Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle
Distributed machine learning training is one of the most common and important workloads running on data centers today, but it is rarely executed alone. Instead, to reduce costs, computing resources are consolidated and shared by different application…
Authors: Michael Kaufmann, Kornilios Kourtis, Celestine Mendler-D"unner
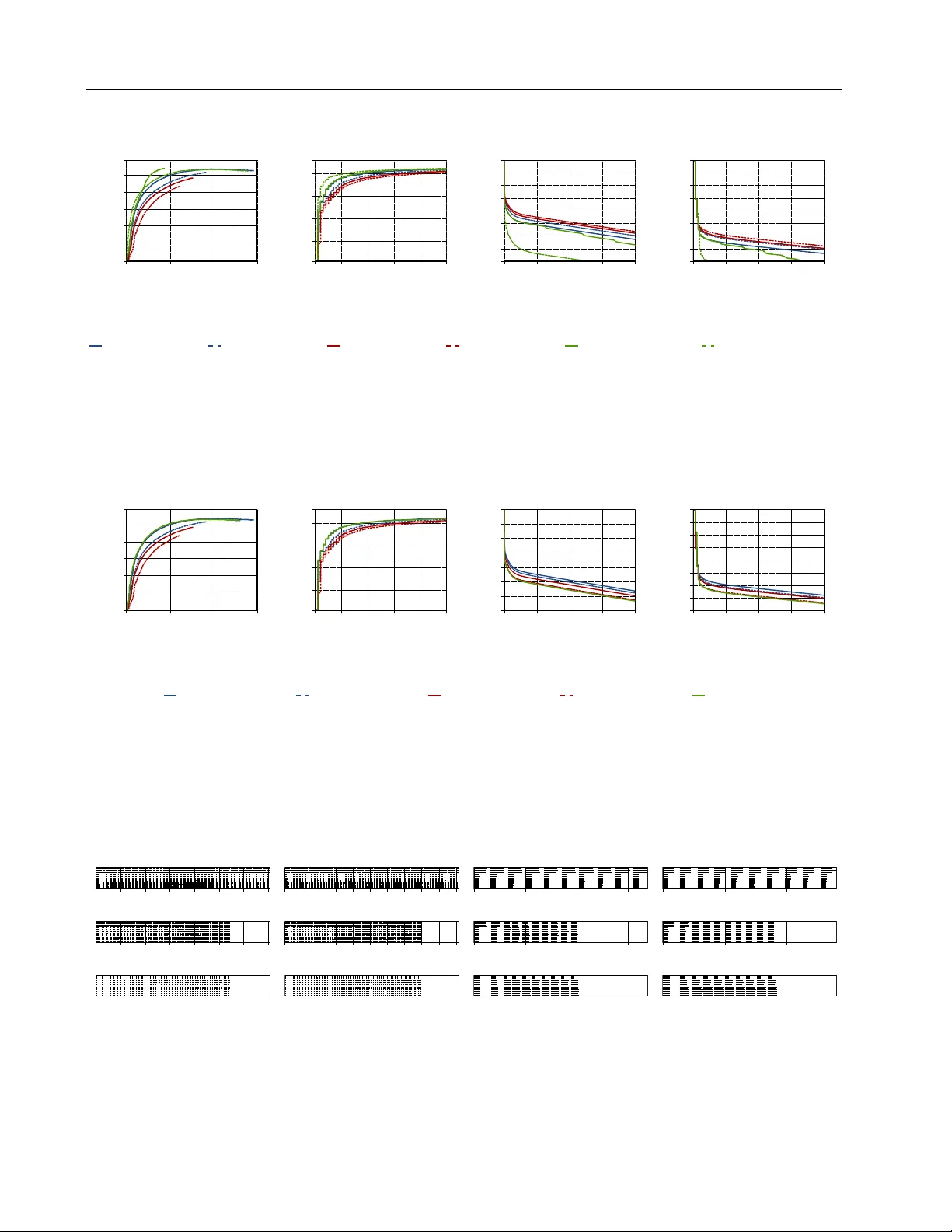
A D D R E S S I N G A L G O R I T H M I C B O T T L E N E C K S I N E L A S T I C M AC H I N E L E A R N I N G W I T H C H I C L E Michael Kaufmann 1 2 Kor nilios Kourtis 1 Celestine Mendler -D ¨ unner 3 Adrian Sch ¨ upbach 1 Thomas Parnell 1 A B S T R AC T Distributed machine learning training is one of the most common and important workloads running on data centers today , but it is rarely e xecuted alone. Instead, to reduce costs, computing resources are consolidated and shared by dif ferent applications. In this scenario, elasticity and proper load balancing are vital to maximize ef ficiency , fairness, and utilization. Currently , most distributed training frameworks do not support the aforementioned properties. A few e xceptions that do support elasticity , imitate generic distributed framew orks and use micro-tasks. In this paper we illustrate that micro-tasks are problematic for machine learning applications, because they require a high degree of parallelism which hinders the con ver gence of distrib uted training at a pure algorithmic le vel (i.e., ignoring overheads and scalability limitations). T o address this, we propose Chicle, a new elastic distrib uted training framew ork which exploits the nature of machine learning algorithms to implement elasticity and load balancing without micro-tasks. W e use Chicle to train deep neural network as well as generalized linear models, and sho w that Chicle achiev es performance competiti ve with state of the art rigid framew orks, while efficiently enabling elastic ex ecution and dynamic load balancing. 1 I N T R O D U C T I O N The e v er-gro wing amounts of data are fueling impressiv e ad- vances in machine learning (ML), b ut depend on substantial computational power to train the corresponding models. As a result, many research works focus on addressing scalabil- ity of distributed training across multiple machines. State of the art algorithms include Mini-batch SGD (mSGD) ( Rob- bins & Monro , 1951 ; Kiefer et al. , 1952 ; Rumelhart et al. , 1988 ) and Local SGD (lSGD) ( Lin et al. , 2018 ) for deep neu- ral networks (DNNs) as well as Communication-efficient distributed dual Coordinate Ascent (CoCoA) ( Jaggi et al. , 2014 ; Smith et al. , 2018 ) for generalized linear models (GLMs). Less work, howe ver , has focused on efficiency , which is equally (if not more) important because it effecti vely pro- vides more computational po wer at the same cost. Indeed, most works on distributed ML assume that they can operate on dedicated clusters, which is rarely the case in practice where ML applications co-inhabit common infrastructure with other applications. In these shared en vironments, effi- ciency depends on two properties: elastic e xecution : dynam- ically adjusting resource (e.g., CPUs, GPUs, nodes) usage as 1 IBM Research, Zurich, Switzerland 2 Karlsruhe Institute of T echnology , Karlsruhe, Germany 3 UC Berkele y , work conducted while at IBM Research. Correspondence to: Michael Kaufmann < kau@zurich.ibm.com > . their av ailability changes, and load balancing : distributing workload across heterogeneous resources ( Ou et al. , 2012 ; Delimitrou & K ozyrakis , 2014 ) such that faster resources do not ha ve to wait for slo wer ones. Elastic ex ecution, specifically , enables optimization opportunities for ML ap- plications where scaling-in or -out as training progresses can increase accuracy and reduce training time ( Kaufmann et al. , 2018 ). As of today , most ML distributed frame works (e.g., Abadi et al. ( 2016 ); Paszke et al. ( 2017 )) do not support elastic ex ecution nor load balancing, which makes them inherently inefficient in shared en vironments and on heterogeneous clusters. Recently , recognizing the importance of elasticity , a number of systems attempt to address elasticity ( Zhang et al. , 2017 ; Harlap et al. , 2017 ; Qiao et al. , 2018 ) for ML ap- plications using micro-tasks or similar mechanisms. Micro- tasks, where work is split up into a large number of short tasks ex ecuted as resources become a vailable, ha ve been ex- tensi vely used in generic distributed application frame works to address elasticity and load balancing ( Zaharia et al. , 2010 ; Ousterhout et al. , 2013 ), so they seem a natural fit for this problem. In this paper we argue that micro-tasks are ill-suited for ML training because they require a large number of short independent tasks for ef ficient scheduling. In order to sup- port full system utilization, the number of tasks has to be chosen based on the lar gest possible degree of parallelism an elastic system could potentially experience. The number Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle 0 10 20 30 8 16 32 64 128 256 512 1024 2048 data parallelism (batch size) # of epochs to converge (a) CIF AR-10 (mSGD/CNN) 0 30 60 90 120 16 32 64 data parallelism (# of partitions) # of epochs to converge (b) Criteo (CoCoA/SVM) Figure 1. Example of the correlation between data parallelism and the number of epochs needed to achiev e a certain training goal. of tasks, in turn, constitutes a lo wer bound on the data par - allelism of each update which means that you need to pick the mini-batch size in mSGD 1 or the number of partitions in CoCoA accordingly . This howe ver is not a desirable thing to do from an algorithmic point of view , since it is widely acknowledged that data parallelism comes at the cost of con ver gence in distrib uted ML applications. Note that when talking about con ver gence we refer to epochs to con verge, where an epoch refers to one pass through the entire dataset. Extensiv e studies of this impact for mSGD have, among others, been conducted by Shallue et al. ( 2019 ), K eskar et al. ( 2016 ) and Goyal et al. ( 2017 ). Figures 1a and 1b also ex- emplify this. The training of a simple conv olutional neural network (CNN) on the CIF AR-10 dataset using mSGD re- quires 44% more epochs to con ver ge when increasing the batch size from 256 to 512. Similarly , doubling the number of partitions from 16 to 32 for the training of a on the Criteo dataset using CoCoA ( Jaggi et al. , 2014 ; Smith et al. , 2018 ) increases the number of epochs to conv erge by 65%. While mitigation strategies, such as warm-up ( Goyal et al. , 2017 ) and layer-wise adapti ve rate scaling ( Y ou et al. , 2017 ) exist, the fundamental problem remains. Overall, micro-tasks lead to an inherent conflict between the number of tasks to use for scheduling efficienc y , where higher is better, and algorithmic ML training efficienc y , where lower is better . Fortunately , as we sho w in this paper, the iterativ e nature of ML applications allows implementing load balancing and elasticity without micro-tasks, thus eliminating the abov e inherent conflict. W e realize our ideas in Chicle 2 , an elastic, load balancing distrib uted framew ork for iterati ve- con ver gent ML training applications. Chicle combines scheduling flexibility with the ef ficiency of special-purpose rigid ML training frame works. Chicle uses uni-tasks and schedules (stateful) data chunks instead of tasks. Each node ex ecutes only a single (multi-threaded) task that processes training samples from multiple data chunks within a single ex ecution context. Data chunks can be moved ef ficiently 1 The mini-batch size needs to be chosen as a multiple of the number of tasks in order to keep relati ve job ov erheads low . 2 Chicle is the Me xican-Spanish word for late x from the sapodilla tree that is used as basis for chewing gum and a ref- erence to Chicle’ s elasticity . between tasks to balance load and to scale in and out. This allows Chicle to use the optimal lev el of data parallelism for the currently used number of resources and combines scheduling with algorithmic efficienc y . Con versely , Chicle is able to efficiently adjust the resource allocation based on feedback from the training algorithm and resource availabil- ity . The main contributions of our work are: 1) W e propose uni-tasks , a new task model that removes the conflict between scheduling and algorithmic ef fi- ciency . W e implement a prototype thereof in Chicle, a distributed ML frame work that enables elastic training and dynamic load balancing in heterogeneous clusters. 2) Our e valuation illustrates that uni-tasks require signif- icantly fewer epochs, and subsequently less time, to con ver ge in elastic and load-balancing scenarios com- pared to micro-tasks. Our paper is structured as follo ws: First, we provide neces- sary background information on the relationship between data parallelism and con ver gence for ML training algorithms as well as requirements for elastic execution in § 2 followed by a discussion of the main ideas behind uni-tasks ( § 3 ). W e continue with a detailed description of Chicle’ s design and implementation ( § 4 ) and present results of our experimental ev aluation ( § 5 ) and conclude ( § 6 ). 2 B AC K G R O U N D & M O T I V AT I O N Increasing parallelism for distributed e xecution of ML train- ing workloads has well-understood tradeof fs. On one hand, ample parallelism results in less work per each indepen- dent execution unit ( task ) which leads to increased ov er- heads ( T otoni et al. , 2017 ). On the other hand, ample par- allelism allo ws utilizing many nodes and enables ef ficient scheduling ( Ousterhout et al. , 2013 ), dealing with load im- balances, and supporting elasticity . Elasticity specifically is increasingly important, since to maximize the ef ficiency , distributed applications are expected to scale-in and -out based on workload demands of themselves and their co- habitants. Indeed, exposing ample parallelism by di viding the problem into man y micro-tasks is the standard way to implement elasticity despite the resulting execution ov er- heads. Litz ( Qiao et al. , 2018 ), for example, a recent ML elastic frame work uses micro-tasks and reports up to 23% of ex ecution overhead. While these overheads are important, our work is motiv ated by another tradeoff that is specific to ML applications but not well recognized in the ML systems community: increased data parallelism hinders the conv ergence of ML training. In contrast to overheads, this problem exists purely at the algorithmic lev el. Generally , distributed training algorithms require more steps to con ver ge in the face of high paral- Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle lelism ( Shallue et al. , 2019 ). The implication for b uilding elastic ML framew orks is that using micro-tasks, i.e., ample parallelism to gain scheduling fle xibility , leads to an inher - ent trade-off in terms of the number of the examples that need to be processed to con ver ge to a solution. In this section, we moti vate our design by illustrating this issue in two different ML algorithms: Mini-batch stochastic gradient descent (SGD), extensi vely used to train neural networks, and CoCoA, a state-of-the art frame work for dis- tributed training of GLMs. Prior to that, we pro vide some necessary background on elastic scheduling and ML train- ing. 2.1 Elasticity and load balancing Both load balancing and elasticity are necessary to ef fi- ciently utilize shared infrastructure. Both are typically im- plemented using micro-tasks in generic analytics frame- works, such as Spark ( Zaharia et al. , 2010 ) and ML frame- works ( Qiao et al. , 2018 ; Zhang et al. , 2017 ), where work is divided into a lar ge number of tasks that are distrib uted among nodes. T asks, i.e., self-contained, atomic entities of a function and input data, are a common abstraction of work, and represent the scheduling unit. Under a task scheduling system, a large number of tasks are required to achiev e efficiency . T o allo w elastic scale-out during training, the number of tasks needs to be at least as large as the maximum number of nodes that will be available at any point during training. Furthermore, common practice ov er-pro visions nodes with many tasks per node to allo w for efficient load balancing. The Spark tuning guidelines ( Spark , 2019 ), for instance, recommend to use of up to 2–3 tasks per av ailable CPU, while other works propose using millions of tasks ( Ousterhout et al. , 2013 ). 2.2 Distributed training algorithms Next, we discuss training in general and introduce two train- ing algorithms that we use in this paper . Most distributed training algorithms iterati vely refine a model m on a train- ing dataset D such that m con ver ges towards a state that minimizes or maximizes an objectiv e function. During each iteration i , an updated model m ( i ) is computed on a ran- domly chosen subset b D ⊆ D : m ( i ) = m ( i − 1) + f ∆ ( m ( i − 1) , b D ) (1) The update function f ∆ is computed in a data parallel man- ner across K nodes by splitting up b D into K disjoint parti- tions D k ⊆ b D . f ∆ ( m ( i − 1) , b D ) = 1 K K X k =1 f ∆ ,k ( m ( i − 1) , D k ) (2) The computation of f ∆ is self-correcting to a certain de- gree, i.e., bounded errors are averaged out in subsequent iterations, and can therefore be tolerated. This property is often exploited for ML-specific optimizations, e.g., to mit- igate stragglers ( Cipar et al. , 2013 ; Cui et al. , 2014 ; Dutta et al. , 2018 ; Ho et al. , 2013 ). The general structure of the algorithms we are considering is depicted in Figure 2 : K workers independently w ork on separate subproblems f ∆ ,k , each defined on a dif ferent partition D k of the data and then combine their results to update a global model m , which forms the basis of the next iteration. During each iteration, a worker processes H × L samples, of which H different sets of L independent samples are processed sequentially . After each set of L samples, a local model update is performed, such that learning on subsequent samples within an iteration can exploit kno wledge gained so far . | {z } H × | {z } one iteration local model update L × training sample K × 1 K P global model update Figure 2. General structure of distributed ML algorithms we con- sider in this paper . While our approach is applicable to a wide set of distributed ML training algorithms, in this paper , we focus on the fol- lowing tw o algorithms. Local SGD ( Lin et al. , 2018 ). A state-of-the-art algo- rithm and improv ement upon mSGD, the de-facto standard for training of neural networks (NNs) and variants thereof. Here, b D refers to the batch and | b D | = H × L refers to the batch size hyper-parameter (e.g. | b D | = 64 ). F or , H = 1 lSGD degrades to mSGD. The negati ve ef fect of data par - allelism on the conv ergence of is a fundamental property of mSGD. An extensi ve study of this property is presented by Shallue et al. ( 2019 ). CoCoA ( Jaggi et al. , 2014 ; Smith et al. , 2018 ). A state- of-the-art distributed frame work for the training of GLMs. It is designed to reduce communication and thus processes significantly more samples per iteration than, e.g., mSGD. W e use CoCoA with a local stochastic coordinate descent (SCD) solver ( Wright , 2015 ). The structure in Figure 2 is parameterized with L = 1 , H = | b D | , whereas b D = D . The local update function f ∆ ,k is computed by a local optimizer on partitions D k , with D = S K k =1 D k . In a homogeneous setting each node typically processes 1 /K -th of the training dataset per iteration. Data parallelism is determined by the Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle number of partitions K . Local optimizers detect correlations within the local dataset without global communication, i.e., the more data is randomly accessible to each optimizer instance, the less epochs are needed for CoCoA to con verge. Con versely , if data access is limited in size, as would be the case when using many tasks, or if no random access is possible, con ver gence suffers. Kaufmann et al. ( 2018 ) empirically study the relationship between con ver gence rate and K and show that by starting with a lar ge K and reducing it after a fe w iterations, con ver gence rate per epoch and time can be increased significantly . Summary . Both algorithms exhibit an inherent trade-of f between data parallelism and conv ergence. Intuiti vely , a higher degree of parallelism limits the opportunity to learn correlations across samples, and thus hurts con v ergence. While we focus on two particular methods in this paper, the trade-of f between parallelism and con ver gence is fundamen- tal in parallel stochastic algorithms. 2.3 Micro-tasks for distrib uted training As exemplified in Figure 1 , increasing data parallelism comes at the cost of increasing the total amount of work to achiev e a certain training goal. Up until a point, the cost in- crease is smaller than the gain in potential parallelism, such that ov erall training time can be reduced by increasing the data parallelism. This, ho we ver , is only true if and only if all tasks are ex ecuted in parallel. In shared and heterogeneous en vironments, this is generally not true. Consider the CIF AR-10 example from Figure 1 . For sim- plicity , we assume perfect linear scaling and zero system ov erheads. If one wanted to train on up to 256 nodes, at least 256 tasks are required and thus a data parallelism of 256 or higher . According to the data in Figure 1 , this re- quires 10 epochs to con ver ge. Assuming that one epoch in this configuration – where all 256 tasks can run in parallel – requires one second, training completes after 10 seconds. The nature of shared systems is, ho wev er , that there are not always enough nodes av ailable to e xecute all tasks in parallel. For instance, let us assume that only 128 nodes are av ailable during the runtime of the application. Then each epoch with 256 tasks requires two seconds as tw o tasks hav e to run back to back on each node, resuling in a total training time of 20s. If one had used a data parallelism of only 128 from the beginning, instead of 256, training would only require eight epochs or 16s, instead of 20s, resulting in a training time reduction of 20%. This example illustrates the dif ficulty of elastic scaling of ML training using a micro- task-based system: In many cases, it is only ef ficient if the maximal number of nodes (resources) are actually a vailable during most of the runtime. This, howe ver , stands in con- trast to the goals of elasticity . This problem is e ven more pronounced if we also consider load balancing between dif- ferently fast nodes. The number of tasks required to allo w for fine-granular work redistrib ution is disproportionately higher than just for elastic scaling alone. 3 U N I - T A S K S F O R D I S T R I B U T E D T R A I N I N G In the previous section, we sho wed how micro-tasks inhibit the performance of distrib uted training. In this section we argue that a different execution model, uni-tasks, is bet- ter suited for ML training applications. The core idea is very simple: to only use a single task per node. While this in itself is not a ne w concept, scientific computing has been using MPI that follo ws this approach for decades, the difficulty is to address the scheduling challenges that are typically addressed by micro-tasks, namely elasticity and load-balancing. Fortunately , we can exploit the iterativ e nature of ML training to tackle these challenges. Core concepts. Uni-tasks consists of two main concepts: immobile tasks and mobile data chunks. 1. All training samples are stored across a large set of small fixed-sized (stateful) data chunks that can be mov ed between tasks by the scheduler . Data chunks can store dense and sparse training data vectors and matrices of variable size. 2. Each node only executes a single task per node (hence the name uni-tasks). Each task has full, random access to all training samples across all data chunks that are local to a task. Additionally , a contract between the scheduler and the appli- cation is defined that regulates o wnership of a data chunk. 1. During an iteration, a task owns all task-local data chunks. It can read all and make modifications to data stored in the data chunks, e.g., to update per -sample state (e.g., as needed in CoCoA). During this period, the scheduler does not add or remov e data chunks. 2. In-between two iterations, the scheduler o wns all data chunks. T asks must not modify any data chunks and the scheduler is free to add or remo ve data chunks from any task. T asks are notified by the scheduler of any data chunk addition or remov al. By mo ving data chunks between tasks in-between iterations, uni-tasks allows one to add and remov e tasks for elastic scaling and to balance load across tasks on heterogeneous clusters. Uni-tasks assumes a correlation between the num- ber of training samples in task-local data chunks and the number of samples processed by each task during each it- eration. In contrast to micro-tasks, scheduling granularity Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle is determined by the number of data chunks, not by the number of tasks. The number of data chunks does not con- stitute a lower bound for the lev el of data parallelism, as multiple data chunks are processed by the same task, hence the number le vel of data parallelism can be lower than the number of data chunks. In contrast to MPI, uni-tasks defines a method to shift load between tasks. In the follo wing paragraphs, we discuss how elasticity and load balancing are addressed for distrib uted training when using uni-tasks. Elasticity . Elasticity is necessary to ef ficiently and fairly utilize resources in shared clusters, to reduce waiting times for job starts, and to react do v arying resource demands of applications throughout their runtime. W e address elasticity in the uni-tasks setting by spawning ne w tasks as nodes are added to the application and by terminating them if nodes need to be released. In both cases data chunks are redis- tributed across all av ailable tasks. In the latter case, ho we ver , a prior notification is required such that data chunks can be transferred before the task is terminated. Elastic scaling is only possible in-between iterations. The application is free to adjust the le vel of data parallelism during each iteration to any value equal or larger than the number of tasks. For both test applications, we al ways choose the lowest possible v alue. Load balancing. Load balancing is necessary to deal with heterogeneity between cluster nodes as well as between different hardware (e.g., CPUs vs GPUs) that results in runtime differences between tasks that process the same amount of input data. T o address heterogeneity , we exploit the f act ML training al- gorithms are typically iterati ve and process a known amount of training samples during each iteration, which allows us to learn how long each task needs to process a training sam- ple. Uni-tasks assumes that the number of training samples processed by each task is a fraction of the total number of training samples across all task-local data chunks, e.g., a task with twice as many training samples as another task also processes twice as many per iteration. This enables the scheduler to influence the runtime by mo ving data chunks from tasks on slo wer to tasks on faster nodes until their runtime aligns. As tasks may process a dif ferent number of training sam- ples during each iteration, their model updates need to be weighted dif ferently as well (as proposed in Stich ( 2018 )). W e do this by multiplying the model update f ∆ ,k of task k by D k / b D (see Equation 2 ). 4 C H I C L E D E S I G N A N D I M P L E M E N TA T I O N Here, we describe how Chicle implements an elastic dis- tributed training frame work using uni-tasks. Solv er Solv er Solver P olicy P olicy Policy T rainer Driver W orker control data/model metrics metrics decisions decisions metrics data/model Figure 3. High-lev el architecture of Chicle. 4.1 Overview Chicle, as shown in Figure 3 , is based on a dri ver/work er design with a central dri ver ( trainer ) and multiple workers ( solvers ) communicating via a RDMA-based RPC mech- anism (see § 4.3 ). The driver executes the trainer module, which, in tandem with multiple policy modules, is responsi- ble for coordinating training. Policy modules make schedul- ing decisions, such as assigning chunks, balancing load, and scaling in and out. W orker processes execute solver modules (uni-tasks) and implement the ML algorithms (e.g., SCD for CoCoA). Crucially , only a single (multi-threaded) worker process is ex ecuted per node. Solvers are controlled by the trainer and polic y modules, which in turn recei ve model and state updates as well as metrics (e.g., duality-gap). Chicle applications need to implement a trainer and solv er module, and may optionally implement polic y modules to control system beha vior during training. For instance, our lSGD implementation uses libtorch (from PyT orch ( Paszke et al. , 2017 )) in the solv er for forward and backw ard prop- agation steps. The trainer module acts as synchronous pa- rameter server that merges updates from solv er instances. A simplified version of the lSGD code is sho wn in Listing 1 . In the remainder of this section, we elaborate on each mod- ule as well as the communication subsystem and in-memory data format of Chicle. 4.2 T rainer and solver The trainer and solver modules represent application code. T rainer modules are the central controlling entity and co- ordinate indi vidual solver instances in tandem with policy modules. Policy modules can implement comple x (reusable) Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle optimizations (e.g., online hyper -parameter tuning), and solver modules implement arbitrary functions for distributed ex ecution. Only a single solver module is ex ecuted per node and application, therefore, each solv er module can internally spawn threads and use all CPUs or GPUs of a node. Trainer and solver modules periodically synchronize at global barri- ers, e.g. in-between iterations, but can exchange additional messages at any time. 4.3 Communication subsystem In distributed training, communication can easily become a bottleneck. For example, using CoCoA to train a model for the Criteo dataset (see T able 1 ), each task has to send/recei ve ≈ 16MiB in updates in-between iterations. For that reason, we built our communication subsystem on RDMA. RDMA allows lo w-overhead, zero-copy , one-sided operations for bulk data transfers, such as model and training (input) data as well as two-sided remote procedure calls (RPCs) using RDMA send/receiv e. 4.4 In-memory chunk data format T o fully exploit RDMA, data is stored in static, consecutive memory regions. The in-memory representation of training (input) data is based on fixed-sized data chunks. Chunks can store sparse or dense training data vectors and matri- ces. The number of training samples per data chunk can vary depending on their size. Chunks allow to easily mo ve training data subsets between nodes. The chunk size can be tuned to an optimal value depending on dataset and system properties, e.g. to the CPU cache size. Chicle’ s in-memory format is application agnostic and sim- ply provides applications a contiguous memory space that can be mov ed across nodes in-between iterations. For in- stance, our lSGD implementation stores the backing mem- ory of nativ e PyT orch tensor objects in data chunks wheras for CoCoA, we simply store sparse vectors as well as per- sample state in a data chunk. Having the ability to store per-sample state in a data chunk is important as it ensures that state and the data it correlates to are always moved together . One important limitation of Chicle’ s data chunk is that they must not require any serialization, as one-sided RDMA read operations are used to transfer them. Deserialization is pos- sible. In the case of PyT orch, for instance, we restore tensor objects via the torch::from blob function, which cre- ates a new tensor object back ed by the in-chunk data. 4.5 Policies Chicle implements a flexible policy framework which we use to implement vital parts of the system. Policies make decisions based on ev ents and metrics they receiv e from trainer and solver modules and return proper decisions for them. Each policy module runs in a separate thread and multiple policy modules can run at the same point in time. Policy modules coordinate with the trainer and can coordi- nate with each other . Next, we present the most relev ant policy modules. Elastic scaling policy . This module interfaces with the resource manager , e.g., Y ARN ( V a vilapalli et al. , 2013 ), to make resource requests and get resource assignment and rev ocation notices. Upon receiving a new resource assign- ment, it re gisters a ne w w orker (task) and notifies the trainer . After the current iteration, it shifts data chunks from old to new workers. It relies on the rebalancing policy ( § 4.5 ) to ensure proper load balancing. Chicle e xpects the resource manager to gi ve adv ance notice before rev oking a resource allocation. Upon receiving such a notice, it redistributes data chunks from to-be freed work ers to remaining ones in a round robin fashion. As before, it relies on the rebalancing policy to ensure load balance. Rebalancing policy . The rebalance policy observes itera- tion runtimes o ver multiple iterations to learn the per -sample runtime of each task, as described abov e. Between iterations, solvers are rank ed according to their median performance ov er the last I iterations and chunks mov ed gradually , across multiple iterations, from slo wer to faster solvers until perfor- mance dif ferences are smaller than the estimated processing time of a single chunk. This policy can also be used to ad- dress slowly changing performance of nodes, e.g. ones that are caused by the start/end of long running background jobs and restore balance after scaleing in and out. Its robustness against runtime fluctuations can be adjusted by tweaking I . W e decided against reloading data from a (shared) filesys- tem as data loading turned out to be more e xpensiv e than transferring loaded data between nodes, especially if input files are stored on a shared network filesystem. Moreover , our in-memory format can combine data chunks with the corresponding state, which needs to be transferred between workers an yway . Other policies. Apart from the abov e described policies, we have implemented policies for straggler mitigation, global background data shuffling and others. 5 E V A L UAT I O N Our ev aluation sho ws ho w Chicle performns in an elastic setting where nodes are added and removed during training and on a heterogeneous cluster where nodes are differently fast. As no other elastic, load-balancing ML training frame- work is publicly a vailable, we emulate micro-tasks with Chicle. Additionally , we compare Chicle with two state-of- Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle the-art rigid ML training framew orks in non-elastic, non- heterogeneous scenario to establish a performance baseline. 5.1 Evaluation setup and methodology Our test cluster consists of 16+1 nodes. Nodes are equipped with Intel Xeon E5-2630/40/50 v2/3 with 2.4 – 2.6GHz and 160 – 256GiB RAM. W e execute Chicle inside Docker containers. For some heterogeneity experiments, we reduce the CPU frequency of four nodes from 2.6 to 1.2GHz. All nodes are connected by a 56GBit/s Infiniband network via a Mellanox SX6036 switch. During experiments, up to 16 nodes are used for workers and one node for the Chicle driv er . Our test applications are lSGD and CoCoA, using test ac- curacy as a metric for con vergence for the former and the duality-gap ( Jaggi et al. , 2014 ; Smith et al. , 2018 ) for the latter . W e train on each dataset for ≈ 20 minutes, after which we terminate the training. Each experiment is repeated fi ve times and average results are presented. T able 1 lists all datasets we use during the ev aluation. The chunk size is set to 1MiB in CoCoA experiments and, due to the smaller dataset sizes, 200KiB for lSGD experiments. T able 1. Number of samples (#S), features (#F) and categories (#C) of datasets used in the ev aluation. Size is giv en for the in-memory representation. D AT A S E T # S # F # C S I Z E H I G G S 1 1 M 2 8 2 2 . 5 G I B C R I T E O 4 6 M 1 M 2 1 5 G I B C I F A R - 1 0 6 0 K 30 7 2 1 0 1 6 2 M I B F A S H I O N - M N I S T 7 0 K 7 8 4 10 3 0 M I B Synchronous local SGD. W e implemented lSGD ( Lin et al. , 2018 ) for Chicle based on libtorch, the C++ backend of PyT orch ( Paszke et al. , 2017 ). W e train a CNN with relu activ ation composing of two con v olutional layers with max- pooling followed by 3 fully connected layers on the CIF AR- 10 and Fashion-MNIST datasets using lSGD. W e use L = 8 and H = 16 , a momentum of 0.9 and a base learning rate α of 1e-4 for CIF AR-10 and 5e-4 for Fashion-MNIST . According to best practice, we scale the learning rate with the square root of the number of tasks K such that the effecti v e learning rate α 0 = α × √ K . The global batch size (number of samples processed during each iteration across all tasks) is K × L × H . For micro-tasks, we select four values for K = { 16 , 24 , 32 , 64 } . Using different v alues of K allows us to assess the trade-of f between scheduling and algorithmic efficienc y . Here, K remains constant during the training. For uni-tasks K equals number of currently used nodes. As mSGD is a special case of lSGD with H = 1 we trivially also support mSGD, which we use for baseline comparisons with PyT orch. CoCoA. W e implemented CoCoA with a local SCD solver for Chicle based on the original Spark implemen- tation ( Smith , 2019 ). W e train a support vector machine (SVM) on the Higgs and Criteo datasets. W e use SCD as local solver with L = 1 and H equal to the number of local training samples. The number of tasks K is the same as abov e. The algorithm parameter σ is set to the the number of tasks, and the regularization coef ficient λ to the number of samples × 0.01. Micro-tasks. As no elastic ML training framework based on micro-tasks (or any other technique) is publicly av ail- able and general-purpose framew orks such as Spark do not perform competitively ( D ¨ unner et al. , 2017 ), we emulate micro-tasks using Chicle with a constant number of tasks K and measure the con ver gence rate per epoch. It is possible to do this accurately because in micro-tasks, con vergence rate per epoch only depends on the number of tasks but not on the number of nodes or on which node a task is e xecuted on. It does not, ho wev er , allo w us to directly measure the con- ver gence rate over time for micro-tasks. Instead, we project the latter by assuming an optimal schedule for the number of tasks, nodes and relativ e node performance. Henceforth, the number of micro-tasks is giv en in parentheses. Using Chicle to emulate micro-tasks during elasticity and load balancing experiments has the additional benefit of keeping implementation-specific v ariables, such as the im- plementation of the training algorithms (lSGD and CoCoA), the communication subsystem (e.g., RDMA vs. TCP/IP), and other factors constant. 5.2 Baseline comparisons W e compare Chicle against Snap ML ( D ¨ unner et al. , 2018 ) for CoCoA and PyT orch ( Paszke et al. , 2017 ) for mSGD in a non-elastic, non-heterogeneous scenario using the same training algorithms, hyper-parameter v alues and datasets on the test setup described abov e. None of the novel function- ality of Chicle was used in this experiment. The purpose of this experiment is to sho w that Chicle does not impair performance in the normal non-elastic, non-heterogeneous case. W e measure con v ergence rate per epoch and over time. Detailed results of this experiment are provided in § A.1 and are summarized here. Con ver gence behavior per epoch for mSGD is identical on Chicle and PyT orch while Chicle requires slightly less time per epoch. Compared to Snap ML, Chicle performed vir- tually identically for the Higgs dataset but outperformed it for the Criteo dataset due to dif ferences in data parti- tioning. This experiment confirms that Chicle’ s baseline performance is on par with that of highly optimized, estab- Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle lished ML training framew orks. In contrast to those, Chicle is able to elastically scale during execution and balance load in heterogeneous clusters. Both aspects are ev aluated in the following. 5.3 Elastic scaling In this section, we e valuate Chicle with the elastic scaling policy enabled in two elastic scenarios and compare it to micro-tasks. Specifically , we consider: i) the ef fect of data parallelism (batch size for lSGD, and number of partitions for CoCoA) on the number of epochs to con ver ge, and ii) the trade-off between scheduling efficiency and conv ergence under micro-tasks. Methodology . Our test scenarios consist of gradual scale- in from 16 to 2 nodes and scale-out from 2 to 16 nodes. W e add (remove) 2 nodes every 20s until the maximum (minimum) number of nodes is reached. During each run, we measure con vergence per epoch and project con ver gence ov er time using an optimal schedule for uni-tasks and micro- tasks for each number of nodes. In micro-tasks, elastic scaling works by distributing a fixed number of tasks across more or fewer nodes and not by adjusting the number of tasks. Moreover , the number of nodes is typically not known by the application. Hence, we assume a fixed number of tasks independently of the nodes used. T o project the time per iteration, we assume a normalized task runtime (one task, processing 1 / 16 th of the data takes one time unit) and compute the number of task w av es necessary for each iteration. • K micro-tasks on N nodes require d K/ N e task w aves, as only N tasks can be executed at the same time. In consequence, each iteration requires 16 /K × d K / N e time units. For instance, K = 32 tasks on N = 14 nodes require d 32 / 14 e = 3 task wa ves and 16 / 32 × 3 = 1 . 5 time units per iteration. • For CoCoA on uni-tasks, load is redistributed such that a single iteration takes 16 / N time units. For instance, on 14 nodes, one iteration requires 16 / 14 = 1 . 14 time units. For lSGD on uni-tasks, the batch size is adjusted such that each iteration still only requires one time unit. Instead, the number of iterations per epoch increases by 16 / N . Our time projections do not include data transfer ov erheads. As each task needs to communicate model updates, the total communication volume of micro-tasks is as least as high as that of uni-tasks, hence by ignoring data transfer ov erheads, we fa vor micro-tasks. Results. Figure 4 sho ws detailed con vergen ve over time plots for elastic scale-in and out for different data parallelism values. Con ver gence per epoch results are pro vided in the appendix ( § A.2 ). Generally , the higher the data parallelism, the more epochs are needed to con verge for micro-tasks, which is consistent with our initial problem statement and previous studies ( Shallue et al. , 2019 ). As Figure 4 shows, the increased scheduling efficienc y of using more micro- tasks cannot compensate for the reduced con vergence rate per epoch and micro-tasks (16) consistently outperforms other micro-tasks configurations. Moreov er , the con vergence rate over time with uni-tasks is equal or higher during scale-in and -out, showing that the ability to adjust the le vel of data parallelism across a wide range can improv e con ver gence per epoch and ov er time. 3 This ability is not only beneficial in shared en vironments but can also be exploited to accelerate the training process in general. Kaufmann et al. ( 2018 ) show for CoCoA, that scaling in training at specific points in time can accelerate training by up to 6 × . Smith et al. ( 2017 ) report that increas- ing the batch size as alternati ve to reducing the learning rate once con ver gence slows down is beneficial for mini-batch SGD. Both cases could be implemented with Chicle. Howe ver , results differ across algorithms and datasets. For lSGD, scale-in as well as scale-out on uni-tasks improves con ver gence over time compared to the best micro-tasks configuration. In the scale-out case, the global batch size for uni-tasks is smaller in the beginning b ut equalizes with micro-tasks (16) quickly as nodes are added. In the scale-in case, the global batch size for uni-tasks is the same as for micro-tasks (16) in the be ginning b ut is quickly reduced. As it is smaller for longer , compared to the scale-out case, the con ver gence benefits over micro-tasks (16) are higher in the scale-in case. The av erage maximal test accuracy for uni-tasks is virtually identical to that of micro-tasks (16), which is the best micro- tasks configuration in all b ut one case: In the scale-in case for CIF AR-10, uni-tasks achiev es an av erage maximal test accuracy of 65.6% compared to 65.0% for micro-tasks (16). Results for CoCoA are similar . Scaling in reduces the num- ber of epochs as well as time to con ver ge, as suggested in Kaufmann et al. ( 2018 ). After each scale-in step (which can be identified in Figure 4c and Figure 4d ) con ver gence rate improv es. The reason for this behavior is that the local SCD solver has access to additional training data and can therefore identify new correlations across training samples locally . Scaling out behaves similarly which is, at first sight, counter intuituve as e very task gets to see fewer and fewer training samples as training scales out. Howe ver , during scale-out the data chunks that are moved to newly added tasks are picked randomly from each old task which effec- 3 Applications are free to choose an y lev el of data parallelism equal or larger the number of tasks if it benefits con v ergence. Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.7 0 20 40 60 80 100 time (projected) test accuracy 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.7 0 12 24 36 48 60 time (projected) test accuracy (a) CIF AR-10 (lSGD) 0.5 0.5 0.6 0.7 0.8 0.9 1.0 1.0 0 20 40 60 80 100 time (projected) test accuracy 0.5 0.5 0.6 0.7 0.8 0.9 1.0 1.0 0 20 40 60 80 100 time (projected) test accuracy (b) Fashion-MNIST (lSGD) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 20 40 60 80 100 time (projected) duality−gap 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 20 40 60 80 100 time (projected) duality−gap (c) Higgs (CoCoA) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 20 40 60 80 100 time (projected) duality−gap 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 20 40 60 80 100 time (projected) duality−gap (d) Criteo (CoCoA) micro-tasks (16) micro-tasks (32) micro-tasks (48) micro-tasks (64) uni-tasks Figure 4. Con vergence over time (projected) vs. data parallelism for elastic scale-in (top) and scale-out (bottom) experiments. The number of micro-tasks is giv en in parentheses. T ime is normalized to 100 time units. tiv ely shuffles training samples. This also allows the solv er to identify new correlations locally while also decreasing the duration of each iteration. 5.4 Load balancing In this section, we compare Chicle, with the load balancing policy enabled, to micro-tasks in a heterogeneous scenario with nodes of different speed. Such a scenario can occur in practice, as compute clusters are often not replaced com- pletely but e xtended and partially replaced ov er time using multiple generations of hardware (e.g., CPUs, GPUs) ( De- limitrou & K ozyrakis , 2014 ). Even the same cloud instance type can be backed by dif ferent models and generations of hardware ( Ou et al. , 2012 ). In a heterogeneous scenario, faster nodes should perform more of the overall work than slower nodes, such that all nodes finish at the same time for each iteration. In a micro- task based system, this is achie ved by scheduling more tasks on fast nodes than slo w nodes. This, ho wev er , requires multiple tasks to be executed per node so that one or more of them can be moved to other nodes. In consequence, no load balancing is possible with micro-tasks (16) on our 16 node test cluster . Chicle balances load by shifting data chunks, of which there are typically hundreds or thousands, from slow nodes to fast nodes and by adjusting the number of samples that individual uni-tasks process in each iteration, such that all tasks finish at the same time, independently of the node performance. Methodology . W e ev aluate heterogeneous load balancing in two scenarios: 1) W e configure the load balancing policy of Chicle to assume eight fast and eight slow nodes, with the latter being 1.5 × slower than the former and measure the number of epochs to con verge. This simple scenario allows us to project time to con vergence. 2) W e execute Chicle with the load balancing policy enabled on our test cluster where the CPU frequency of four nodes has been reduced to increase the le vel of heterogeneity . W e measure the task and iteration runtimes as well as the number of data chunks of each task across the load balancing process to show ho w Chicle can correctly learn task runtime and balance load in response. In micro-tasks, load balancing works by balancing fixes- size tasks across all nodes and not by adjusting the number training samples per task. Hence, we assume that each task processes the same number of training samples per iteration. T o project the time per iteration, we assume a normalized task runtime: One task, processing 1 / 16 th of the data takes one time unit on the fast nodes and 1.5 time units on the slow nodes. W e use this to compute the optimal (shortest) schedule for each iteration. • For micro-tasks, K tasks on eight fast and eight slo w nodes, the optimal schedule is max( i × 1 . 5 s, j × 1 . 0 s ) × 16 /K long with i ( j ) being the number of tasks on each slow (fast) node such that the schedule length is minimal. For instance, with K = 64 tasks, the optimal schedule is max(3 × 1 . 5 s, 5 × 1 . 0 s ) × 16 / 64 = 1 . 25 s per iteration. Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle 0.10 0.21 0.31 0.41 0.51 0.61 0.70 0 20 40 60 80 100 time (projected) test accuracy (a) CIF AR-10 (lSGD) 0.50 0.59 0.69 0.79 0.89 0.95 0 20 40 60 80 100 time (projected) test accuracy (b) Fashion-MNIST (lSGD) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 0 20 40 60 80 100 time (projected) duality−gap (c) Higgs (CoCoA) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 20 40 60 80 100 time (projected) duality−gap (d) Criteo (CoCoA) micro-tasks (16) micro-tasks (32) micro-tasks (48) micro-tasks (64) uni-tasks Figure 5. Con vergence over time (projected) when balancing load balancing in a heterogeneous cluster . The number of micro-tasks is giv en in parentheses. T ime is normalized to 100 time units. • For uni-tasks, load is redistributed such that fast nodes process 1.5 × as many training samples as slo w nodes, resulting in an iteration duration of 1 . 2 s . As before, our time projections do not include data transfer ov erheads, which fav ors micro-tasks. Results. Figure 5 sho ws detailed con vergen ve over time plots for different data parallelism values. Con ver gence per epoch results are sho wn in § A.3 . Per epoch, Chicle con ver ges as fast as micro-tasks (16). Over time, howe ver , Chicle con ver ges faster than an y micro-tasks configuration as it requires as few epochs to con v erge as micro-tasks (16) but can balance load more ef fectiv ely than micro-tasks (64), which reduces iteration duration and thus combines algo- rithmic and scheduling efficienc y . For lSGD, the average maximal test accuracy is ≈ 0.5% lo wer with uni-tasks than with micro-tasks (16). Howe ver , no load balancing is actu- ally possible with the latter . Compared to other micro-task configurations, uni-tasks achiev es a similar av erage maximal test accuracies. For CoCoA, uni-tasks con verges virtually identical to micro-tasks (16) per epoch but outperforms it ov er time due to its ability to balance load more effecti vely . Swimlane diagrams in Figure 6 visualize the load balancing process for the Criteo dataset on our test cluster where the CPU frequency of four nodes has been reduced to 1.2GHz to improv e the visibility of this process. Results for the other datasets are similar and provided in the appendix ( § A.3 ). The top diagram shows task runtimes per node and iteration without load balancing. Here, iteration duration is deter- mined by the four slow nodes. T ask runtimes are visualized by horizontal black bars. Bars that start at the same time represent tasks of the same iteration. Space in-between bars represents time during which tasks are inactiv e, i.e., communicating or waiting for the latest model update from the trainer . The middle diagram sho ws task runtimes with load balancing enabled. During the first iteration, task run- times are the same as without load balancing. As load is 0 10 20 time (s) node task runtime (w/o load balancing) 0 10 20 time (s) node task runtime (w/ load balancing) number of data chunks per iteration node relative workload (w/ load balancing) Figure 6. V isualization of the load balancing process on a real heterogeneous cluster . shifted during subsequent iterations, task runtimes align and iteration durations reduce. The bottom diagram sho ws the relativ e workload (not time) of tasks in the middle diagram. It shows how the w orkload is shifted from slo w to fast nodes. The length of the bars represent the number of data chunks for each task and iteration, relati ve to all other tasks and it- erations. After a fe w iterations, workload and task runtimes stabilize as Chicle has learned the performance of each node and balance load accordingly . 6 C O N C L U S I O N A N D F U T U R E W O R K W e presented Chicle, a distrib uted ML training framew ork based on uni-tasks. Chicle enables ef ficient elastic scaling and load balancing without incurring o verheads that are typical for micro-task systems and can thereby accelerate time to con ver gence by orders of magnitude in some cases. Our work touches man y issues that distinguish distrib uted ML training from re gular distributed applications, such as their sensitivity to data parallelism. Still, many aspects of ML workloads remain une xplored, and we believ e there is a lot of potential to further e xploit the unique properties of ML algorithms to build more ef ficient systems. Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle R E F E R E N C E S Abadi, M., Barham, P ., Chen, J., Chen, Z., Davis, A., Dean, J., De vin, M., Ghemawat, S., Irving, G., Isard, M., et al. T ensorflow: a system for large-scale machine learning. In OSDI , volume 16, pp. 265–283, 2016. Cipar , J., Ho, Q., Kim, J. K., Lee, S., Ganger , G. R., Gibson, G., Keeton, K., and Xing, E. Solving the straggler problem with bounded staleness. In Presented as part of the 14th W orkshop on Hot T opics in Operating Systems , Santa Ana Pueblo, NM, 2013. USENIX. URL https: //www.usenix.org/conference/hotos13/ solving- straggler- problem- bounded- staleness . Cui, H., Cipar, J., Ho, Q., Kim, J. K., Lee, S., Kumar , A., W ei, J., Dai, W ., Ganger , G. R., Gibbons, P . B., Gibson, G. A., and Xing, E. P . Exploiting bounded staleness to speed up big data analytics. In 2014 USENIX Annual T echnical Conference (USENIX ATC 14) , pp. 37–48, Philadelphia, P A, 2014. USENIX Association. ISBN 978-1-931971-10-2. URL https: //www.usenix.org/conference/atc14/ technical- sessions/presentation/cui . Delimitrou, C. and K ozyrakis, C. Quasar: resource-efficient and qos-aware cluster management. ACM SIGPLAN No- tices , 49(4):127–144, 2014. D ¨ unner , C., Parnell, T ., Atasu, K., Sifalakis, M., and Pozidis, H. Understanding and optimizing the performance of distributed machine learning applications on apache spark. In 2017 IEEE International Confer ence on Big Data (Big Data) , pp. 331–338. IEEE, 2017. D ¨ unner , C., P arnell, T ., Sarigiannis, D., Ioannou, N., Anghel, A., Ravi, G., Kandasamy , M., and Pozidis, H. Snap ml: A hierarchical framework for machine learning. In Advances in Neural Information Pr ocessing Systems , pp. 250–260, 2018. Dutta, S., Joshi, G., Ghosh, S., Dube, P ., and Nag- purkar , P . Slow and stale gradients can win the race: Error-runtime trade-offs in distributed sgd. In Storkey , A. and Perez-Cruz, F . (eds.), Pr oceedings of the T wenty-F irst International Confer ence on Arti- ficial Intelligence and Statistics , v olume 84 of Pro- ceedings of Machine Learning Resear ch , pp. 803–812, Playa Blanca, Lanzarote, Canary Islands, 09–11 Apr 2018. PMLR. URL http://proceedings.mlr. press/v84/dutta18a.html . Goyal, P ., Doll ´ ar , P ., Girshick, R., Noordhuis, P ., W esolowski, L., Kyrola, A., T ulloch, A., Jia, Y ., and He, K. Accurate, lar ge minibatch sgd: Training imagenet in 1 hour . arXiv pr eprint arXiv:1706.02677 , 2017. Harlap, A., T umanov , A., Chung, A., Ganger, G. R., and Gibbons, P . B. Proteus: agile ml elasticity through tiered reliability in dynamic resource mark ets. In Pr oceedings of the T welfth Eur opean Confer ence on Computer Systems , pp. 589–604. A CM, 2017. Ho, Q., Cipar, J., Cui, H., Lee, S., Kim, J. K., Gibbons, P . B., Gibson, G. A., Ganger , G., and Xing, E. P . More ef fecti ve distributed ml via a stale synchronous parallel parameter server . In Advances in neural information pr ocessing systems , pp. 1223–1231, 2013. Jaggi, M., Smith, V ., T ak ´ ac, M., T erhorst, J., Krishnan, S., Hofmann, T ., and Jordan, M. I. Communication-efficient distributed dual coordinate ascent. In Advances in neural information pr ocessing systems , pp. 3068–3076, 2014. Kaufmann, M., P arnell, T ., and Kourtis, K. Elastic Co- CoA: Scaling in to improv e con ver gence. NeurIPS 2018 Systems for ML workshop , December 2018. Keskar , N. S., Mudigere, D., Nocedal, J., Smelyanskiy , M., and T ang, P . T . P . On lar ge-batch training for deep learning: Generalization gap and sharp minima. arXiv pr eprint arXiv:1609.04836 , 2016. Kiefer , J., W olfowitz, J., et al. Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics , 23(3):462–466, 1952. Lin, T ., Stich, S. U., and Jaggi, M. Don’t use large mini- batches, use local sgd. arXiv pr eprint arXiv:1808.07217 , 2018. Ou, Z., Zhuang, H., Nurminen, J. K., Yl ¨ a-J ¨ a ¨ aski, A., and Hui, P . Exploiting hardware heterogeneity within the same instance type of amazon ec2. In Pr esented as part of the , 2012. Ousterhout, K., P anda, A., Rosen, J., V enkataraman, S., Xin, R., Ratnasamy , S., Shenker , S., and Stoica, I. The case for tiny tasks in compute clusters. In Pr oceedings of the 14th W orkshop on Hot T opics in Operating Systems , v olume 13 of HotOS ’16 , Santa Ana Pueblo, NM, 2013. USENIX. URL https: //www.usenix.org/conference/hotos13/ case- tiny- tasks- compute- clusters . Paszke, A., Gross, S., Chintala, S., Chanan, G., Y ang, E., DeV ito, Z., Lin, Z., Desmaison, A., Antiga, L., and Lerer , A. Automatic differentiation in pytorch. In NIPS-W , 2017. Qiao, A., Aghayev , A., Y u, W ., Chen, H., Ho, Q., Gib- son, G. A., and Xing, E. P . Litz: Elastic frame- work for high-performance distrib uted machine learn- ing. In 2018 USENIX Annual T echnical Confer- ence (USENIX A TC 18) , pp. 631–644, Boston, MA, Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle 2018. USENIX Association. ISBN 978-1-931971-44-7. URL https://www.usenix.org/conference/ atc18/presentation/qiao . Robbins, H. and Monro, S. A stochastic approximation method. The annals of mathematical statistics , pp. 400– 407, 1951. Rumelhart, D. E., Hinton, G. E., W illiams, R. J., et al. Learn- ing representations by back-propag ating errors. Cognitive modeling , 5(3):1, 1988. Shallue, C. J., Lee, J., Antognini, J., Sohl-Dickstein, J., Frostig, R., and Dahl, G. E. Measuring the effects of data parallelism on neural network training. J ournal of Machine Learning Resear c h , 20(112):1–49, 2019. Smith, S. L., Kindermans, P .-J., Y ing, C., and Le, Q. V . Don’t decay the learning rate, increase the batch size. arXiv pr eprint arXiv:1711.00489 , 2017. Smith, V . Cocoa for spark, 2019. URL https: //github.com/gingsmith/cocoa . accessed 2019/05/10. Smith, V ., F orte, S., Chenxin, M., T ak ´ a ˇ c, M., Jordan, M. I., and Jaggi, M. Cocoa: A general framework for communication-efficient distributed optimization. Jour- nal of Machine Learning Resear c h , 18:230, 2018. Spark. http://spark.apache. org/docs/latest/tuning.html# level- of- parallelism , 2019. URL http://spark.apache.org/docs/latest/ tuning.html#level- of- parallelism . Stich, S. U. Local sgd con ver ges fast and communicates little. arXiv pr eprint arXiv:1805.09767 , 2018. T otoni, E., Dulloor , S. R., and Ro y , A. A case against tiny tasks in iterativ e analytics. In Pr oceedings of the 16th W orkshop on Hot T opics in Operating Systems , HotOS ’17, pp. 144–149, Ne w Y ork, NY , USA, 2017. A CM, A CM. ISBN 978-1-4503-5068-6. doi: 10.1145/3102980. 3103004. URL http://doi.acm.org/10.1145/ 3102980.3103004 . V avilapalli, V . K., Murthy , A. C., Douglas, C., Agarwal, S., K onar , M., Ev ans, R., Gra ves, T ., Lowe, J., Shah, H., Seth, S., Saha, B., Curino, C., O’Malley , O., Ra- dia, S., Reed, B., and Baldeschwieler , E. Apache Hadoop Y ARN: Y et another resource negotiator . In Pr oceedings of the 4th Annual Symposium on Cloud Computing , SOCC ’13, pp. 5:1–5:16, New Y ork, NY , USA, 2013. A CM. ISBN 978-1-4503-2428-1. doi: 10.1145/2523616.2523633. URL http://doi.acm. org/10.1145/2523616.2523633 . Wright, S. J. Coordinate descent algorithms. Math. Pro- gram. , 151(1):3–34, 2015. ISSN 0025-5610. Y ou, Y ., Gitman, I., and Ginsbur g, B. Large batch training of con v olutional networks. arXiv pr eprint arXiv:1708.03888 , 2017. Zaharia, M., Chowdhury , M., Franklin, M. J., Shenker , S., and Stoica, I. Spark: Cluster computing with working sets. In Pr oceedings of the 2nd USENIX Confer ence on Hot T opics in Cloud Computing , Hot- Cloud’10, Berkeley , CA, USA, 2010. USENIX Asso- ciation. URL http://dl.acm.org/citation. cfm?id=1863103.1863113 . Zhang, H., Stafman, L., Or , A., and Freedman, M. J. Slaq: Quality-driv en scheduling for distrib uted machine learn- ing. In Pr oceedings of the 2017 Symposium on Cloud Computing , SoCC ’17, pp. 390–404, New Y ork, NY , USA, 2017. A CM. ISBN 978-1-4503-5028-0. doi: 10.1145/3127479.3127490. URL http://doi.acm. org/10.1145/3127479.3127490 . Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle A A P P E N D I X A.1 Baseline comparisons W e compare Chicle against Snap ML ( D ¨ unner et al. , 2018 ) for CoCoA and PyT orch ( P aszke et al. , 2017 ) for mSGD in a non-elastic, non-heterogeneous scenario. Neither compared- to frame work is able to elastically scale nor balance load. The purpose of this comparison is to show that the elasticity and load balancing capabilities of Chicle and uni-tasks do not come at a cost of performance in the normal case. In consequence, Chicle’ s elasticity and load balancing policies are also not used during these experiments. Both frame- works are e xecuted with RDMA-enabled MPI communica- tion backends. W e measure the conv ergence per epoch and ov er time. Each experiment is repeated 5 × . PyT orch. As no lSGD implementation for PyT orch exists, we compared Chicle to PyT orch using mSGD. mSGD is a special case of lSGD with H = 1 . Chicle’ s mSGD training algorithm uses libtorch, the C++ backend of PyT orch, which allows us to rule out the implementation of the training algorithm as source for an y potential differences. For both datasets, a learning rate of 0.002 and a momentum of 0.9 is used. Con ver gence per epochs is virtually identical to PyT orch. This is expected as both are based on libtorch and therefore use the same training algorithm implementations, CNN and hyper-parameters. Per time, Chicle is slightly faster , which is likely due to o verheads introduced by Python, which do not afflict Chicle, at it is nati vely implemented in C++. The maximal test accuracy that w as achieved within the test duration is 65.2% for CIF AR-10 with both framew orks. For Fashion-MNIST , Chicle has a 0.2% lead ov er PyT orch with 91.4%. Note that we did not tune hyper -parameters for each dataset dataset nor adjust them online, which is why the test accuracy for CIF AR-10 degrades slightly after reaching a peak. Snap ML. Chicle’ s CoCoA/SCD implementation for the training of a SVM is based on the original Spark implemen- tation ( Smith , 2019 ). The algorithm parameter σ is set to the the number of tasks, and the regularization coef ficient λ to the number of samples × 0.01. Compared to Snap ML, Chicle shows similar con v ergence and runtime behavior for the Higgs dataset. For Criteo, ho wev er , Chicle con ver ges much faster . This is due to the sensiti vity of Criteo to data partitioning. Chicle randomly assigns data chunks to tasks, whereas Snap ML splits the data into 16 contiguous parti- tions. Per iteration, Snap ML is slightly faster as Chicle’ s reduce and broadcast primitiv es are less optimized than their MPI counterparts used by Snap ML. W ith one exception (Criteo), Chicle performs similarly to both rigid frame works in a baseline scenario, showing that neither Chicle not uni-tasks impair baseline performance. 0.10 0.21 0.31 0.41 0.51 0.61 0.70 0 25 50 75 100 # of epochs test accuracy (a) CIF AR-10 (epochs) 0.50 0.59 0.69 0.79 0.89 0.95 0 20 40 60 # of epochs test accuracy (b) Fashion-MNIST (epochs) 0.10 0.21 0.31 0.41 0.51 0.61 0.70 0 120 240 360 time (s) test accuracy (c) CIF AR-10 (time) 0.50 0.59 0.69 0.79 0.89 0.95 0 120 240 360 time (s) test accuracy (d) Fashion-MNIST (time) Figure 7. Comparison with PyT orch w .r .t. conv ergence over epochs (top) and time (bottom). 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 0 100 200 300 # of epochs duality−gap Chicle Snap ML (a) Higgs (epochs) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 0 20 40 60 # of epochs duality−gap Chicle Snap ML (b) Criteo (epochs) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 0 20 40 60 time (s) duality−gap Chicle Snap ML (c) Higgs (time) 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 0 50 100 150 200 time (s) duality−gap Chicle Snap ML (d) Criteo (time) Figure 8. Comparison with Snap ML w .r .t. con vergence over epochs (top) and time (bottom). Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle A.2 Elastic scaling Figure 9 shows per-epoch con ver gence results for the elastic scaling experiments. A.3 Load balancing Figure 10 shows per -epoch con vergence results for the load balancing experiments. Figure 11 shows the load balanc- ing process during the first 10 (CoCoA) and 50 (lSGD) iterations. A.4 Example application Listing 1 sho ws a simplified trained and solver module for mSGD on Chicle. 1 Trainer::run() { 2 while (!done) { 3 signal(StartIteration); 4 wait(IterationFinished); 5 model = merge_updates(); // merge and 6 broadcast(model); // broadcast updates 7 } 8 } 9 10 Solver::run() { 11 while (!done) { 12 wait(IterationStarted); 13 model = get_model() // fetch model 14 // perform training 15 sample = get_next_sample(); 16 output = model->forward(sample->data); 17 loss = compute_loss(output, sample->label); 18 loss->backward(); 19 sgd_optimizer.step(); 20 send(model) // post updates 21 signal(IterationFinished); 22 } 23 } Listing 1. A minimal Chicle application example Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle 0.10 0.21 0.31 0.41 0.51 0.61 0.70 0 100 200 300 # of epochs test accuracy (a) CIF AR-10 0.50 0.59 0.69 0.79 0.89 0.95 0 10 20 30 40 50 # of epochs test accuracy (b) Fashion-MNIST 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 250 500 750 1000 # of epochs duality−gap (c) Higgs 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 25 50 75 100 # of epochs duality−gap (d) Criteo micro-tasks (16) micro-tasks (32) micro-tasks (48) micro-tasks (64) uni-tasks (scale-in) uni-tasks (scale-out) Figure 9. Con vergence per epoch vs. data parallelism for elastic scale-in/out experiments. The number of micro-tasks is giv en in parentheses. 0.10 0.21 0.31 0.41 0.51 0.61 0.70 0 100 200 300 # of epochs test accuracy (a) CIF AR-10 0.50 0.59 0.69 0.79 0.89 0.95 0 10 20 30 40 50 # of epochs test accuracy (b) Fashion-MNIST 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 0 250 500 750 1000 # of epochs duality−gap (c) Higgs 1e−1 1e−2 1e−3 1e−4 1e−5 1e−6 1e−7 1e−8 1e−9 0 25 50 75 100 # of epochs duality−gap (d) Criteo micro-tasks (16) micro-tasks (32) micro-tasks (48) micro-tasks (64) uni-tasks Figure 10. Con vergence per epoch when balancing load balancing in a heterogeneous cluster . The number of micro-tasks is giv en in parentheses. 0 1 2 3 4 5 6 7 time (s) node task runtime (not balanced) 0 1 2 3 4 5 6 7 time (s) node task runtime (balanced) number of data chunks per iteration node relative workload (balanced) (a) CIF AR-10 0 1 2 3 4 5 6 7 8 9 10 time (s) node task runtime (not balanced) 0 1 2 3 4 5 6 7 8 9 10 time (s) node task runtime (balanced) number of data chunks per iteration node relative workload (balanced) (b) Fashion-MNIST 0 1 2 3 time (s) node task runtime (w/o load balancing) 0 1 2 3 time (s) node task runtime (w/ load balancing) number of data chunks per iteration node relative workload (w/ load balancing) (c) Higgs 0 10 20 time (s) node task runtime (w/o load balancing) 0 10 20 time (s) node task runtime (w/ load balancing) number of data chunks per iteration node relative workload (w/ load balancing) (d) Criteo Figure 11. T ask ex ecution duration and per worker workload for the load balancing in a heterogeneous cluster e xperiments.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment