Advancing Multi-Accented LSTM-CTC Speech Recognition using a Domain Specific Student-Teacher Learning Paradigm
Non-native speech causes automatic speech recognition systems to degrade in performance. Past strategies to address this challenge have considered model adaptation, accent classification with a model selection, alternate pronunciation lexicon, etc. I…
Authors: Shahram Ghorbani, Ahmet E. Bulut, John H.L. Hansen
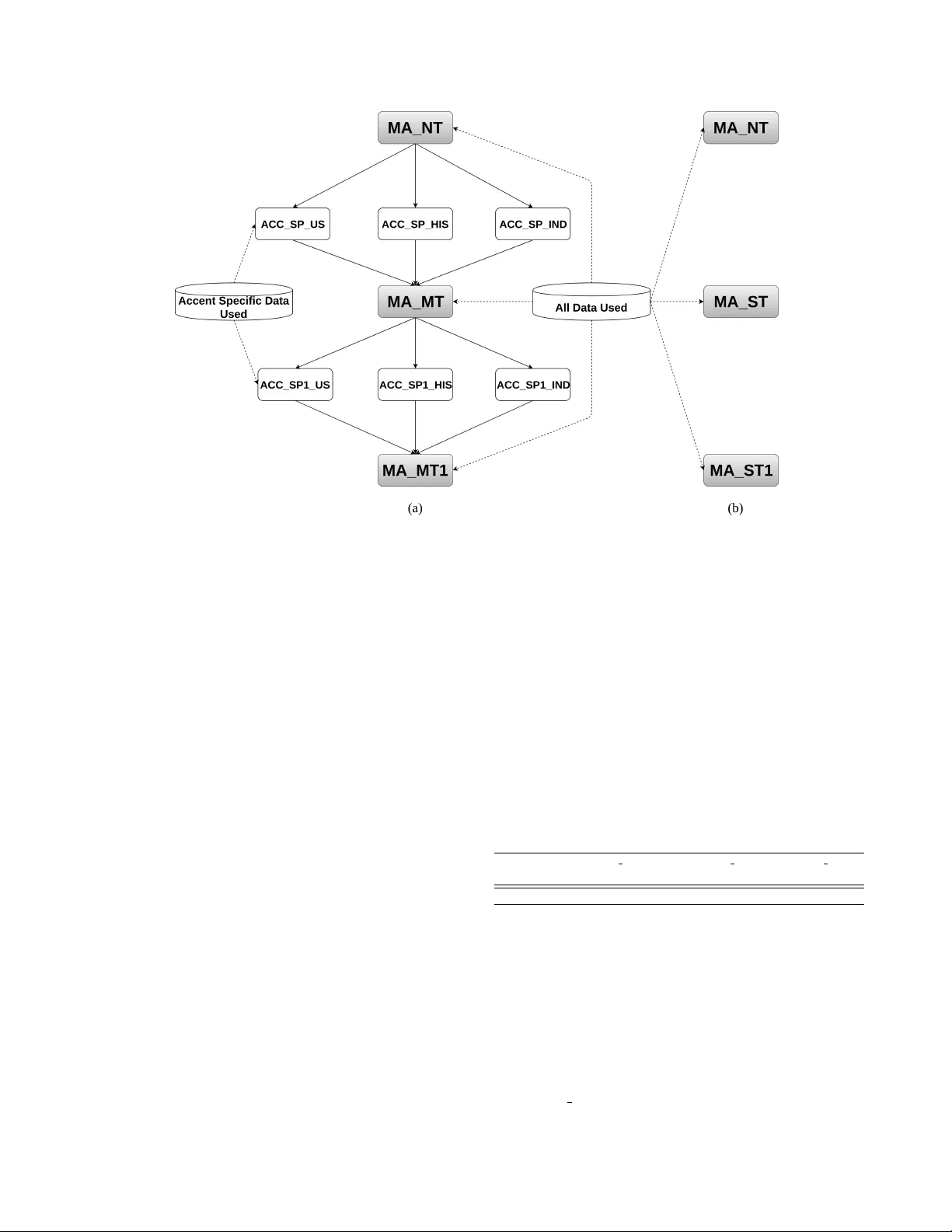
AD V ANCING MUL TI-A CCENTED LSTM-CTC SPEECH RECOGNITION USING A DOMAIN SPECIFIC STUDENT -TEA CHER LEARNING P ARADIGM Shahram Ghorbani, Ahmet E. Bulut, J ohn H.L. Hansen Center for Robust Speech Systems (CRSS) Uni versity of T exas at Dallas, Richardson, TX 75080 { shahram.ghorbani, ahmet.bulut, john.hansen } @utdallas.edu ABSTRA CT ‘Non-nativ e speech causes automatic speech recognition sys- tems to degrade in performance. Past strate gies to address this challenge hav e considered model adaptation, accent clas- sification with a model selection, alternate pronunciation lexicon, etc. In this study , we consider a recurrent neural network (RNN) with connectionist temporal classification (CTC) cost function trained on multi-accent English data in- cluding US (Nati ve), Indian and Hispanic accents. W e exploit dark knowledge from a model trained with the multi-accent data to train student models under the guidance of both a teacher model and CTC cost of tar get transcription. W e show that transferring kno wledge from a single RNN-CTC trained model toward a student model, yields better performance than the stand-alone teacher model. Since the outputs of different trained CTC models are not necessarily aligned, it is not possible to simply use an ensemble of CTC teacher models. T o address this problem, we train accent specific models under the guidance of a single multi-accent teacher , which results in having multiple aligned and trained CTC models. Furthermore, we train a student model under the supervision of the accent-specific teachers, resulting in an ev en further complementary model, which achiev es +20.1% relativ e Character Error Rate (CER) reduction compared to the baseline trained without an y teacher . Having this effecti ve multi-accent model, we can achiev e further improv ement for each accent by adapting the model to each accent. Using the accent specific model’ s outputs to regularize the adapting process (i.e., a knowledge distillation version of Kullback- Leibler (KL) di vergence) results in e ven superior performance compared to the con ventional approach using general teacher models. Index T erms — speech recognition, student-teacher learn- ing, multi-accent acoustic model, end-to-end models This project was funded by AFRL under contract F A8750-15-1-0205 and partially by the Univ ersity of T exas at Dallas from the Distinguished Uni- versity Chair in T elecommunications Engineering held by J. H. L. Hansen. 1. INTR ODUCTION Current successful ASR systems emplo y deep neural netw ork (DNN) models as acoustic model combined with a hidden Markov model (HMM) [1, 2], or use them within an end- to-end configuration [3, 4]. Such systems perform well if they are ev aluated in the same condition with their training data. Howe ver , in real scenarios, speech typically exhibits wide variation due to the differences in room acoustics and rev erberation, speakers and accents, and also environment or recording/channel distortions. For many of these situations, it is possible to simulate (augment) or collect more data to gen- eralize the final ASR system. Giv en training data of multiple conditions, we need to exploit the data ef ficiently to train an improv ed multi-condition (domain) ASR model [5, 6, 7, 8, 9]. In our scenario, we have data from different accents of En- glish (nativ e US, Hispanic English accent, and Indian English accent) with all other recording conditions remaining con- stant, thus, allowing us to focus only on the acoustic differ- ences between these accents. The general problem of accent within speech technology is a challenging problem, since non-nativ e speech causes loss in performance for speech recognition and diariza- tion systems. The specific problem of accent recogni- tion/classification has been inv estigated extensi vely in the past [10, 11, 12]. In addition, the notion of accent classi- fication combined to improve speech recognition is also a long-standing goal in the field. Recent advancements in ma- chine learning has caused a renewal in exploring improved techniques to address this problem. There have been many attempts to train a multi-accent (dialect) system. Kanishka et al., in [13] used a multi-task hierarchical CTC-based model with accent-dependent phoneme recognition as a secondary task. [14] explores an accent-related bottleneck feature as auxiliary information. [15] adds a special accent-specific symbol at the end of target transcriptions to train a multi- dialect sequence-to-sequence model. In this study , we in- vestigate employing student-teacher learning to adv ance a muli-accent model. In student-teacher learning, rather than training a model directly on hard targets, training is carried out in tw o steps [16, 17]. First, we train sev eral complex, dis- tinct, complementary teacher acoustic models. Next, we train a student model constraining it to mimic the soft-outputs (posteriors or logits) of the original trained teachers. This technique has been successfully applied in the ASR domain: distant-talking ASR [18], multilingual [19, 20], domain adap- tation [21], and others. In this study , we inv estigate a novel approach of knowl- edge transference to achieve an adv anced multi-accent model. In our proposed scenario, teacher models are accent-specific RNN-CTC models which are only trained with the corre- sponding accent English data. Howe ver , since the outputs of different trained CTC models are not necessarily aligned, we cannot simply use the ensemble of CTC teacher models. T o align the outputs of the accent-specific model, we propose to train them under the guidance of a single multi-accent model. In addition to aligning the CTC trained models, this approach also achiev es better generalization. Having the aligned accent-specific models, we train an improved multi-accent model under the supervision of both the teacher models and CTC cost of the target transcription. The result- ing multi-accent model significantly outperforms the baseline multi-accent model trained with no teacher model. Adapting the best multi-accent model to each accent, b ut constraining it to mimic the soft-outputs of the corresponding accent-specific model generalizes the adaptation process. The proposed ap- proach of adaptation outperforms the knowledge distillation version of KL-di vergence [21]. 2. RNN-CTC MODELS Long Short-T erm Memory (LSTM) networks hav e prov en to be ef fective in many sequential tasks [22]. Having gated memory cells to store information within the network en- ables them to exploit long-range context and produces related outputs with an arbitrary delay . In the speech recognition do- main, an LSTM neural network can outperform con ventional RNNs [23]. Alex et al., [24] introduced a new architec- ture for LSTM networks that recei ve input features in both forward and backward directions and sho wed improv ed per- formance for acoustic models compared to a unidirectional trained model. In this study , we also employ bidirectional LSTM cells in the recurrent layers to address the problem of accent/non-nativ e speech recognition. Giv en an input sequence of feature vectors X = { x 1 , x 2 , ... , x N } , a naiv e RNN produces a sequence of distributions over a set of output characters Y = { y 1 , y 2 , ..., y N } by iterating the following By inter grating on: h t = H ( W ih x t + W hh h t − 1 + b h ) , y t = W ho h t + b o , (1) where W and b are the weights and biases of the network, re- spectiv ely , H is the hidden layer activ ation function and y t is the t- th output of the network corresponding to the t- th input ( x t ). In our scenario, the last layer of our model has | S | out- puts, where S = { char acter s of the lang uag e, blank , space , noise } . Here, ’blank’ is a special character that is used by CTC for calculating the cost of the output and also by the decoder to output the final sequence. For each frame, outputs of the model (logits) are submitted to a softmax function to transform them to a valid probability distribution over the members of S : P r ( k , t | X ) = exp ( y t k ) P | S | j =1 exp ( y t j ) , (2) where y t k is the probability of emitting the k - th member of S for the giv en input x t . W e consider the result of the soft- max layer for a given sequence X as the matrix O of size | S | ∗ N . By choosing one element of each column, we obtain a length N output sequence where its probability is P r ( a | X ) = Q N t =1 O ( a ( t ) , t ) . The CTC objectiv e is to maximize the prob- abilities of such sequences that correspond to the target labels: θ = ar gmax X a ∈A N Y t =1 O ( a ( t ) , t ) . (3) Here, A is the set of all alignments related to the target se- quence and θ represents the parameters of the neural network. Next, gi ven a ne w input sequence for the trained netw ork, the decoder finds the most probable output character sequence. The study in [3] exploited two decoders: 1) Simply choosing the most probable output from each column of O (best-path); 2) Beam search decoding approach which considers a beam size of N best paths. In our experiments, we employ the sec- ond beam search decoding method. 3. TEA CHER-STUDENT MODELS FOR END-TO-END CTC SPEECH RECOGNITION MODELS The first effort to in vestigate teacher-student model was [25], examining the consequences of ha ving a deep neural network. Hinton et al., [17], introduced the term ”knowledge distilla- tion”, suggesting a new temperature parameter to soften the softmax outputs before being used to guide the training of another neural network. The main idea for student-teacher learning comes from the fact that the distribution of outputs produced by a trained neural network contain underlying re- lations between output labels. T raining another network (stu- dent) to output such soft labels which are easier to achiev e than hard labels, regularizes the student trained model. As a general setting, having a trained complex model or en- semble of neural networks (teacher models), it is possible to achiev e an improved single (smaller) student by constrain- ing it to mimic the soft outputs produced by the teacher(s) [16, 17]. A general framew ork for teacher-student learning is obtained through the cross-entropy (CE) between outputs of the teacher and student which is represented as: F C E = − N X t =1 | S | X j =1 O 0 Ref ( j, t ) log( O 0 ( j, t )) , (4) where O 0 ( j, t ) and O 0 Ref ( j, t ) are the tempered softmax probability of the j -th character at time t for student and teacher model, respectiv ely , which are computed as follo ws: O 0 ( k , t | X ) = exp ( y t k /T ) P | S | j =1 exp ( y t j /T ) , (5) where T is a temperature. As T becomes larger , the resulting distribution gets softer . T ransferring knowledge from a model trained with CTC is challenging [26] and has not been adequately explored. Out- puts of a CTC trained model are spik y [27], implying that the model tends to giv e very sharp posterior probabilities. While the probability of a single class may be close to 1, the rest of the classes are typically closer to 0. In addition, for our setting which uses ’blank’, since the model just needs one spike of each character to output the desired transcription, most output spikes are ’blank’ which does not have an explicit phonetic similarity with other speech activities, ho wever , there should be some other underlying relation with the neighboring char - acters. Finally , because of the fact that CTC does an arbi- trary alignment between labels and network outputs, as well as ha ving a model with memory which remembers the acous- tic states and outputs spikes at any time, the timing of the probability spikes is different from the true frame-character based alignments [28]. In [26], Hasim et al., considered employing student- teacher learning to improve ASR performance for noisy speech with a CTC-based trained model. Howe ver , their stu- dent model did not outperform the baseline model which was simply trained with noisy data. In that work, they simply used the soft-outputs to train the student model. Howe ver , in scenarios where one has the correct transcription, exploiting the target labels in combination with the soft labels would provide greater benefit to the student models [17]. Therefore, in our student-teacher setting, we use a weighted average of the CE cost of a teacher model and CTC of the true labels as the cost function: L = λ F C E + (1 − λ ) F C T C ( O , Y ) , (6) where λ is the interpolation weight. Student-teacher learning would be more efficient if it could distill the kno wledge from an ensemble of trained com- plementary models into a single system. It is suggested to construct these complementary models with: training models with dif ferent training data, employing alternate architec- tures of neural network (e.g., con volutional neural network or LSTM), or initializing with different approaches among others. In our case, we consider multi-accent data with the aim to achiev e an advanced multi-accent (MA) English model. Each accent has its own underlying similarities be- tween speech acoustic units. For example, in an Indian accent, phoneme /t/, in many w ords, is pronounced more like a voiced sound making it closer to /d/. Howe ver , in native English, /t/ is an un voiced phoneme that has the same vocal tract configuration but alternate excitation to phoneme /d/. In addition, for end-to-end ASR that also models the grammar of languages/accents, alternate accents might posses alternate grammar structure or word choice that could influence the relations between acoustic units. W e hypothesize, accent specific teacher models, which are just trained with data from one accent, benefits the stu- dent model more than a multi-accent teacher model. How- ev er , as is discussed, training multiple LSTM-CTC using dif- ferent accent speech data results in models with their outputs not aligned. T o address this issue, we suggest a novel ar- chitecture employing student-teacher model: first we train a multi-accent model with training data from all accents, then we train multiple accent specific models from scratch under the guidance of the multi-accent model. Being trained with the same teacher but seeing only the data of one accent re- sults in aligned accent specific models. The last step is to train a ne w multi-accent model with these individual teachers from which we obtain soft-outputs of each accent from the corresponding model (Figure 1). Having student models that perform better than the teacher provides a new space to explore system advance- ments. Could these advanced student models teach another generation of students with the aim to achieve further im- prov ement? The knowledge that comes from an improv ed model is more accurate and probably more close to actual similarities between labels, providing an easier point for stu- dents to achiev e and generalize the learning. T o this end, we apply our proposed student teacher learning one step further as shown in Figure 1. W e employ the advanced multi-accent model from the pre vious step (MA MT) to train three new accent-specific models (i.e., A CC SP1 US, A CC SP1 IND, and ACC SP1 HIS). Next, we exploit these accent-specific models to teach a further superior multi- accent model (MA MT1). 4. EXPERIMENT AL SETUP For training and ev aluating the model across accents, the UT - CRSS-4EnglishAccent corpus is used [11]. This corpus of 420 speakers was collected at CRSS-UTDallas and consists of four major English accents: US (native), Hispanic, Indian and Australian. The data for each accent consists of about 100 speakers balanced for gender and age, with session content that consists of read and spontaneous speech. In our study , we use US, Hispanic and Indian parts of the corpus to train both multi-accent and accent-specific models. In this corpus, for each accent, there is about 28h of training data, 5h of de- Fig. 1 . The proposed student-teacher learning to adv ance a multi-accent model: using accent-specific teachers (a), using multi- accent teachers (b). velopment and 5h of e valuation data. W e extract 26 dim Mel filterbank coefficients for each 25ms frame with a skip rate of 10ms. W e expand each frame by stacking 4 frames to each side, then the frames are dec- imated by skipping 2 frames per each frame for processing. we use the skip process as described in [29]. The neural network architecture starts with two feed for- ward layers each of 500 neurons, where their outputs go through two bidirectional LSTM layers with 300 neurons in each direction. The LSTM layers are followed by two forward layers each containing 500 neurons. W e use Adam Optimizer with an initial learning rate of 0.001 to train the model. Gradients are computed from Mini-batches of 30 utterances. W e employ early-stopping by monitoring the per - formance on a held-out validation set during training epochs. In the ev aluation step, we emplo y a beam search decoding [3] with a beam width of 100 with no language model or lexicon information. 5. RESUL TS AND DISCUSSION 5.1. Knowledge transferring for CTC-based models In this section, we e xamine our proposed approach to address the problem of aligning the CTC trained models. The base- line model for this section is trained with the multi-accent data (i.e., US, Indian and Hispanic English) which is used as a teacher model. Next, we train a US-specific (i.e., only trained with US English part of the corpus) student model in three settings: 1) trained from scratch with no guidance from the teacher (No-T eacher), 2) trained student model with λ = 0 . 5 , 3) trained student model with λ = 0 . 9 . W e examine two settings of student models to in vestigate how much the supervision of the teacher influences the student alignments, howe ver , a setting with λ = 1 . 0 is not reported because this setting does not result in better ASR performance. In all ex- periments, default v alues of λ and T are 0.9 and 4, respec- tiv ely (unless otherwise specified). T able 1 . Percentage of CSO between the multi-accent model (T eacher model) and different US-specific models. No T eacher T eacher λ :0.5 T eacher λ :0.9 T rain T est T rain T est T rain T est T eacher model 81% 78% 89% 82% 95% 87% T o examine the ov erlap between spikes of two CTC trained models, we obtain the index of maximum charac- ter per frame for each model, resulting in two sequences of character index es for each utterance. Next, we calculate an average of ov erlap between these two sequences for all utterances of the data, referred to as the ”characters’ spikes ov erlap” (CSO). T able1 shows the percentages of CSO for training and test utterances of US English data between the baseline and the three accent-specific models. The base- line and No T eacher model have approximately 80% CSO, showing the difference between CTC trained models’ spikes. Howe ver , training the student model under the guidance of the baseline model increases CSO to 95% for the train data. The proposed approach could increase CSO to an accept- able point for kno wledge distillation where we only need to hav e aligned models for training data. Howe ver , despite the CSO increase for the test data, there exists some room for improv ement in scenarios of ensembling the CTC models in the ev aluation step. T able 2 . CER% of adapting a multi-accent trained model to Indian accent using tempered KL-di vergence with three soft- outputs: Outputs of the multi-accent model (MA), outputs of accent-specific model with no teacher (No-T eacher) and an accent-specific student model with λ = 0.9 and T=4 (Student). The baseline performance is shown in the first ro w . MA (baseline: 14.2) + Adaptation MA [21] No-T eacher Student MA adapted 12.4 12.2 11.7 T o inv estigate whether having high CSO influences knowledge transferring between two models, we adapt the baseline model to Indian accent using tempered KL-div ergence [21] with three dif ferent soft-outputs (T able 2). Adapting the baseline model using outputs of the model itself as soft- outputs [21] results in a +12.7% relativ e CER improv ement compared to the baseline. Howe ver , adapting using the stu- dent model outperforms the former setting, demonstrating that accent-specific models provide better soft-outputs which represent the underlying similarities between characters of that accent. Using outputs of No-T eacher model as soft out- puts of the adaptation process performs better than using the baseline’ s soft outputs, demonstrating the efficac y of accent- specific models ev en with low CSO. 5.2. Improved multi-accent model with accent-specific teachers T o examine our proposed multi-step knowledge transferring (Figure 1), first, we train a multi-accent model with all accents pooled together without any teacher information (MA NT). T o this end, we train a student model with the same architec- ture to examine how much the single teacher model can regu- larize another multi-accent model (Figure 1-b). Having fixed soft character alignments from the teacher model not only generalizes the student model (MA ST), it makes the training more stable compared to CTC which changes the alignments dynamically during the training steps. As shown in T able 3, the resulting MA ST model achieves improv ed performance compared to MA NT model. T o consider the proposed two steps of knowledge transferring in the single teacher case, we exploit MA ST to teach an ev en more improved student model (MA ST1). This MA ST1 achiev es a greater decrease in CER for all accents, demonstrating the ef ficacy of knowl- edge distillation ov er multiple teacher-student generations. T able 3 . CER% of multi-accent without teacher model (MA NT), Multi-accent with a single teacher mode (MA ST), multi-accent with accent specific teacher (MA MT) and ac- cent specific models on US English, Hispanic English (HIS) and Indian English (IND). Model T eacher Model US HIS IND A ve MA NT None 14.1 13.5 14.2 13.9 A CC SP0 None 17.3 18.2 17.6 17.7 A CC SP MA NT 15.2 14.5 13.2 14.3 MA ST MA NT 11.9 11.6 12.0 11.8 MA ST1 MA ST 11.5 10.8 11.7 11.3 MA MT Acc Sp 11.3 10.8 11.4 11.2 Acc Sp1 MA MT 14.2 14.0 12.7 13.6 MA MT1 Acc Sp1 11.2 10.8 11.3 11.1 MA MT1 Adpt MA MT1 11.2 10.8 10.9 11 MA MT1 Adpt1 Acc Sp1 11.2 10.7 10.5 10.8 In this section, we inv estigate the ef fectiveness of having multiple accent-specific teacher models to train a multi-accent model. W e train three accent specific models from scratch as well as under the guidance of MA NT . Each model is only trained with the corresponding accent speech data (A CC SPs models). These resulting accent specific models perform better than accent specific models which are trained with no teacher (A CC SP vs. ACC SP0 in T able 3). These improve- ments sho w that using soft-outputs of the teacher model not only aligns the student models (T able 1), it regularizes them as well. W e leverage the three accent-specific aligned models (i.e., A CC SP US, ACC SP HIS, and A CC SP IND) to train an overall improved multi-accent multi-teacher model (MA MT). As shown in Figure 1, soft-outputs of each accent data are produced by the corresponding A CC SP model. The resulting model outperforms both former improved multi- accent models (MA ST and MA ST1), demonstrating that accent specific models provide better underlying relations between output characters, resulting in a more generalized student model. Comparing the av erage CER of A CC SP models (14.3%) with MA ST (11.8%) demonstrates that for our multi-accent data, accent-specific teachers are more ef- fectiv e than a superior multi-accent teacher model. Following the diagram of Figure 1 to transfer knowledge one step fur- ther , we achiev ed the best multi-accent model (MA MT1) which outperforms all other multi-accent models yielding a relativ e CER gain of +20.1% vs. baseline (MA NT). Adapt- ing the best multi-accent model to each accent using both Acc Sp1 (see Figure 1) and MA MT1 to regularize the adap- tation process, again supports the idea that accent specific model outputs perform better than multi-accent model out- puts (MA MT1 Adpt vs. MA MT1 Adpt in T able 3). 6. CONCLUSIONS In this study , we in vestig ate employing student-teacher learn- ing to advance an LSTM-CTC muli-accent model. W e pro- posed to train multiple CTC accent-specific models under the guidance of a single multi-accent teacher model to align their outputs. This approach not only aligned the CTC trained model, but also generalized the resulting student models. T o achiev e an advanced multi-accent model, we also pro- posed a novel approach of knowledge transfer, where we trained a multi-accent model (student model) under the su- pervision of accent-specific aligned models. The proposed method was shown to significantly outperform the base- line multi-accent model trained without any teacher model. Having this advanced multi-accent model leads to further improv ement, by training new accent-specific models from which we guide a new multi-accent model. This second step of knowledge transfer yields the best multi-accent model providing a +20.1% CER gain over the original baseline multi-accent model. Accent-specific models not only led to the best multi-accent model, their soft-outputs regularize the adapting process of the multi-accent model to each ac- cent. Finally , constraining the adapted model to imitate the accent-specific models’ outputs results in a more generalized adapted model compared to the method employing outputs of the multi-accent model itself. 7. REFERENCES [1] Alex Grav es, Na vdeep Jaitly , and Abdel-rahman Mo- hamed, “Hybrid speech recognition with deep bidirec- tional lstm, ” in Automatic Speech Recognition and Un- derstanding (ASR U), 2013 IEEE W orkshop on . IEEE, 2013, pp. 273–278. [2] Has ¸ im Sak, Andrew Senior , and Franc ¸ oise Beaufays, “Long short-term memory based recurrent neural net- work architectures for large vocab ulary speech recogni- tion, ” arXiv preprint , 2014. [3] Alex Grav es, Abdel-rahman Mohamed, and Geoffrey Hinton, “Speech recognition with deep recurrent neural networks, ” in Acoustics, speech and signal processing (icassp), 2013 ieee international confer ence on . IEEE, 2013, pp. 6645–6649. [4] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper , Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al., “Deep speech 2: End-to-end speech recog- nition in english and mandarin, ” in International Con- fer ence on Machine Learning , 2016, pp. 173–182. [5] Mohamed Elfeky , Meysam Bastani, Xa vier V elez, Pedro Moreno, and Austin W aters, “T ow ards acoustic model unification across dialects, ” in Spoken Language T ech- nology W orkshop (SLT), 2016 IEEE . IEEE, 2016, pp. 624–628. [6] Seyedmahdad Mirsamadi and John HL Hansen, “On multi-domain training and adaptation of end-to-end rnn acoustic models for distant speech recognition, ” Pr oc. Interspeech 2017 , pp. 404–408, 2017. [7] T ara N Sainath, Rohit Prabhavalkar , Shankar Kumar , Seungji Lee, Anjuli Kannan, David Rybach, Vlad Schogol, Patrick Nguyen, Bo Li, Y onghui W u, et al., “No need for a lexicon? ev aluating the value of the pro- nunciation lexica in end-to-end models, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE In- ternational Confer ence on . IEEE, 2017. [8] Ritwik Giri, Michael L Seltzer, Jasha Droppo, and Dong Y u, “Improving speech recognition in re verberation us- ing a room-aware deep neural network and multi-task learning, ” in Acoustics, Speech and Signal Pr ocess- ing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 5014–5018. [9] Midia Y ousefi, Soheil Khorram, and John HL Hansen, “Probabilistic permutation inv ariant training for speech separation, ” arXiv preprint , 2019. [10] John HL Hansen and Gang Liu, “Unsupervised accent classification for deep data fusion of accent and lan- guage information, ” Speech Communication , vol. 78, pp. 19–33, 2016. [11] Shahram Ghorbani and John HL Hansen, “Lev erag- ing native language information for improv ed accented speech recognition, ” Proc. Inter speech , 2018. [12] Rongqing Huang, John HL Hansen, and Pongtep Angki- titrakul, “Dialect/accent classification using unrestricted audio, ” IEEE T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 15, no. 2, pp. 453–464, 2007. [13] Kanishka Rao and Has ¸ im Sak, “Multi-accent speech recognition with hierarchical grapheme based models, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 4815–4819. [14] Jiangyan Y i, Hao Ni, Zhengqi W en, and Jianhua T ao, “Improving blstm rnn based mandarin speech recogni- tion using accent dependent bottleneck features, ” in Signal and Information Pr ocessing Association Annual Summit and Confer ence (APSIP A), 2016 Asia-P acific . IEEE, 2016, pp. 1–5. [15] Bo Li, T ara N Sainath, Khe Chai Sim, Michiel Bacchi- ani, Eugene W einstein, Patrick Nguyen, Zhifeng Chen, Y onghui W u, and Kanishka Rao, “Multi-dialect speech recognition with a single sequence-to-sequence model, ” arXiv pr eprint arXiv:1712.01541 , 2017. [16] T akashi Fukuda, Masayuki Suzuki, Gakuto Kurata, Samuel Thomas, Jia Cui, and Bhuvana Ramabhadran, “Efficient knowledge distillation from an ensemble of teachers, ” Pr oc. Interspeech 2017 , pp. 3697–3701, 2017. [17] Geoffre y Hinton, Oriol V inyals, and Jef f Dean, “Distill- ing the knowledge in a neural netw ork, ” stat , vol. 1050, pp. 9, 2015. [18] Shinji W atanabe, T akaaki Hori, Jonathan Le Roux, and John R Hershey , “Student-teacher network learning with enhanced features, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer - ence on . IEEE, 2017, pp. 5275–5279. [19] Jia Cui, Brian Kingsb ury , Bhuv ana Ramabhadran, George Saon, T om Sercu, Kartik Audhkhasi, Abhinav Sethy , Markus Nussbaum-Thom, and Andrew Rosen- berg, “Knowledge distillation across ensembles of mul- tilingual models for low-resource languages, ” in Acous- tics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 4825–4829. [20] Roger Hsiao, T im Ng, Le Zhang, Shivesh Ran- jan, Stavros Tsakalidis, Long Nguyen, and Richard Schwartz, “Improving semi-supervised deep neural net- work for keyw ord search in lo w resource languages, ” in F ifteenth Annual Confer ence of the International Speech Communication Association , 2014. [21] T aichi Asami, Ryo Masumura, Y oshikazu Y amaguchi, Hirokazu Masataki, and Y ushi Aono, “Domain adap- tation of dnn acoustic models using knowledge dis- tillation, ” in Acoustics, Speech and Signal Pr ocess- ing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 5185–5189. [22] Ian Goodfellow , Y oshua Bengio, Aaron Courville, and Y oshua Bengio, Deep learning , v ol. 1, MIT press Cam- bridge, 2016. [23] Chengzhu Y u, Chunlei Zhang, Chao W eng, Jia Cui, and Dong Y u, “ A multistage training framework for acoustic-to-word model, ” in Pr oc. Interspeech 2018 , 2018, pp. 786–790. [24] Alex Grav es and J ¨ urgen Schmidhuber , “Framewise phoneme classification with bidirectional lstm and other neural network architectures, ” Neural Networks , vol. 18, no. 5, pp. 602–610, 2005. [25] Jimmy Ba and Rich Caruana, “Do deep nets really need to be deep?, ” in Advances in neural information pr o- cessing systems , 2014, pp. 2654–2662. [26] Has ¸ im Sak, F ´ elix de Chaumont Quitry , T ara Sainath, Kanishka Rao, et al., “ Acoustic modelling with cd-ctc- smbr lstm rnns, ” in Automatic Speech Recognition and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 604–609. [27] Alex Grav es and Navdeep Jaitly , “T o wards end-to-end speech recognition with recurrent neural networks, ” in International Confer ence on Machine Learning , 2014, pp. 1764–1772. [28] Has ¸ im Sak, Andre w Senior , Kanishka Rao, Ozan Irsoy , Alex Grav es, Franc ¸ oise Beaufays, and Johan Schalk- wyk, “Learning acoustic frame labeling for speech recognition with recurrent neural networks, ” in Acous- tics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 4280–4284. [29] Has ¸ im Sak, Andrew Senior , Kanishka Rao, and Franc ¸ oise Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition, ” arXiv pr eprint arXiv:1507.06947 , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment