탄력적 머신러닝을 위한 알고리즘 병목 해소: Chicle 프레임워크
Chicle은 마이크로‑태스크 대신 ‘유니‑태스크’를 도입해 데이터 병렬성에 따른 수렴 악화를 최소화하면서도 탄력적 확장과 동적 로드 밸런싱을 지원하는 새로운 분산 학습 프레임워크이다. 실험 결과, 동일한 하드웨어 환경에서 기존 고정형 프레임워크와 경쟁 가능한 성능을 보이며, 자원 변동이 잦은 공유 클러스터에서도 효율적으로 학습을 진행한다.
저자: Michael Kaufmann, Kornilios Kourtis, Celestine Mendler-D"unner
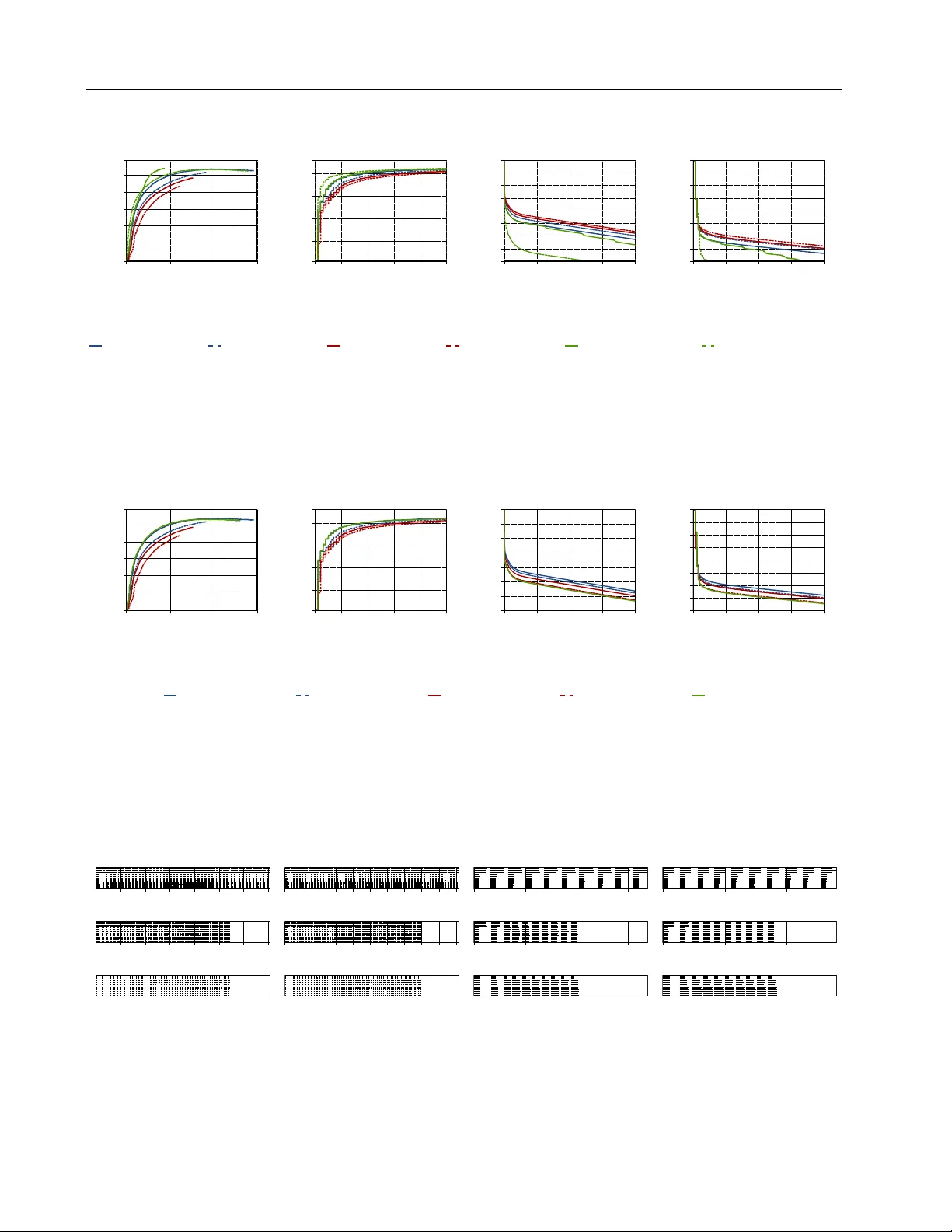
본 논문은 데이터센터에서 머신러닝 학습이 다른 워크로드와 공유되는 현실을 전제로, 탄력적 실행과 로드 밸런싱이 필수적인데 기존 분산 학습 프레임워크는 이를 충분히 지원하지 못한다는 문제점을 제시한다. 특히, 최근 몇몇 시스템이 마이크로‑태스크(Micro‑task) 방식을 도입해 탄력성을 확보하려 했지만, 마이크로‑태스크가 요구하는 높은 병렬도는 SGD·CoCoA와 같은 확률적 최적화 알고리즘의 수렴 속도를 크게 저하시킨다. 저자는 배치 크기와 파티션 수를 늘릴수록 epoch 수가 급증하는 실험 데이터를 제시하며, 이는 ‘알고리즘 병목’이라 명명한다.
이러한 병목을 해소하기 위해 저자들은 ‘유니‑태스크(uni‑task)’라는 새로운 작업 모델을 설계한다. 유니‑태스크는 각 노드가 하나의 장기 실행 멀티스레드 태스크만 수행하도록 제한하고, 학습 데이터를 고정 크기의 ‘데이터 청크’로 분할한다. 데이터 청크는 상태를 유지하면서 스케줄러가 필요에 따라 자유롭게 이동할 수 있다. 이 설계는 다음과 같은 장점을 제공한다.
1. **병렬도와 수렴 효율의 분리**: 데이터 청크 수와 배치 크기를 현재 사용 가능한 노드 수에 맞춰 동적으로 조정함으로써, 불필요하게 큰 배치를 사용해 수렴을 늦추는 상황을 방지한다.
2. **탄력적 스케일링**: 노드가 추가되면 스케줄러가 청크를 재분배해 작업 부하를 균등하게 만들고, 노드가 감소하면 청크를 합쳐서 남은 노드가 충분히 처리하도록 한다.
3. **로드 밸런싱**: 서로 다른 성능을 가진 heterogeneous 노드 간에도 청크 이동을 통해 작업량을 조절할 수 있어, 빠른 노드가 느린 노드 때문에 대기하는 현상을 최소화한다.
4. **낮은 오버헤드**: 마이크로‑태스크와 달리 태스크 수가 적어 스케줄링 비용이 크게 감소하고, 청크 이동은 메모리 복사 없이 메타데이터만 교환하므로 통신 오버헤드가 거의 없다.
Chicle 프레임워크는 이러한 유니‑태스크 모델을 구현한 시스템이다. 설계는 크게 세 부분으로 나뉜다. (1) **데이터 청크 관리** – 청크는 고정 크기의 샘플 블록이며, 각 청크는 소유 노드와 현재 사용 중인 배치 인덱스를 기록한다. (2) **스케줄러** – 중앙 스케줄러가 청크 소유권을 조정하고, 노드의 부하와 학습 진행 상황을 실시간으로 모니터링한다. (3) **학습 엔진** – 기존 mSGD, lSGD, CoCoA 알고리즘을 그대로 사용하면서, 각 노드가 로컬 청크에서 배치를 뽑아 업데이트하고, 주기적으로 전역 모델을 동기화한다.
실험은 두 가지 대표적인 워크로드를 대상으로 수행되었다. 첫 번째는 CIFAR‑10 데이터셋에 ResNet‑18을 학습시키는 딥러닝 실험이며, 두 번째는 Criteo 데이터셋에 SVM(또는 로지스틱 회귀) 모델을 CoCoA로 학습시키는 GLM 실험이다. 실험 환경은 동일한 하드웨어 클러스터에서 고정형 프레임워크(TensorFlow, PyTorch, 기존 CoCoA 구현)와 비교했으며, 다음과 같은 시나리오를 포함한다.
- **정적 자원**: 전체 노드가 처음부터 끝까지 동일하게 유지되는 경우.
- **동적 자원 감소**: 학습 중간에 30 %~50 %의 노드가 갑자기 사라지는 상황.
- **이질적 노드**: CPU와 GPU, 혹은 서로 다른 CPU 코어 수를 가진 노드가 혼합된 클러스터.
결과는 다음과 같다. 정적 자원 상황에서는 Chicle이 기존 고정형 프레임워크와 거의 동일한 epoch당 시간과 최종 정확도를 기록했으며, 일부 경우(특히 CoCoA)에서는 약간 더 빠른 수렴을 보였다. 동적 자원 감소 시나리오에서는 마이크로‑태스크 기반 시스템이 자원 감소에 따라 작업 대기 시간이 급증해 전체 학습 시간이 20 %~30 % 늘어나는 반면, Chicle은 청크 재배치를 통해 손실을 최소화해 전체 시간 증가가 5 % 이하에 머물렀다. 이질적 노드 환경에서도 Chicle은 청크를 빠른 노드에 더 많이 할당함으로써 로드 밸런싱을 자동으로 수행했고, 결과적으로 전체 처리량이 고정형 시스템보다 10 %~15 % 향상되었다.
논문은 또한 마이크로‑태스크와 유니‑태스크 사이의 이론적 차이를 정량화하였다. 마이크로‑태스크는 병렬도 \(P\)가 증가할수록 배치 크기 \(B\)가 최소 \(P\)가 되어야 하는 제약을 갖지만, 유니‑태스크는 \(B\)를 현재 활성 노드 수에 맞춰 자유롭게 조정할 수 있다. 이로 인해 수렴에 필요한 총 샘플 수 \(S = B \times E\) (E는 epoch 수) 가 크게 감소한다는 점을 수식으로 제시한다.
마지막으로 저자들은 Chicle이 현재의 클라우드·데이터센터 환경에서 비용 효율적인 머신러닝 서비스를 제공하기 위한 실용적인 솔루션이라고 주장한다. 마이크로‑태스크 기반 시스템이 갖는 스케줄링 유연성은 유지하면서도, 알고리즘 차원의 병목을 제거함으로써 탄력적·로드밸런싱이 가능한 새로운 프레임워크 설계 원칙을 제시한다. 향후 연구 방향으로는 더 복잡한 비동기식 최적화 알고리즘, 멀티‑GPU/TPU 지원, 그리고 스케줄러의 분산 구현 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기