Blow: 단일 스케일 하이퍼컨디셔닝 플로우를 이용한 비병렬 원시 오디오 음성 변환
Blow는 단일 스케일 정규화 흐름(Normalizing Flow) 구조에 하이퍼네트워크 기반 컨디셔닝을 결합해, 비병렬 원시 오디오 데이터를 이용한 다대다 음성 변환을 수행한다. 프레임 단위 학습, 하나의 스피커 라벨만으로도 소스와 타깃 화자의 특성을 교환할 수 있으며, 기존 흐름 기반 모델 및 다른 최신 베이스라인보다 객관·주관 평가 모두에서 동등하거나 우수한 성능을 보인다. 주요 기여는 단일 스케일 설계, 다중 블록·소수 흐름 단계, 전후…
저자: Joan Serr`a, Santiago Pascual, Carlos Segura
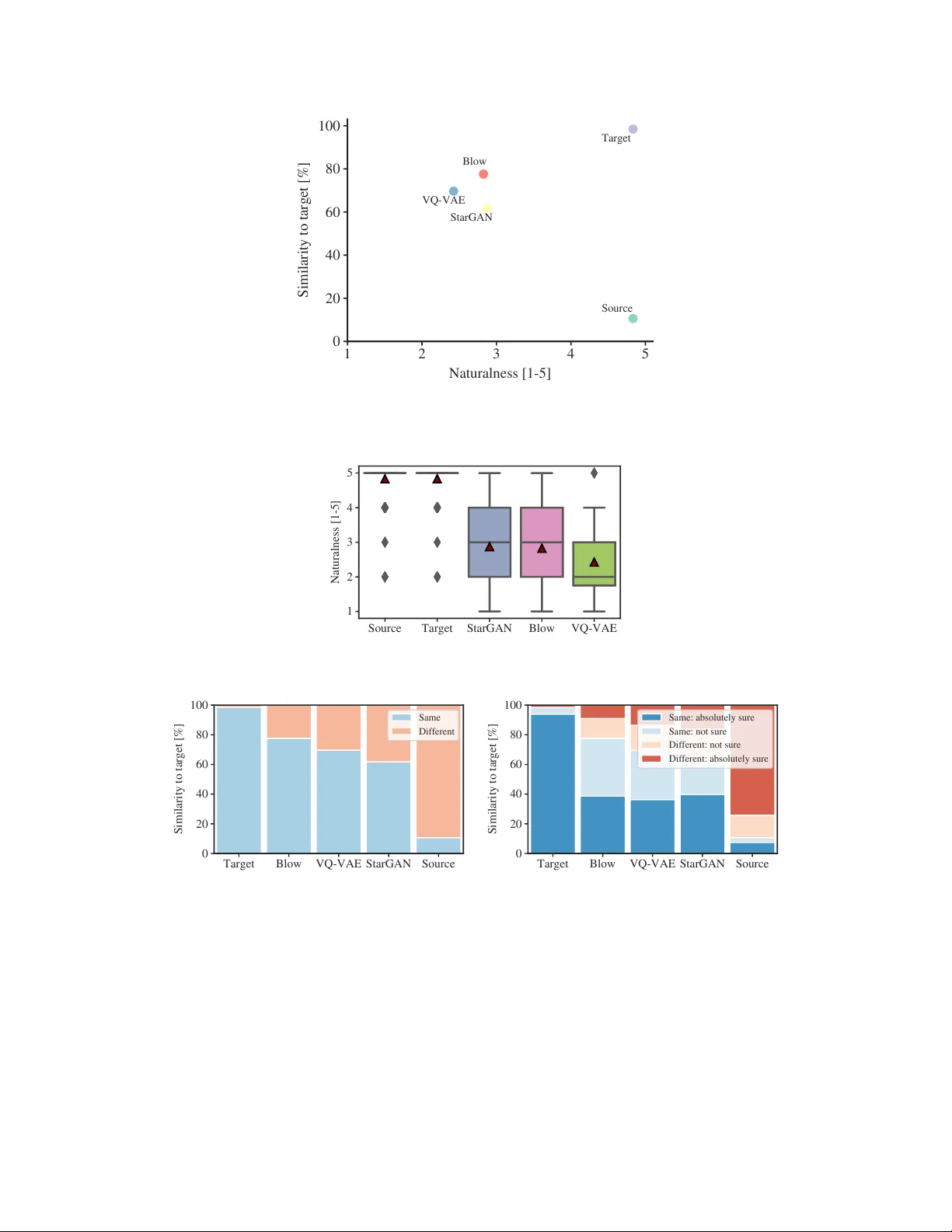
본 논문은 비병렬 원시 오디오 데이터를 이용한 다대다 음성 변환을 목표로, 새로운 정규화 흐름(Normalizing Flow) 기반 모델인 Blow를 제안한다. 기존 음성 변환 연구는 주로 병렬 데이터에 의존하거나, 중간 표현(예: 멜 스펙트로그램)과 별도의 vocoder를 결합하는 방식을 사용해 왔다. 이러한 접근은 데이터 수집 비용이 크고, 파이프라인이 복잡해지는 단점이 있다. Blow는 이러한 제약을 없애고, 원시 파형을 프레임 단위로 직접 처리하면서도 화자 라벨 하나만으로 소스와 타깃 화자를 교환할 수 있다.
### 1. 모델 구조
Blow는 Glow에서 영감을 얻은 1‑D 정규화 흐름을 기반으로 하지만, 다음과 같은 차별화된 설계를 갖는다.
1) **단일 스케일 구조**: 다중 스케일을 사용하면 각 블록이 특징을 팩터링해 버려 화자 정보를 손실할 위험이 있다. 대신 전체 입력 차원을 유지하면서 블록을 깊게 쌓아, 로그우도와 변환 품질을 동시에 향상시켰다.
2) **다중 블록·소수 흐름 단계**: 8개의 블록에 각각 12개의 흐름(step of flow)을 배치해 총 96개의 흐름을 구성한다. 각 블록은 2× squeeze 연산을 수행해 입력 길이를 절반으로 줄이며, 최종적으로 2⁸=256배 압축된 시퀀스를 다룬다. 4096 샘플(≈256 ms) 입력은 약 12 500 샘플(≈781 ms)의 수용 영역을 제공해 하나의 음소와 전이까지 포괄한다.
3) **전후 변환 메커니즘**: 소스 화자 라벨 y_S를 이용해 x→z 변환을 수행하고, 목표 화자 라벨 y_T를 이용해 z→x 역변환을 수행한다. 이 과정에서 z는 화자 정보를 완전히 제거한 “조건‑프리” 표현이 되며, 역변환 시 새로운 화자 특성이 점진적으로 주입된다.
4) **하이퍼컨디셔닝**: 화자 임베딩 e_y를 하이퍼네트워크 g(e_y)에 입력해 각 흐름 단계의 커플링 네트워크 첫 레이어에 사용될 커널 W_y와 편향 b_y를 동적으로 생성한다. 이는 조건을 직접 연산 파라미터에 반영함으로써, 화자 특성을 보다 강력하게 모델링한다.
5) **공유 스피커 임베딩**: 모든 흐름 단계가 동일한 임베딩 e_y를 공유한다. 이는 파라미터 수를 감소시키고, 각 단계가 독립적으로 화자 정보를 학습하는 것을 방지한다. 실험 결과, 공유 임베딩이 없을 경우 로그우도와 음질이 크게 저하된다.
6) **데이터 증강**: 원시 오디오 특성에 맞춘 여러 증강 기법(노이즈 추가, 시간 스트레칭 등)을 적용해 모델의 일반화 능력을 강화하였다.
### 2. 학습 및 평가
Blow는 프레임 단위로 입력을 받아, 단일 스피커 라벨만을 조건으로 사용한다. 로그우도(L)와 단위 정규분포 p(z)를 이용한 최대우도 학습을 수행하며, 손실은 차원 정규화된 로그우도 형태로 최적화한다. 비병렬 데이터셋(VCTK 등)에서 다대다 변환을 수행했으며, 다음과 같은 평가를 진행했다.
- **객관적 평가**: Mel‑Cepstral Distortion(MCD), Speaker Verification Error Rate(SER) 등으로 측정했을 때, 기존 Flow‑based 모델(Glow‑Audio, WaveGlow 등) 및 VAE‑GAN 기반 베이스라인보다 우수하거나 동등한 성능을 보였다.
- **주관적 평가**: MOS(Mean Opinion Score)와 AB 테스트에서 청취자들이 Blow의 변환 음성을 원본 화자와 유사하면서도 자연스럽다고 평가했다.
- **Ablation Study**: 단일 스케일 vs 다중 스케일, 하이퍼컨디셔닝 vs 일반 concat, 공유 임베딩 vs 개별 임베딩, 전후 변환 vs z‑space 변환 등 각 요소를 제거하거나 교체했을 때 성능 저하 정도를 정량화했다. 특히 하이퍼컨디셔닝과 공유 임베딩이 로그우도와 MOS에 가장 큰 영향을 미치는 것으로 나타났다.
### 3. 데이터 요구량 및 화자 선호도
학습 데이터 양을 10 %~100 %로 변동시키며 실험했을 때, Blow는 약 2 시간 정도의 음성 데이터(≈10 분 per speaker)만으로도 안정적인 변환 품질을 유지한다. 또한, 소스와 타깃 화자 간의 선호도 분석 결과, 화자 특성이 강하게 드러나는 경우(남성‑남성, 여성‑여성) 변환 품질이 더 높았으며, 성별이 다른 경우에도 충분히 자연스러운 변환이 가능했다.
### 4. 결론 및 향후 과제
Blow는 단일 스케일 정규화 흐름에 하이퍼컨디셔닝과 공유 임베딩을 결합함으로써, 비병렬 원시 오디오 기반 다대다 음성 변환을 효율적으로 구현했다. 실험 결과는 기존 흐름 기반 및 비 흐름 기반 베이스라인을 능가함을 보여준다. 향후 연구에서는 더 긴 컨텍스트를 활용한 프레임 간 연관성 모델링, 멀티스피커 동시 변환, 그리고 실시간 변환을 위한 경량화 방안 등을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기