GAN 기반 화자 적응으로 고품질 WaveNet 보코더 구현
본 논문은 기존 Parallel WaveNet의 복잡한 교사‑학생 증류 과정을 대체하고, 소량의 화자 데이터만으로도 고품질 음성을 생성할 수 있도록 GAN 기반 적응 프레임워크를 제안한다. LSGAN 손실과 로그‑스펙트럼 손실을 결합해 주파수 세부 정보를 보존하고, 실험을 통해 MOS 점수가 기존 방법보다 향상됨을 확인하였다.
저자: Qiao Tian, Xucheng Wan, Shan Liu
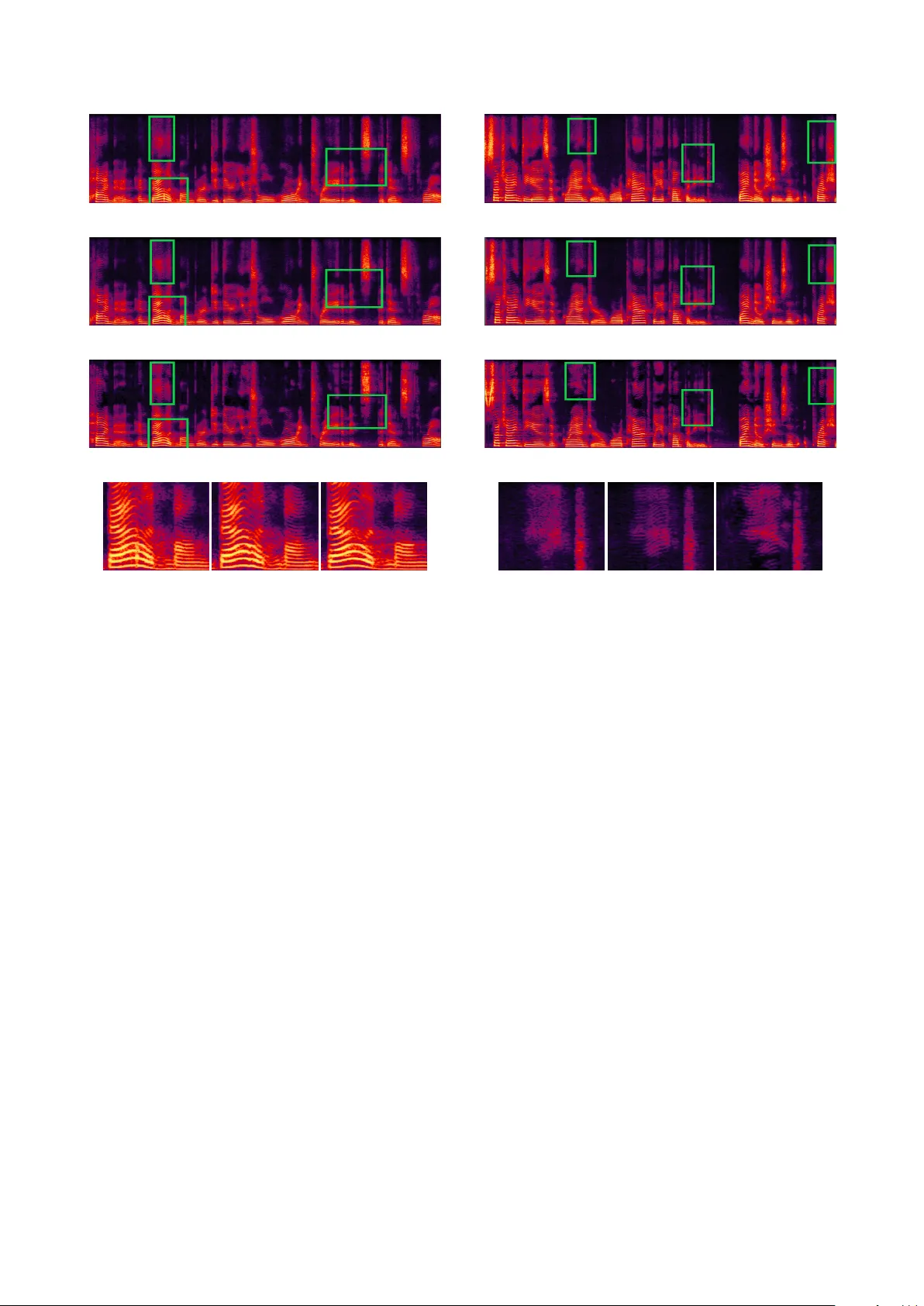
본 논문은 최신 신경 보코더인 Parallel WaveNet이 실시간 파형 생성은 가능하게 했지만, 두 가지 근본적인 한계—증류 기반 학습의 복잡성 및 생성 음성의 품질 격차—를 지적한다. 이를 해결하기 위해 저자는 GAN 기반 화자 적응 프레임워크(AGAN)를 제안한다. 기본 아이디어는 사전 학습된 Parallel WaveNet을 생성기로 사용하고, 새로운 화자 데이터에 대해 판별기를 학습시켜 생성기의 출력이 실제 음성과 구별되지 않도록 하는 것이다.
GAN은 조건부 형태(cGAN)로, 멜 스펙트로그램을 조건 입력으로 사용한다. 손실 함수는 두 부분으로 구성된다. 첫 번째는 LSGAN의 최소제곱 손실로, 판별기가 “진짜”라고 판단하도록 만든다. 두 번째는 로그‑스펙트럼 손실(L_log‑mag)이며, 이는 STFT magnitude의 로그값 차이를 L1로 최소화한다. 로그‑스펙트럼 손실은 주파수 영역에서 세밀한 스펙트럼 정보를 보존하도록 설계돼, 기존 GAN이 시간 도메인에만 집중하는 한계를 보완한다.
판별기 구조는 비인과적(dilated) 컨볼루션 10층을 사용해 샘플 수준의 구분 능력을 유지하면서도 효율성을 확보한다. 학습 초기 50k 스텝에서는 생성기 파라미터를 고정하고 판별기만 학습해 안정적인 판별 기준을 만든 뒤, 이후 100k 스텝에서 생성기와 판별기를 교대로 업데이트한다. 손실 가중치 λ는 실험적으로 1.5가 최적으로 확인되었으며, λ를 크게 낮출 경우 품질이 급격히 저하되는 것을 확인했다.
데이터는 두 단계로 나뉜다. 사전 학습 단계에서는 12시간 분량의 중국어 여성 화자 데이터를 사용해 Parallel WaveNet을 학습한다. 적응 단계에서는 공개된 LJSpeech(영어, 약 3시간) 데이터를 사용해 AGAN을 학습한다. 언어와 샘플링 레이트가 다름에도 불구하고 모델이 일반화 가능함을 보여준다.
실험 결과는 MOS 평가와 스펙트로그램 분석으로 제시된다. MOS에서는 기존 증류 기반 적응 대비 0.05점 상승(베이스라인 4.45 → AGAN 4.50)했으며, 이는 인간 청취자가 자연음에 근접한 고품질을 인지하는 데 의미가 있다. 스펙트로그램에서는 AGAN이 고주파 영역의 비자연적 라인과 손실된 조화 구조를 복원해, 원음과 거의 동일한 스펙트럼 패턴을 보여준다. 또한, 적응 시간은 기존 방법 대비 약 30% 이상 단축돼, Tesla P40 GPU에서 약 36시간 내에 완료되었다.
논문의 주요 기여는 다음과 같다. (1) 증류 없이 GAN을 이용해 효율적인 화자 적응을 구현하였다. (2) 로그‑스펙트럼 손실을 도입해 주파수 디테일을 보존함으로써 고충실도 WaveNet 보코더를 실현했다. (3) 적은 양의 데이터와 짧은 학습 시간으로도 기존 방법과 동등하거나 더 나은 품질을 달성했다.
향후 연구 과제로는 λ와 손실 구성의 최적화, 다언어·다화자 환경에서의 확장성, 실시간 인퍼런스와의 결합 가능성, 그리고 GAN 구조 자체의 안정성 향상이 있다. 이러한 방향은 신경 보코더를 실제 서비스에 적용하는 데 필수적인 요소가 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기