지식 그래프 임베딩의 불확실성을 측정하는 신경 변분 추론
본 논문은 신경 변분 추론을 활용해 지식 그래프 임베딩의 예측 불확실성을 추정하는 새로운 생성 모델 프레임워크를 제안한다. Latent Information Model (LIM)과 Latent Fact Model (LFM)이라는 두 가지 확률적 모델을 도입하고, Bernoulli 샘플링을 통한 확장성 있는 학습 방법을 제시한다. 실험을 통해 특정 조건에서 기존 방법 대비 성능 향상을 보였으며, 학습된 임베딩의 분산을 활용한 불확실성 추정의 유용…
저자: Alex, er I. Cowen-Rivers, Pasquale Minervini
이 논문은 지식 그래프에서 누락된 링크를 예측(지식 베이스 완성)하는 문제에 있어, 예측의 불확실성을 정량화할 수 있는 생성적 신경 변분 모델 프레임워크를 제안한다. 기존 신경 링크 예측 모델이 판별적 모델로 점 추정만을 제공하는 한계를 지적하며, 대신 엔티티와 관계의 임베딩을 잠재 변수로 하는 베이지안 생성 모델을 설계한다.
핵심 방법론은 두 가지 새로운 모델, 즉 Latent Information Model (LIM)과 Latent Fact Model (LFM)의 도입이다. LIM은 엔티티 임베딩 집합(E)과 관계 임베딩 집합(R)을 별개의 잠재 변수로 설정하고, 사전 분포로 단위 정규분포를 부여한다. 반면 LFM은 모든 임베딩을 하나의 잠재 변수 집합(H)으로 통합한다. 두 모델 모두 관측된 삼중항 데이터(D)의 가능도는 임베딩을 기반으로 한 점수 함수(예: ComplEx, DistMult)의 소프트맥스 출력으로 정의한다. 변분 추론을 적용하여 이 모델들의 Evidence Lower Bound (ELBO)를 유도한다.
주요 기여점 중 하나는 대규모 최적화를 위한 확장성 있는 학습 전략이다. 지식 그래프의 모든 가능한 음수 삼중항을 고려하는 것은 계산상 비현실적이다. 논문은 Bernoulli 샘플링을 통해 ELBO 목적 함수를 근사하는 방식을 제시하며, 이를 통해 각 미니배치에서 하나의 음수 샘플만을 사용하는 일반적인 실무 방식을 변분 추론의 관점에서 엄밀하게 정당화한다. 이는 학습 시간을 크게 단축시키는 동시에 추가적인 근사 오차를 도입하는 트레이드오프를 만든다.
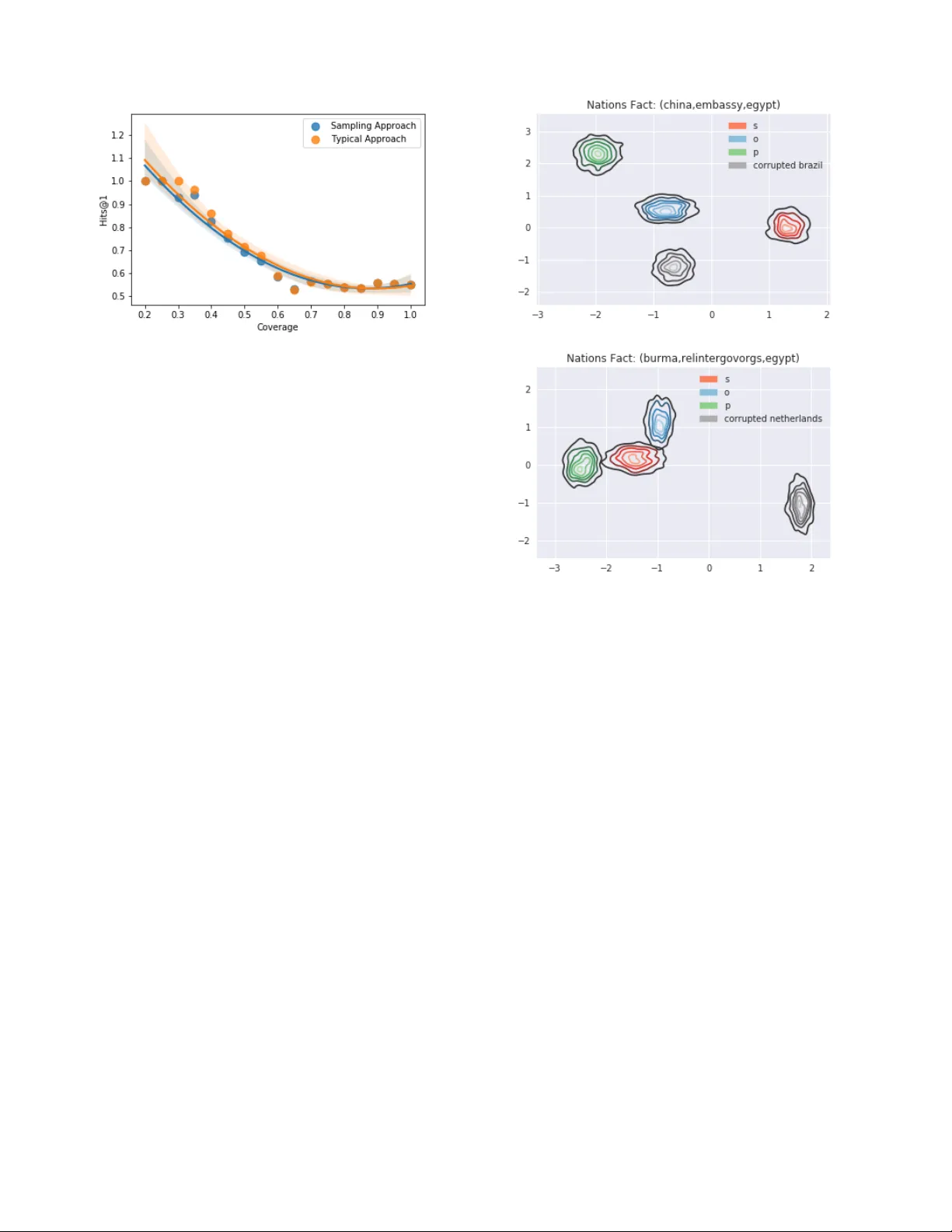
실험에서는 WN18과 WN18RR 데이터셋을 사용하여 제안된 변분 모델(Variational DistMult/ComplEx)을 기준선 모델과 비교한다. 결과는 일관되게 우월하지는 않지만, WN18에서 Variational ComplEx (LIM)가 기준 ComplEx 대비 Hits@10에서 약간의 향상을 보이는 등 특정 조건에서 개선이 가능함을 시사한다.更重要的是, 논문은 학습된 불확실성의 질을 분석한다. 엔티티와 관계의 평균 분산을 그 빈도에 대해 플롯한 결과, 빈도가 낮은 심볼일수록 모델이 더 높은 분산(즉, 더 큰 불확실성)을 부여한다는 명확한 상관관계를 발견했다. 이는 모델이 데이터의 통계적 특성을 성공적으로 포착하고 있음을 의미한다. 또한, 예측값의 크기 또는 순방향 샘플링을 통해 추정한 불확실성을 신뢰도 점수로 활용하여 정밀도-커버리지 곡선을 분석함으로써, 불확실성 추정이 예측 성능을 보정하거나 어려운 샘플을 식별하는 데 활용될 잠재력을 탐구한다.
종합적으로, 이 연구는 지식 그래프 임베딩에 베이지안 불확실성 추정을 통합하는 이론적으로 견고하고 확장 가능한 프레임워크를 제시하며, 학습된 불확실성이 의미 있는 정보를 담고 있음을 실증적으로 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기