Blow: a single-scale hyperconditioned flow for non-parallel raw-audio voice conversion
End-to-end models for raw audio generation are a challenge, specially if they have to work with non-parallel data, which is a desirable setup in many situations. Voice conversion, in which a model has to impersonate a speaker in a recording, is one o…
Authors: Joan Serr`a, Santiago Pascual, Carlos Segura
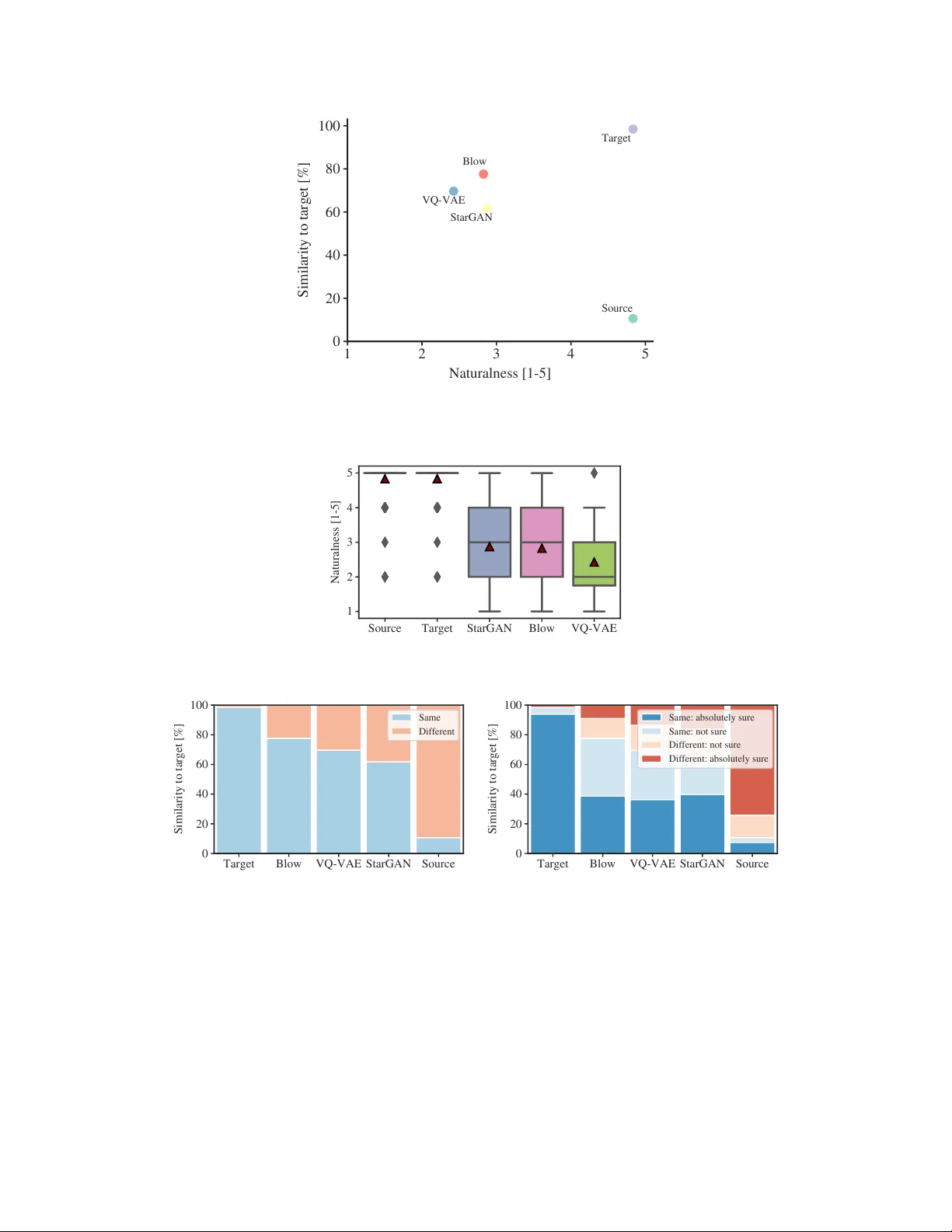
Blow: a single-scale h yper conditioned flow f or non-parallel raw-audio voice con v ersion Joan Serrà T elefónica Research joan.serra@telefonica.com Santiago Pascual Univ ersitat Politècnica de Catalun ya santi.pascual@upc.edu Carlos Segura T elefónica Research carlos.seguraperales @telefonica.com Abstract End-to-end models for raw audio generation are a challenge, specially if they hav e to work with non-parallel data, which is a desirable setup in many situations. V oice con v ersion, in which a model has to impersonate a speaker in a recording, is one of those situations. In this paper , we propose Blow , a single-scale normalizing flow using hypernetw ork conditioning to perform many-to-many v oice con v ersion between raw audio. Blo w is trained end-to-end, with non-parallel data, on a frame- by-frame basis using a single speaker identifier . W e sho w that Blow compares fa vorably to existing flow-based architectures and other competitiv e baselines, obtaining equal or better performance in both objectiv e and subjectiv e e v aluations. W e further assess the impact of its main components with an ablation study , and quantify a number of properties such as the necessary amount of training data or the preference for source or target speak ers. 1 Introduction End-to-end generation of raw audio wav eforms remains a challenge for current neural systems. Dealing with raw audio is more demanding than dealing with intermediate representations, as it requires a higher model capacity and a usually lar ger recepti v e field. In f act, producing high-le vel wa veform structure was long thought to be intractable, e ven at a sampling rate of 16 kHz, and is only starting to be explored with the help of autoregressi ve models [ 1 – 3 ], generati ve adversarial networks [ 4 , 5 ] and, more recently , normalizing flo ws [ 6 , 7 ]. Nonetheless, generation without long- term conte xt information still leads to sub-optimal results, as existing architectures struggle to capture such information, ev en if the y employ a theoretically suf ficiently lar ge recepti ve field (cf. [ 8 ]). V oice con version is the task of replacing a source speaker identity by a targeted dif ferent one while preserving spoken content [ 9 , 10 ]. It has multiple applications, the main ones being in the medical, entertainment, and education domains (see [ 9 , 10 ] and references therein). V oice con version systems are usually one-to-one or many-to-one, in the sense that the y are only able to con vert from a single or , at most, a handful of source speakers to a unique tar get one. While this may be suf ficient for some cases, it limits their applicability and, at the same time, it pre vents them from learning from multiple targets. In addition, v oice conv ersion systems are usually trained with parallel data, in a strictly supervised fashion. T o do so, one needs input/output pairs of recordings with the corresponding source/target speak ers pronouncing the same underlying content with a relativ ely accurate temporal alignment. Collecting such data is non-scalable and, in the best of cases, problematic. Thus, researchers are shifting to wards the use of non-parallel data [ 11 – 15 ]. Ho wever , non-parallel voice con v ersion is still an open issue, with results that are far from those using parallel data [ 10 ]. In this w ork, we e xplore the use of normalizing flows for non-parallel, man y-to-man y , raw-audio voice con version. W e propose Blo w , a normalizing flow architecture that learns to con vert v oice recordings end-to-end with minimal supervision. It only emplo ys individual audio frames, together with an 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouver , Canada. identifier or label that signals the speaker identity in such frames. Blow inherits some structure from Glo w [ 16 ], but introduces several improvements that, besides yielding better likelihoods, pro ve crucial for effecti ve voice con version. Improv ements include the use of a single-scale structure, many blocks with few flo ws in each, a forward-backward con version mechanism, a conditioning module based on hypernetworks [ 17 ], shared speak er embeddings, and a number of data augmentation strategies for raw audio. W e quantify the effecti veness of Blo w both objectively and subjectiv ely , obtaining comparable or e ven better performance than a number of baselines. W e also perform an ablation study to quantify the relativ e importance of e very ne w component, and assess further aspects such as the preference for source/target speakers or the relation between objecti ve scores and the amount of training audio. W e use public data and make our code a v ailable at https://github.com/joansj/blow . A number of voice con version examples are pro vided in https://blowconversions.github.io . 2 Related work T o the best of our knowledge, there are no published works utilizing normalizing flo ws for voice con v ersion, and only three using normalizing flo ws for audio in general. Prenger et al. [ 6 ] and Kim et al. [ 7 ] concurrently propose using normalizing flo ws as a decoder from mel spectrograms to ra w audio. Their models are based on Glow , b ut with a W aveNet [ 1 ] structure in the affine coupling network. Y amaguchi et al. [ 18 ] employ normalizing flows for audio anomaly detection and cross- domain image translation. They propose the use of class-dependant statistics to adaptively normalize flow acti vations, as done with AdaBN for regular netw orks [ 19 ]. 2.1 Normalizing flows Based on Barlow’ s principle of redundanc y reduction [ 20 ], Redlich [ 21 ] and Deco and Brauer [ 22 ] already used inv ertible v olume-preserving neural architectures. In more recent times, Dinh et al. [ 23 ] proposed performing factorial learning via maximum lik elihood for image generation, still with volume-preserving transformations. Rezende and Mohamed [ 24 ] and Dinh et al. [ 25 ] introduced the usage of non-volume-preserving transformations, the formers adopting the terminology of normalizing flows and the use of affine and radial transformations [ 26 ]. Kingma and Dhariwal [ 16 ] proposed an effecti ve architecture for image generation and manipulation that lev erages 1 × 1 in v ertible conv olutions. Despite having gained little attention compared to generativ e adversarial networks, autoregressi ve models, or v ariational autoencoders, flow-based models feature a number of merits that make them specially attracti ve [ 16 ], including exact inference and likelihood e valuation, efficient synthesis, a useful latent space, and some potential for gradient memory sa vings. 2.2 Non-parallel voice con version Non-parallel voice con version has a long tradition of approaches using classical machine learning techniques [ 27 – 30 ]. Ho we ver , today , neural networks dominate the field. Some approaches make use of automatic speech recognition or te xt representations to disentangle content from acoustics [ 31 , 32 ]. This easily removes the characteristics of the source speaker , but further challenges the generator , which needs additional context to properly define the target voice. Many approaches employ a vocoder for obtaining an intermediate representation and as a generation module. Those typically con v ert between intermediate representations using variational autoencoders [ 11 , 12 ], generati v e adversarial netw orks [ 13 , 14 ], or both [ 15 ]. Finally , there are a fe w works emplo ying a fully neural architecture on raw audio [ 33 ]. In that case, parts of the architecture may be pre-trained or not learned end-to-end. Besides voice con version, there are some works dealing with non-parallel music or audio con version: Engel et al. [ 34 ] propose a W a v eNet autoencoder for note synthesis and instrument timbre transformations; Mor et al. [ 35 ] incorporate a domain-confusion loss for general musical translation and Nachmani and W olf [ 36 ] incorporate an identity-agnostic loss for singing voice conv ersion; Haque et al. [ 37 ] use a sequence-to-sequence model for audio style transfer . 3 Flow-based generativ e models Flow-based generativ e models learn a bijecti ve mapping from input samples x ∈ X to latent representations z ∈ Z such that z = f ( x ) and x = f − 1 ( z ) . This mapping f , commonly called a normalizing flow [ 24 ], is a function parameterized by a neural network, and is composed by a 2 sequence of k in v ertible transformations f = f 1 ◦ · · · ◦ f k . Thus, the relationship between x and z , which are of the same dimensionality , can be expressed [ 16 ] as x , h 0 f 1 ← → h 1 f 2 ← → h 2 · · · f k ← → h k , z . For a generative approach, we want to model the probability density p ( X ) in order to be able to generate realistic samples. This is usually intractable in a direct way , but we can now use f to model the exact log-likelihood L ( X ) = 1 |X | |X | X i =1 log ( p ( x i )) . (1) For a single sample x , and using a change of v ariables, the in verse function theorem, compositionality , and logarithm properties (Appendix A ), we can write log ( p ( x )) = log ( p ( z )) + k X i =1 log det ∂ f i ( h i − 1 ) ∂ h i − 1 , where ∂ f i ( h i − 1 ) /∂ h i − 1 is the Jacobian matrix of f i at h i − 1 and the log-determinants measure the change in log-density made by f i . In practice, one chooses transformations f i with triangular Jacobian matrices to achieve a fast calculation of the determinant and ensure in vertibility , albeit these may not be as expressi v e as more elaborate ones (see for instance [ 38 – 40 ]). Similarly , one chooses an isotropic unit Gaussian for p ( z ) in order to allow f ast sampling and straightforward operations. A number of structures and parameterizations of f and f i hav e been proposed for image generation, the most popular ones being RealNVP [ 25 ] and Glo w [ 16 ]. More recently , other works ha ve proposed improv ements for better density estimation and image generation in multiple contexts [ 38 – 43 ]. RealNVP uses a block structure with batch normalization, masked con volutions, and affine coupling layers. It combines those with 2 × 2 squeezing operations and alternating checkerboard and channel- wise masks. Glo w goes one step further and, besides replacing batch normalization by activ ation normalization (ActNorm), introduces a channel-wise mixing through in vertible 1 × 1 con volutions. Its architecture is composed of 3 to 6 blocks, formed by a 2 × 2 squeezing operation and 32 to 64 steps of flow , which comprise a sequence of ActNorm, 1 × 1 in vertible con v olution, and af fine coupling. F or the af fine coupling, three con v olutional layers with rectified linear units (ReLUs) are used. Both Glo w and RealNVP feature a multi-scale structure that factors out components of z at different resolutions, with the intention of defining intermediary lev els of representation at different granularities. This is also the strategy follo wed by other image generation flows and the two existing audio generation ones [ 6 , 7 ]. 4 Blow Blow inherits some structure from Glo w , but incorporates se veral modifications that we sho w are key for effecti ve v oice con version. The main ones are the use of (1) a single-scale structure, (2) more blocks with less flo ws in each, (3) a forward-backward con version mechanism, (4) a hyperconditioning module, (5) shared speak er embeddings, and (6) a number of data augmentation strate gies for ra w audio. W e now provide an o vervie w of the general structure (Fig. 1 ). W e use one-dimensional 2 × squeeze operations with an alternate pattern [ 25 ] and a series of steps of flow (Fig. 1 , left). A step of flow is composed of a linear inv ertible layer as channel mixer (similar to a 1 × 1 in vertible conv olution in the two-dimensional case), ActNorm, and a coupling network with af fine coupling (Fig. 1 , center). Coupling networks are formed by one-dimensional con v olutions and h ypercon v olutions with ReLU activ ations (Fig. 1 , right). The last con volution and the hypercon volution of the coupling netw ork hav e a k ernel width of 3, while the intermediate con volution has a kernel width of 1 (we use 512 × 512 channels). The same speaker embedding feeds all coupling networks, and is independently adapted for each hypercon volution. Following common practice, we compare the output z against a unit isotropic Gaussian and optimize the log-likelihood L (Eq. 1 ) normalized by the dimensionality of z . 4.1 Single-scale structure Besides the aforementioned ability to deal with intermediary le vels of representation, a multi-scale structure is thought to encourage the gradient flow and, therefore, facilitate the training of v ery deep 3 Squeeze Step of flow Embedding Step of flow Block x y Step of flow Channel mixer ActNorm Coupling network Affine coupling Hyperconvolution ReLU Convolution ReLU Convolution Adapter Coupling network Figure 1: Blow schema featuring its block structure (left), steps of flo w (center), and coupling network with hypercon volution module (right). models [ 44 ] like normalizing flo ws. Here, in preliminary analysis, we observ ed that speaker identity traits were almost present only at the coarser level of representation. Moreov er , we found that, by removing the multi-scale structure and carrying the same input dimensionality across blocks, not only gradients were flowing without issue, b ut better log-likelihoods were also obtained (see below). W e believ e that the fact that gradients still flow without factoring out block activ ations is because the log-determinant term in the loss function is still factored out at ev ery flow step (Appendix A ). Therefore, some gradient is still shuttled back to the corresponding layer and below . The fact that we obtain better log-likelihoods with a single-scale structure was someho w e xpected, as block acti vations now under go further processing in subsequent blocks. Howev er , to our understanding, this aspect seems to be missed in the likelihood-based e v aluation of current image generation flo ws. 4.2 Many blocks Flo w-based image generation models deal with images between 32 × 32 and 256 × 256 pixels. For raw audio, a one-dimensional input of 256 samples at 16 kHz corresponds to 16 ms, which is insufficient to capture any interesting speech construct. Phoneme duration can be between 50 and 180 ms [ 45 ], and we need a little more length to model some phoneme transition. Therefore, we need to increase the input and the recepti ve field of the model. T o do so, flo w-based audio generation models [ 6 , 7 ] opt for more aggressiv e squeezing factors, together with a W aveNet-style coupling network with dilation up to 2 8 . In Blo w , in contrast, we opt for using man y blocks with relati v ely fe w flo w steps each. In particular , we use 8 blocks with 12 flows each (an 8 × 12 structure). Since e very block has a 2 × squeeze operation, this implies a total squeezing of 2 8 samples. Considering two con v olutions of kernel width 3, an 8 × 12 structure yields a receptive field of roughly 12500 samples that, at 16 kHz, corresponds to 781 ms. Ho we v er , to allow for larger batch sizes, we use an input frame size of 4096 samples (256 ms at 16 kHz). This is suf ficient to accommodate, at least, one phoneme and one phoneme transition if we cut in the middle of words, and is comparable to the recepti ve field of other successful models like W aveNet. Blow operates on a frame-by-frame basis without context; we admit that this could be insufficient to model long-range speak er-dependent prosody , but nonetheless belie ve it is enough to model core speaker identity traits. 4.3 Forward-backward con version The def ault strategy to perform image manipulation [ 16 ] or class-conditioning [ 41 , 42 ] in Glow- based models is to work in the z space. This has a number of interesting properties, including the possibility to perform progressiv e changes or interpolations, and the potential for fe w-shot learning or manipulations based on small data. Howe ver , we observ ed that, for voice con version, results following this strate gy were lar gely unsatisfactory (Appendix B ). Instead of using z to perform identity manipulations, we think of it as an identity-agnostic representa- tion. Our idea is that any supplied condition specifying some real input characteristic of x should be useful to transform x to z , specially if we consider a maximum likelihood objectiv e. That is, kno wing 4 a condition/characteristic of the input should facilitate the disco very of further similarities that were hidden by said condition/characteristic, and thus facilitate learning. Follo wing this line of thought, if conditioning at multiple lev els in the flow from x to z progressiv ely get us to a condition-free z space (Appendix C.3 ), then, when transforming back from z to x with a dif ferent condition, that should also progressiv ely imprint the characteristics of this ne w condition to the output x . Blow uses the source speaker identifier y S for transforming x ( S ) to z , and the target speaker identifier y T for transforming z to the con v erted audio frame x ( T ) . 4.4 Hyperconditioning A straightforward place to introduce conditioning in flow-based models is the coupling network, as no Jacobian matrix needs to be computed and no in vertibility constraints apply . Furthermore, in the case of affine channel-wise couplings [ 16 , 25 ], the coupling network is in charge of performing most of the transformation, so we want it to have a great representation po wer , possibly boosted by further conditioning information. A common way to condition the coupling network is to add or concatenate some representation to its input layers. Howe v er , based on our observ ations that concatenation tended to be ignored and that addition was not po werful enough, we decided to perform conditioning directly with the weights of the con v olutional kernels. That is, that a conditioning representation determines the weights employed by a con volution operator , like done with hypernetw orks [ 17 ]. W e do it at the first layer of the coupling network (Fig. 1 , right). Using one-dimensional conv olutions, and given an input acti vation matrix H , for the i -th con volutional filter we hav e h ( i ) = W ( i ) y ∗ H + b ( i ) y , (2) where ∗ is the one-dimensional con volution operator , and W ( i ) y and b ( i ) y represent the i -th kernel weights and bias, respectiv ely , imposed by condition y . A set of n condition-dependent kernels and biases K y can be obtained by K y = n W (1) y , b (1) y . . . W ( n ) y , b ( n ) y o = g ( e y ) , (3) where g is an adapter network that takes the conditioning representation e y as input, which in turn depends on condition identifier y (the speaker identity in our case). V ector e y is an embedding that can either be fixed or initialized at some pre-calculated feature representation of a speaker , or learned from scratch if we need a standalone model. In this paper we choose the standalone v ersion. 4.5 Structure-wise shar ed embeddings W e find that learning one e y per coupling network usually results in sub-optimal results. W e hypothe- size that, giv en a large number of steps of flow (or coupling networks), independent conditioning representations do not need to focus on the essence of the condition (the speaker identity), and are thus free to learn an y combination of numbers that minimizes the negati ve log-likelihood, irrespecti ve of their relation with the condition. Therefore, to reduce the freedom of the model, we decide to constrain such representations. Loosely inspired by the StyleGAN architecture [ 46 ], we set a single learnable embedding e y that is shared by each coupling network in all steps of flow (Fig. 1 , left). This reduces both the number of parameters and the freedom of the model, and turns out to yield better results. F ollo wing a similar reasoning, we also use the smallest possible adapter netw ork g (Fig. 1 , right): a single linear layer with bias that merely performs dimensonality adjustment. 4.6 Data augmentation T o train Blo w , we discard silent frames (Appendix B ) and then enhance the remaining ones with 4 data augmentation strategies. Firstly , we apply a temporal jitter . W e shift the start j of each frame x as j 0 = j + b U ( − ξ , ξ ) e , where U is a uniform random number generator and ξ is half of the frame size. Secondly , we use a random pre-/de-emphasis filter . Since the identity of the speaker is not going to v ary with a simple filtering strategy , we apply an emphasis filter [ 47 ] with a coefficient α = U ( − 0 . 25 , 0 . 25) . Thirdly , we perform a random amplitude scaling. Speaker identity is also going to be preserved with scaling, plus we want the model to be able to deal with any amplitude between − 1 and 1. W e use x 0 = U (0 , 1) · x / max( | x | ) . Finally , we randomly flip the values in the frame. Auditory perception is relati ve to an av erage pressure level, so we can flip the sign of x to obtain a different input with the same perceptual qualities: x 0 = sgn ( U ( − 1 , 1)) · x . 5 4.7 Implementation details W e now outline the details that differ from the common implementation of flow-based generativ e models and further refer the interested reader to the pro vided code for a full account of them. W e also want to note that we did not perform any h yperparameter tuning on Blo w . General — W e train Blow with Adam using a learning rate of 10 − 4 and a batch size of 114. W e anneal the learning rate by a factor of 5 if 10 epochs have passed without improv ement in the validation set, and stop training at the third time this happens. W e use an 8 × 12 structure, with 2 × alternate-pattern squeezing operations. F or the coupling network, we split channels into two halv es, and use one-dimensional conv olutions with 512 filters and kernel widths 3, 1, and 3. Embeddings are of dimension 128. W e train with a frame size of 4096 at 16 kHz with no o verlap, and initialize the ActNorm weights with one data-augmented batch (batches contain a random mixture of frames from all speakers). W e synthesize with a Hann window and 50% ov erlap, normalizing the entire utterance between − 1 and 1. W e implement Blow using PyT orch [ 48 ]. Coupling — As done in the of ficial Glo w code (but not mentioned in the paper), we find that constraining the scaling factor that comes out of the coupling network improves the stability of training. F or af fine couplings with channel-wise concatenation H 0 = H 1: c , s 0 ( H 1: c ) ( H c +1:2 c + t ( H 1: c )) , where 2 c is the total number of channels, we use s 0 ( H 1: c ) = σ ( s ( H 1: c ) + 2) + , where σ corresponds to the sigmoid function and is a small constant to pre v ent an infinite log- determinant (and division by 0 in the re verse pass). Hyperconditioning — If we strictly follo w Eqs. 2 and 3 , the hyperconditioning operation can in volv e both a lar ge GPU memory footprint ( n different kernels per batch element) and time-consuming calculations (a double loop for e very k ernel and batch element). This can, in practice, make the operation impossible to perform for a very deep flo w-based architecture like Blo w . Howe ver , by restricting the dimensionality of kernels W ( i ) y such that e v ery channel is con volv ed with its o wn set of kernels, we can achie ve a minor GPU footprint and a tractable number of parameters per adaptation network. This corresponds to depthwise separable conv olutions [ 49 ], and can be implemented with grouped con v olution [ 50 ], a v ailable in most deep learning libraries. 5 Experimental setup T o study the performance of Blo w we use the VCTK data set [ 51 ], which comprises 46 h of audio from 109 speak ers. W e downsample it at 16 kHz and randomly extract 10% of the sentences for validation and 10% for testing (we use a simple parsing script to ensure that the same sentence text does not get into different splits, see Appendix B ). W ith this amount of data, the training of Blow takes 13 days using three GeForce R TX 2080-T i GPUs 1 . Con versions are performed between all possible gender combinations, from test utterances to randomly-selected VCTK speakers. T o compare with e xisting approaches, we consider two flow-based generative models and two competitiv e v oice con version systems. As flo w-based generative models we adapt Glo w [ 16 ] to the one-dimensional case and replicate a version of Glo w with a W av eNet coupling network follo wing [ 6 , 7 ] (Glow-W a veNet). Conv ersion is done both via manipulation of the z space and by learning an identity conditioner (Appendix B ). These models use the same frame size and hav e the same number of flow steps as Blo w , with a comparable number of parameters. As voice con version systems we implement a VQ-V AE architecture with a W aveNet decoder [ 33 ] and an adaptation of the StarGAN architecture to voice con version like StarGAN-VC [ 14 ]. VQ-V AE conv erts in the wa veform domain, while StarGAN does it between mel-cepstrums. Both systems can be considered as very competiti ve for the non-parallel voice con version task. W e do not use pre-training nor transfer learning in any of the models. T o quantify performance, we carry out both objecti ve and subjecti ve e v aluations. As objectiv e metri cs we consider the per-dimensionality log-likelihood of the flow-based models ( L ) and a spoofing 1 Nonetheless, con version plus synthesis with 1 GPU and 50% o verlap is around 14 × f aster than real time. 6 T able 1: Objecti ve scores and their relativ e dif ference for possible Blow alternati ves (5 min per speaker , 100 epochs). Configuration L [nat/dim] Spoofing [%] Blow 4.30 66.2 1: with 3 × 32 structure 4.01 ( − 6.7%) 17.2 ( − 74.0%) 2: with 3 × 32 structure (squeeze of 8) 4.21 ( − 2.1%) 65.7 ( − 0.8%) 3: with multi-scale structure 3.64 ( − 15.3%) 3.5 ( − 94.7%) 4: with multi-scale structure (5 × 19, squeeze of 4) 3.99 ( − 7.2%) 16.6 ( − 74.9%) 5: with additi v e conditioning (coupling network) 4.28 ( − 0.5%) 39.5 ( − 40.3%) 6: with additi v e conditioning (before ActNorm) 4.28 ( − 0.5%) 22.5 ( − 66.0%) 7: without data augmentation 4.15 ( − 3.5%) 28.3 ( − 57.2%) T able 2: Objective and subjecti ve voice con version scores. F or all measures, higher is better . The first two reference ro ws correspond to using original recordings from source or tar get speakers as tar get. Approach Objectiv e Subjectiv e L [nat/dim] Spoofing [%] Naturalness [1–5] Similarity [%] Source as target n/a 1.1 4.83 10.6 T ar get as target n/a 99.3 4.83 98.5 Glow 4.11 1.2 n/a n/a Glow-W aveNet 4.18 3.1 n/a n/a StarGAN n/a 44.4 2.87 61.8 VQ-V AE n/a 65.0 2.42 69.7 Blow 4.45 89.3 2.83 77.6 measure reflecting the percentage of times a con version is able to fool a speaker identification classifier (Spoofing). The classifier is an MFCC-based single-layer classifier trained with the same split as the con version systems (Appendix B ). For the subjecti ve ev aluation we follow W ester et al. [ 52 ] and consider the naturalness of the speech (Naturalness) and the similarity of the con verted speech to the target identity (Similarity). Naturalness is based on a mean opinion score from 1 to 5, while Similarity is an aggregate percentage from a binary rating. A total of 33 people participated in the subjectiv e e v aluation. Further details on our experimental setup are giv en in Appendix B . 6 Results 6.1 Ablation study First of all, we assess the effect of the introduced changes with objectiv e scores L and Spoofing. Due to computational constraints, in this set of e xperiments we limit training to 5 min of audio per speaker and 100 epochs. The results are in T able 1 . In general, we see that all introduced improvements are important, as remo ving any of them alw ays implies worse scores. Nonetheless, some are more critical than others. The most critical one is the use of a single-scale structure. The two alternativ es with a multi-scale structure (3–4) yield the worst likelihoods and spoofings, to the point that (3) does not ev en perform any conv ersion. Using an 8 × 12 structure instead of the original 3 × 32 structure of Glow can also hav e a large ef fect (1). Howe ver , if we further tune the squeezing factor we can mitigate it (2). Substituting the hyperconditioning module by a re gular con volution plus a learnable additiv e embedding has a marginal ef fect on L , but a crucial ef fect on Spoofing (5–6). Finally , the proposed data augmentation strategies also prov e to be important, at least with 5 min per speaker (7). 6.2 V oice conv ersion In T able 2 we sho w the results for both objecti ve and subjecti v e scores. The two objecti ve scores, L and Spoofing, indicate that Blow outperforms the other considered approaches. It achie ves a relativ e L increment of 6% from Glo w-W av enet and a relati ve Spoofing increment of 37% from VQ-V AE. Another thing to note is that adapted Glow-based models, although achieving a reasonable likelihood, 7 1 4 8 16 32 Training audio [h] 4.1 4.2 4.3 4.4 L [ n a t / d i m ] A 1 4 8 16 32 Training audio [h] 0 25 50 75 100 Spoofing [%] B 1 25 50 75 100 Target speaker (sorted) 0 50 100 Spoofing [%] C 1 25 50 75 100 Source speaker (sorted) 0 50 100 D Figure 2: Objecti ve scores with respect to amount of training (A–B) and target/source speaker (C–D). are not able to perform con v ersion, as their Spoofing is very close to that of the “source as target” reference. Because of that, we discarded those in the subjecti v e e v aluation. The subjectiv e e v aluation confirms the good performance of Blow . In terms of Naturalness, StarGAN outperforms Blo w , albeit by only a 1% relati ve dif ference, without statistical significance (ANO V A, p = 0 . 76 ). Howe ver , both approaches are significantly below the reference audios ( p < 0 . 05 ). In terms of similarity to the tar get, Blo w outperforms both StarGAN and VQ-V AE by a relativ e 25 and 11%, respecti vely . Statistical significance is observ ed between Blo w and StarGAN (Barnard’ s test, p = 0 . 02 ) but not between Blow and VQ-V AE ( p = 0 . 13 ). Further analysis of the obtained subjectiv e scores can be found in Appendix C . T o put Blow’ s results into further perspectiv e, we can hav e a look at the non-parallel task of the last voice con version challenge [ 10 ], where systems that do not perform transfer learning or pre-training achie ve Naturalness scores slightly below 3.0 and Similarity scores equal to or lower than 75%. Example con versions can be listened from https://blowconversions.github.io . 6.3 Amount of training data and source/tar get prefer ence T o conclude, we study the behavior of the objectiv e scores when decreasing the amount of training audio (including the inherent silence in the data set, which we estimate is around 40%). W e observ e that, at 100 epochs, training with 18 h yields almost the same likelihood (Fig. 2 A) and spoofing (Fig. 2 B) than training with the full set of 37 h. W ith it, we do not observe any clear relationship between Spoofing and per-speaker duration (Appendix C ). What we observe, ho we v er , is a tendency with re gard to source and tar get identities. If we a verage spoofing scores for a gi v en tar get identity , we obtain both almost-perfect scores close to 100% and some scores below 50% (Fig. 2 C). In contrast, if we av erage spoofing scores for a gi v en source identity , those are almost always abo ve 70% and belo w 100% (Fig. 2 D). This indicates that the target identity is critical for the con version to succeed, with relativ e independence of the source. W e hypothesize that this is due to the way normalizing flows are trained (maximizing likelihood only for single inputs and identifiers; nev er performing an actual con v ersion to a target speak er), b ut leav e the analysis of this phenomenon for future work. 7 Conclusion In this work we put forward the potential of flo w-based generati ve models for raw audio synthesis, and specially for the challenging task of non-parallel v oice con version. W e propose Blow , a single- scale hyperconditioned flo w that features a many-block structure with shared embeddings and performs con v ersion in a forward-backward manner . Because Blo w departs from existing flo w-based generativ e models in these aspects, it is able to outperform those and compete with, or ev en impro ve upon, existing non-parallel v oice conv ersion systems. W e also quantify the impact of the proposed improv ements and assess the effect that the amount of training data and the selection of source/target speaker can ha ve in the final result. As future work, we want to improv e the model to see if we can deal with other tasks such as speech enhancement or instrument con version, perhaps by further enhancing the hyperconditioning mechanism or , simply , by tuning its structure or hyperparameters. Acknowledgments W e are grateful to all participants of the subjectiv e e v aluation for their input and feedback. W e thank Antonio Bonafonte, Ferran Diego, and Martin Pielot for helpful comments. SP ackno wledges partial support from the project TEC2015-69266-P (MINECO/FEDER, UE). 8 References [1] A. V an den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Grav es, N. Kalchbrenner , A. Senior , and K. Kavukcuoglu. W av eNet: a generati ve model for ra w audio. ArXiv , 1609.03499, 2016. [2] S. Mehri, K. Kumar , I. Gulrajani, R. Kumar , S. Jain, J. Sotelo, A. Courville, and Y . Bengio. SampleRNN: an unconditional end-to-end neural audio generation model. In Pr oc. of the Int. Conf. on Learning Representations (ICLR) , 2017. [3] N. Kalchbrenner , E. Elsen, K. Simonyan, N. Casagrande, E. Lockhart, F . Stimber g, A. V an den Oord, S. Dieleman, and K. Ka vukcuoglu. Efficient neural audio synthesis. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 2410–2419, 2018. [4] S. Pascual, A. Bonafonte, and J. Serrà. SEGAN: speech enhancement generativ e adv ersarial network. In Pr oc. of the Int. Speech Communication Association Conf. (INTERSPEECH) , pages 3642–3646, 2017. [5] C. Donahue, J. McAuley , and M. Puckette. Adversarial audio synthesis. In Pr oc. of the Int. Conf. on Learning Representations (ICLR) , 2019. [6] R. Prenger , R. V alle, and B. Catanzaro. W a veGlo w: a flow-based generati ve netw ork for speech synthesis. In Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 3617–3621, 2018. [7] S. Kim, S.-G. Lee, J. Song, and S. Y oon. FloW a veNet : a generati ve flow for raw audio. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 3370–3378, 2018. [8] S. Dieleman, A. V an den Oord, and K. Simonyan. The challenge of realistic music generation: modeling raw audio at scale. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , volume 31, pages 7989–7999. Curran Associates, Inc., 2018. [9] S. H. Mohammadi and A. Kain. An overvie w of voice con version systems. Speech Communica- tion , 88:65–82, 2017. [10] J. Lorenzo-T rueba, J. Y amagishi, T . T oda, D. Saito, F . V illa vicencio, T . Kinnunen, and Z. Ling. The voice con v ersion challenge 2018: promoting dev elopment of parallel and nonparallel methods. In Pr oc. of Odissey , The Speaker and Language Recognition W orkshop (Odisse y) , pages 195–202, 2018. [11] Y . Saito, Y . Ijima, K. Nishida, and S. T akamichi. Non-parallel voice con version using v ariational autoencoders conditioned by phonetic posteriorgrams and d-vectors. In Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 5274–5278, 2018. [12] H. Kameoka, T . Kaneko, K. T anaka, and N. Hojo. ACV AE-VC: Non-parallel many-to-many voice con version with auxiliary classifier v ariational autoencoder. ArXiv , 1808.05092, 2018. [13] T . Kaneko and H. Kameoka. CycleGAN-VC: non-parallel voice con version using c ycle- consistent adversarial networks. In Pr oc. o f the Eur opean Signal Pr ocessing Conf. (EUSIPCO) , pages 2114–2118, 2018. [14] H. Kameoka, T . Kaneko, K. T anaka, and N. Hojo. StarGAN-VC: non-parallel many-to-many voice conv ersion with star generative adversarial networks. In Pr oc. of the IEEE Spok en Language T ec hnology W orkshop (SLT) , pages 266–273, 2018. [15] C. C. Hsu, H. T . Hwang, Y . C. W u, Y . Tsao, and H. M. W ang. V oice con version from unaligned corpora using variational autoencoding wasserstein generati ve adversarial networks. In Pr oc. of the Int. Speech Communication Association Conf. (INTERSPEECH) , pages 3364–3368, 2017. [16] D. P . Kingma and P . Dhariwal. Glow: generative flow with in vertible 1x1 con volutions. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , volume 31, pages 10215–10224. Curran Associates, Inc., 2018. [17] D. Ha, A. Dai, and Q. V . Le. HyperNetworks. In Pr oc. of the Int. Conf. on Learning Repr esen- tations (ICLR) , 2017. 9 [18] M. Y amaguchi, Y . K oizumi, and N. Harada. AdaFlow: domain-adaptive density estimator with application to anomaly detection and unpaired cross-domain translation. In Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 3647–3651, 2019. [19] Y . Li, N. W ang, J. Shi, H. Hou, and J. Liu. Adapti ve batch normalization for practical domain adaptation. P attern Recognition , 80:109–117, 2018. [20] H. B. Barlo w . Unsupervised learning. Neural Computation , 1:295–311, 1989. [21] A. N. Redlich. Supervised factorial learning. Neural Computation , 5:750–766, 1993. [22] G. Deco and W . Brauer . Higher order statistical decorrelation without information loss. In Advances in Neural Information Processing Systems (NeurIPS) , volume 7, pages 247–254. MIT Press, 1995. [23] L. Dinh, D. Krueger , and Y . Bengio. NICE: non-linear independent components estimation. In Pr oc. of the Int. Conf. on Learning Repr esentations (ICLR) , 2015. [24] D. J. Rezende and S. Mohamed. V ariational inference with normalizing flo ws. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 1530–1538, 2015. [25] L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using Real NVP. In Proc. of the Int. Conf. on Learning Representations (ICLR) , 2017. [26] E. G. T abak and C. V . T urner . A family of non-parametric density estimation algorithms. Communications on Pur e and Applied Mathematics , 66(2):145–164, 2013. [27] A. Mouchtaris, J. V an der Spie gel, and P . Mueller . Non-parallel training for v oice con version based on a parameter adaptation approach. IEEE T rans. on Audio, Speech and Language Pr ocessing , 14(3):952–963, 2006. [28] D. Erro, A. Moreno, and A. Bonafonte. INCA algorithm for training voice con version systems from nonparallel corpora. IEEE T rans. on Audio, Speech and Language Processing , 18(5): 944–953, 2010. [29] Z. W u, T . Kinnunen, E. S. Chang, and H. Li. Mixture of factor analyzers using priors from non-parallel speech for voice con version. IEEE Signal Processing Letters , 19(12):914–917, 2012. [30] T . Kinnunen, L. Juvela, P . Alku, and J. Y amagishi. Non-parallel voice con version using i-vector PLD A: towards unifying speak er verification and transformation. In Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 5535–5539, 2017. [31] F .-L. Xie, F . K. Soong, and H. Li. A KL diver gence and DNN-based approach to v oice con v ersion without parallel training sentences. In Pr oc. of the Int. Speech Communication Association Conf. (INTERSPEECH) , pages 287–291, 2016. [32] S. O. Arik, J. Chen, K. Peng, W . Ping, and Y . Zhou. Neural v oice cloning with a fe w samples. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , volume 31, pages 10019–10029. Curran Associates, Inc., 2018. [33] A. V an den Oord, O. V inyals, and K. Kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , volume 30, pages 6306–6315. Curran Associates, Inc., 2017. [34] J. Engel, C. Resnick, A. Roberts, S. Dieleman, D. Eck, K. Simonyan, and M. Norouzi. Neural audio synthesis of musical notes with W aveNet autoencoders. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 1068–1077, 2017. [35] N. Mor , L. W olf, A. Polyak, and Y . T aigman. A univ ersal music translation network. In Pr oc. of the Int. Conf. on Learning Representations (ICLR) , 2019. [36] E. Nachmani and L. W olf. Unsupervised singing voice con v ersion. ArXiv , 1904.06590, 2019. 10 [37] A. Haque, M. Guo, and P . V erma. Conditional end-to-end audio transforms. In Pr oc. of the Int. Speech Communication Association Conf. (INTERSPEECH) , pages 2295–2299, 2018. [38] W . Grathwohl, R. T . Q. Chen, J. Bettencourt, I. Sutske ver , and D. Duv enaud. FFJORD: free- form continuous dynamics for scalable re v ersible generati ve models. In Pr oc. of the Int. Conf. on Learning Repr esentations (ICLR) , 2019. [39] J. Ho, X. Chen, A. Sriniv as, R. Duan, and P . Abbeel. Flo w++: improving flow-based generati ve models with variational dequantization and architecture design. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 2722–2730, 2019. [40] L. Dinh, J. Sohl-Dickstein, R. P ascanu, and H. Larochelle. A RAD approach to deep mixture models. ArXiv , 1903.07714, 2019. [41] M. Livne and D. J. Fleet. TzK Flow - Conditional Generativ e Model. ArXiv , 1811.01837, 2018. [42] S. J. Hwang and W . H. Kim. Conditional recurrent flow: conditional generation of longitudinal samples with applications to neuroimaging. ArXiv , 1811.09897, 2018. [43] E. Hoogeboom, R. V an den Berg, and M. W elling. Emerging con volutions for generative normalizing flows. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 2771–2780, 2019. [44] K. Simonyan and A. Zisserman. V ery deep con v olutional networks for large-scale image recognition. In Pr oc. of the Int. Conf. on Learning Repr esentations (ICLR) , 2015. [45] B. Ziolko and M. Ziolk o. T ime durations of phonemes in Polish language for speech and speaker recognition. In Z. V etulani, editor, Human language technology - Challenges for computer science and linguistics , volume 6562 of Lectur e Notes in Computer Science . Springer , Berlin, Germany , 2011. [46] T . Karras, S. Laine, and T . Aila. A style-based generator architecture for generativ e adversarial networks. In Proc. of the Conf. on Computer V ision and P attern Recognition (CVPR) , 2019. [47] P . Boersma and D. W eenink. Praat: doing phonetics by computer, 2019. URL http://www. praat.org/ . [48] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Y ang, Z. DeV ito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer . Automatic differentiation in PyT orch. In NeurIPS W orkshop on The Futur e of Gradient-based Machine Learning Software & T ec hniques (NeurIPS-Autodif f) , 2017. [49] L. Kaiser , A. N. Gomez, and F . Chollet. Depthwise separable conv olutions for neural machine translation. In Pr oc. of the Int. Conf. on Learning Repr esentations (ICLR) , 2018. [50] A. Krizhe vsky , I. Sutsk e ver , and G. Hinton. ImageNet classification with deep con volutional neural networks. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , volume 25, pages 1097–1105. Curran Associates, Inc., 2012. [51] C. V eaux, J. Y amagishi, and K. MacDonald. CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit, 2012. URL http://dx.doi.org/10.7488/ds/1994 . [52] M. W ester , Z. W u, and J. Y amagishi. Analysis of the v oice con version challenge 2016 e valuation results. In Pr oc. of the Int. Speech Communication Association Conf. (INTERSPEECH) , pages 1637–1641, 2016. [53] Y . Choi, M. Choi, M. Kim, J.-W . Ha, S. Kim, and J. Choo. StarGAN: unified generative adversarial networks for multi-domain image-to-image translation. In Proc. of the Conf. on Computer V ision and P attern Recognition (CVPR) , pages 8789–8797, 2018. [54] M. Morise, F . Y okomori, and K. Oza wa. WORLD: a vocoder-based high-quality speech synthesis system for real-time applications. IEICE T ransactions on Information and Systems , 99(7):1877–1884, 2016. [55] S. O. Arik, M. Chrzanowski, A. Coates, G. Diamos, A. Gibiansky , Y . Kang, X. Li, J. Miller, A. Ng, J. Raiman, S. Sengupta, and M. Shoeybi. Deep voice: real-time neural text-to-speech. In Pr oc. of the Int. Conf. on Machine Learning (ICML) , pages 195–204, 2017. 11 A ppendix A Recap of the log-likelihood equation deriv ation Follo wing Rezende and Mohamed [ 24 ] , if we use a normalizing flow f to transform a random v ariable x with distribution p ( x ) , the resulting random v ariable z = f ( x ) has a distribution p ( z ) = p ( f ( x )) = p ( x ) det ∂ f − 1 ( z ) ∂ z , which is deri ved from the change of variables formula. By the in verse function theorem, we can work with the Jacobian of f , p ( z ) = p ( x ) det ∂ f ( z ) ∂ z − 1 and, taking logarithms and rearranging, we reach log ( p ( x )) = log ( p ( z )) + log det ∂ f ( z ) ∂ z , as expressed by , for instance, Dinh et al. [ 25 ] . Finally , since f is a composite function (Sec. 3), we can write the previous equation as Kingma and Dhariw al [ 16 ]: log ( p ( x )) = log ( p ( z )) + k X i =1 log det ∂ f i ( h i − 1 ) ∂ h i − 1 . This is the expression we use to optimize the normalizing flo w . Notice that log-determinants can be factored out at each flo w step, shuttling gradients back to each f i (or h i ) and below . B Detail of the experimental setup B.1 Data As mentioned in the main paper , we use the VCTK data set [ 51 ], which originally contains 46 h of audio from 109 speakers. The only pre-processing we perform to the original audio is to downsample to 16 kHz and to normalize ev ery file between − 1 and 1. Later , at training time, silent frames with a standard deviation belo w 0.025 are discarded. As mentioned, we use frames of 4096 samples. T o obtain train, v alidation, and test splits, we parse the text of e very sentence and group utterances of the same text (we discard the speaker without a v ailable text). W e then randomly e xtract 10% of the sentences for validation and 10% for test. This way , we force that the same text content is not present in more than one split, and therefore that sentences in v alidation or test are not included in training. The total amount of training audio is 36 h which, with 108 speakers, yields an av erage of 20 min per speaker . Other statistics are reported in T able 3 . T able 3: Train, v alidation, and test numbers. Description T rain V alidation T est Audio duration 36.7 h 4.4 h 4.5 h Number of sentences 10609 1325 1325 Number of files 35247 4417 4406 Number of frames (discarding silence) 291154 34390 35253 All reported results are based on the test split, including the audios used for subjecti ve e valuation. W e perform one con version per test file, by choosing a dif ferent speaker from the pool of all av ailable speakers uniformly at random (irrespecti ve of the gender or other metadata). 12 B.2 Baselines B.2.1 Glow-based For performing audio con version with Glow-based baselines, we initially considered a conditioning- only strategy . In the case of Glow , this implied computing a Gaussian mean for e very label at training time and subtracting it in z space (adding it when going from z to x ). In the case of Glo w-W aveNet, as it directly accepts a conditioning, we implement independent learnable embeddings that are added at the first layer of e v ery coupling, as done with the mel conditioning of W aveGlo w [ 6 ]. The conditioning-only strategy , ho wever , turned out to perform poorly for these models in preliminary experiments. Using a manipulation-only strategy as proposed by Kingma and Dhariwal [ 16 ] was also found to perform poorly . Some con version could be perceiv ed, like for instance changing identities from male to female, but obtained identities were not similar to the target ones. In addition, we found annoying audio artifacts were easily appearing, and that those could be amplified with just minimal changes in the manipulation strategy . In the end, we decided to use both strategies and augment the conditioning-only strategy with the semantic manipulation one. W e empirically chose a scaling factor of 3 as a trade-off between amount of con v ersion and generation of artifacts. W e also found that weighting the contribution to the mean by the energy of x could slightly impro ve con version. B.2.2 StarGAN The baseline StarGAN model is based on StarGAN-VC [ 14 ], which uses StarGAN [ 53 ] to learn non-parallel many-to-man y mappings between speak ers. It is worth noting that this approach does not work at the waveform le vel, but instead extracts the fundamental frequency , aperiodicity , and spectral en velope from each audio clip, and then performs the con v ersion by means of its generator at the spectral en v elope le vel. For generating the target speak ers’ speech, the WORLD v ocoder [ 54 ] is used with the transformed spectral en velope, linearly-con verted pitch, and original aperiodicity as inputs. In the original StarGAN-VC paper , the experiments comprised only 4 speakers (2 male and 2 female), while in this work we extended it to all VCTK speakers. Howe ver , in our setup, publicly a v ailable implementations of this architecture did not generate a reasonably natural speech, and hence we tried with a alternati ve implementation. In particular , our baseline is based on an implementation 2 that uses the same architecture as the original image-to-image StarGAN [ 53 ]. The main difference with StarGAN-VC is that it does not include any conditioning on the speaker in the discriminator network, b ut instead the discriminator and domain classifier (that acts as a speak er classifier) share the same underlying network weights. The other difference is that the training uses a W asserstein GAN objectiv e with gradient penalty . B.2.3 VQ-V AE The baseline VQ-V AE model for v oice con version is based on [ 33 ]. The e xact specification details such as the wa veform encoder architecture are not pro vided in the paper and, to our kno wledge, an of ficial model implementation has not been published so far . W e tried a number of non-of ficial implementations but, in the end, found our o wn implementation to perform better in preliminary experiments. Our implementation follows as closely as possible [ 33 ]. W e use 7 strided con volutions for the audio encoder with a stride of 2 and a kernel size of 4, with 448 channels in the last layer . Therefore, we have a time-domain compression of 2 7 compared to the original raw audio. The feature map is then projected into a latent space of dimension 128, and the discrete space of the quantized vectors is 512. The discrete latent codes are concatenated with the target speaker embedding and then upsampled in the time dimension using a decon volutional layer with a stride of 2 7 , which is used as the local conditioning for the W a veNet decoder . T o speed up the audio generation, our W a v eNet implementation uses the one provided by NVIDIA 3 , which implements the W aveNet v ariant 2 https://github.com/liusongxiang/StarGAN- Voice- Conversion 3 https://github.com/NVIDIA/nv- wavenet 13 described by Arik et al. [ 55 ] . Howe ver , to perform a fair comparison with Blow (and possibly differently from [ 33 ]), we do not use any pre-trained weight in the W aveNet nor the VQ-V AE structures. B.3 Spoofing classifier T o objecti vely ev aluate the capacity of the considered approaches to perform v oice con version we employ a speaker identity classifier , which we train on the same split as the con v ersion approaches. The classifier uses classic speech features computed within a short-time frame. W ith that, we believe the Spoofing measure captures not only speak er identities, b ut can also be af fected by audio artif acts or distortions that may ha ve an impact to the short-time, frame-based features. W e use 40 mel-frequency cepstral coefficients (MFCCs), their deltas, their delta-deltas, and the root mean square energy . From those we then compute the mean and the standard deviation across frames to summarize the speaker identity in an audio file. T o extract features we use librosa 4 with default parameters, except for some of the MFCC ones: FFT hop of 128, FFT windo w of 256, FFT size of 2048, and 200 mel bands. After feature extraction, we apply z-score normalization, computing the mean and the standard de viation from training data. The classifier is a linear network with dropout, trained with categorical cross-entropy . W e then apply a dropout of 0.4 to the input features and a linear layer with bias. W e train the classifier with Adam using a learning rate of 10 − 3 and stop training when the v alidation loss has not impro ved for 10 epochs. W ith 108 speakers, this classifier achiev es an accurac y of 99.3% on the test split. B.4 Subjective e valuation For the subjecti ve e v aluation we follo w W ester et al. [ 52 ] . The y di vide it into tw o aspects: naturalness and similarity . Naturalness aims to measure the amount of artifacts or distortion that is present in the generated signals. Similarity aims to measure how much the con verted speaker identity resembles either the source or the tar get identity . Naturalness is measured with a mean opinion score between 1 and 5, and similarities are measured with a binary decision, allowing the option to e xpress some uncertainty . Statistical significance is assessed with an analysis of v ariance (ANO V A) for Naturalness and with Barnard’ s test for Similarity (both single tail, with p < 0 . 05 ). A total of 33 subjects participated of the subjective e valuation. From those, 3 were nativ e English speakers and 8 declared having some speech processing expertise. Participants were presented to 16 audio examples in the Naturalness assessment part (4 per system) and to 16 audio pairs in the Similarity assessment part (4 per system, two for similar t o the target and tw o for similar to the source assessments). C Additional results C.1 Analysis of subjective scor es A visual summary of the numbers reported in the main paper is depicted in Fig. 3 . W e see that the three considered systems cluster together , falling apart from the real target and source v oices. Among the three systems, Blo w stands out, specially in similarity to the target (v ertical axis), and competes closely with StarGAN in terms of Naturalness (horizontal axis). If we study naturalness scores alone, we see that the dif ference between Blow and StarGAN is minimal (Fig 4 ). Actually , we find no statistically significant dif ference between the two (ANO V A, p = 0 . 76 ). This is a good result if we consider that spectral-based approaches, such as StarGAN, are often preferred with regard to Naturalness due to their constriction to not generate audible artifacts in the time domain. If we study similarity judgments alone, we observe a different picture (Figs. 5 and 6 ). Focusing on similarity to the target, Blo w performs better than StarGAN and VQ-V AE. The ranking of the methods can be clearly seen when disreg arding the confidence on the decisions (Fig. 5 , left). Statistical significance is observed between Blo w and StarGAN (Barnard’ s test, p = 0 . 02 ) but not between Blow and VQ-V AE ( p = 0 . 13 ). If we consider the de gree of confidence, we see the dif ference is in 4 http://librosa.github.io/librosa 14 1 2 3 4 5 Naturalness [1-5] 0 20 40 60 80 100 Similarity to target [%] Source StarGAN Target Blow VQ-VAE Figure 3: Scatter plot of the subjectiv e ev aluation results: Naturalness (horizontal axis) and similarity to the target (v ertical axis) for the considered models and references. Source Target StarGAN Blow VQ-VAE 1 2 3 4 5 Naturalness [1-5] Figure 4: Box plot of Naturalness MOS. Red triangles indicate the arithmetic mean. Target Blow VQ-VAE StarGAN Source 0 20 40 60 80 100 Similarity to target [%] Same Different Target Blow VQ-VAE StarGAN Source 0 20 40 60 80 100 Similarity to target [%] Same: absolutely sure Same: not sure Different: not sure Different: absolutely sure Figure 5: Similarity to the target ratings disregarding confidence (left) and including confidence assessment (right). the “Same: not sure” ratings, as all three obtain almost the same number of “Same: absolutely sure” decisions (Fig. 5 , right). Finally , it is also interesting to look at the results for similarity to the source (Fig. 6 ). In them, we see that Blow and StarGAN generate slightly more audios that are considered to be similar to the source than VQ-V AE. This could indicate a problem in con v erting from some source identities, as the characteristics of those seem to remain in the con version. Howe v er , in general, the amount of “Similar to the source” con versions is lo w , belo w 20%, and relati vely close to the 10.6% obtained for the control group that compares real dif ferent identities (the target ones) with the source identities (Fig. 6 , leftmost bars). 15 Target VQ-VAE StarGAN Blow Source 0 20 40 60 80 100 Similarity to source [%] Same Different Target VQ-VAE StarGAN Blow Source 0 20 40 60 80 100 Similarity to source [%] Same: absolutely sure Same: not sure Different: not sure Different: absolutely sure Figure 6: Similarity to the source ratings disregarding confidence (left) and including confidence (right) assessments. T able 4: Objective scores at 100 epochs for dif ferent training sizes. T otal amount of training audio 1.8 h 3.6 h 9 h 18 h 37 h (full) T raining audio per speaker 1 min 2 min 5 min 10 min 20.4 min (average) L [nat/dim] 4.11 4.20 4.30 4.35 4.37 Spoofing [%] 9.3 31.9 66.2 81.6 86.5 15 20 25 30 35 40 Duration [min] 0 25 50 75 100 Spoofing [%] Figure 7: Spoofing percentage with respect to amount of training audio per speaker at 100 training epochs (full data set, including silence). C.2 Amount of training audio For completeness, in T able 4 we report the exact numbers depicted in Figs. 2A and 2B of the main paper . In Fig. 7 , we further study Spoofing with respect to the amount of audio per speaker in the full training set. W e do not observe any trend with respect to duration of training audio per speaker . All these results are calculated after 100 epochs of training. C.3 Condition-free latent space A driving idea of Blo w is that the latent space z should be condition-free (or identity-agnostic). This is what motiv ates us to use hyperconditioning to progressively remo ve condition/identity characteristics when transforming from x to z (and later to progressi vely imprint ne w condition/identity character - istics when transforming back from z to x ). In order to substantiate a bit more our hypothesis, we decide to study the capacity to perform speaker identification in the latent space z . The idea is that, if z vectors contain some speaker information, a classifier should be able to perform some speaker identification in z space. 16 T o quantify the amount of speaker identity information present in z , we proceed as with the Spoofing classifier (see above), but using the actual vectors z as frame-based features. The only difference is that, in the current case, we are interested in the result of a more comple x classifier with enough power to e xtract non-tri vial, relev ant information from the features, if any . T o this end, we consider a random forest classifier and a multi-layer perceptron (we use scikit-learn version 0.20.2 with default parameters, except for the number of estimators of the random forest classifier , which we set to 50, and the number of layers of the multi-layer perceptron, which we set to three, with 1000 and 100 intermediate activ ations). The test accuracies we obtain for the two classifiers are 1.8% (random forest) and 1.4% (multi- layer perceptron). Both are only marginally above random chance (1.1%), and far from the value obtained by classic features extracted from x (99.3%). This gi ves us an indication that there is little identity information in the z space. Ho wever , to further confirm our original hypothesis, additional experiments on the latent space z , which are beyond the scope of the current work, should be carried out. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment