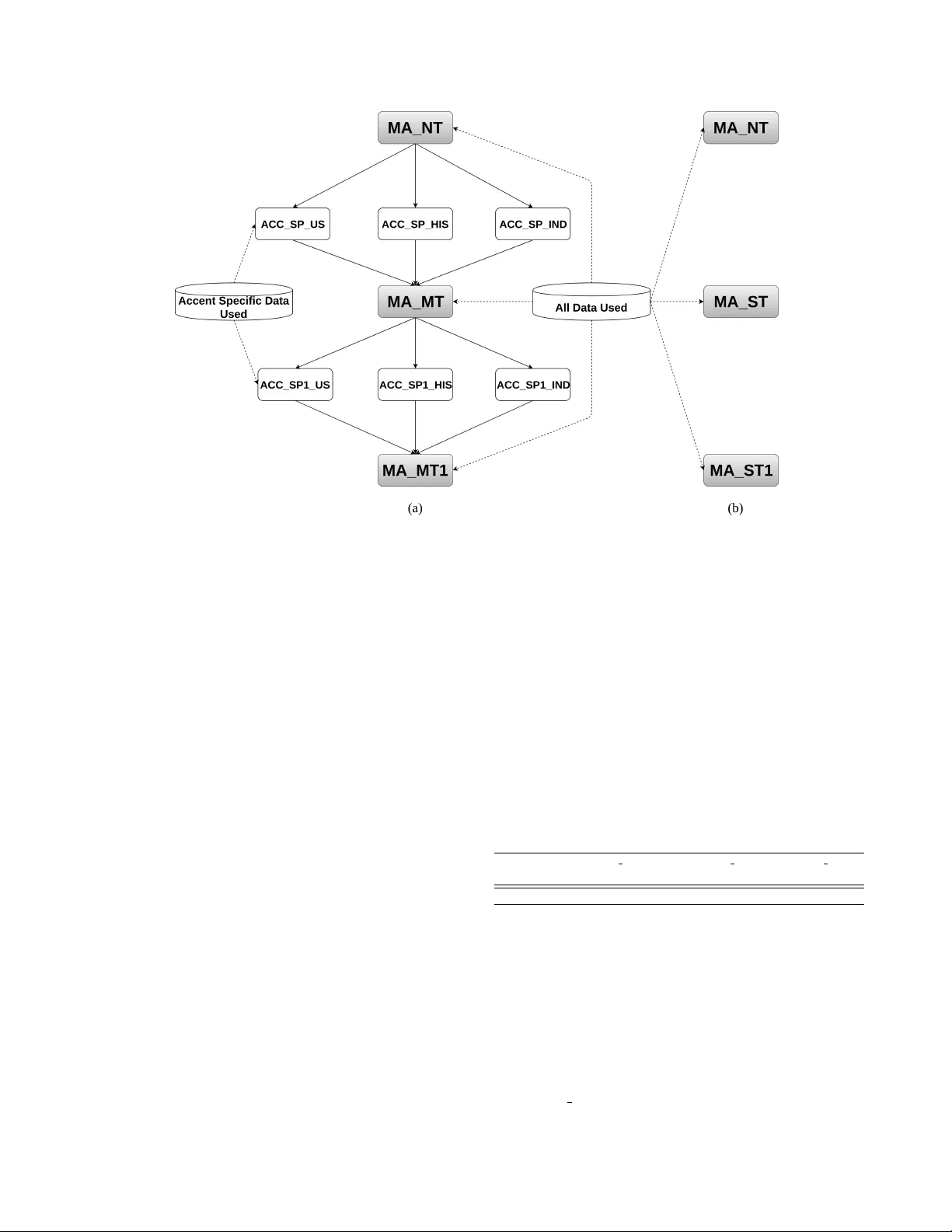
본 논문은 비원어민 억양이 자동 음성인식(ASR) 시스템의 성능 저하를 초래한다는 문제를 다루며, 특히 미국(네이티브), 인도, 히스패닉 세 가지 영어 억양을 대상으로 한다. 기존 연구에서는 모델 적응, 억양 분류 후 모델 선택, 발음 사전 교체 등 다양한 방법을 제시했지만, 이들 방법은 데이터 효율성이나 구현 복잡성에서 한계를 보였다.
저자들은 LSTM 기반 CTC(end‑to‑end) 구조를 채택하고, 전체 억양 데이터를 합쳐 다중 억양 교사 모델(MA‑Teacher)을 먼저 학습한다. CTC는 출력이 ‘blank’와 문자 스파이크로 구성된 시계열 확률 분포를 생성하는데, 서로 다른 모델 간 스파이크 위치가 일치하지 않아 직접적인 앙상블이 어려운 것이 특징이다. 이를 해결하기 위해 MA‑Teacher의 소프트 출력(온도 T를 적용해 부드럽게 만든 확률)을 이용해 각 억양별 교사 모델(ACC‑SP_US, ACC‑SP_IND, ACC‑SP_HIS)을 별도로 학습한다. 동일 교사의 지도 하에 억양별 모델을 학습함으로써 훈련 데이터에 대한 스파이크 정렬률(Characters’ Spikes Overlap, CSO)이 80 % 수준에서 95 %까지 상승한다.
다음 단계에서는 억양별 교사 모델들의 소프트 출력과 실제 전사 라벨의 CTC 손실을 결합한 복합 손실 함수를 사용한다. 구체적으로 L = λ·F_CE + (1‑λ)·F_CTC이며, 여기서 F_CE는 교사와 학생 사이의 교차 엔트로피, F_CTC는 정답 라벨에 대한 CTC 손실이다. λ는 두 손실의 가중치를 조절하는 파라미터이며, 실험에서는 λ = 0.9, 온도 T = 4가 기본값으로 채택되었다. 이 손실 함수를 통해 새로운 다중 억양 학생 모델(MA‑Student)을 학습하면, 기존 MA‑Teacher 대비 문자 오류율(CER)에서 20.1 %의 상대적 감소를 달성한다. 즉, 학생 모델이 교사 모델보다 더 나은 일반화 능력을 갖게 된다.
또한, 최종 MA‑Student 모델을 각 억양에 맞게 추가 적응(adaptation)시키는 과정에서도 지식 증류를 활용한다. 기존 방법은 일반적인 KL‑발산을 이용해 전체 모델의 소프트 출력을 정규화했지만, 여기서는 각 억양별 교사 모델의 소프트 출력을 정규화 항으로 사용한다. 실험 결과, 인도 억양에 대한 적응 시 CER가 14.2 %에서 11.7 %로 감소했으며, 이는 일반 KL‑발산 기반 적응보다 약 0.3 %~0.5 % 더 좋은 성능이다.
전체 실험은 UT‑CRSS‑4EnglishAccent 코퍼스를 사용했으며, 각 억양당 약 28시간의 훈련 데이터와 5시간씩의 개발·평가 데이터를 포함한다. 입력 특징은 26차원 Mel filterbank에 4프레임을 양쪽으로 스택하고, 2프레임씩 스킵하는 전처리를 적용했다. 네트워크 구조는 2개의 전방 피드포워드 레이어(500 유닛) → 2개의 양방향 LSTM 레이어(각 방향 300 유닛) → 2개의 전방 피드포워드 레이어(500 유닛)이며, Adam 옵티마이저(학습률 0.001)와 미니배치(30 utterance)로 학습하였다. 디코딩은 언어 모델 없이 빔 서치(빔 폭 100)를 사용했다.
결론적으로, 이 연구는 (1) CTC 모델의 출력 정렬 문제를 단일 다중 억양 교사 모델을 통해 해결하고, (2) 소프트 라벨과 CTC 라벨을 동시에 활용한 복합 손실이 학생 모델의 성능을 크게 향상시키며, (3) 억양별 교사 모델을 이용한 적응이 기존 KL‑발산 기반 적응보다 더 효과적이라는 세 가지 주요 기여를 제시한다. 이러한 접근은 다중 억양, 다중 도메인, 다중 언어 ASR 시스템에 적용 가능하며, 향후 연구에서는 더 많은 억양 및 방언을 포함한 확장과, 언어 모델과 결합한 최종 인식 성능 향상을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기