DALI: a large Dataset of synchronized Audio, LyrIcs and notes, automatically created using teacher-student machine learning paradigm
The goal of this paper is twofold. First, we introduce DALI, a large and rich multimodal dataset containing 5358 audio tracks with their time-aligned vocal melody notes and lyrics at four levels of granularity. The second goal is to explain our metho…
Authors: Gabriel Meseguer-Brocal, Alice Cohen-Hadria, Geoffroy Peeters
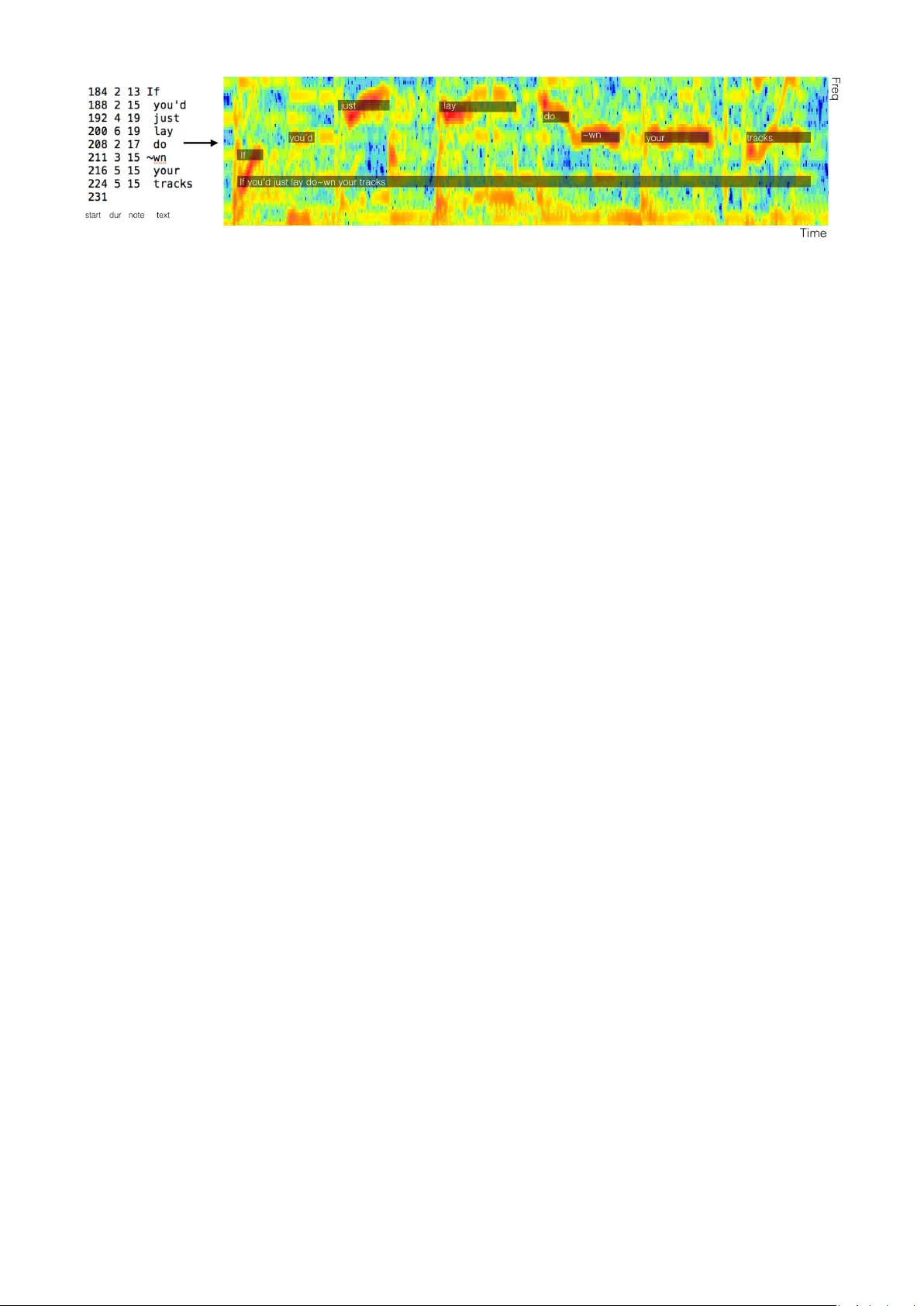
D ALI: A LARGE D A T ASET OF SYNCHR ONIZED A UDIO, L YRICS AND NO TES, A UT OMA TICALL Y CREA TED USING TEA CHER-STUDENT MA CHINE LEARNING P ARADIGM Gabriel Meseguer -Brocal Alice Cohen-Hadria Geoffroy P eeters Ircam Lab, CNRS, Sorbonne Univ ersit ´ e, Minist ` ere de la Culture, F-75004 Paris, France gabriel.meseguerbrocal@ircam.fr, alice.cohenhadria@ircam.fr, geoffroy.peeters@ircam.fr ABSTRA CT The goal of this paper is twofold. First, we introduce D ALI, a lar ge and rich multimodal dataset containing 5358 audio tracks with their time-aligned vocal melody notes and lyrics at four lev els of granularity . The second goal is to explain our methodology where dataset creation and learning models interact using a teacher-student machine learning paradigm that benefits each other . W e start with a set of manual annotations of draft time-aligned lyrics and notes made by non-expert users of Karaoke games. This set comes without audio. Therefore, we need to find the corresponding audio and adapt the annotations to it. T o that end, we retrie ve audio candidates from the W eb. Each candidate is then turned into a singing-voice probability over time using a teacher , a deep con volutional neural network singing-voice detec- tion system (SVD), trained on cleaned data. Comparing the time-aligned lyrics and the singing-voice probability , we detect matches and update the time-alignment lyrics ac- cordingly . From this, we obtain ne w audio sets. They are then used to train new SVD students used to perform again the abov e comparison. The process could be repeated it- erativ ely . W e sho w that this allo ws to progressi vely im- prov e the performances of our SVD and get better audio- matching and alignment. 1. INTRODUCTION Singing v oice is one of the most important elements in pop- ular music. It combines its two main dimensions: melody and lyrics. T ogether , they tell stories and con vey emo- tions improving our listening experience. Singing v oice is usually the central element around which songs are com- posed. It adds a linguistic dimension that complements the abstraction of the musical instruments. The relationship between lyrics and music is both global (lyrics topics are usually highly related to music genre) and local (it con- © Gabriel Mese guer-Brocal, Alice Cohen-Hadria, Geoffro y Peeters. Licensed under a Creativ e Commons Attribution 4.0 Interna- tional License (CC BY 4.0). Attribution: Gabriel Meseguer-Brocal, Alice Cohen-Hadria, Geoffroy Peeters. “DALI: a large Dataset of syn- chronized Audio, L yrIcs and notes, automatically created using teacher- student machine learning paradigm”, 19th International Society for Music Information Retriev al Conference, Paris, France, 2018. nects specific musical parts with a concrete lexical mean- ing, and also defines the structure of a song). Despite its importance, singing voice has not recei ved much attention from the MIR community . It has only been introduced a few years ago as a standalone topic [12, 17]. One of the most important factors that prev ents its de- velopment is the absence of large and good quality ref- erence datasets. This problem also exists in other MIR fields, ne vertheless sev eral solutions have been proposed [3, 9]. Currently , researchers working in singing voice use small designed dataset following different methodol- ogy [10]. Large datasets as the one used in [13] are pri vate and not accessible to the community . The goal of this paper is to propose such a dataset and to describe the methodology followed to construct it. 1.1 Proposal W e present the D ALI dataset: a large D ataset of synchro- nised A udio, L yr I cs and notes that aims to stand as a ref- erence for the singing voice community . It contains 5358 songs (real music) each with – its audio in full-duration, – its time-aligned lyrics and – its time-aligned notes (of the vocal melody). L yrics are described according to four lev els of granularity: notes (and textual information un- derlying a given note), words, lines and paragraphs. For each song, we also provide additional multimodal infor- mation such as genre, language, musician, album covers or links to video clips. The rest of this paper focuses on our methodology for creating D ALI. In Figure 1, we illustrate the input and output of our dataset creation system. See Section 4 for more details about the dataset itself. The DALI dataset has been created automatically . Our approach consists in a constant interaction between dataset creation and learning models where they benefit from each other . W e developed a system that acquires lyrics and notes aligned in time and finds the corresponding audio tracks. The time-aligned lyrics and notes come from Karaoke re- sources (see Section 3.1 for more deatils). Here, non- expert users manually describe the lyrics of a song as a se- quence of annotations: time aligned notes with their asso- ciated textual information. While this information is pow- erful it has tw o major problems: 1) there is no information about the e xact audio used for the annotation process (only the song title and artist name which may lead to many dif- ferent audio versions), 2) even if the right audio is found, Figure 1 : [Left part] The inputs of our dataset creation system are karaoke-user annotations presented as a triple of { time (start + duration), musical-notes, text } . [Right part] Our dataset creation system automatically finds the corresponding full-audio track and aligned the vocal melody and the lyrics to it. In this example, we illustrate the alignment for a small excerpts. W e only represent two lev els of lyrics granularity: notes and lines. annotations may need to be adjusted to fit the audio per- fectly . In Section 3.2, we define how we retrieve from the W eb the possible audio candidates for each song. In Sec- tion 3.3, we describe how we select the right audio among all the possible candidates and how we automatically adapt the annotated time-alignment lyrics to this audio. In order to do this, we propose a distance that measures the corre- spondence between an audio track and a sequence of man- ual annotations. This distance is also used to perform the necessary adaptations on the annotations to be perfectly aligned with the audio. Our distance requires the audio to be described as a singing voice probability sequence. This is computed using a singing voice detection (SVD) system based on deep conv olutional neural network (Con- vNet). The performance of our system highly depends on the precision of the SVD. Our first v ersion is trained on few but accurately-labeled ground truths. While this sys- tem is sufficient to select the right audio it is not to get the best alignment. T o improve the SVD, in Section 3.4 we propose to use a teacher-student paradigm. Thanks to the first SVD system (the teacher) we selected a first set of audio tracks and their corresponding annotations. Using them, we train new SVD systems (the students). W e show in Section 3.4.1 that new SVD systems (the students) are better than the initial one (the teacher). W ith this new ver - sion, we increase the quality and size of the DALI dataset. Finally , we discuss our research in Section 5. 2. RELA TED WORKS W e re view pre vious works related to our work: singing voice detection methods and the teacher-student paradigm. Singing V oice detection. Most approaches share a common architecture. Short-time observations are used to train a classifier that discriminates observations (per frame) in vocal or non-vocal classes. The final stream of predic- tions is then post-processed to reduce artifacts. Early works explore classification techniques such as Support V ector Machines (SVMs) [16, 20], Gaussian mix- ture model (GMM) [11] or multi-layer perceptron (MLP) [4]. Other approaches also tried to use specific vocal traits such as vibrato and tremolo [21] or to adapt speech recog- nition systems for the particularities of singing voice [5]. Over the past few years, most works focus on the use of deep learning techniques. For example, [23, 24] propose the use of Con vNet combined with data augmentation tech- niques (to increase the size of the training set) or trained on weakly labeled data (the data are only labeled at the file lev el, not at the segment lev el). [13] also proposes the use of CNN but with a Constant-Q input and a training on a very large priv ate datasets mined from Spotify re- sources. Some researchers suggest the use of Recurrent Neural Networks (RNN) [15] or Long Short-T erm Mem- ory (LSTM) [14]. One adv antage of these models is that they directly model the decisions sequence over time and no post-processing is needed. Other singing voice detec- tion systems are dev eloped to be used as a pre-processing- step: for lyrics transcription [17] or for source separation [25] trained then to obtain ideal binary masks. T eacher-student paradigm. T eacher-student learning paradigm [2, 28] has appeared as a solution to ov ercome the problem of insufficient labeled training data in MIR. Since manual labeling is a time-consuming tasks, the teacher- student paradigm e xplores the use of unlabeled data for su- pervised problems. The two main agents of this paradigm are: the teacher and the student. The teacher is trained with labels of well known ground truths datasets (often manu- ally annotated). It is then used to automatically label unla- beled data on a (usually) larger dataset. These new labels (the one gi ven by the teacher) are the ones used for training the student(s) . Student(s) indirectly acquire(s) the desired knowledge by mimicking the “teacher behaviour”. This model has achiv ed great results for tasks in speech recog- nition [27] and multilingual models [8]. It has also been prov ed that student(s) can achiev e superior performances than the teacher [8, 28]. 3. SINGING V OICE D A T ASET : CREA TION 3.1 Karaoke r esources Outside the MIR community there are rich sources of in- formation that can be explored. One of these sources is Karaoke video games that fit exactly our requirements. In these games, users have to sing along with the music to win points according to their singing accuracy . T o mea- sure their accurac y , the user melody is compared with a T able 1 : T erms overvie w: definition of each term used in this paper . T erm Definition Annotation basic alignment unit as a triple of time (start + duration wrt F r ), musical-notes (with 0 = C3) and text. A file with annotations group of annotations that define the alignment of a particular song. Offset time as O it indicates the start of the annotations, its modifications moves all bock to the right or left. Frame rate as F r it controls the annotation grid size stretching or compressing its basic unit. Annotation voice sequence as av s ( t ) ∈ { 0 , 1 } singing v oice (SV) sequence extracted from karaoke-users annotations. Predictions as ˆ p ( t ) ∈ [0 , 1] SV probability sequence pro vided by our singing voice detection. Labels labels sequence of well kno wn ground truths datasets checked by the MIR community . Teacher first SV detection (SVD) system trained on Labels . Student ne w SVD system trained on the av s ( t ) for the subset of track for which N C C ( ˆ o, ˆ f r ) ≥ T corr . reference timing note (that has fine time and frequency). Hence, large datasets of time-aligned note and lyrics exist. Such datasets can be found as open-source. Nowadays, there are several acti ve and big karaoke open-source com- munities. In those, non-expert users exchange text files containing lyrics and melody annotations. Howe ver there is no further professional revision. Each file contains all the necessary information to describe a song: • the sequence of triplets { time, musical-notes, text } , • the offset time (start of the sequence) and frame rate (annotation time-grid), • the song title and the artist name . W e refer to T able 1 for the definition of all the terms we use. These annotations can be transformed to get the time and note frequencies as seen Figure 1. W e were able to retrie ve 13339 karaoke annotation files. Although this information is outstanding for our commu- nity , it presents sev eral problems that have to be solv ed: Global. When performing the annotation, users can choose the audio file they want. The problem is that only the song title and artist name are provided. This combi- nation might refer to different audio versions (studio, ra- dio edit, li ve, remix, etc.). Consequently , we do not kno w which audio version has been used. Annotations made for a version do not work for another . Besides, e ven if the correct audio is known, annotations may not perfectly fit it. As a result annotations must be adapted. This is done by modifying the provided offset time and frame rate . These issues are not problematic for karaoke-users but critical T o the automatic creation of a large dataset for MIR research. Local. It refers to errors due to fact the that users are non- professionals. It covers local alignment problems of par- ticular lyric blocks, text misspellings or note mistakes. In this paper we only focus on global problems leaving the local ones for future works. W ASABI is a semantic database of song kno wledge gathering metadata collected from various music databases on the W eb [18]. In order to benefit from the richness of this database, we first linked each annotation file to W asabi. T o that end, we connected a specific song title and artist name with all possible corresponding audio versions (studio, radio, edit, liv e, remix, etc.). The W ASABI also provides lyrics in a text only annotations (grouped by lines and paragraphs). Using the two lyrics representations (note-based annotations and text only an- notations), we created four lev els of granularity: notes, words, lines and paragraphs. Finally , W ASABI also pro- vides extra multimodal information such as cover images, links to video clips, metadata, biography , expert notes, etc. 3.2 Retrieving audio candidates Our input is an annotation file connected to the W ASABI database. This database provides us with the different ex- isting versions (studio, radio, edit, live, remix, etc.) for a song title and artist name combination. Knowing the possible versions, we then automatically query Y ouT ube 1 to get a set of audio candidates. W e now need to select among the set of audio candidates the one corresponding to the annotation file. 3.3 Selecting the right audio fr om the candidate and adapting annotation to it Each audio candidate is compared to the reference annota- tion file. W e do this by measuring a distance between both and keeping the one with the lar gest value. Audio and annotations liv e in two dif ferent representa- tion spaces that cannot be directly compared. In order to find a proper distance, we need to transform them to a com- mon representation space. T wo directions were studied: Annotations as audio. W e hav e e xplored lyrics synchro- nization techniques [10] but their complexity and pho- netic model limitations prevent us to use them. As anno- tations can be transformed into musical notes, score align- ment approaches [7, 26] seem a natural choice. Howe ver , due to missing information in the corresponding score (we only have the score of the vocal melody) these sys- tems f ailed. W e then tried to reduce the audio to the vocal melody (using Melodia [22]) and then align it to the vocal melody score but this also failed. Consequently , we did not persist in this direction. A udio as annotations. The idea we dev elop in the remain- der is the following. W e con vert the audio track to a singing-voice probability ˆ p ( t ) o ver time t . This sequence has v alue ˆ p ( t ) → 1 when voice is present at time t and ˆ p ( t ) → 0 otherwise. This probability is computed from the audio signal using a Singing V oice Detection (SVD) 1 W e use https://github.com/rg3/youtube- dl Figure 2 : Architecture of our Singing V oice Detection system using a Con vNet. system described below . W e name this function predic- tions . Similarly , the sequence of annotated triplets { time, musical-notes, text } can be mapped to the same space: av s ( t ) = 1 when a vocal note exists at t and av s ( t ) = 0 otherwise. W e name this function annotation voice se- quence . Singing V oice Detection system. Our system is based on the deep Con volutionnal Neural Network proposed by [24]. The audio signal is first con verted to a sequence of patches of 80 Log-Mel bands over 115 time frames. Figure 2 shows the architecture of the netw ork. The output of the system represents the singing voice probability for the center time-frame of the patch. The network is trained on binary target using cross-entropy loss-function, AD AMAX optimizer , mini-batch of 128, and 10 epochs. Cross-corr elation. T o compare audio and annotation, we simply compare the functions ˆ p ( t ) and av s ( t ) . As ex- plained before, the annotation files also come with a pro- posed offset time and frame rate . W e denote them by O and F r in the following. The alignment between ˆ p ( t ) and av s ( t ) depends on the correctness of O and F r v alues. W e will search around O and F r to find the best possible alignment. W e denote by o the correction to be applied to O and by f r the best F r . Our goals are to: 1. find the value of o and f r that provides the best alignment between ˆ p ( t ) and avs ( t ) , 2. based on this best alignment, deciding if ˆ p ( t ) and av s ( t ) actually match each other and establishing if the match is good enough to be kept. Since we are interested in a global matching between ˆ p ( t ) ∈ [0 , 1] and av s ( t ) ∈ { 0 , 1 } we use the normalized cross-correlation (NCC) as distance 2 : N C C ( o, f r ) = P t av s f r ( t − o ) ˆ p ( t ) p P t av s f r ( t ) 2 p P t ˆ p ( t ) 2 The NCC provides us directly with the best ˆ o value. This value directly provides the necessary correction to be applied to O to best align both sequences. T o find the best value of f r we compress or stretch annotation by changing the grid size. This warp is con- stant and respect the annotation structure. W e denote it as av s f r ( t ) . The optimal f r value is computed using a brute 2 Matches between ˆ p ( t ) and av s ( t ) can also be found using Dynamic T ime W arping (DTW). Howe ver , we found its application not successfull for our purpose. Indeed, DTW computes local warps that does not respect the global structure of the user annotations. In addition, its score is not normalized prev enting its use for matches selection. force approach, testing the values of f r around the original F r in an interv al controlled by α (we use α = F r ∗ 0 . 05 ): ˆ f r , ˆ o = arg max f r ∈ [ F r − α,F r + α ] ,o N C C ( o, f r ) Our final score is giv en by N C C ( ˆ o, ˆ f r ) . The audio is considered as good match the annotation if N C C ( ˆ o, ˆ f r ) ≥ T corr . The value of T corr has been found empirically to be T corr = 0 . 8 . For a specific annotation, if se veral audio candidate tracks have a v alue N C C ≥ T corr , we only keep the one with the largest value. T corr = 0 . 8 is quite restrictiv e but even if we may loose good pairs we ensure that those we keep are well aligned. When an audio match is found, the annotations are adapted to it using ˆ f r and ˆ o . Necessity to improv e the Singing V oice Detection system. The score N C C proposed above strongly de- pends on the quality of ˆ p ( t ) (the prediction pro vided by the Singing V oice Detection (SVD) system). Small dif- ferences in predictions lead to similar N C C ( ˆ o, ˆ f r ) v alues but v ery different alignments. While the predictions of the baseline SVD system are good enough to select the cor- rect audio candidates (although there are still quite a few false negativ es), it is not good enough to correctly estimate ˆ f r and ˆ o . As improving the SVD system the number of false ne gatives will be reduced and we will also find better alignments. W e hence need to improve our SVD system. The idea we propose below is to re-train the SVD sys- tem using the set of candidates audio that match the an- notations. This is a much larger training set (around 2000) than the one used to train the baseline system (around 100). W e do this using a teacher-student paradigm. 3.4 T eacher -Student Our goal is to improve our Singing V oice Detection (SVD) system. If it becomes better , it will find better matches and align more precisely audio and annotations. Conse- quently , we will obtain a better D ALI dataset. This larger dataset can then be used to train a new SVD system which again, can be used to find more and better matches improv- ing and increasing the DALI dataset. This can be repeated iterativ ely . After our first iteration and using our best SVD system, we reach 5358 songs in the D ALI dataset. W e formulate this procedure as a T eacher-Student paradigm. The processing steps of the whole Singing V oice Dataset creation is summarized in Figure 3. Upper left box. W e start from Karaok e resources that pro- vide our set of annotation files. Each annotation file de- fines a sequence of triplets { time, note, next } that we con- Figure 3 : Singing V oice Dataset creation using a teacher-student paradigm. vert to an annotation voice sequence avs ( t ) . For each an- notation file, we retriev e a set of audio candidates. Upper right box. W e independently trained a first version of the SVD system (based on Con vNet) using the training set of a ground truth labeled dataset as provided by the Jamendo [20] or Medle yDB [6] datasets. W e call this first version the teacher . Upper middle part. This teacher is then applied on each audio candidate to predict ˆ p ( t ) . Lower left box. W e measure the distance between av s ( t ) and ˆ p ( t ) using our cross-correlation method. It allows us to find the best audio candidate for an annotation file and the best alignment parameters ˆ f r , ˆ o . Lower middle box. W e select the audio annotation pairs for which N C C ( ˆ o, ˆ f r ) ≥ T corr = 0 . 8 . The set of se- lected audio tracks forms a new training set. Lower right box. This new set is then used to train a ne w SVD systems based on the same CNN architecture. This new version is called the student . T o this end, we need to define the target p to be minimized in the loss L ( p, ˆ p ) . There are three choices: a) we use as target p the predicted value ˆ p giv en right by the teacher (usual teacher -student paradigm). b) we use as tar get p the v alue avs corresponding to the annotations after aligning them using ˆ f r and ˆ o . c) a combination of both, k eeping only these frames for which ˆ p ( t ) = av s ( t ) . Up to now and since the avs have been found more pre- cise than the ˆ p we only in vestigated option b) . W e compare in the following part the results obtained using different teachers and students. 3.4.1 V alidating the teacher -student pardigm In this part, we demonstrate that the students trained on the new training-set actually perform better than the teacher trained on the ground-truth label dataset. Ground-truth datasets: W e use two ground-truth labels datasets: Jamendo [20] and MedleyDB [6]. W e created a third dataset by merging J amendo and Medle yDB named as J+M . Each dataset is split into a train and a test part us- ing an artist filter (the same artist cannot appear in both). T eachers: W ith each ground-truth datasets we trained a teacher using only the training part. Once trained, each teacher is used to select the audio matches as described in Section 3.3. As a result, we produce three new train- ing sets. They contains 2440, 2673 and 1596 items for the teacher J+M , Jamendo and MedleyDB respecti vely . The intersection of the three sets (not presented here) in- dicates that 89.8 % of the tracks selected using the Med- le yDB teacher are also present within the tracks selected using the J+M teacher or the Jamendo teacher . Also, 91.4 % of the tracks selected using the J amendo teacher are within the tracks selected using the J+M teacher . It means that the three teachers agree most of the time on selecting the audio candidates. Students: W e train three students using the audio and the av s value of the new training sets. Even if there is a large audio files overlap within the training sets, their alignment (and therefore the av s value) is different. The reason to this is that each teacher gets a different ˆ p which results in different ˆ f r , ˆ o v alues. 3.4.2 Results W e ev aluate the performances of the various teachers and students SVD systems using the test parts of J a- mendo (J test) and MedleyDB (M test). W e measure the quality of each SVD system using the frame accuracy i.e. av erage value ov er all the tracks of the test set. Results are indicated in T able 2. In this table, e.g. “Stu- dent (T eacher J train) (2673)” refers to the student trained on the 2673 audio candidates and the avs values computed with the T eacher trained on J amendo train set. T able 2 : Performances of the teachers and students using the various datasets. Number of tracks in brackets. SVD system T est set J test (16) M test (36) T eacher J train (61) 87% 82% Student (T eacher J train) (2673) 82% 82% T eacher M train (98) 76% 85% Student (T eacher M train) (1596) 80% 84% T eacher J+M train (159) 82% 82% Student (teacher J+M train) (2440) 86% 87% Perf ormance of the teachers. W e first test the teachers. T eacher J train obtains the best results on J test (87%). T eacher M train obtains the best results on M test (85%). In both cases, since training and testing are performed on two parts of the same dataset, they share similar audio characteristics. These results are artificially high. T o best demonstrate the generalization of the trained SVD sys- tems, we need to test them in a cross-dataset scenario, namely train and test in different datasets. Indeed, in this scenario the results are quite differ- ent. Applying T eacher J train on M test the results de- creases do wn to 82% (a 5% drop). Similarly when apply- ing T eacher M train on J test the results decreases down to 76% (a 9% drop). Consequently , we can say that the teachers do not generalize very well. Lastly , the T eacher J+M train trained on J+M train actually performs worse on both J test (82%) and M test (82%) than their non-joined teacher (87% and 85%). These results are surprising and remain unexplained. Perf ormance of the students. W e now test the students. It is important to note that students are always ev aluated in a cross-dataset scenario since the D ALI dataset (on which they hav e been trained) does not contain any track from J amendo or MedleyDB . Hence, there is no possible over - fitting for those. Our hypothesis is that students achieve better the results than the teachers because they have seen more data. Especially , we assume that their generalization to unseen data will be better . This is true for the performances obtained with the stu- dent based on T eacher M train . When applied to J test, it reaches 80% which is higher than the performances of the T eacher M train directly (76%). This is also true for the performances computed with the student based on T eacher J+M train . When applied either to J test or M test, it reaches 86.5% (86% on J amendo and 86% on Medle yDB ) which is abov e the T eacher J+M train (82%). Also, 86.5% is similar or abov e the results obtained with T eacher J train on J test (87%) and T eacher M train on M test (85%). This is a very interesting result that demonstrates the generaliza- tion of the student system whiche ver data-set it is applied to. The student based on T eacher J+M train is the one used for defining the final 5358 songs of the D ALI dataset. Howe ver , the performances obtained with the student based on T eacher J train applied to M test (82%) do not improv e over the direct use of the T eacher J train (82%). On alignment. Not explained in this paper is the fact that the ˆ f r and ˆ o v alues computed with the students are much better (almost perfect) than the ones obtained with the teacher . Howe ver , we cannot measure it precisely since D ALI dataset does not have ground-truth label annota- tions to that end. Indeed, the goal of this paper is exactly to obtain such annotations automatically . 4. SINGING V OICE D A T ASET : A CCESS The DALI dataset can be do wnloaded at https://github. com/gabolsgabs/DALI . There, we pro vide the detailed de- sciption of the dataset as well as all the necessary informa- tion for using it. DALI is presented under the recommen- dation made by [19] for the description of MIR corpora. The current v ersion of D ALI is 1.0. Future updates will be detailed in the website. 5. CONCLUSION AND FUTURE WORKS In this paper we introduced D ALI, a large and rich mul- timodal dataset containing 5358 audio tracks with their time-aligned vocal melody notes and lyrics at four lev els of granularity . W e explained our methodology where dataset cre- ation and learning models interact using a teacher-student paradigm benefiting one-another . From manual karaoke user annotations of time-aligned lyrics and notes, we found a set of matching audio candidates from the W eb . T o se- lect and align the best candidate, we compare the annotated vocal sequence (corresponding to the lyrics) to the singing voice probability (obtained with a Con vNet). T o improve the latter (and therefore obtain a better selection and align- ment) we applied a teacher-student paradigm. Through an experiment, we prov ed that the students outperform the teachers notably in a cross-dataset scenario, when train-set and test-set are from different datasets. It is important to note that the results of the students are higher than the teacher ones, ev en if they have been train- ing on imperfect data. In our case, we showed that, in the context of deep learning, it is better to have imperfect but large dataset rather than small and perfect ones. Howe ver , other works went in the opposite direction [1]. Future work. W e have only performed the teacher- student iteration once. In next works will use the results of the first student generations to train a second student generations. This will define a new D ALI dataset. W e plan to quantitati ve measure the quality of ˆ o, ˆ f r and to continue exploring the alignments between note annotations and the audio. Currently , we trained our student using as tar get p = av s , which do not transfer directly the knowledge of the teacher . W e will explore other possibilities of knowl- edge transfer using other targets (points a) and c) in Section 3.4) as well as the local problems describe at Section 3.1. Acknowledgement. This research has receiv ed fund- ing from the French National Research Agency under the contract ANR-16-CE23-0017-01 (W ASABI project). 6. REFERENCES [1] Xavier Amatriain. ”in machine learning, is more data always better than better algorithms?”. https:// bit.ly/2seQzj9 . [2] A. Ashok, N. Rhinehart, F . Beainy , and K. M. Kitani. N2N learning: Netw ork to network compression via policy gradient reinforcement learning. CoRR , 2017. [3] K. Benzi, M. Defferrard, P . V andergheynst, and X. Bresson. FMA: A dataset for music analysis. CoRR , abs/1612.01840, 2016. [4] A. Berenzweig, D. P . W . Ellis, and S. Lawrence. Us- ing voice segments to improve artist classification of music. In AES 22 , 2002. [5] A. L. Berenzweig and D. P . W . Ellis. Locating singing voice segments within music signals. In W ASP AA , pages 119–122, 2001. [6] R. Bittner , J. Salamon, M. T ierney , M. Mauch, C. Can- nam, and J. Bello. Medleydb: A multitrack dataset for annotation-intensiv e mir research. In ISMIR , 2014. [7] A. Cont, D. Schwarz, N. Schnell, and C. Raphael. Eval- uation of Real-T ime Audio-to-Score Alignment. In IS- MIR , V ienna, Austria, 2007. [8] J. Cui, B. Kingsbury , B. Ramabhadran, G. Saon, T . Sercu, K. Audhkhasi, A. Sethy , M. Nussbaum- Thom, and A. Rosenberg. Knowledge distillation across ensembles of multilingual models for low- resource languages. In ICASSP , 2017. [9] E. Fonseca, J. Pons, X. Fa vory , F . Font, D. Bog- danov , A. Ferraro, S. Oramas, A. Porter , and X. Serra. Freesound datasets: A platform for the creation of open audio datasets. In ISMIR , Suzhou, China, 2017. [10] H. Fujihara and M. Goto. L yrics-to-Audio Alignment and its Application. In Multimodal Music Pr ocess- ing , volume 3 of Dagstuhl F ollow-Ups , pages 23–36. Dagstuhl, Germany , 2012. [11] H. Fujihara, M. Goto, J. Ogata, and H. G. Okuno. L yricsynchronizer: Automatic synchronization system between musical audio signals and lyrics. 5(6):1252– 1261, 2011. [12] M. Goto. Singing information processing. In ICSP , pages 2431–2438, 2014. [13] E. J. Humphrey , N. Montecchio, R. Bittner , A. Jansson, and T . Jehan. Mining labeled data from web-scale col- lections for vocal activity detection in music. In ISMIR , 2017. [14] S. Leglai ve, R. Hennequin, and R. Badeau. Singing voice detection with deep recurrent neural networks. In IEEE, editor, ICASSP , pages 121–125, Brisbane, Aus- tralia, 2015. [15] B. Lehner , G. Widmer , and S. Bock. A lo w-latency , real-time-capable singing voice detection method with lstm recurrent neural networks. In 2015 23rd Eur opean Signal Pr ocessing Confer ence (EUSIPCO) , 2015. [16] M. Mauch, H. Fujihara, K. Y oshii, and M. Goto. T im- bre and melody features for the recognition of vocal activity and instrumental solos in polyphonic music. In ISMIR 2011 , pages 233–238, 2011. [17] A. Mesaros. Singing voice identification and lyrics transcription for music information retriev al invited pa- per . In 7th Confer ence on Speech T echnology and Hu- man - Computer Dialogue (SpeD) , pages 1–10, 2013. [18] G. Meseguer -Brocal, G. Peeters, G. Pellerin, M. Buffa, E. Cabrio, C. Faron Zucker , A. Giboin, I. Mirbel, R. Hennequin, M. Moussallam, F . Piccoli, and T . Fil- lon. W ASABI: a T wo Million Song Database Project with Audio and Cultural Metadata plus W ebAudio en- hanced Client Applications. In W eb Audio Conf. , Lon- don, U.K., 2017. Queen Mary Univ ersity of London. [19] G. Peeters and K. Fort. T ow ards a (better) Definition of Annotated MIR Corpora. In ISMIR , Porto, Portug al, 2012. [20] M. Ramona, G. Richard, and B. David. V ocal detec- tion in music with support vector machines. In Pr oc. ICASSP ’08 , 2008. [21] L. Regnier and G. Peeters. Singing V oice Detection in Music T racks using Direct V oice V ibrato Detection. In ICASSP , page 1, taipei, T aiwan, 2009. [22] J. Salamon and E. G ´ omez. Melody extraction from polyphonic music signals using pitch contour char- acteristics. IEEE T ransactions on Audio, Speec h and Language Pr ocessing , 20:1759–1770, 2012. [23] J. Schl ¨ uter . Learning to pinpoint singing voice from weakly labeled e xamples. In ISMIR , New Y ork City , USA, 2016. ISMIR. [24] J. Schl ¨ uter and T . Grill. Exploring Data Augmenta- tion for Impro ved Singing V oice Detection with Neural Networks. In ISMIR 2015 , Malaga, Spain, 2015. [25] A. J. R. Simpson, G. Roma, and M. D. Plumb- ley . Deep karaoke: Extracting vocals from musical mixtures using a con volutional deep neural network. abs/1504.04658, 2015. [26] F . Soulez, X. Rodet, and D. Schwarz. Improving poly- phonic and poly-instrumental music to score align- ment. In ISMIR , page 6, Baltimore, United States, 2003. [27] S. W atanabe, T . Hori, J. Le Roux, and J. Hershey . Student-teacher network learning with enhanced fea- tures. In ICASSP , pages 5275–5279, 2017. [28] C. W u and A. Lerch. Automatic drum transcription us- ing the student-teacher learning paradigm with unla- beled music data. In ISMIR , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment