다국어 음성 합성 및 교차 언어 음성 클로닝
본 논문은 Tacotron 기반의 다중 화자·다국어 TTS 모델을 제안한다. phoneme 입력을 사용해 언어 간 모델 용량을 공유하고, 스피커‑언어 상관관계를 해소하기 위해 텍스트 인코더에 스피커‑adversarial 손실을 적용한다. 다수 화자를 각 언어에 배치하고 residual VAE‑style 인코더를 추가해 학습 안정성을 높였다. 실험 결과, 영어 화자의 목소리를 스페인어·중국어 텍스트에 자연스럽게 적용할 수 있음을 보이며, 음성 품…
저자: Yu Zhang, Ron J. Weiss, Heiga Zen
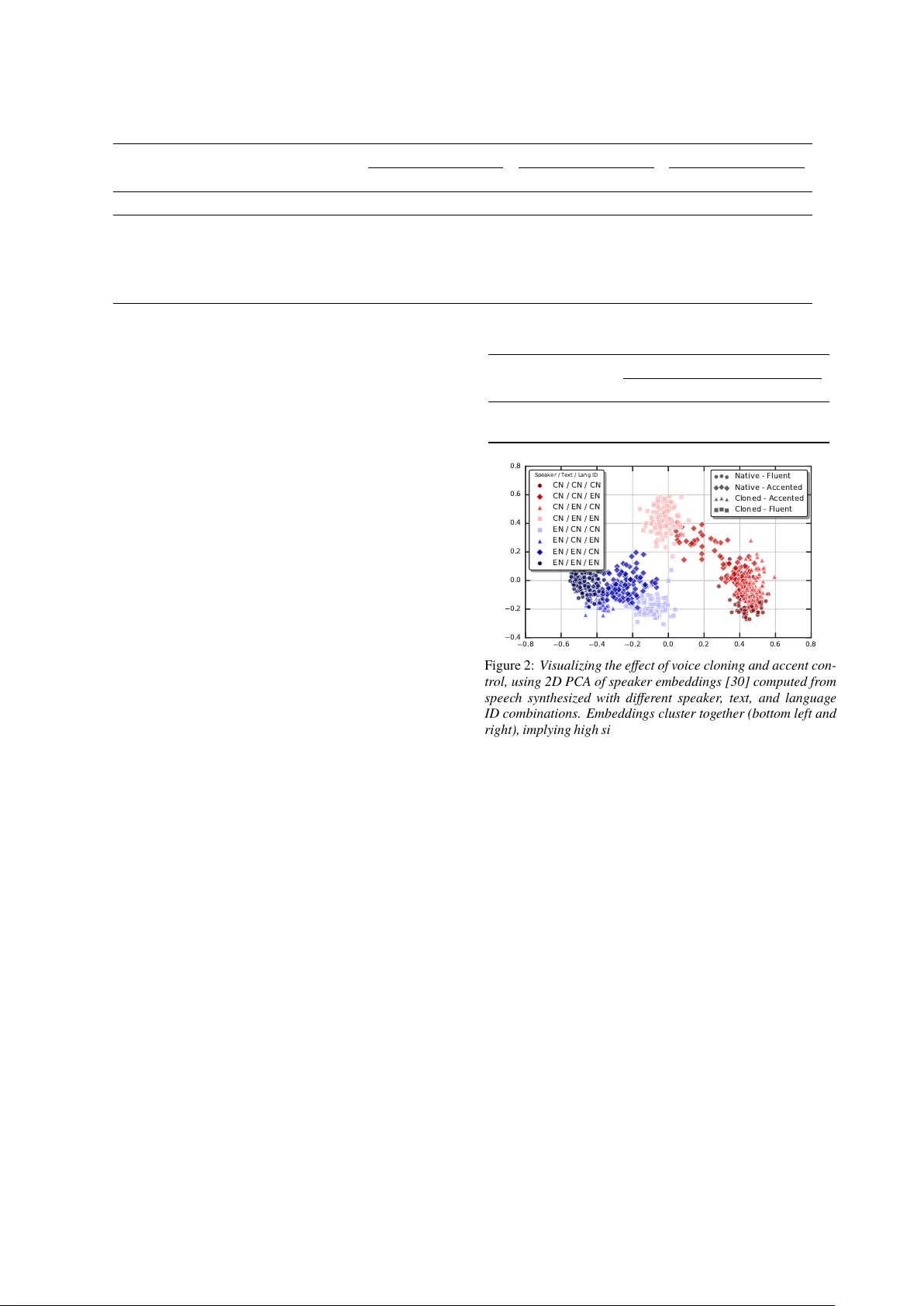
본 논문은 Tacotron‑2 기반의 다중 화자·다국어 텍스트‑투‑스피치(TTS) 모델을 설계하고, 화자와 언어가 완전히 결합된 데이터 환경에서도 화자‑언어 분리를 달성하는 방법을 제시한다. 서론에서는 기존 end‑to‑end TTS가 문자 혹은 phoneme 입력을 사용해 단일 언어에 최적화돼 왔으며, 다국어 확장은 문자 집합이 급증하거나 언어‑특정 발음 규칙을 학습해야 하는 어려움을 강조한다. 특히, 각 언어마다 화자가 하나씩만 존재하는 경우 스피커와 언어가 1:1로 매핑돼 교차 언어 음성 클로닝이 거의 불가능하다는 점을 문제점으로 제시한다.
관련 연구에서는 HMM 기반 화자‑언어 팩터화, 다국어 파라메트릭 TTS, 언어‑특정 인코더와 fine‑tuning을 통한 클로닝 등이 소개되지만, 이들 모두 다수 화자를 활용하거나 별도 언어 인코더가 필요했다. 본 연구는 이러한 제약을 없애고, 단일 모델에 모든 언어와 화자를 동시에 학습한다는 점에서 차별성을 가진다.
모델 구조는 크게 네 부분으로 구성된다. 첫째, 입력 표현으로 문자, UTF‑8 바이트, phoneme 세 가지를 비교한다. 실험 결과, phoneme 입력이 88개의 공통 토큰으로 가장 효율적인 공유를 가능하게 하며, 특히 중국어의 성조를 별도 임베딩으로 처리해 발음 정확도를 높였다. 둘째, 기본 Tacotron‑2 encoder‑decoder에 화자 임베딩(64‑dim)과 언어 임베딩(3‑dim)을 concat하여 디코더에 전달한다. 셋째, 텍스트 인코더 출력에 스피커‑adversarial 손실을 적용한다. Gradient Reversal Layer와 스피커 분류기를 사용해 텍스트 표현이 스피커 정보를 포함하지 않도록 학습한다. 이때 λ=0.5로 그래디언트를 클리핑해 언어‑특정 토큰이 과도하게 영향을 미치는 것을 방지한다. 넷째, residual VAE‑style 인코더를 도입해 mel‑spectrogram에서 16‑dim 잠재 변수를 추출한다. 학습 시 posterior를 디코더에 조건으로 넣고, 추론 시 평균값(0)을 사용해 불필요한 변동성을 억제한다.
학습 데이터는 영어 385시간(84명), 스페인어 97시간(3명), 중국어 68시간(5명)으로 구성된 고품질 음성 코퍼스를 사용했다. 모델은 배치 256, Adam(1e‑3)으로 200k 스텝까지 학습했으며, 학습 중에 학습률을 12.5k 스텝마다 절반씩 감소시켰다. WaveRNN vocoder를 별도로 학습해 24kHz 16‑bit 오디오를 생성한다.
평가에서는 두 가지 MOS 실험을 진행한다. 첫째, 자연스러움 MOS는 1~5 점 척도로 청취자를 6명씩 배정해 100개의 샘플을 평가했다. 둘째, 화자 유사도 MOS는 합성 음성과 동일 화자의 실제 음성을 쌍으로 제시하고, 언어가 다를 경우에도 화자 정체성을 얼마나 유지하는지를 측정했다. 결과는 다음과 같다.
1) 입력 표현 비교: monolingual 모델에서 phoneme 입력이 가장 높은 자연스러움(MOS 4.59~4.39)과 일관된 품질을 보였으며, 다국어 모델에서도 phoneme 기반이 char·byte 대비 약 0.2~0.3점 높은 점수를 기록했다. 특히 중국어는 char·byte가 OOV 문제로 성능이 급락했지만 phoneme은 톤 임베딩 덕분에 안정적인 결과를 냈다.
2) 스피커‑adversarial 효과: adversarial 손실을 적용하면 텍스트 인코더가 스피커 정보를 최소화해 교차 언어 클로닝 시 자연스러움이 약간 감소하더라도 화자 유사도가 크게 향상된다. 예를 들어, EN→ES 클로닝에서 phoneme+adversarial 모델은 유사도 MOS 4.23점을 달성했으며, adversarial 없이 동일 입력은 3.96점에 머물렀다.
3) 교차 언어 클로닝: 다중 화자·다국어 모델에서 EN 화자 임베딩을 ES·CN 텍스트에 적용했을 때, phoneme+adversarial 조합이 가장 성공적이었다. EN→ES는 자연스러움 MOS 4.37, 유사도 4.63을 기록했으며, EN→CN은 자연스러움 4.49, 유사도 2.46으로 억양 차이가 크게 작용했음을 보여준다. 이는 언어별 억양 특성이 완전히 disentangle되지 않았음을 의미한다.
4) 다중 화자 확장: 각 언어당 화자를 다수 배치(EN 84명, ES 3명, CN 5명)한 모델은 단일 화자 모델과 비교해 자연스러움에서 큰 차이가 없으며, 화자 다양성이 증가해 언어 임베딩만으로 억양을 조절할 수 있는 가능성을 시사한다.
결론적으로, 본 연구는 (i) phoneme 기반 입력이 다국어 TTS에서 가장 효율적인 공통 표현임을, (ii) 텍스트 인코더에 스피커‑adversarial 손실을 적용해 화자와 언어를 효과적으로 disentangle 할 수 있음을, (iii) residual VAE 인코더가 학습 안정성과 품질 향상에 기여함을 입증한다. 한계점으로는 억양·강세 제어가 완전하지 않아 언어별 억양이 화자 유사도에 영향을 미치는 점, 그리고 저자원 언어에 대한 확장성 검증이 부족한 점을 들 수 있다. 향후 연구에서는 언어‑특정 억양 컨트롤 모듈과 더 많은 저자원 언어 데이터를 활용해 모델의 일반화 능력을 강화할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기