Neural Variational Inference For Estimating Uncertainty in Knowledge Graph Embeddings
Recent advances in Neural Variational Inference allowed for a renaissance in latent variable models in a variety of domains involving high-dimensional data. While traditional variational methods derive an analytical approximation for the intractable …
Authors: Alex, er I. Cowen-Rivers, Pasquale Minervini
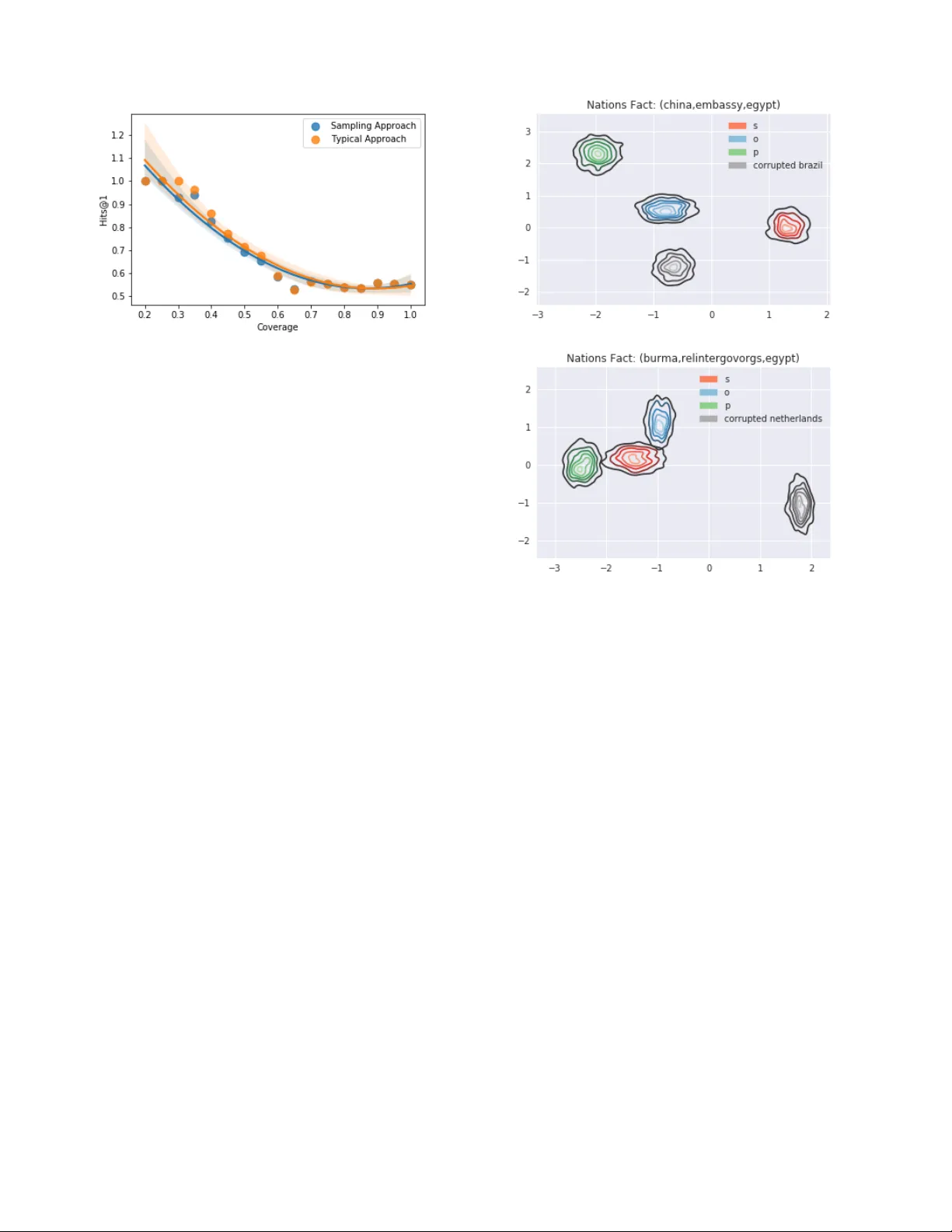
Neural V ariational Infer ence F or Estimating Uncertainty in Knowledge Graph Embeddings Alexander I. Cowen-Riv ers 1 , Pasquale Minervini 2 , Tim Rocktäschel 2 , Matko Bošnjak 2 , Sebastian Riedel 2 , Jun W ang 1 , 2 1 MediaGamma 2 Uni versity Colle ge London alexander .cowen-ri v ers@mediagamma.com Abstract Recent advances in Neural V ariational Inference al- lowed for a renaissance in latent variable models in a variety of domains in volving high-dimensional data. While traditional variational methods deri ve an ana- lytical approximation for the intractable distribution ov er the latent variables, here we construct an infer - ence network conditioned on the symbolic represen- tation of entities and relation types in the Kno wledge Graph, to provide the v ariational distributions. The new frame work results in a highly-scalable method. Under a Bernoulli sampling framework, we provide an alternati ve justification for commonly used tech- niques in large-scale stochastic v ariational inference, which drastically reduce training time at a cost of an additional approximation to the variational lo wer bound. W e introduce tw o models from this highly scalable probabilistic framew ork, namely the Latent Information and Latent F act models, for reasoning ov er knowledge graph-based representations. Our Latent Information and Latent Fact models improve upon baseline performance under certain conditions. W e use the learnt embedding v ariance to estimate predictiv e uncertainty during link prediction, and discuss the quality of these learnt uncertainty esti- mates. Our source code and datasets are publicly av ailable online 1 . 1 Introduction In many fields, including physics and biology , being able to represent uncertainty is of crucial importance [ Ghahramani, 2015 ] . Considering that neural link prediction models for predicting missing links in Knowledge Graphs are used in a variety of decision making tasks [ Bean et al. , 2017 ] , it would be beneficial to assess the predicti ve uncertainty of a model. Where a Kno wledge Graph is a set of f acts between symbols i.e. entities. Howe ver , a significant shortcoming of current neural link prediction models [ Dettmers et al. , 2017; T rouillon et al. , 2016 ] – and for the vast majority of neural representation 1 https://github .com/alexanderimanicowenri vers/ Neural- V ariational- Kno wledge- Graphs learning approaches – is their inability to e xpress a notion of uncertainty . Neural link prediction models typically return only point estimates of parameters and predictions [ Nickel et al. , 2016 ] , and are trained discriminatively rather than generatively : they aim at predicting one variable of interest conditioned on all the others, rather than accurately representing the relationships between different v ariables [ Ng and Jordan, 2001 ] . In a gener- ativ e probabilistic model, we could leverage the variance in model parameters and predictions for finding which f acts to sample during training, in an Active Learning setting [ Kapoor et al. , 2007; Gal et al. , 2017 ] . Furthermore, Kno wledge Graphs can be v ery large [ Dong et al. , 2014 ] , and often suf fer from incompleteness and spar- sity [ Dong et al. , 2014 ] : we deal with this through introducing a nov el method for including negati ve sampling in the estima- tion of the expected lower bound of our probabilistic models. 2 Background In this work, we focus on models for pr edicting missing links in large, multi-relational networks such as F R E E BA S E , be- tween symbolic items, i.e. nodes. In the literature, this prob- lem is referred to as link pr ediction . W e specifically focus on knowledge graphs , i.e., graph-structured kno wledge bases where f actual information is stored in the form of relationships between entities. Link prediction in kno wledge graphs is also known as knowledg e base completion . W e refer to [ Nickel et al. , 2016 ] for a recent surve y on approaches to this problem. A kno wledge graph G = { ( s, r , o ) } ⊆ [ N e ] × [ N r ] × [ N e ] can be formalised as a set of triples (facts) consisting of a r elation type r ∈ [ N r ] and two entities s, o ∈ [ N e ] , re- spectiv ely referred to as the subject (or head ) and the object (or tail ) of the triple. Each kno wledge graph triple ( s, r , o ) encodes a relationship of type r between entities s and o . A knowledge graph G can be represented as an adjacency tensor T ∈ { 0 , 1 } | [ N e ] |×| [ N r ] |×| [ N e ] | , where T s,r,o = 1 iff ( s, r , o ) ∈ G , and T s,r,o = 0 otherwise. Link pr ediction in knowledge graphs is often simplified to a learning to r ank problem, where the objecti ve is to find a score or ranking function φ Θ r : [ N e ] × [ N e ] 7→ R for a relation r that can be used for ranking triples according to the likelihood that the corresponding facts hold true. 2.1 Neural Link Pr ediction Recently , a specific class of link predictors receiv ed a growing interest [ Nickel et al. , 2016 ] . These predictors can be un- derstood as multi-layer neural networks where, gi ven a triple ( s, r , o ) of symbols, the associated score φ Θ ( s, r , o ) is given by a neural netw ork architecture encompassing an encoding layer and a scoring layer . In the encoding layer , the subject and object entities s and o are mapped to lo w-dimensional vector representations (em- beddings) E s = h ( s ) ∈ R k and E o = h ( o ) ∈ R k , produced by an encoder h Γ : [ N e ] → R k with parameters Γ . Sim- ilarly , relations r are mapped to R r = h ( r ) ∈ R k . This layer can be pre-trained [ Vylomov a et al. , 2016 ] or , more commonly , learnt from data by back-propagating the link prediction error to the encoding layer [ Nickel et al. , 2016; T rouillon et al. , 2016 ] . The scoring layer captures the interaction between the entity and relation representations E s , E o and R r are scored by a function φ Θ ( E s , R r , E o ) , parametrised by Θ . Other work encodes the entity-pair in one vector [ Riedel et al. , 2013 ] . Summarising, the high-lev el architecture is defined as: E s , R r , E o = h Γ ( s ) , h Γ ( r ) , h Γ ( o ) X s,r,o ≈ φ ( s, r, o ) = φ Θ ( E s , R r , E o ) . Ideally , more likely triples should be associated with higher scores, while less likely triples should be associated with lower scores. While the literature has produced a multitude of encoding and scoring strate gies, for bre vity , we overvie w only a small subset of these. Howe ver , we point out that our method makes no further assumptions about the network architecture other than the existence of an encoding layer . DistMult. D I S T M U L T [ Y ang et al. , 2015 ] represents each re- lation r and entities s, o using parameter vectors E s , R r , E o ∈ R k . For a fact ( s, r, o ) , the model scores the embeddings ( E s , R r , E o ) using the follo wing scoring function: φ Θ ( E s , R r , E o ) = h R r , E s , E o i where h· , · , ·i denotes the tri-linear dot product. ComplEx. C O M P L E X [ T rouillon et al. , 2016 ] is an exten- sion of D I S T M U LT [ Y ang et al. , 2015 ] using complex-v alued embeddings while retaining the mathematical definition of the dot product. In this model, the scoring function is defined as: φ Θ ( E s , R r , E o ) = Re h R r , E s , E o i , where E s , R r , E o ∈ C k are complex-valued v ectors, Re ( · ) denotes the real part of a vector , and E o denotes the complex conjugate of E o . 3 Generative Models In the follo wing, we propose tw o generati ve models for knowl- edge graph embeddings – the Latent Information Model (LIM) and the Latent Fact Model (LFM). y o i E e E r ( s i , r i ) e ∈ [ N e ] r ∈ [ N r ] i ∈ [ n ] (a) LIM y H h o i ( s i , r i ) h ∈ [ N e ] ∪ [ N r ] i ∈ [ n ] (b) LFM Generative Processes. A plate model for the LIM is shown in Figure 1(a). Let D ⊆ [ N e ] × [ N r ] × [ N e ] denote a set of triples. W e can define a joint probability distrib ution ov er p ( D , E , R ) – where E , R denote all the entity and relation embeddings – via the following generati ve model. • For each entity e ∈ [ N e ] , and relation r ∈ [ N r ] , draw an embedding vector E e ∼ p ( E e ) and R r ∼ p ( R r ) , e.g. from a multiv ariate normal distribution. • Repeat for each triple ( s, r , o ) ∈ D : – Draw a head s ∼ p ( s, r ) and a relation r ∼ p ( s, r ) from the discrete joint distribution p ( s, r ) . The choice of probability distrib ution p ( s, r ) has no in- fluence on inference. – Draw o ∼ Multinomial ( softmax ( X s,r,o )) with softmax ( X s,r,o ) = exp( X s,r,o ) / P o 0 exp( X s,r,o 0 ) , where X s,r,o is a model dependent function of E s , R r and E o , e.g a function of the model C O M - P L E X X s,r,o φ Θ ( E s , R r , E o ) . Generative Process: LFM Fig 1(b): A similar generati ve process to LIM, where we treat the embeddings for the entity and relation embeddings as a single latent variable. 3.1 Latent Fact Model The set of latent variables in this model is H = { E ∪ R } . For the Latent Fact Model (LFM), we assume that the Knowledge Graph was generated according to the follo wing generati ve model. W e place the unit Gaussian prior p θ ( H ) = G (0 , I ) on H . The joint probability of the variables p θ ( D , H ) is defined as follows: p θ ( D , H ) = Y h ∈ [ N e ] ∪ [ N r ] p θ ( H h ) Y ( X s,r,o ) ∈D p θ ( X s,r,o | H h ) The marginal distrib ution over D is then bounded as follo ws, with respect to our variational distrib ution q : Proposition 1 As a consequence, the log-mar ginal likelihood of the data, under the Latent F act Model, is bounded by: log p θ ( D ) ≥ E H ∼ q φ log p θ ( D | H ) − KL[ q φ ( H ) || p θ ( H )] (1) Assumptions: LFM model assumes each fact of is a ran- domly generated v ariable, as well as a mean field v ariational distribution and that each training e xample is independently distributed. Optimising LFM’ s ELBO Note that this is an enormous sum o ver |D | elements, which can be approximated via Importance Sampling, or Bernoulli Sampling [ Botev et al. , 2017 ] . ELBO = X ( X s,r,o ) ∈D E E , R ∼ q φ log p θ ( X s,r,o | H ) − KL[ q φ ( H ) || p θ ( H )] = X ( X s,r,o ) ∈D + E H ∼ q φ log p θ ( X s,r,o | H ) + X ( X s,r,o ) ∈D − E H ∼ q φ log p θ ( X s,r,o | H ) − KL[ q φ ( H ) || p θ ( H )] By using Bernoulli Sampling, ELBO can be approximated by defining a probability distrib ution of sampling from D + and D − – similarly to Bayesian Personalised Ranking [ Rendle et al. , 2009 ] , we sample one negati ve triple for each positiv e one — we use a constant probability for each element depending on whether it is in the positiv e or negati ve set. Proposition 2 The Latent F act models ELBO can be esti- mated similarly using a constant probability for positive or ne gative samples. W e end up with the following estimate: ELBO ≈ X ( X s,r,o ) ∈D + s s,r,o b + E H ∼ q φ log p θ ( X s,r,o | H ) + X ( X s,r,o ) ∈D − s s,r,o b − E H ∼ q φ log p θ ( X s,r,o | H ) − KL[ q φ ( H ) || p θ ( H )] where p θ ( s s,r,o = 1) = b s,r,o can be defined as the probability that for the coefficient s s,r,o each positive or negati ve fact s, r, o is equal to one (i.e is included in the ELBO summation). The exact ELBO can be recovered from setting b s,r,o = 1 . 0 for all s, r, o . where b + = |D + | / |D + | and b − = |D + | / |D − | . 3.2 Latent Information Model In Figure 1(a)’ s graphical model, we assume that the Kno wl- edge Graph was generated according to the follo wing genera- tiv e model. The set of latent entity v ariables in this model is E = { E e | e ∈ [ N e ] } and the set of latent relation variables R = { R r | r ∈ [ N r ] } . W e place the follo wing unit Gaussian priors p θ ( E ) = G (0 , I ) and p θ ( R ) = G (0 , I ) on E and R , re- spectiv ely . The joint probability of the variables p θ ( D , E , R ) is defined as follows: p θ ( D , E , R ) = Y e ∈ [ N e ] p θ ( E e ) Y r ∈ [ N r ] p θ ( R r ) Y ( X s,r,o ) ∈D p θ ( X s,r,o | E , R ) (2) Proposition 3 The log-mar ginal likelihood of the data, under the Latent Information Model, is the following: log p θ ( D ) ≥ E E , R ∼ q φ log p θ ( D | E , R ) − KL[ q φ ( E ) || p θ ( E )] − KL[ q φ ( R ) || p θ ( R )] (3) Assumptions: LIM makes the same assumptions as LFM, with the additional assumption that the entities and relations are separate latent variables. Optimising LIM’ s ELBO Similarly to Section 3.1, by using Bernoulli Sampling the ELBO can be approximated by using a constant probability for positi ve or ne gative samples, we end up with t he follo wing estimate: Proposition 4 The Latent Information Models ELBO can be estimated similarly using a constant pr obability for positive or ne gative samples. W e end up with the following estimate: ELBO ≈ ( X ( X s,r,o ) ∈D + s s,r,o b + E E , R ∼ q φ log p θ ( X s,r,o | E , R ) ) + ( X ( X s,r,o ) ∈D − s s,r,o b − E E , R ∼ q φ log p θ ( X s,r,o | E , R ) ) − KL[ q φ ( E ) || p θ ( E )] − KL[ q φ ( R ) || p θ ( R )] (4) where b + = |D + | / |D + | and b − = |D + | / |D − | . 4 Related W ork V ariational Deep Learning has seen great success in areas such as parametric/non-parametric document modelling [ Miao et al. , 2017; Miao et al. , 2016 ] and image generation [ Kingma and W elling, 2013a ] . Stochastic v ariational inference has been used to learn probability distributions over model weights [ Blundell et al. , 2015 ] , which the authors named "Bayes By Backprop". These models hav e pro ven powerful enough to train deep belief networks [ V ilnis and McCallum, 2014 ] , by improving upon the stochastic variational Bayes estimator [ Kingma and W elling, 2013a ] , using general v ariance reduc- tion techniques. Pre vious work has also researched word embeddings within a Bayesian frame work [ Zhang et al. , 2014; V ilnis and Mc- Callum, 2014 ] , as well as researched graph embeddings in a Bayesian framework [ He et al. , 2015 ] . Ho wever , these methods are expensi ve to train due to the ev aluation of com- plex tensor in versions. Recent work by [ Barkan, 2016; Bražinskas et al. , 2017 ] show that it is possible to train word embeddings through a variational Bayes [ Bishop, 2006 ] framew ork. KG2E [ He et al. , 2015 ] proposed a probabilistic embed- ding method for modelling the uncertainties in KGs. How- ev er, this was not a generativ e model. [ Xiao et al. , 2016 ] argued theirs was the first generativ e model for kno wledge graph embeddings. Howe ver , their work is empirically worse than a fe w of the generati ve models b uilt under our proposed framew ork, and their method is restricted to a Gaussian distri- bution prior . In contrast, we can use an y prior that permits a Dataset Scoring Function MR Hits @ Filter Raw 1 3 10 WN18 V DistMult (LIM) 786 798 0.671 0.931 0.947 DistMult 813 827 0.754 0.911 0.939 V ComplEx (LIM) 753 765 0.934 0.945 0.952 ComplEx* – – 0.939 0.944 0.947 WN18RR V DistMult (LIM) 6095 6109 0.357 0.423 0.440 DistMult 8595 8595 0.367 0.390 0.412 V ComplEx (LFM) 6500 6514 0.385 0.446 0.489 ComplEx** 5261 – 0.41 0.46 0.51 T able 1: Filtered and Mean Rank (MR) for the models tested on the WN18, WN18RR datasets. Hits@m metrics are filtered. Scoring functions with a "V" are results we reported under our variational framew ork LIM/LFM vs reported baseline results. re-parameterisation trick — such as a Normal [ Kingma and W elling, 2013b ] or von-Mises distribution [ Davidson et al. , 2018 ] . Later , [ Kipf and W elling, 2016 ] proposed a generative model for graph embeddings. Howe ver , their method lacks scalability as it requires the use of the full adjacency tensor of the graph as input. Moreover , our work differs in that we create a frame work for man y v ariational generati ve models ov er multi-relational data, rather than just a single genera- tiv e model over uni-relational data [ Kipf and W elling, 2016; Grov er et al. , 2018 ] . In a different task of graph genera- tion, similar models hav e been used on graph inputs, such as variational auto-encoders, to generate full graph struc- tures, such as molecules [ Simonovsk y and K omodakis, 2018; Liu et al. , 2018; De Cao and Kipf, 2018 ] . [ Salehi et al. , 2018 ] recently purposed a probabilistic kno wledge graph model, this is then used to learn regularisation weights using EM, whereas we want to focus on studying the learnt predictiv e uncertainty and not focus on learning a regularisation weight. Recent work by [ Chen et al. , 2018 ] constructed a v ariational path ranking algorithm, a graph feature model. This work differs from ours for two reasons. Firstly , it does not produce a generati ve model for kno wledge graph embeddings. Secondly , their work is a graph feature model, with the constraint of at most one relation per entity pair , whereas our model is a latent feature model with a theoretical unconstrained limit on the number of existing relationships between a gi ven pair of entities. 5 Experiments Experimental Setup W e run each link prediction experi- ment ov er 500 epochs and validate e very 50 epochs. Each KB dataset is separated into 80 % training facts, 10% de velopment facts, and 10% test facts. Results T able 1 shows definite improv ements on WN18 for V ariational ComplEx compared with the initially published x. W e believe this is due to the well-balanced model regu- larisation induced by the zero mean unit variance Gaussian prior . T able 1 also shows that the variational framew ork is outperformed by existing non-generativ e models, highlighting that the generati ve model may be better suited at identifying and predicting symmetric relationships. W ordNet18 [ Bordes et al. , 2013 ] (WN18) is a large lexical database of English. WN18RR is a subset with only asymmetric relations. W e now compare our model to the pre vious state-of-the-art multi- Dataset Scoring Function MR Filtered Raw Filter Hits@ 10 WN18 KG2E [ He et al. , 2015 ] 362 345 0.932 T ransG (Generativ e) [ Xiao et al. , 2016 ] 345 357 0.949 V ariational ComplEx (LIM) 753 765 0.952 T able 2: Latent Information Model vs. Existing Generative Models Figure 1: Mean V ariance vs. log frequency . T op: WN18RR Predicate Matrix. Bottom: WN18RR Entity Matrix. relational generative model T ransG [ Xiao et al. , 2016 ] , as well as to a previously published probabilistic embedding method KG2E (similarly represents each embedding with a multiv ariate Gaussian distribution) [ He et al. , 2015 ] on the WN18 dataset. T able 2 makes clear the improv ements in the performance of the pre vious state-of-the-art generati ve multi- relational knowledge graph model. Uncertainty Analysis These results hint at the possibility that the slightly stronger results of WN18 are due to covari- ances in our v ariational frame work able to capture information about symbol frequencies. W e verify this by plotting the mean value of cov ariance matrices, as a function of the entity or predicate frequencies (Figure 1). The plots confirm our hy- pothesis: covariances for the v ariational Latent Information Model gro ws with the frequency , and hence the LIM would put a preference on predicting relationships between less frequent symbols in the kno wledge graph. This also suggests that co- variances from the generati ve framework can capture accurate Figure 2: Precision - Cov erage Relationship. For the first confidence estimation method, we interpret the magnitude of the prediction as confidence. W e search over 1,000 cov erage values between (0,1]. At each cov erage value, we implement a threshold in which predictions outside this confidence range are discarded. W e then plot these and fit a regression line of order two, to estimate the trend. information about the generality of symbolic representations. Motiv ated by the desiring to reduce predictive uncertainty , we explore two methods for confidence estimation by; taking the magnitude of the prediction as confidence, attempting to mea- suring the models’ predictive uncertainty (achie ved through forward sampling). This experiment was carried out using the LIM on Nations dataset with, V ariational DistMult. Based on Fig 2, we can see a general trend of increased precision with a decrease in cov erage, exactly what we would desire from a model to estimate its confidence in a prediction. Unfortunately , utilising the uncertainty on the latent embeddings through sam- pling does not result in improv ed uncertainty estimates over using the magnitude of likelihood estimate as the confidence, which leav es further room for research into how best to utilise these learnt uncertainty estimates. V isualised V ariational Embedding Distrib utions W e project the high dimensional mean embedding vectors to tw o dimensions using Principal Component Analysis, to project the v ariance embedding vectors down to tw o dimensions using Non-negati ve Matrix Factorisation. Once we have the parame- ters for a bi variate normal distrib ution, we then sample from the bi variate normal distribution 1,000 times and then plot a bi-variate kernel density estimate of these samples. By visu- alising these two-dimensional samples, we can concei ve the space in which the entity or relation occupies. W e complete this process for the subject, object, relation, and a randomly sampled corrupted entity (under LCW A) to produce a visuali- sation of a fact, as sho wn in Figure 3. Figure 3 displays two true positiv es from test time predictions. The plots sho w that the v ariational framework can learn high dimensional represen- tations which when projected onto lower (more interpretable) dimensions, the distribution over embeddings are shaped to occupy areas at which facts lie. Figure 3: T rue positives. Each image visualises a facts sub- ject (red), object (blue) and relation (green) embedding, to show similarity , as well as a randomly sampled corrupted embedding to show dissimilarity . T op: C hina ⇒ Embassy E g y pt . Bottom: B ur ma ⇒ Intergov eremental Org E g y pt 6 Conclusion W e argue there is a lack of methods for quantifying predictive uncertainty in a kno wledge graph embedding representation, which can only be utilised using probabilistic modelling, as well as a lack of expressi veness under fixed-point represen- tations. W e introduce a frame work for creating a family of highly scalable probabilistic models for knowledge graph rep- resentation The frame work impro ves model performance un- der certain conditions, while reducing the parameter search by one hyper-parameter , as the unit Gaussian prior is self- regularising. Overall, we belie ve this work will enable knowl- edge graph researchers to work towards the goal of creating models better able to express their predicti ve uncertainty . Acknowledgments W e want to thank all members of the UCL NLP for useful discussions, and facilities provided by MediaGamma Ltd. References [ Barkan, 2016 ] O. Barkan. Bayesian neural word embedding. CoRR , abs/1603.06571, 2016. [ Bean et al. , 2017 ] D. Bean, H. W u, O. Dzahini, M. Broadbent, R. Stew art, and R. Dobson. Kno wledge graph prediction of unknown adverse drug reactions and v alidation in electronic health records. Scientific Reports , 7(1), 11 2017. [ Bishop, 2006 ] C. M. Bishop. P attern reco gnition and machine learning . Springer, 2006. [ Blundell et al. , 2015 ] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. W ierstra. W eight Uncertainty in Neural Networks. ArXiv e-prints , May 2015. [ Bordes et al. , 2013 ] A. Bordes, N. Usunier, A. Garcia-Duran, J. W eston, and O. Y akhnenko. T ranslating embeddings for modeling multi-relational data. In C. J. C. Burges, L. Bottou, M. W elling, Z. Ghahramani, and K. Q. W einberger , editors, Advances in Neural Information Pr ocessing Systems 26 , pages 2787–2795. Curran Associates, Inc., 2013. [ Botev et al. , 2017 ] A. Botev , B. Zheng, and D. Barber . Comple- mentary sum sampling for likelihood approximation in lar ge scale classification. In A. Singh and others, editors, Pr oceedings of the 20th International Confer ence on Artificial Intelligence and Statistics, AIST ATS 2017 , volume 54 of Pr oceedings of Machine Learning Resear ch , pages 1030–1038. PMLR, 2017. [ Bražinskas et al. , 2017 ] A. Bražinskas, S. Havrylov, and I. Tito v. Embedding W ords as Distributions with a Bayesian Skip-gram Model. ArXiv e-prints , November 2017. [ Chen et al. , 2018 ] W . Chen, W . Xiong, X. Y an, and W . Y . W ang. V ariational kno wledge graph reasoning. In NAA CL-HLT , 2018. [ Davidson et al. , 2018 ] T . R. Da vidson, L. Falorsi, N. De Cao, T . Kipf, and J. M. T omczak. Hyperspherical variational auto- encoders. arXiv preprint , 2018. [ De Cao and Kipf, 2018 ] N. De Cao and T . Kipf. Molgan: An im- plicit generati ve model for small molecular graphs. arXiv preprint arXiv:1805.11973 , 2018. [ Dettmers et al. , 2017 ] T . Dettmers, P . Minervini, P . Stenetorp, and S. Riedel. Con volutional 2d knowledge graph embeddings. arXiv pr eprint arXiv:1707.01476 , 2017. [ Dong et al. , 2014 ] X. Dong, E. Gabrilovich, G. Heitz, W . Horn, N. Lao, K. Murphy , T . Strohmann, S. Sun, and W . Zhang. Knowledge vault: a web-scale approach to probabilistic knowledge fusion. In S. A. Macskassy and others, editors, The 20th A CM SIGKDD International Confer ence on Knowledge Discovery and Data Min- ing, KDD ’14 , pages 601–610. A CM, 2014. [ Gal et al. , 2017 ] Y . Gal, R. Islam, and Z. Ghahramani. Deep bayesian activ e learning with image data. In D. Precup and oth- ers, editors, Pr oceedings of the 34th International Conference on Machine Learning, ICML 2017 , v olume 70 of Proceedings of Machine Learning Resear ch , pages 1183–1192. PMLR, 2017. [ Ghahramani, 2015 ] Z. Ghahramani. Probabilistic machine learning and artificial intelligence. Nature , 521(7553):452–459, 2015. [ Grov er et al. , 2018 ] A. Grov er , A. Zweig, and S. Ermon. Graphite: Iterativ e generative modeling of graphs. arXiv pr eprint arXiv:1803.10459 , 2018. [ He et al. , 2015 ] S. He, K. Liu, G. Ji, and J. Zhao. Learning to repre- sent knowledge graphs with gaussian embedding. In Proceedings of the 24th ACM International on Confer ence on Information and Knowledge Manag ement , CIKM ’15, pages 623–632, Ne w Y ork, NY , USA, 2015. ACM. [ Kapoor et al. , 2007 ] A. Kapoor, K. Grauman, R. Urtasun, and T . Darrell. Active learning with gaussian processes for object cate- gorization. In IEEE 11th International Conference on Computer V ision, ICCV 2007 , pages 1–8. IEEE Computer Society , 2007. [ Kingma and W elling, 2013a ] D. P . Kingma and M. W elling. Auto- Encoding V ariational Bayes. UvA , pages 1–14, 2013. [ Kingma and W elling, 2013b ] D. P . Kingma and M. W elling. Auto- encoding variational bayes. CoRR , abs/1312.6114, 2013. [ Kipf and W elling, 2016 ] T . N. Kipf and M. W elling. V ariational graph auto-encoders. arXiv preprint , 2016. [ Liu et al. , 2018 ] Q. Liu, M. Allamanis, M. Brockschmidt, and A. L. Gaunt. Constrained graph v ariational autoencoders for molecule design. arXiv preprint , 2018. [ Miao et al. , 2016 ] Y . Miao, L. Y u, and P . Blunsom. Neural v ari- ational inference for text processing. Pr oceedings of the 33r d International Confer ence on Machine Learning , 2016. [ Miao et al. , 2017 ] Y . Miao, E. Grefenstette, and P . Blunsom. Dis- cov ering Discrete Latent T opics with Neural V ariational Inference. ArXiv e-prints , June 2017. [ Ng and Jordan, 2001 ] A. Y . Ng and M. I. Jordan. On discriminativ e vs. generativ e classifiers: A comparison of logistic regression and naiv e bayes. In T . G. Dietterich and others, editors, Advances in Neural Information Pr ocessing Systems 14 [Neur al Information Pr ocessing Systems: Natural and Synthetic, NIPS 2001] , pages 841–848. MIT Press, 2001. [ Nickel et al. , 2016 ] M. Nickel, K. Murphy , V . T resp, and E. Gabrilovich. A revie w of relational machine learning for knowl- edge graphs. Proceedings of the IEEE , 104(1):11–33, 2016. [ Rendle et al. , 2009 ] S. Rendle, C. Freudenthaler, Z. Gantner , and L. Schmidt-Thieme. BPR: bayesian personalized ranking from implicit feedback. In J. A. Bilmes and others, editors, U AI 2009, Pr oceedings of the T wenty-Fifth Conference on Uncertainty in Artificial Intelligence , pages 452–461. A U AI Press, 2009. [ Riedel et al. , 2013 ] S. Riedel, L. Y ao, A. McCallum, and B. M. Marlin. Relation extraction with matrix factorization and uni ver- sal schemas. In L. V anderwende and othersSS, editors, Human Language T echnolo gies: Confer ence of the North American Chap- ter of the Association of Computational Linguistics , pages 74–84. The Association for Computational Linguistics, 2013. [ Salehi et al. , 2018 ] F . Salehi, R. Bamler , and S. Mandt. Probabilis- tic knowledge graph embeddings. 2018. [ Simonovsk y and K omodakis, 2018 ] M. Simonovsky and N. Ko- modakis. Graphvae: T o wards generation of small graphs using variational autoencoders. arXiv preprint , 2018. [ T rouillon et al. , 2016 ] T . Trouillon, J. W elbl, S. Riedel, É. Gaussier , and G. Bouchard. Complex embeddings for simple link predic- tion. In M. Balcan and others, editors, Pr oceedings of the 33nd International Confer ence on Machine Learning, ICML 2016 , v ol- ume 48 of JMLR W orkshop and Confer ence Pr oceedings , pages 2071–2080. JMLR.org, 2016. [ V ilnis and McCallum, 2014 ] L. V ilnis and A. McCallum. W ord representations via gaussian embedding. CoRR , abs/1412.6623, 2014. [ Vylomov a et al. , 2016 ] E. Vylomova, L. Rimell, T . Cohn, and T . Baldwin. T ake and T ook, Gaggle and Goose, Book and Read: Evaluating the Utility of V ector Differences for Le xical Relation Learning. In ACL , 2016. [ Xiao et al. , 2016 ] H. Xiao, M. Huang, and X. Zhu. Transg : A generativ e model for kno wledge graph embedding. In A CL , 2016. [ Y ang et al. , 2015 ] B. Y ang, W . Y ih, X. He, J. Gao, and L. Deng. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In ICLR , 2015. [ Zhang et al. , 2014 ] J. Zhang, J. Salwen, M. Glass, and A. Gliozzo. W ord semantic representations using bayesian probabilistic tensor factorization. Pr oceedings of the 2014 Confer ence on Empirical Methods in Natural Languag e Pr ocessing (EMNLP) , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment