Generative Adversarial Network based Speaker Adaptation for High Fidelity WaveNet Vocoder
Although state-of-the-art parallel WaveNet has addressed the issue of real-time waveform generation, there remains problems. Firstly, due to the noisy input signal of the model, there is still a gap between the quality of generated and natural wavefo…
Authors: Qiao Tian, Xucheng Wan, Shan Liu
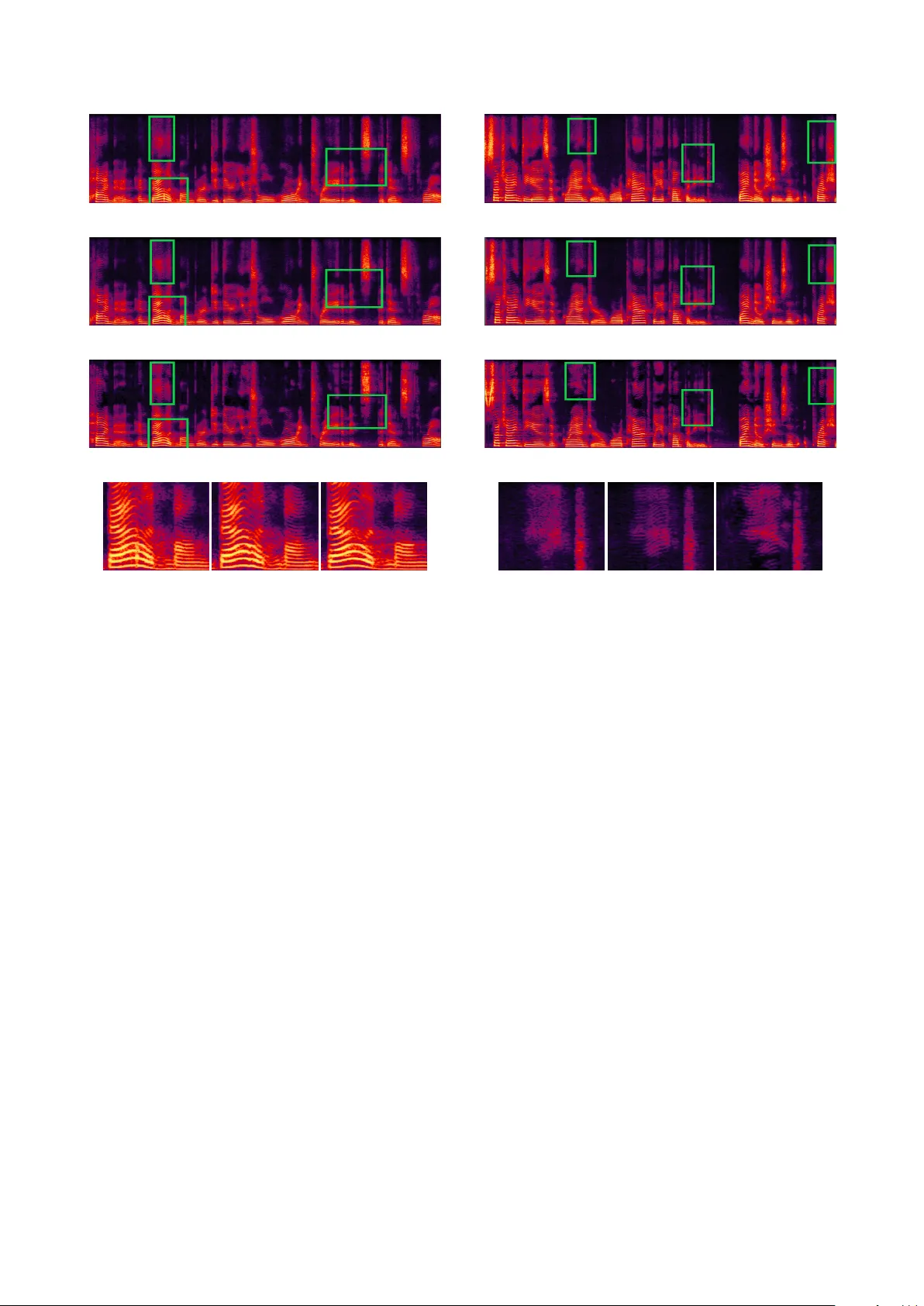
Generativ e Adversarial Netw ork based Speaker Adaptation f or High Fidelity W a veNet V ocoder Qiao T ian 1 , Xucheng W an 2 , Shan Liu 1 Cloud and Smart Industries Group, T encent T echnology Co., Ltd 1 { briantian,shiningliu } @tencent.com, 2 xucheng.wan@wisc.edu ∗ Abstract Although state-of-the-art parallel W av eNet has addressed the issue of real-time waveform generation, there remains prob- lems. Firstly , due to the noisy input signal of the model, there is still a gap between the quality of generated and natural w av e- forms. Secondly , a parallel W aveNet is trained under a distilla- tion frame work, which makes it tedious to adapt a well trained model to a ne w speaker . T o address these two problems, in this paper we propose an end-to-end adaptation method based on the generativ e adversarial network (GAN), which can reduce the computational cost for the training of new speaker adapta- tion. Our subjectiv e e xperiments sho ws that the proposed train- ing method can further reduce the quality gap between gener- ated and natural wa veforms. Index T erms : Neural V ocoder , Parallel W av eNet, Speaker Adaptation, Generativ e Adversarial Netw ork 1. Intr oduction In recent years, deep learning has made great progress in the field of speech synthesis. The state-of-the-art approach T acotron2 [1], which proposes an end-to-end acoustic model with modified W av eNet as neural vocoder[2], is able to produce high fidelity synthesized audio. Compared with the conv en- tional statistical parametric speech synthesis methods [3] com- bining with long short term memory (LSTM) and traditional vocoders [4, 5], this approach makes the synthesized speech greatly closer to wards natural speech in both speech quality and prosody . Parellel W aveNet [6] is proposed for real-time generation of speech based on the original W aveNet. It alleviates the enormous computational burden of the original auto-regressiv e W aveNet while preserving its relati ve high performance. Core idea of this parallel W aveNet that we employ for our system is the in verse autoregressi ve flows(IAFs) where sampling pro- cess is performed in parallel so that the inference can be im- plemented much faster than real-time. Howev er , there are still two issues that remained to be addressed in practical applica- tions. Firstly , training the entire system can be super slow since the basic training procedure is still auto-regressiv e. The train- ing pipeline of the parallel W av eNet is relativ ely tedious since it is trained follo wing the model distillation frame work [7]. Un- der such framework, a well learned auto-re gressiv e W aveNet is required as the teacher model to guide the training of the stu- dent model which is our tar get parallel W av eNet. And training both teacher and student models could take weeks. In addition, sufficient data are required to train teacher model for the new speaker . Secondly , although generated speech is of good qual- *This paper was done during Xucheng W an’s internship in CSIG, T encent T echnology Co., Ltd ity , there still exists a gap between generated and natural speech. This is due to the noisy input signal of the parallel W aveNet model, which results in lots of detailed information missing in high frequency domain of the generated speech. In this paper , we propose an adaptation frame work to adapt a well learned parallel W aveNet to a speaker with merely few hours of training data. W e replaced the distillation component in training framework with a generative adversarial component [8]. The minimax training trick of generati ve adversarial net- work (GAN) makes the generated samples undistinguishable from real samples. The discriminator of the GAN can capture some subtle differences between generated w av eforms and nat- ural audios, which are usually neglected by the auto-regressiv e teacher W av eNet, and it helps the generator to produce audios of higher fidelity . The contribution of this paper includes: 1) W e propose an end-to-end speaker adaptation for high fidelity neural vocoder based on GAN. The training of the proposed framew ork is much more efficient than the original distillation framew ork, such as parallel W av eNet and Clarinet [9]. 2) W e use the GAN to further reduce the gap between generated and natural speech. This paper is organized as follo ws: In Section 2, we will briefly revie w the basic background of GAN. Then the proposed method will be gi ven in Section 3. Experimental details and re- sults will be gi ven in Section 4. Lastly in Section 5, conclusions and potential future research directions are presented. 2. Generative Adversarial Network Generativ e Adversarial Network is a new framework proposed in recent years, which has been proven to be able to generate impressiv e samples in the field of computer vision. As shown in Fig. 1, a typical GAN model consists of two sub-networks: a Discriminator network (D) and a Generator network (G). The generator network learns to map a simple distribution p z ( z ) to a complex distrib ution P g ( x ) , where z denotes the random noise sample and x denotes the target data sample. The generator is trained to mak e the generated sample distribution P g ( x ) undis- tinguishable from real data distribution P d ( x ) . On the contrary , the discriminator is trained to identify the generated (f ake) sam- ples against data (real) samples which makes the adversarial training a minimax game. For conditional sample generation tasks, such as speech synthesis, an additional condition vector c is usually added to the input of both the generator and discrim- inator , which yields the conditional GAN (cGAN) model [10]. The training objectiv e of the cGAN is formulated as min G max D V ( D , G ) = E x , c ∼ p d ( x , c ) [log D ( x , c )] + E z ∼ p z ( z ) ,c ∼ p D ( c ) [log(1 − D ( G ( z , c ) , c )] . (1) The minimax training process of the original GAN is unsta- ble and difficult to con verge. And it usually results in mode col- Real Data Discriminator Binary Label Real Fake Generator Random Noise Figure 1: The ar chitectur e of generative adversarial network lapse problem where the samples from the input distrib ution all map to the same output which the discriminator can not distin- guish from the real data. A lot of tricks are therefore proposed to improve the training and ensure model to learn realistic dis- tribution. In order to alleviate mode collapse and also address the problem of vanishing gradients caused by sigmoid cross- entropy loss, the least-squares GAN (LSGAN) [11], is proposed by replacing the cross-entropy loss with a least-squares binary coding loss. The training objectiv es for the discriminator and generator of the LSGAN are defined as followings: min D V LSGAN ( D ) = 1 2 E x , c ∼ p d ( x , c ) ( D ( x , c ) − 1) 2 + 1 2 E z ∼ p z ( z ) , c ∼ p d ( c ) D ( G ( z , c ) , c ) 2 (2) min G V LSGAN ( G ) = 1 2 E z ∼ p z ( z ) , c ∼ p d ( c ) ( D ( G ( z , c ) , c ) − 1) 2 (3) The LSGAN has been applied to speech enhancement (SEGAN) [12] which generates clean speech signal condition- ing on noisy speech signal. An additional L 1 norm loss is used in learning the parameters of the G network of SEGAN, en- abling it to benefit from adversarial training to product much cleaner speech wav eform. This L 1 norm based loss term for the generator is defined as follows: min G V SEGAN ( G ) = λ || G ( z , e x ) − x || 1 + 1 2 E z ∼ p z ( z ) , e x ∼ p d ( e x ) [(( D ( G ( z , e x ) , e x ) − 1) 2 ] , (4) where ˜ x denotes the input noisy signal and a hyper parameter λ is used to balance the GAN loss and L 1 loss. 3. W aveNet Adaptation Using GAN The original auto-regressiv e W aveNet is a model that can gen- erate perfect speech wav eform. Dif ferent from the con ven- tional v ocoders, such as STRAIGHT [5] and WORLD [4], the W aveNet vocoder doesn’t depend on the source-filter assump- tion of speech signal. This makes it a perfect vocoder that can av oid the problems of excitation extraction. Howe ver , due to its auto-regressi ve nature, the wav eform generation is unbearably slow (100 times slower than real time or more on a Nvidia T esla P40 GPU). 3.1. Parallel W a veNet V ocoder The parallel W aveNet addressed the inference problem by using the inv erse auto-regressiv e flow (IAF) [13], which can perform 30 times faster than real time on a Nvidia T esla P40 GPU. How- ev er its training is very hard and trick y . pretrain process Distilling Initializing T eacher WaveNet Parallel W aveNet Generator Discriminator adaptation process adversarial training Figure 2: The ar chitectur e of speaker adaptation of parallel W aveNet using GAN. IAF is a method that enables the model to con vert the input noise signal into speech wav eform. Using noise signal as inputs allows the model to compute in parallel which is ke y to real- time generation. Howev er , IAF is difficult to optimize directly because of the requirement of auto-regressiv ely computed log- likelihood loss. [6] proposed a probability density distillation method to distill the student W aveNet ef ficiently from auto-regressi ve W aveNet with mixture of logistic (MoL) output distrib ution [14]. Therefore, the student W aveNet can generate audios whose fidelities are close to that of the auto-regressiv e W aveNet. On the other hand, the training of the model starts from training a time-consuming teacher auto-regressi ve W av eNet. 3.2. W aveNet Adaptation Speaker adaptation is a commonly adopted method for fast building of acoustic models for speech synthesis and speech recognition, especially for cases where training data are limited. If applying speaker adaptation directly to the parallel W aveNet model, we will need to apply it to both teacher and student mod- els. This would make the adaptation training of a new speaker extremely slo w and tedious. Therefore, in this paper we propose to employ the GAN framew ork to accelerate this adaptation training process and thus improv e the ef ficiency of training the entire parallel W aveNet system. As showed in Fig. 2, we adapt parallel W aveNet to a new speaker based on the adversarial training method by replacing the distilling teacher model with a discrim- inator from a GAN. Specifically for the adaptation GAN (AGAN), a parallel W aveNet of one speaker was pre-trained in advance. In this pre-training process, we apply the same model structure as pro- posed in [6]. But instead of using the same power -loss in the original parallel W aveNet system, we adopt a new loss term - the mean square loss of log-scale STFT -magnitude (log-mag loss) [15] which we will explain in detail shortly . At the adaptation phase, the pre-trained model is used to initialize the parameters of the generator of the GAN. W e apply the least-square loss [11] to stablize the training of adaptation. Howe ver , it is difficult for a v ocoder trained only using a single adversarial loss to produce speech waveform with high fidelity . Because least-square loss term only learns the information in time domain while the detailed information in frequency do- main is neglected. This idea can also be demonstrated by the experiment result of training the model with a single Kullback- Leibler (KL) loss in the original parallel W aveNet[6]. W e there- fore use an additional log-mag loss which has been proven to be ef fective in capturing spectral details during the training pro- cess. The log-mag loss is computed in frequency domain and it is defined as following: L log − mag ( x , x 0 ) = || log ( | STFT( x ) | + ) − log( | STFT( x 0 ) | + ) || 1 (5) where L 1 norm is used and is a very small value to ensure the positivity of spectral magnitude. W e construct our discriminator network using a non-causal dilated con v olution structure[16], similar to the architecture of a non-autoregressiv e W aveNet, to identify the generated (fake) wa veform against the recorded (real) wa veform. For this dis- criminator , we build the network with 10 dilated con volution layers without sacrificing discrimination performance at sample scale. And for our adaptation model, the mel-domain spectro- grams are used as conditional input, which is represented by c in this paper . In detail, for each sentence, we sample the wav eform x 0 from the output distribution of the generator network. Then x 0 is fed to the discriminator network to e v aluate the D loss against samples from real data distrib ution. The loss of the generator is defined as min G V AGAN ( G ) = L log − mag ( G ( z , c ) , x )+ λ 2 E z ∼ p z ( z ) , c ∼ p d ( c ) [(( D ( G ( z , c ) , c ) − 1) 2 ] . (6) where z denotes the input random noise c denotes the mel- spectrum and p ’ s represent the sample distrib utions accordingly . 4. Experiments 4.1. Data Set W e use two different datasets for the two training phases of our experiment. The initial parallel W aveNet model was pre- trained on our internal speech dataset, which contains 12 hours of mandarin speech records by a female speaker . For the adap- tation phase, we use the public LJSpeech dataset [17] to ev alu- ate the performance of the proposed speaker adaptation GAN. The audio for pre-training phase is re-sampled at 24 kHz, while in the adaptation phase, the original 22.05 kHz sampling rate of LJSpeech is preserved. LJSpeech dataset contains 13,100 short audio clips of public domain English speech data from a speaker . The lengths of audio clips range from 1 to 10 seconds and the total length is approximately 24 hours. W e randomly select 2000 audio clips, which add up to about 3 hours, as our training data. It is worth noting that we selected Mandarin speech sam- pled at 24 kHz to train the basic model while in the adaptation phase we used English speech sampled at 22.05 kHz. Man- darin is a tone-based language and English speech replies more on phonemes. By conducting our experiments on different lan- guages and at different sampling rates, it is further demonstrated that our model with proposed adaptation GAN method is pow- erful enough to handle most training cases. 4.2. Model setup Follo wing the configuration of acoustic analysis in T acotron2 [18], we e xtracted 80-dim mel-spectrograms as the local acous- tic condition for neural vocoders with a frame shift of 256 points and frame length of 2048 points. The initial parallel W aveNet was trained with 1500k steps with a teacher MoL W av eNet trained on the same dataset. In adaptation phase, we adopted the Adam optimizer [19] for the A GAN. The noam scheme [20] for learning rate was used with 4k warm-up step. The A GAN model was trained with batch size of 4 clips and max sample length 24000. For comparison, another parallel W av eNet was adapted by distilling using data of the target speak er . Both generator and discriminator in our GAN structure use adam optimizer . The discriminator of A GAN is trained with a random initialization. Its architecture is a non-causal W aveNet with 10 dilated conv olution layers using filter size 3 and max dilation rate of 10. W e add Leaky ReLU [21] activ ation func- tion with α = 0 . 2 after each layer of con volution except the last output layer . The discriminator also uses mel-spectrograms as local condition which is up-sampled to sample scale by a 4-layer de-con v olution network. The learning rate of the gener- ator and discriminator were set to 0.005 and 0.001 respecti vely . In the first 50k steps, we freeze the parameters of the generator in order to better learn a discriminator . Then for the next 100k steps till model con ver ges, the generator and discriminator are adversarial trained simultaneously . W e find that the coefficient λ of adversarial loss can, to some extend, reflect the fidelity of the generated w av eform. W e achiev e a relati vely good result by setting λ = 1 . 5 and another experiment with λ = 0 . 05 is set for comparison. 4.3. Experimental r esults W e adopt the commonly used Mean Opinion Score (MOS) to subjectiv ely ev aluate our proposed GAN-based speaker adap- tation framework. In order to ensure that the results are con- vincing enough, we randomly select 30 sentences that are not included in the training set from the dataset. Three mod- els are compared, including a parallel W av eNet model adap- tiv ely trained with the conv entional distillation framework as our baseline and two proposed A GAN models with λ = 0 . 05 and λ = 1 . 5 respectiv ely . The ground-truth recordings are used in comparison and 63 professional English listeners participated in the listening test. Since it is a neural vocoder , we focused on the fidelity (quality) of speech samples in our experiment. The results of the subjective MOS ev aluation are presented in T able 1. As we can see, our best model (AGAN with λ = 1 . 5 ) performs better than the conv entional adaptation ap- proach (baseline). Absolute rise of 0.05 in MOS seems not lar ge enough, but its worth noting that when MOS approaching nat- ural speech, a tiny improvement (say , 0.01) represents notable improv ements in some aspects of the human acoustical percep- tion. The gap between the baseline parallel W av eNet model and ground truth natural speech is 0.1 in MOS. And our method further narrows this gap by half, making the speech generation achieving human le vel high fidelity 1 . W e also inv estigated the importance of adversarial loss in A GAN by setting different values to λ . It can be easily analyzed from the results in T able 1 that the performance of A GAN sig- nificantly degraded when decreasing weight of adversarial loss, ev en worse than the baseline model. And of course, more ex- periments are still needed to further demonstrate the relation between speech quality and adversarial loss. Apart from MOS ev aluation, we also conducted a case study on the Mel-spectrograms of the models. As shown in 1 Audio samples can be found at https://agan- demo. github.io/ . (1-a) Parallel W aveNet (1-b) A GAN (1-c) Ground-truth (1-d) Expanded Area Figure 3: STFT spectro grams of samples fr om parallel W aveNet, A GAN (ours) and Gr ound-T ruth r ecor ding. Spectr o- grams of example 1. (1-d) subfigures ar e the expanded low fre- quency patterns of the lower left green-windowed ar eas(fr om left to right: parallel W aveNet, AGAN, Gr ound-truth). we can see that ther e e xist some non-natural spectrum lines in parallel- W aveNet generated audio, while A GAN gener ated audio avoids such issue . Fig. 3 and Fig. 4, we list two groups of audio samples which is consisting of ground-truth audio, PWN-generated audio and A GAN-generated audio spectrograms. When comparing thoses Mel-spectrograms along time axis, it is clear that the proposed model can capture more detailed spectral information of the target speaker than parallel W av eNet model. T ypical differ- ences are marked with green windows in the figure. And in those areas, our A GAN model generated audios with resonance peaks that approach ground-truth audios better while parallel W aveNet generated lower quality spectragroms. W e can find obvious harmonic structures in the spectrograms of A GAN and ground truth generation results, but some of those details are missing in the parallel W aveNet baseline result. 4.4. Adaptation cost of training T ime consumption of adaptation training is vital for deployment in practical applications. Once the basic pre-trained model is obtained, the efficienc y of adaptation determines the speed of training the entire vocoder system. T o prove the adaptation ef- ficient of our proposed model, we ev aluate the training time of our method on a Nvidia T esla P40 GPU. It takes about 36 hours to complete an adaptation training for the baseline par - (2-a) Parallel W aveNet (2-b) A GAN (2-c) Ground-T ruth (2-d) Expanded Area Figure 4: STFT spectro grams of samples fr om parallel W aveNet, A GAN (ours) and Gr ound-T ruth r ecor ding. Spec- tr ogr ams of example 2. (2-d) subfigur e expands the upper left gr een-windowed high fr equency areas(fr om left to right: paral- lel W aveNet, AGAN, Gr ound-truth). F r om these figur es we can tell that the r esonance peaks are clear in A GAN output against the blurring spectrum in the baseline output ,which verifies that our AGAN method can generate mor e natural audios than par- allel W aveNet allel W aveNet, which includes both teacher and student model. The adaptation training of proposed AGAN on the same dataset takes about 12 hours, merely one third of the time that paral- lel W av eNet consumed. This remarkable low time consumption is not only due to the efficiency of A GAN training, but also be- cause that adaptation process is independent of a teacher model. Although a discriminator is required in A GAN, its training is quite fast and stable. 5. Conclusions In this work, we propose a speaker adaptation framework for parallel W av eNet vocoder based on GAN (AGAN). Compar- ing to con ventional retrain-based model adaptation, A GAN per- forms more efficient adaptation on a relativ ely small amount of a new speaker data and generates speech with higher percep- tual quality . And it provides an end to end adaptation method which is much faster than distilled framework such as parallel W aveNet. Our experiments indicates that the proposed method can further reduce the gap between speech samples from record- ing and proposed model. In addition, as a future work, it is straightforward that the T able 1: Mean Opinion Score(MOS) with 95% confidence in- tervals for differ ent adaptation method. Method Subjective 5-scale MOS Parallel W aveNet (baseline) 4.53 ± 0.17 A GAN ( λ =0.05) 4.50 ± 0.20 A GAN ( λ =1.50) 4.58 ± 0.16 Ground-truth 4.63 ± 0.14 proposed method can also be applied to optimize an IAF di- rectly based parallel W av eNet model from scratch without the requirement of auto-regressi ve teacher model. 6. References [1] Y . W ang, R. Skerry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio et al. , “T acotron: A fully end-to-end text-to-speech synthesis model, ” arXiv preprint , 2017. [2] A. v . d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “W av enet: A generativ e model for raw audio, ” arXiv preprint arXiv:1609.03499 , 2016. [3] H. Zen and H. Sak, “Unidirectional long short-term memory re- current neural network with recurrent output layer for lo w-latency speech synthesis, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 4470–4474. [4] M. Morise, F . Y okomori, and K. Ozawa, “W orld: a v ocoder-based high-quality speech synthesis system for real-time applications, ” IEICE TRANSACTIONS on Information and Systems , v ol. 99, no. 7, pp. 1877–1884, 2016. [5] H. Kawahara, I. Masuda-Katsuse, and A. De Cheveigne, “Re- structuring speech representations using a pitch-adaptive time– frequency smoothing and an instantaneous-frequency-based f0 extraction: Possible role of a repetitive structure in sounds1, ” Speech communication , v ol. 27, no. 3-4, pp. 187–207, 1999. [6] A. v . d. Oord, Y . Li, I. Babuschkin, K. Simonyan, O. V inyals, K. Kavukcuoglu, G. v . d. Driessche, E. Lockhart, L. C. Cobo, F . Stimberg et al. , “Parallel wavenet: Fast high-fidelity speech synthesis, ” arXiv preprint , 2017. [7] G. Hinton, O. V inyals, and J. Dean, “Distilling the knowledge in a neural network, ” arXiv pr eprint arXiv:1503.02531 , 2015. [8] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair, A. Courville, and Y . Bengio, “Generati ve adver- sarial nets, ” in Advances in neural information pr ocessing sys- tems , 2014, pp. 2672–2680. [9] W . Ping, K. Peng, and J. Chen, “Clarinet: Parallel wav e generation in end-to-end text-to-speech, ” arXiv preprint , 2018. [10] A. Odena, C. Olah, and J. Shlens, “Conditional image synthesis with auxiliary classifier gans, ” arXiv pr eprint arXiv:1610.09585 , 2016. [11] X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. W ang, and S. P . Smolley , “Least squares generative adversarial networks, ” in Computer V i- sion (ICCV), 2017 IEEE International Conference on . IEEE, 2017, pp. 2813–2821. [12] S. Pascual, A. Bonafonte, and J. Serra, “Se gan: Speech enhancement generativ e adversarial network, ” arXiv preprint arXiv:1703.09452 , 2017. [13] D. P . Kingma, T . Salimans, R. Jozefowicz, X. Chen, I. Sutske ver , and M. W elling, “Improved v ariational inference with in verse au- toregressi ve flo w , ” in Advances in Neural Information Pr ocessing Systems , 2016, pp. 4743–4751. [14] T . Salimans, A. Karpathy , X. Chen, and D. P . Kingma, “Pixelcnn++: Improving the pixelcnn with discretized logis- tic mixture likelihood and other modifications, ” arXiv preprint arXiv:1701.05517 , 2017. [15] S. O. Arik, H. Jun, and G. Diamos, “Fast spectrogram in version using multi-head conv olutional neural networks, ” arXiv preprint arXiv:1808.06719 , 2018. [16] D. Rethage, J. Pons, and X. Serra, “ A wavenet for speech denois- ing, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 5069–5073. [17] K. Ito, “The lj speech dataset, ” https://keithito.com/LJ-Speech- Dataset/, 2017. [18] J. Shen, R. Pang, R. J. W eiss, M. Schuster, N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, R. Skerrv-Ryan et al. , “Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 4779– 4783. [19] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv preprint , 2014. [20] A. V aswani, S. Bengio, E. Brevdo, F . Chollet, A. N. Gomez, S. Gouws, L. Jones, Ł. Kaiser, N. Kalchbrenner , N. Parmar et al. , “T ensor2tensor for neural machine translation, ” arXiv pr eprint arXiv:1803.07416 , 2018. [21] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlinearities improve neural network acoustic models, ” in Pr oc. icml , vol. 30, no. 1, 2013, p. 3.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment