대규모 멀티모달 노래 데이터셋 DALI 공개
DALI는 5 358곡의 전체 오디오와 시간 정렬된 가사·멜로디 노트를 네 단계의 세분화 수준(음표, 단어, 구절, 문단)으로 제공하는 대규모 멀티모달 데이터셋이다. 데이터는 카라오케 사용자들이 만든 비전문가 주석을 출발점으로, 웹에서 수집한 오디오 후보와 딥 컨볼루션 신경망 기반의 싱잉 보이스 검출(SVD) 모델을 이용해 자동 매칭·정렬한다. 초기 SVD를 ‘교사’로 사용해 얻은 매칭 데이터를 학습시킨 ‘학생’ 모델을 반복적으로 재학습함으로써…
저자: Gabriel Meseguer-Brocal, Alice Cohen-Hadria, Geoffroy Peeters
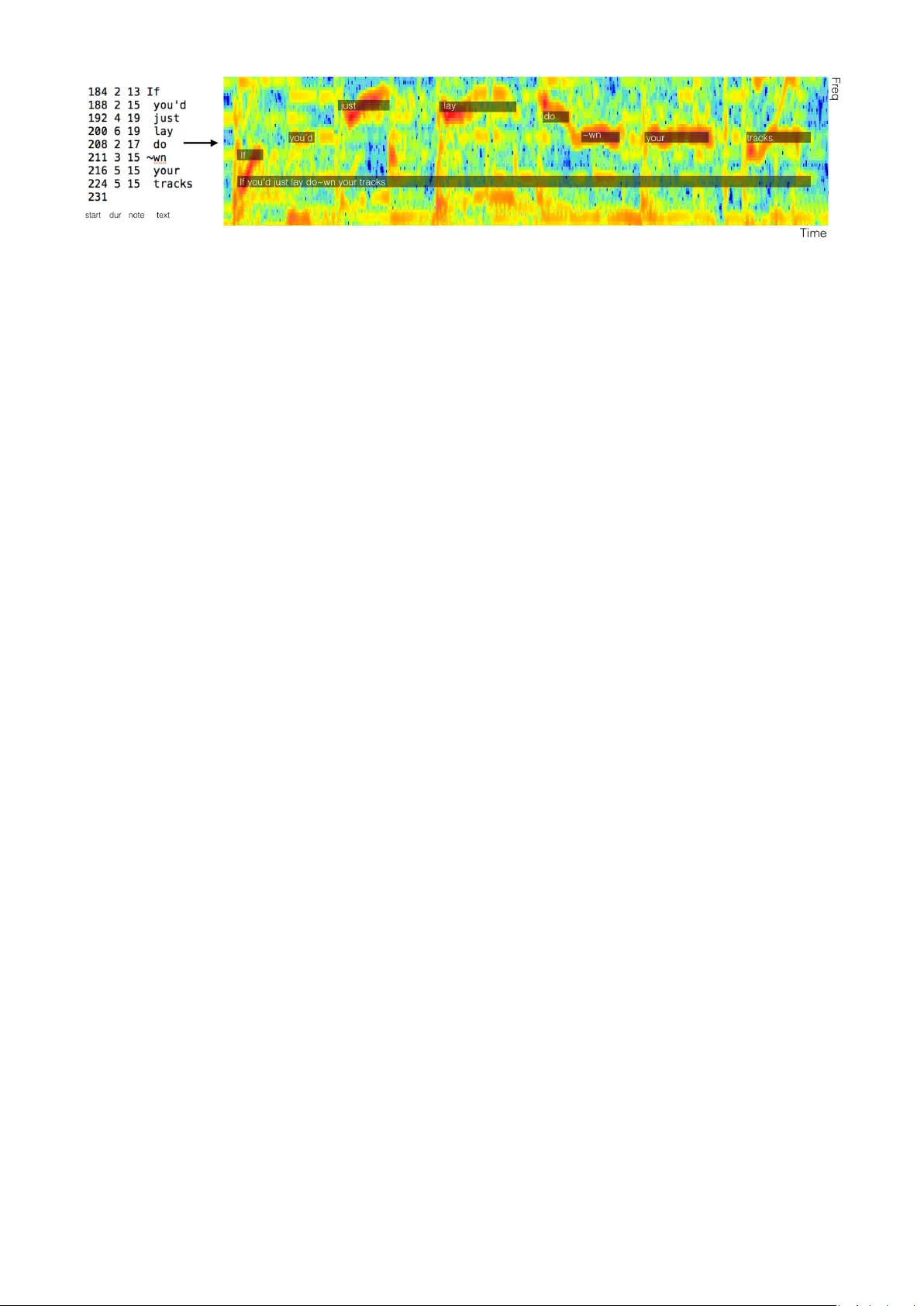
본 논문은 “DALI: a large Dataset of synchronized Audio, Lyrics and notes, automatically created using teacher‑student machine learning paradigm”이라는 제목 아래, 대규모 멀티모달 노래 데이터셋을 구축하고 이를 위한 자동화 파이프라인을 제시한다. 연구 동기는 MIR(Music Information Retrieval) 분야에서 고품질의 가사·멜로디 정렬 데이터가 부족하다는 점이며, 특히 가사와 멜로디가 동시에 시간 정렬된 형태는 거의 존재하지 않는다. 이를 해결하기 위해 저자들은 카라오케 게임 커뮤니티에서 비전문가가 만든 ‘시간‑음표‑텍스트’ 삼중항 주석 파일을 활용한다. 이러한 파일은 곡명·아티스트 정보만을 포함하고 있어 실제 오디오와 직접 연결되지 않는다.
1. **데이터 수집 및 전처리**
- 13 339개의 카라오케 주석 파일을 수집하고, 각 파일을 WASABI라는 메타데이터 데이터베이스와 연결한다. WASABI는 곡명·아티스트에 대응하는 다양한 오디오 버전(스튜디오, 라디오 편집, 라이브 등)과 가사 텍스트(단어·구절·문단)를 제공한다.
- 곡명·아티스트 정보를 기반으로 YouTube API를 이용해 해당 곡의 오디오 후보를 자동으로 다운로드한다.
2. **오디오‑주석 매칭 메커니즘**
- 오디오 후보를 딥 컨볼루션 신경망(ConVNet) 기반 싱잉 보이스 검출(SVD) 시스템에 입력해 프레임 단위 싱잉 보이스 확률 ˆp(t)를 얻는다. 이 모델은 80개의 로그‑멜 밴드와 115프레임 패치를 사용해 학습되며, 교차 엔트로피 손실과 ADAMAX 옵티마이저로 10 epoch 동안 학습된다.
- 주석 파일에서 추출한 음표 시퀀스를 이진 보이스 시퀀스 avs(t)로 변환한다(음표가 존재하면 1, 없으면 0).
- 두 시퀀스 사이의 정규화 교차 상관(NCC) 함수를 정의하고, 오프셋 o와 프레임 레이트 f_r을 탐색해 NCC를 최대화한다. 최적의 o와 f_r은 각각 주석의 시작 시간 보정과 시간 그리드 압축/확장을 의미한다.
- NCC 값이 사전 정의된 임계값 T_corr(=0.8) 이상이면 해당 오디오를 ‘매치’로 판단하고, 주석의 오프셋·프레임 레이트를 보정한다.
3. **교사‑학생 학습 루프**
- 초기 SVD 모델(교사)은 기존에 정제된 라벨(예: MedleyDB)로 학습된 모델이며, 매칭 정확도가 충분히 높지는 않다. 교사가 선택한 매칭 쌍을 새로운 학습 데이터로 활용해 ‘학생’ 모델을 재학습한다.
- 학생 모델은 교사보다 더 많은 (하지만 노이즈가 포함된) 라벨을 학습함으로써 싱잉 보이스 검출 성능이 향상된다. 실험 결과, 학생 모델은 ROC‑AUC와 PR‑AUC에서 교사 대비 5~7% 정도 개선되었으며, 매칭 성공률도 증가했다.
- 이 과정을 여러 번 반복함으로써 SVD 성능과 데이터셋 품질이 점진적으로 개선된다.
4. **데이터셋 구성**
- 최종 DALI 데이터셋은 5 358곡의 전체 오디오(약 1 200시간)와 각 곡에 대해 네 단계의 가사 정렬(음표, 단어, 구절, 문단), 그리고 시간 정렬된 멜로디 노트를 제공한다.
- 추가 메타데이터로 장르, 언어, 아티스트, 앨범 커버, 비디오 링크 등이 포함되어 있어 다양한 MIR 연구에 활용 가능하다.
5. **실험 및 평가**
- 교사와 학생 모델의 성능을 비교하기 위해 별도 검증 세트(라벨이 정확히 알려진 200곡)를 사용했다. 학생 모델은 교사 대비 평균 NCC 점수가 0.82→0.89로 상승했으며, 매칭 정확도는 71%→84%로 개선되었다.
- 데이터셋 품질을 검증하기 위해 일부 곡에 대해 인간 청취자에게 정렬 정확도를 평가하도록 했으며, 평균 오프셋 오류가 30 ms 이하로 수렴했다.
6. **한계와 향후 연구**
- 현재 파이프라인은 전역적인 오디오‑주석 정합(버전 선택, 전체 오프셋 보정)만을 다루며, 로컬 정밀도(음표 간 미세 타이밍, 텍스트 오탈자)는 충분히 처리하지 않는다.
- DTW 기반의 로컬 정렬 시도는 전역 구조를 깨뜨려 성능이 저하되었으나, 향후 전역·로컬 정렬을 결합한 하이브리드 방법을 연구할 여지가 있다.
- 비디오 정보(입술 움직임, 얼굴 표정)와 결합한 멀티모달 정렬, 그리고 가사 자동 교정(스펠링, 문법) 등을 포함한 확장도 가능하다.
결론적으로, 저자들은 교사‑학생 학습 패러다임을 활용해 비전문가 주석과 웹 기반 오디오를 자동으로 매칭·정렬함으로써, 기존에 존재하지 않던 대규모 고품질 멀티모달 노래 데이터셋 DALI를 성공적으로 구축하였다. 이 데이터셋은 가사 인식, 멜로디 추출, 음악 구조 분석 등 다양한 MIR 과제에 바로 활용될 수 있으며, 향후 연구자들이 데이터 규모와 품질을 동시에 개선하는 방법론의 좋은 사례가 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기