Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent …
Authors: Yu Zhang, Ron J. Weiss, Heiga Zen
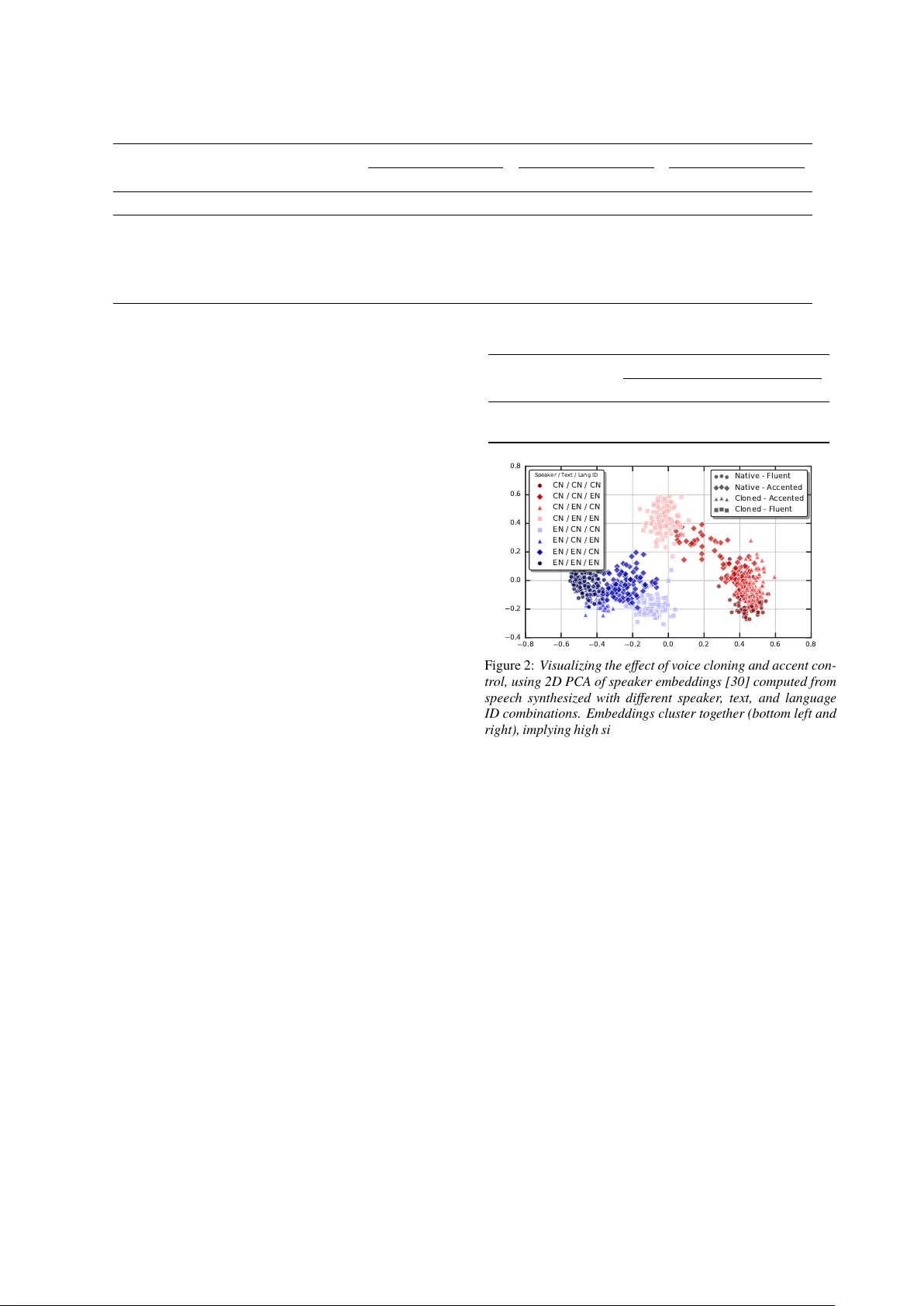
Learning to Speak Fluentl y in a F oreign Languag e: Multilingual Speech Synthesis and Cr oss-Languag e V oice Cloning Y u Zhang, R on J. W eiss, Heig a Zen, Y onghui W u, Zhif eng Chen, RJ Skerr y-Ryan, Y e Jia, Andr ew Rosenber g, Bhuvana Ramabhadr an Google {ngyuzh, ronw}@google.com Abstract W e present a multispeaker , multilingual te xt-to-speech (TTS) synthesis model based on T acotron that is able to produce high quality speech in multiple languages. Moreo ver , the model is able to transfer v oices across languages, e.g. synthesize fluent Spanish speec h using an English speaker ’ s voice, without train- ing on an y bilingual or parallel e xamples. Such transf er works across distantl y related languages, e.g. English and Mandar in. Critical to achie ving this result are: 1. using a phonemic in- put representation to encourage sharing of model capacity across languages, and 2. incor porating an adv ersar ial loss ter m to en- courage the model to disentangle its representation of speaker identity (which is per fectl y cor related with language in the train- ing data) from the speech content. F ur ther scaling up the model b y training on multiple speakers of each language, and incor po- rating an autoencoding input to help stabilize attention dur ing training, results in a model which can be used to consistentl y synthesize intelligible speech f or training speakers in all lan- guages seen during training, and in nativ e or foreign accents. Index T erms : speech synthesis, end-to-end, adv ersar ial loss 1. Introduction Recent end-to-end neural TTS models [1–3] hav e been e xtended to enable control of speaker identity [4–7] as well as unlabelled speech attributes, e.g. prosody , by conditioning synthesis on la- tent representations [8–12] in addition to te xt. Extending such models to suppor t multiple, unrelated languages is nontr ivial when using language-dependent input representations or model components, especially when the amount of training data per lan- guage is imbalanced. For e xample, there is no ov erlap in the te xt representation between languages like Mandarin and English. Further more, recordings from bilingual speak ers are expensiv e to collect. It is therefore most common for each speaker in the training set to speak only one language, so speaker identity is perfectl y correlated with language. This makes it difficult to transf er v oices across different languages, a desirable feature when the number of a vailable training voices for a particular language is small. Moreov er , for languages with bor ro w ed or shared w ords, such as proper nouns in Spanish (ES) and English (EN), pronunciations of the same te xt might be different. This adds more ambiguity when a naiv ely trained model sometimes generates accented speech f or a par ticular speaker . Zen et al. proposed a speaker and languag e factorization f or HMM-based parametric TTS sy stem [13], aiming to transfer a v oice from one languag e to others. [14] proposed a multilingual parametric neural TTS system, which used a unified input repre- sentation and shared parameters across languages, ho we ver the v oices used for each language w ere disjoint. [15] descr ibed a sim- ilar bilingual Chinese and English neural TTS system trained on speech from a bilingual speaker , allo wing it to synthesize speech Adversarial Loss Mel spectrogram T ext sequence Residual Encoding T ext Encoding Decoder Mel spectrogram Inference Network Speaker Embedding Language Embedding Speaker Classifier Gradient Reversal Synthesizer T ext Encoder Residual Encoder Figure 1: Ov er view of the components of the pr oposed model. Dashed lines denote sampling via repar ameterization [21] dur - ing training. The prior mean is always use during infer ence. in both languages using the same voice. [16] studied lear ning pronunciation from a bilingual TTS model. Most recently , [17] presented a multilingual neural TTS model which supports voice cloning across English, Spanish, and Ger man. It used language- specific text and speaker encoders, and incor porated a secondar y fine-tuning step to optimize a speak er identity -preserving loss, ensuring that the model could output a consistent voice regard- less of languag e. W e also note that the sound quality is not on par with recent neural TTS sys tems, potentially because of its use of the W ORLD vocoder [18] f or wa vef or m synthesis. Our w ork is most similar to [19], which descr ibes a mul- tilingual TTS model based on T acotron 2 [20] which uses a U nicode encoding “b yte” input representation to train a model on one speaker of each of English, Spanish, and Mandarin. In this paper, we ev aluate different input representations, scale up the number of training speakers f or each languag e, and extend the model to suppor t cross-lingual voice cloning. The model is trained in a single stag e, with no language-specific compo- nents, and obtains naturalness on par with baseline monolingual models. Our contr ibutions include: (1) Evaluating the effect of using different te xt input representations in a multilingual TTS model. (2) Introducing a per -input token speaker -adversarial loss to enable cross-lingual v oice transfer when onl y one train- ing speaker is av ailable for each language. (3) Incor porating an e xplicit language embedding to the input, which enables mod- erate control of speech accent, independent of speaker identity , when the training data contains multiple speakers per languag e. W e e valuate the contr ibution of eac h component, and demonstrate the proposed model’ s ability to disentangle speak - ers from languages and consis tently synthesize high quality speech f or all speakers, despite the per f ect cor relation to the original language in the training data. 2. Model Structure W e base our multilingual TTS model on T acotron 2 [20], which uses an attention-based sequence-to-sequence model to gener - ate a sequence of log-mel spectrogram frames based on an input te xt sequence. The architecture is illustrated in Figure 1. It augments the base T acotron 2 model with additional speaker and, optionally , language embedding inputs (bottom right), an adv ersar ially -trained speaker classifier (top right), and a varia- tional autoencoder -sty le residual encoder (top left) which con- ditions the decoder on a latent embedding computed from the targ et spectrog ram during training (top left). F inally , similar to T acotron 2, w e separately train a W a v eRNN [22] neural vocoder . 2.1. In put representations End-to-end TTS models hav e typically used character [2] or phoneme [8, 23] input representations, or hybrids between them [24, 25]. Recently , [19] proposed using inputs derived from the UTF-8 byte encoding in multilingual settings. W e ev aluate the effects of using these representations for multilingual TTS. 2.1.1. Char acters / Graphemes Embeddings cor responding to each character or g rapheme are the default inputs f or end-to-end TTS models [2, 20, 23], requir - ing the model to implicitly learn how to pronounce input words (i.e. grapheme-to-phoneme conv ersion [26]) as par t of the syn- thesis task. Extending a g rapheme-based input v ocabular y to a multilingual setting is straightf orward, by simply concatenating grapheme sets in the training cor pus for each language. This can grow quickl y for languages with large alphabets, e.g. our Man- darin vocabulary contains o v er 4.5k tokens. W e simply concate- nate all g raphemes appear ing in the training cor pus, leading to a total of 4,619 tok ens. Equivalent graphemes are shared across languages. During inference all previously unseen characters are mapped to a special out-of-vocabulary (OO V) symbol. 2.1.2. UTF -8 Encoded Bytes Follo wing [19] we e xperiment with an input representation based on the UTF-8 text encoding, which uses 256 possible values as each input token where the mapping from graphemes to bytes is language-dependent. For languages with single-byte characters (e.g., English), this representation is equivalent to the grapheme representation. Ho we v er, for languages with multi-byte char - acters (such as Mandarin) the TTS model must lear n to attend to a consistent sequence of bytes to cor rectly generate the cor - responding speech. On the other hand, using a UTF-8 byte representation ma y promote shar ing of representations between languages due to the smaller number of input tokens. 2.1.3. Phonemes Using phoneme inputs simplifies the TTS task, as the model no longer needs to lear n complicated pronunciation r ules f or lan- guages such as English. Similar to our grapheme-based model, equiv alent phonemes are shared across languages. W e concate- nate all possible phoneme symbols, for a total of 88 tokens. T o suppor t Mandar in, we include tone inf ormation by lear n- ing phoneme-independent embeddings for each of the 4 possible tones, and broadcast each tone embedding to all phoneme em- beddings inside the corresponding syllable. For English and Spanish, tone embeddings are replaced b y stress embeddings which include primar y and secondar y stresses. A special sym- bol is used when there is no tone or stress. 2.2. R esidual encoder Follo wing [12], we augment the TTS model by incor porating a variational autoencoder -like residual encoder which encodes the latent factors in the training audio, e.g. prosody or background noise, which is not well-e xplained by the conditioning inputs: the text representation, speaker , and language embeddings. W e f ollow the structure from [12], e xcept we use a standard single Gaussian prior distribution and reduce the latent dimension to 16 . In our e xper iments, we obser v e that feeding in the pr ior mean (all zeros) during inference, significantly improv es stability of cross-lingual speaker transfer and leads to improv ed naturalness as shown by MOS ev aluations in Section 3.4. 2.3. A dversarial training One of the challenges f or multilingual TTS is data sparsity , where some languages ma y only hav e training data for a f ew speakers. In the extreme case where there is only one speaker per language in the training data, the speaker identity is essentially the same as the language ID. T o encourage the model to learn disentangled representations of the text and speak er identity , we proactivel y discourage the text encoding t s from also capturing speaker inf or mation. W e emplo y domain adversarial training [27] to encourage t i to encode te xt in a speaker -independent manner b y introducing a speaker classifier based on the text encoding and a g radient rev ersal lay er . Note that the speaker classifier is optimized with a different objective than the rest of the model: L speaker ( ψ s ; t i ) = Í N i log p ( s i | t i ) , where s i is the speaker label and ψ s are the parameters f or speaker classifier . T o train the full model, w e insert a gradient re versal lay er [27] prior to this speaker classifier, whic h scales the g radient b y − λ . Follo wing [28], we also explore inser ting another adv ersarial la yer on top of the variational autoencoder to encourage it to lear n speak er- independent representations. How ev er, we f ound that this la y er has no effect after decreasing the latent space dimension. W e impose this adv ersar ial loss separately on each element of the encoded text sequence, in order to encourag e the model to lear n a speaker - and language-independent te xt embedding space. In contrast to [28], which disentangled speaker identity from back g round noise, some input tokens are highly language- dependent which can lead to unstable adversarial classifier gra- dients. W e address this by clipping gradients computed at the rev ersal lay er to limit the impact of such outliers. 3. Experiments W e train models using a proprietar y dataset composed of high quality speech in three languages: (1) 385 hours of English (EN) from 84 professional voice actors with accents from the United States, Great Britain, A ustralia, and Singapore; (2) 97 hours of Spanish (ES) from 3 f emale speakers include Cas tilian and US Spanish; (3) 68 hours of Mandar in (CN) from 5 speakers. 3.1. Model and training setup The synthesizer network uses the T acotron 2 architecture [20], with additional inputs consisting of lear ned speaker (64-dim) and language embeddings (3-dim), concatenated and passed to the decoder at each step. The generated speech is represented as a sequence of 128-dim log-mel spectrogram frames, computed from 50ms window s shifted by 12.5ms. The variational residual encoder architecture closely fol- lo ws the attr ibute encoder in [12]. It maps a variable length mel spectrog ram to two vectors parameter izing the mean and log v ar iance of the Gaussian posterior . The speaker classifiers are fully -connected netw orks with one 256 unit hidden la yer f ollow ed b y a softmax predicting the speaker identity . The syn- thesizer and speaker classifier are trained with weight 1 . 0 and 0 . 02 respectivel y . As described in the previous section w e appl y T able 1: Speaker similarity Mean Opinion Score (MOS) com- paring ground truth audio from speakers of different languag es. Rater s are nativ e speakers of the targ et languag e. Source Language T arget Language EN ES CN EN 4.40 ± 0.07 1.72 ± 0.15 1.80 ± 0.08 ES 1.49 ± 0.06 4.39 ± 0.06 2.14 ± 0.09 CN 1.32 ± 0.06 2.06 ± 0.09 3.51 ± 0.12 gradient clipping with factor 0 . 5 to the gradient rev ersal lay er . The entire model is trained jointly with a batch size of 256, using the Adam optimizer configured with an initial learning rate of 10 − 3 , and an exponential decay that halv es the learning rate ev er y 12.5k steps, star ting at 50k steps. W av ef or ms are synthesized using a W av eRNN [22] v ocoder which g enerates 16-bit signals sampled at 24 kHz conditioned on spectrog rams predicted by the TTS model. W e synthesize 100 samples per model, and hav e each one rated by 6 raters. 3.2. Ev aluation T o evaluate synthesized speech, we rely on crowdsourced Mean Opinion Score (MOS) ev aluations of speech naturalness via subjectiv e listening tests. Ratings f ollo w the Absolute Categor y Rating scale, with scores from 1 to 5 in 0.5 point increments. For cross-language voice cloning, we also ev aluate whether the synthesized speech resembles the identity of the reference speaker by pairing each synthesized utterance with a ref erence utterance from the same speaker f or subjective MOS e valuation of speaker similarity , as in [5]. Although rater instructions e xplicitly ask ed f or the content to be ignored, note that this similarity ev aluation is more challenging than the one in [5] because the reference and targ et e xamples are spoken in different languages, and raters are not bilingual. W e found that low fidelity audio tended to result in high variance similar ity MOS so we alw ay s use W av eRNN outputs. 1 For each language, we chose one speaker to use f or similarity tests. As shown in T able 1, the EN speaker is f ound to be dissimilar to the ES and CN speakers (MOS belo w 2.0), while the ES and CN speakers are slightly similar (MOS around 2.0). The CN speaker has more natural variability compared to EN and ES, leading to a lo wer self similar ity . The scores are consistent when EN and CN raters ev aluate the same EN and CN test set. The observation is consistent with [29]: raters are able to discriminate between speakers across languages. Ho we v er , when rating synthetic speech, we obser v ed that English speaking raters often considered “heavy accented” synthetic CN speech to sound more similar to the target EN speaker , compared to more fluent speech from the same speaker . This indicates that accent and speaker identity are not full y disentangled. W e encourage readers to listen to samples on the companion webpag e. 2 3.3. Com paring input representations W e first build and ev aluate models comparing the per formance of different te xt input representations. For all three languages, b yte-based models alw ay s use a 256-dim softmax output. Mono- lingual character and phoneme models each use a different input 1 Some raters ga ve lo w fidelity audio low er scores, treating "blur ri- ness" as a proper ty of the speaker . Others ga ve higher scores because they recognized such audio as synthetic and had low er e xpectations. 2 http://google.github.io/tacotron/publications/multilingual T able 2: Natur alness MOS of monolingual and multilingual models synthesizing speech of in different languag es. Language Model Input EN ES CN Ground tr uth 4.60 ± 0.05 4.37 ± 0.06 4.42 ± 0.06 Monolingual char 4.24 ± 0.12 4.21 ± 0.11 3.48 ± 0.11 phone 4.59 ± 0.06 4.39 ± 0.04 4.16 ± 0.08 Multilingual b yte 4.23 ± 0.14 4.23 ± 0.10 3.42 ± 0.12 1EN 1ES 1CN c har 3.94 ± 0.15 4.33 ± 0.09 3.63 ± 0.10 phone 4.34 ± 0.09 4.41 ± 0.05 4.06 ± 0.10 Multilingual b yte 4.11 ± 0.14 4.21 ± 0.12 3.67 ± 0.12 84EN 3ES 5CN char 4.26 ± 0.13 4.23 ± 0.11 3.46 ± 0.11 phone 4.37 ± 0.12 4.37 ± 0.04 4.09 ± 0.10 T able 3: Naturalness and speaker similarity MOS of cr oss- languag e voice cloning of an EN source speaker . Models which use differ ent input r epresentations are compared, with and with- out the speaker -adversarial loss. fail: rater s complained that too many utter ances wer e spoken in the wrong languag e. ES targ et CN targ et Input Naturalness Similarity Naturalness Similarity char 2.62 ± 0.10 4.25 ± 0.09 N/A N/A b yte 2.62 ± 0.15 3.96 ± 0.10 N/A N/A with adversarial loss b yte 2.34 ± 0.10 4.23 ± 0.09 fail 3.85 ± 0.11 phone 3.20 ± 0.09 4.15 ± 0.10 2.75 ± 0.12 3.60 ± 0.09 v ocabular y corresponding to the training language. T able 2 compares monolingual and multilingual model per - f or mance using different input representations. For Mandarin, the phoneme-based model perf orms significantl y better than char - or byte-based variants due to rare and OO V w ords. Com- pared to the monolingual system, multilingual phoneme-based sys tems hav e similar per f ormance on ES and CN but are slightly w orse on EN. CN has a larg er gap to ground truth (top) due to unseen word segmentation (f or simplicity , we didn ’t add w ord boundary during training). The multispeaker model (bottom) performs about the same as the single speak er per -language variant (middle). Overall, when using phoneme inputs all the languages obtain MOS scores abov e 4.0. 3.4. Cr oss-language v oice cloning W e ev aluate how w ell the multispeaker models can be used to clone a speaker’ s v oice into a new language by simply passing in speaker embeddings cor responding to a different language from the input te xt. T able 3 sho ws voice cloning per f or mance from an EN speak er in the most data-poor scenar io (129 hours), where only a single speaker is av ailable for each training languag e (1EN 1ES 1CN) without using the speaker -adversarial loss. Us- ing byte inputs 3 it was possible to clone the EN speaker to ES with high similar ity MOS, albeit with significantly reduced naturalness. Ho wev er, cloning the EN voice to CN failed 4 , as did cloning to ES and CN using phoneme inputs. 3 Using character or byte inputs led to similar results. 4 W e didn ’ t run listening tests because it was clear that synthesizing EN text using the CN speaker embedding didn ’t affect the model output. T able 4: Naturalness and speaker similarity MOS of cross-languag e voice cloning of the full multilingual model using phoneme inputs. Source Language EN targ et ES targ et CN targ et Model Naturalness Similarity Naturalness Similarity N aturalness Similarity - Ground tr uth (self-similar ity) 4.60 ± 0.05 4.40 ± 0.07 4.37 ± 0.06 4.39 ± 0.06 4.42 ± 0.06 3.51 ± 0.12 EN 84EN 3ES 5CN 4.37 ± 0.12 4.63 ± 0.06 4.20 ± 0.07 3.50 ± 0.12 3.94 ± 0.09 3.03 ± 0.10 language ID fixed to EN - - 3.68 ± 0.07 4.06 ± 0.09 3.09 ± 0.09 3.20 ± 0.09 ES 84EN 3ES 5CN 4.28 ± 0.10 3.24 ± 0.09 4.37 ± 0.04 4.01 ± 0.07 3.85 ± 0.09 2.93 ± 0.12 CN 84EN 3ES 5CN 4.49 ± 0.08 2.46 ± 0.10 4.56 ± 0.08 2.48 ± 0.09 4.09 ± 0.10 3.45 ± 0.12 A dding the adv ersar ial speaker classifier enabled cross- language cloning of the EN speaker to CN with very high simi- larity MOS f or both byte and phoneme models. Ho we v er, natu- ralness MOS remains much low er than using the nativ e speaker identity , with the naturalness listening test failing entirely in the CN case with byte inputs as a result of rater comments that the speech sounded lik e a foreign language. According to rater comments on the phoneme system, most of the degradation came from mismatched accent and pronunciation, not fidelity . CN raters commented that it sounded like “a foreigner speaking Chinese ”. More interestingly , fe w ES raters commented that “The voice does not sound robotic but instead sounds like an English nativ e speaker who is lear ning to pronounce the words in Spanish. ” Based on these results, w e only use phoneme inputs in the f ollowing experiments since this guarantees that pronun- ciations are cor rect and results in more fluent speech. T able 4 evaluates v oice cloning performance of the full mul- tilingual model (84EN 3ES 5CN), which is trained on the full dataset with increased speaker co verag e, and uses the speaker - adv ersar ial loss and speaker/languag e embeddings. Incorporat- ing the adv ersar ial loss f orces the text representation to be less language-specific, instead relying on the language embedding to capture language-dependent information. Across all language pairs, the model synthesizes speech in all voices with natural- ness MOS abov e 3.85, demonstrating that increasing training speaker div ersity improv es generalization. In most cases syn- thesizing EN and ES speech (ex cept EN-to-ES) approaches the ground tr uth scores. In contrast, naturalness of CN speech is consistentl y lo wer than the ground tr uth. The high naturalness and similar ity MOS scores in the top ro w of T able 4 indicate that the model is able to successfully transf er the EN v oice to both ES and CN almost without accent. When consistently conditioning on the EN language embedding regardless of the targ et language (second row), the model pro- duces more English accented ES and CN speech, which leads to lo wer naturalness but higher similar ity MOS scores. Also see Figure 2 and the demo f or accent transfer audio ex amples. W e see that cloning the CN voice to other languages (bottom ro w) has the lo wes t similar ity MOS, although the scores are still much higher than different-speaker similar ity MOS in the off- diagonals of T able 1 indicating that there is some degree of transf er. This is a consequence of the lo w speak er cov erage of CN compared to EN in the training data, as well as the larg e distance betw een CN and other languages. Finall y , T able 5 demonstrates the importance of training us- ing a variational residual encoder to stabilize the model output. Naturalness MOS decreases by 0.4 points for EN-to-CN cloning without the residual encoder (bottom ro w). In informal compar - isons of the outputs of the two models we find that the model without the residual encoder tends to skip rare words or inser ts T able 5: Effect of EN speaker cloning with no residual encoder . T arget Language Model EN ES CN 84EN 3ES 5CN 4.37 ± 0.12 4.20 ± 0.07 3.94 ± 0.09 - residual encoder 4.38 ± 0.10 4.11 ± 0.06 3.52 ± 0.11 0.8 0.6 0.4 0.2 0.0 0.2 0.4 0.6 0.8 0.4 0.2 0.0 0.2 0.4 0.6 0.8 Native - Fluent Native - Accented Cloned - Accented Cloned - Fluent Speaker / Text / Lang ID CN / CN / CN CN / CN / EN CN / EN / CN CN / EN / EN EN / CN / CN EN / CN / EN EN / EN / CN EN / EN / EN Figure 2: Visualizing the effect of voice cloning and accent con- trol, using 2D PCA of speaker embeddings [30] computed from speec h synthesized with different speaker , text, and languag e ID combinations. Embeddings cluster tog ether (bottom left and right), implying high similarity, when the speaker’ s original lan- guag e matches the languag e embedding, reg ardless of the text languag e. Howev er , using languag e ID from the text (squares), modifying the speaker’ s accent to speak fluently, hur ts similarity compar ed to the native languag e and accent (circles). unnatural pauses in the output speech. This indicates the V AE prior learns a mode which helps stabilize attention. 4. Conclusions W e descr ibe extensions to the T acotron 2 neural TTS model which allow training of a multilingual model trained only on monolingual speakers, which is able to synthesize high quality speech in three languages, and transfer training voices across languages. Fur thermore, the model lear ns to speak f oreign lan- guages with moderate control of accent, and, as demonstrated on the companion webpag e, has r udimentar y suppor t for code switching. In future w ork we plan to inv estig ate methods f or scaling up to le verag e larg e amounts of lo w quality training data, and suppor t man y more speakers and languages. 5. A ckno wledgements W e thank Ami Patel, Amanda Ritchart-Scott, Ry an Li, Siamak T azar i, Y utian Chen, Paul McCar tney , Er ic Battenberg, T oby Ha wker , and Rob Clark f or discussions and helpful feedbac k. 6. Ref erences [1] A. van den Oord, S. Dieleman, H. Zen, K. Simon yan, O. Vin yals, A. Grav es, N. Kalchbrenner , A. Senior, and K. Kavukcuoglu, “W av eNet: A generative model for raw audio, ” CoRR abs/1609.03499 , 2016. [2] Y . W ang, R. Skerr y-R yan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio et al. , “ T acotron: A full y end-to-end text-to-speec h synthesis model, ” arXiv preprint , 2017. [3] S. Arik, G. Diamos, A. Gibiansky , J. Miller , K. Peng, W . Ping, J. Raiman, and Y . Zhou, “Deep V oice 2: Multi-speaker neural text- to-speech, ” in Advances in Neur al Information Pr ocessing Sys tems (NIPS) , 2017. [4] S. O. Ar ik, J. Chen, K. Peng, W . Ping, and Y . Zhou, “Neural voice cloning with a fe w samples, ” in Advances in Neur al Inf or mation Processing Sys tems , 2018. [5] Y . Jia, Y . Zhang, R. J. W eiss, Q. W ang, J. Shen, F . Ren, Z. Chen, P . Nguy en, R. Pang, I. L. Moreno, and Y . W u, “ T ransfer learn- ing from speaker verification to multispeaker text-to-speech syn- thesis, ” in Advances in Neur al Information Processing Syst ems , 2018. [6] E. Nac hmani, A. Pol yak, Y . T aigman, and L. W olf, “Fitting new speakers based on a shor t untranscribed sample, ” in International Confer ence on Machine Learning (ICML) , 2018. [7] Y . Chen, Y . Assael, B. Shillingf ord, D. Budden, S. Reed, H. Zen, Q. W ang, L. C. Cobo, A. T rask, B. Laurie et al. , “Sample efficient adaptiv e text-to-speech, ” arXiv preprint arXiv :1809.10460 , 2018. [8] Y . W ang, D. S tanton, Y . Zhang, R. Skerr y-R yan, E. Battenberg, J. Shor , Y . Xiao, F . Ren, Y . Jia, and R. A. Saurous, “Style tokens: Unsupervised style modeling, control and transf er in end-to-end speech synthesis,” in International Confer ence on Machine Learn- ing (ICML) , 2018. [9] R. Skerry-Ry an, E. Battenberg, Y . Xiao, Y . W ang, D. Stanton, J. Shor, R. J. W eiss, R. Clark, and R. A. Saurous, “T ow ards end- to-end prosody transf er for e xpressiv e speech synthesis with T aco- tron, ” in International Confer ence on Mac hine Learning (ICML) , 2018. [10] K. Akuzawa, Y . Iwasa wa, and Y . Matsuo, “Expressiv e speech synthesis via modeling expressions with variational autoencoder ,” in Interspeec h , 2018. [11] G. E. Henter, J. Lorenzo- T rueba, X. W ang, and J. Y amagishi, “Deep encoder-decoder models f or unsupervised learning of con- trollable speech synthesis, ” arXiv preprint arXiv :1807.11470 , 2018. [12] W .-N. Hsu, Y . Zhang, R. J. W eiss, H. Zen, Y . W u, Y . W ang, Y . Cao, Y . Jia, Z. Chen, J. Shen, P . Nguyen, and R. P ang, “Hierarchical generativ e modeling for controllable speech synthesis, ” in ICLR , 2019. [13] H. Zen, N. Braunschweiler , S. Buchholz, M. Gales, K. Knill, S. Krstulo vić, and J. Lator re, “Statistical parametr ic speech syn- thesis based on speaker and language factorization, ” IEEE T rans. Audio, Speech, Lang. Process. , vol. 20, no. 6, pp. 1713–1724, 2012. [14] B. Li and H. Zen, “Multi-language multi-speaker acoustic model- ing f or LSTM-RNN based statistical parametr ic speech synthesis, ” in Proc. Interspeec h , 2016, pp. 2468–2472. [15] H. Ming, Y . Lu, Z. Zhang, and M. Dong, “ A light-weight method of building an LSTM-RNN-based bilingual TTS system, ” in In- ternational Confer ence on Asian Languag e Processing , 2017, pp. 201–205. [16] Y . Lee and T . Kim, “Learning pronunciation from a f or - eign language in speec h synthesis networks, ” arXiv preprint arXiv :1811.09364 , 2018. [17] E. Nachmani and L. W olf, “Unsupervised poly glot text to speech, ” in ICASSP , 2019. [18] M. Morise, F . Y okomori, and K. Ozaw a, “WORLD: a v ocoder - based high-quality speech synthesis sys tem for real-time applica- tions, ” IEICE T ransactions on Inf or mation and Systems , vol. 99, no. 7, pp. 1877–1884, 2016. [19] B. Li, Y . Zhang, T . Sainath, Y . W u, and W . Chan, “Bytes are all you need: End-to-end multilingual speech recognition and synthesis with bytes, ” in ICASSP , 2018. [20] J. Shen, R. Pang, R. J. W eiss, M. Schuster , N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, R. Skerr y-R yan et al. , “Natural TTS synthesis by conditioning W av eNet on mel spectrog ram predic- tions, ” in ICASSP , 2018. [21] D. P . Kingma and M. W elling, “ Auto-encoding variational Bay es,” in International Confer ence on Lear ning Representations (ICLR) , 2014. [22] N. Kalchbrenner , E. Elsen, K. Simony an, S. Noury , N. Casag rande, E. Lockhar t, F . Stimberg, A. van den Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient neural audio synthesis,” in ICML , 2018. [23] J. Sotelo, S. Mehr i, K. Kumar , J. F . Santos, K. Kastner , A. Courville, and Y . Bengio, “Char2wa v: End-to-end speech syn- thesis, ” in ICLR: W orkshop , 2017. [24] W . Ping, K. Peng, A. Gibiansky , S. O. Arik, A. Kannan, S. Narang, J. Raiman, and J. Miller , “Deep V oice 3: Scaling te xt-to-speech with conv olutional sequence lear ning, ” in International Confer - ence on Learning Repr esentations (ICLR) , 2018. [25] K. Kastner , J. F. Santos, Y . Bengio, and A. C. Courville, “Repre- sentation mixing f or TTS synthesis, ” arXiv :1811.07240 , 2018. [26] A. V an Den Bosch and W . Daelemans, “Data-oriented methods f or grapheme-to-phoneme conv ersion, ” in Proc. Association for Computational Linguistics , 1993, pp. 45–53. [27] Y . Ganin, E. Ustino va, H. Ajakan, P . Germain, H. Larochelle, F . La violette, M. Marchand, and V . Lempitsky , “Domain- adv ersarial training of neural networks, ” The Journal of Machine Learning Resear ch , vol. 17, no. 1, pp. 2096–2030, 2016. [28] W .-N. Hsu, Y . Zhang, R. J. W eiss, Y . an Chung, Y . W ang, Y . W u, and J. Glass, “Disentangling cor related speak er and noise f or speech synthesis via data augmentation and adversarial factor - ization, ” in ICASSP , 2019. [29] M. W ester and H. Liang, “Cross-lingual speaker discrimination using natural and synthetic speech, ” in T welfth Annual Confer ence of the International Speech Communication Association , 2011. [30] L. W an, Q. W ang, A. Papir , and I. L. Moreno, “Generalized end- to-end loss f or speaker verification, ” in Proc. ICASSP , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment