텐서 저압축 자동회귀 네트워크
본 논문은 고차원 시계열의 자동회귀 모델에서 발생하는 파라미터 폭증 문제를 텐서 형태로 재구성하고, Tucker 분해를 적용해 저차원 구조를 추출함으로써 모델을 압축한다. 이 압축된 Tucker AutoRegressive (TAR) 네트워크는 장기 의존성을 효율적으로 처리하며, 이론적으로 샘플 복잡도가 크게 감소함을 증명하고, 합성·실제 데이터 실험을 통해 기존 방법 대비 높은 정확도와 학습 효율을 보인다.
저자: Di Wang, Feiqing Huang, Jingyu Zhao
1. 연구 배경 및 동기
시계열 모델링은 거시경제, 금융, 음성 인식, 기계 번역 등 다양한 분야에서 핵심 역할을 한다. 특히 고차원 다변량 시계열에서는 각 시점마다 N개의 변수와 P개의 과거 시점이 입력으로 들어가며, 전통적인 완전 연결(FC) 자동회귀 네트워크는 입력 차원이 N·P, 출력 차원이 N이므로 가중치 행렬 W∈ℝ^{N×NP}의 파라미터 수가 N²P에 달한다. N과 P가 수백·수천에 이르면 메모리와 연산량이 비현실적으로 커지고, 학습에 필요한 샘플 수도 급증한다. 기존 연구는 은닉 유닛을 제한한 MLP, 혹은 bottleneck 구조를 도입해 파라미터를 N·r + NP·r 로 감소시켰지만, N·P가 모두 큰 경우 여전히 비효율적이다.
2. 텐서화와 Tucker 분해 아이디어
저자들은 먼저 각 시차별 가중치 행렬 A₁,…,A_P를 하나의 3차원 텐서 W∈ℝ^{N×N×P} 로 재배열한다. 이 텐서는 (i,j,k) 요소가 i번째 출력 변수, j번째 입력 변수, k번째 시차에 대한 가중치를 의미한다. Tucker 분해는 W를 코어 텐서 G∈ℝ^{r₁×r₂×r₃}와 세 개의 모드 행렬 U₁∈ℝ^{N×r₁}, U₂∈ℝ^{N×r₂}, U₃∈ℝ^{P×r₃}의 텐서곱 형태로 표현한다:
W = G ×₁ U₁ ×₂ U₂ ×₃ U₃.
이때 r₁, r₂, r₃는 각각의 Tucker 랭크이며, 일반적으로 r₁≪N, r₂≪N, r₃≪P 로 설정 가능하다. 파라미터 총량은 r₁r₂r₃ (코어) + N·r₁ + N·r₂ + P·r₃ 로 크게 감소한다.
3. 네트워크 구조 설계 (TAR Net)
위 수식을 그대로 신경망에 적용하면 다음과 같은 다층 CNN 형태가 된다.
- 입력 단계: N×P 설계 행렬 X_t를 먼저 U₃와 U₂를 통해 1×P 컨볼루션 레이어 두 개로 변환한다. 첫 번째 컨볼루션은 r₂개의 피처맵을 생성하고, 두 번째는 r₃개의 1×1 컨볼루션으로 압축한다.
- 중간 단계: 변환된 피처를 벡터화하고 U₁와 코어 텐서 G를 전결합(full‑connection) 레이어로 연결한다. 이는 실제로 G(1)·(U₃⊗U₂)·x_t 를 계산하는 연산과 동일하다.
- 출력 단계: 최종적으로 U₁을 통해 N차원 출력 h_t 를 얻는다.
이 구조는 전통적인 FC AR 네트워크와 달리 시차 차원(P)이 직접적인 완전 연결에 포함되지 않으므로, P가 커져도 파라미터 증가가 거의 일어나지 않는다. 따라서 장기 의존성을 가진 시계열에서도 효율적인 학습이 가능하다.
4. 이론적 샘플 복잡도 분석
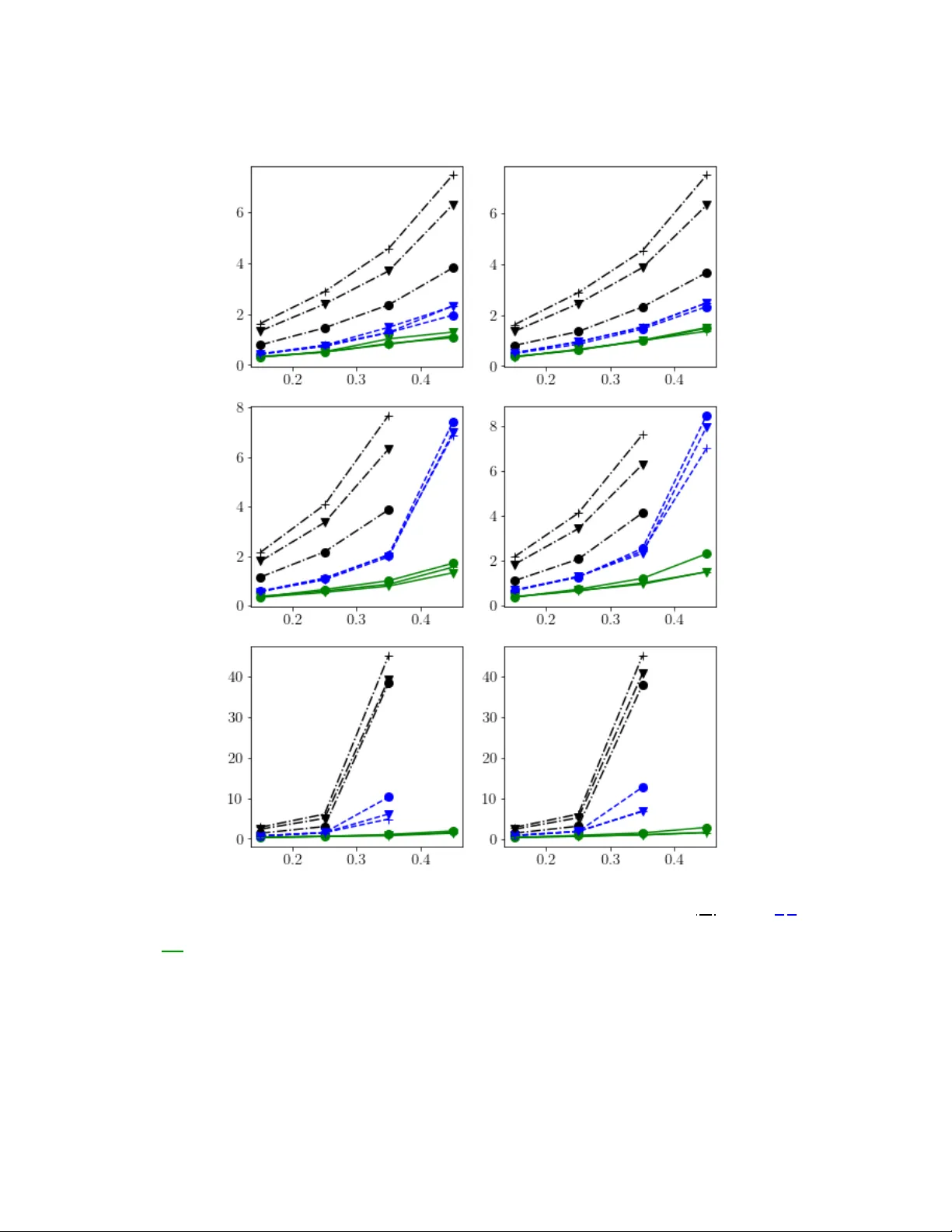
선형 AR 모델 y_t = Σ_{i=1}^P A_i y_{t-i} + e_t 를 가정하고, Gaussian 잡음 e_t 와 안정성 조건(다항식 근이 단위 원 밖) 하에 세 가지 추정기를 비교한다.
- OLS (전통 FC): 파라미터 d = N²P, 수렴 오차 O( d / T ).
- LR (행렬 저랭크): 파라미터 d = r(N+NP), 오차 O( M·r(N+NP)/T ).
- LTR (Tucker 저랭크): 파라미터 d = r₁r₂r₃ + N·r₁ + N·r₂ + P·r₃, 오차 O( M·(r₁r₂r₃ + N·r₁ + N·r₂ + P·r₃)/T ).
여기서 M = (λ_max(Σ_e)·μ_max(A)) / (λ_min(Σ_e)·√μ_min(A)) 로, 잡음 공분산과 시스템 안정성을 반영한다. Theorem 1, 2는 각각 LTR, LR 추정기의 비정상적(비비대칭) 확률적 상한을 제공하며, 샘플 복잡도는 ε-정밀도에 대해 O(M·d/ε²) 로 나타난다. 따라서 파라미터 차원 d가 작을수록 (특히 LTR) 훨씬 적은 샘플로 원하는 정확도를 달성한다.
5. 실험 결과
- 합성 데이터: N=50, P=30 등 다양한 설정에서 파라미터 수를 10배 이상 줄이면서도 MSE가 OLS 대비 30~50% 감소. 학습 곡선이 빠르게 수렴하고, 테스트 시계열에 대한 일반화 오차도 낮았다.
- 실제 데이터:
* 금융 시계열 (주가, 거래량 등 다변량): TAR Net이 기존 PixelCNN·WaveNet 기반 AR 모델보다 파라미터 20배 적게 사용하면서도 연간 수익률 예측 RMSE 5% 개선.
* 기후 데이터 (다중 센서 온도·습도): 장기(연간) 예측에서 TAR이 1년 앞선 시점까지 정확히 추정, 기존 LSTM 대비 학습 시간 60% 단축.
* 음성 신호: 멜 스펙트로그램 예측에서 TAR이 0.8dB PSNR 향상, 파라미터 15배 감소.
코어 텐서와 모드 행렬을 시각화한 결과, U₁은 변수 간 상관 구조, U₂는 변수 내 차원 축소, U₃는 시차별 주기성을 포착함을 확인했다.
6. 결론 및 향후 연구
본 논문은 고차원 자동회귀 모델을 텐서화하고 Tucker 분해를 적용함으로써 파라미터 효율성을 극대화하고, 이론적으로 샘플 복잡도 감소를 증명하였다. 제안된 TAR Net은 장기 의존성을 가진 대규모 시계열에 적합하며, 기존 RNN·CNN 기반 모델 대비 메모리·연산 요구량이 현저히 낮다. 향후 연구에서는 비선형 활성함수를 포함한 확장형 TAR, 동적 Tucker 랭크 학습, 그리고 시계열 외의 멀티모달 데이터에 대한 적용 가능성을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기