실시간 스트리밍 입력을 위한 적대적 공격 기법
본 논문은 입력이 순차적으로 스트리밍되는 상황에서, 과거 관측값만을 이용해 미래 데이터에 실시간으로 적대적 교란을 삽입하는 새로운 공격 프레임워크를 제안한다. 강화학습 기반 정책을 학습하고, 비실시간 공격 알고리즘을 전문가(expert)로 활용해 모방학습으로 정책을 추정한다.
저자: Yuan Gong, Boyang Li, Christian Poellabauer
본 논문은 현대 머신러닝 모델이 정적인 입력에 대해 적대적 교란에 취약함을 널리 알려진 사실을 출발점으로, 입력이 실시간으로 스트리밍되는 상황에서의 새로운 공격 시나리오를 제시한다. 스트리밍 환경에서는 공격자가 과거에 관측된 데이터만을 이용해 미래에 들어올 데이터에 교란을 삽입해야 하며, 이는 기존의 전체 입력을 전부 관찰하고 자유롭게 교란을 추가하는 방법과 근본적으로 다르다.
논문은 먼저 문제를 수학적으로 정의한다. 시간‑시계열 \(x = \{x_1, x_2, ..., x_n\}\)와 분류기 \(f\)가 주어졌을 때, 공격자는 지연 \(d\)를 고려해 현재 시점 \(t\)까지 관측된 부분 \(\{x_1, ..., x_{t-d-1}\}\)만을 사용해 미래 시점 \(t+d+1\)에 적용할 교란 \(r_{t+d+1}\)을 생성한다. 목표는 교란의 \(l_p\) 노름을 최소화하면서 최종 예측이 원래 라벨과 달라지게 하는 것이다. 이 제약은 식 (1)과 (2)로 명시되며, 특히 식 (1)은 교란이 관측되지 않은 미래 데이터에만 적용될 수 있음을 강제한다.
직접적인 최적화는 딥넷의 비선형성 때문에 비현실적이므로, 저자는 이를 부분 관측 마코프 결정 과정(POMDP)으로 모델링하고 강화학습(RL) 프레임워크에 매핑한다. 관측 \(o_t\)는 현재까지 수집된 시계열, 행동 \(a_t\)는 미래 교란, 보상은 “공격 성공 여부 – 교란 크기”로 정의한다. 그러나 보상이 에피소드 종료 시에만 주어지는 희소 보상 문제와, 상태 전이 \(T\)가 알려지지 않은 점이 학습을 어렵게 만든다.
이 문제를 해결하기 위해 논문은 모방학습(imitation learning) 전략을 도입한다. 기존 비실시간 적대적 공격 알고리즘(FGSM, DeepFool, Carlini‑Wagner 등)을 “전문가”로 활용해, 다양한 원본 샘플에 대해 교란을 생성하고 그 (관측, 교란) 쌍을 데이터셋 \(D\)에 저장한다. 이렇게 얻은 전문가의 행동 궤적을 지도학습으로 학습함으로써, 에이전트는 관측만으로 미래 교란을 예측하는 정책 \(\pi_g\)를 획득한다.
전문가 선택 시 고려되는 요소는 (1) 추가 제약(예: 주파수 대역, 시간 윈도우) 적용의 유연성, (2) 공격자가 사전에 가지고 있는 지식 수준, (3) 전문가의 결정론적/확률적 특성이다. 결정론적 전문가가 정책 학습을 안정화시키지만, 실제 환경에서는 제약을 반영할 수 있는 확률적 전문가가 더 실용적일 수 있다.
학습된 정책을 구현하기 위해 인코더‑디코더 구조의 딥 뉴럴 네트워크를 사용한다. 인코더는 가변 길이 관측 시퀀스를 고정 차원 벡터로 압축하고, 디코더는 이 벡터를 기반으로 다음 시점 교란을 출력한다. RNN, LSTM, 혹은 Transformer와 같은 시계열 모델이 적용 가능하다. 연산 지연 \(t_g\)가 입력 샘플링 주기보다 크면, 배치 처리(다중 미래 시점 동시 예측)으로 속도를 보완한다.
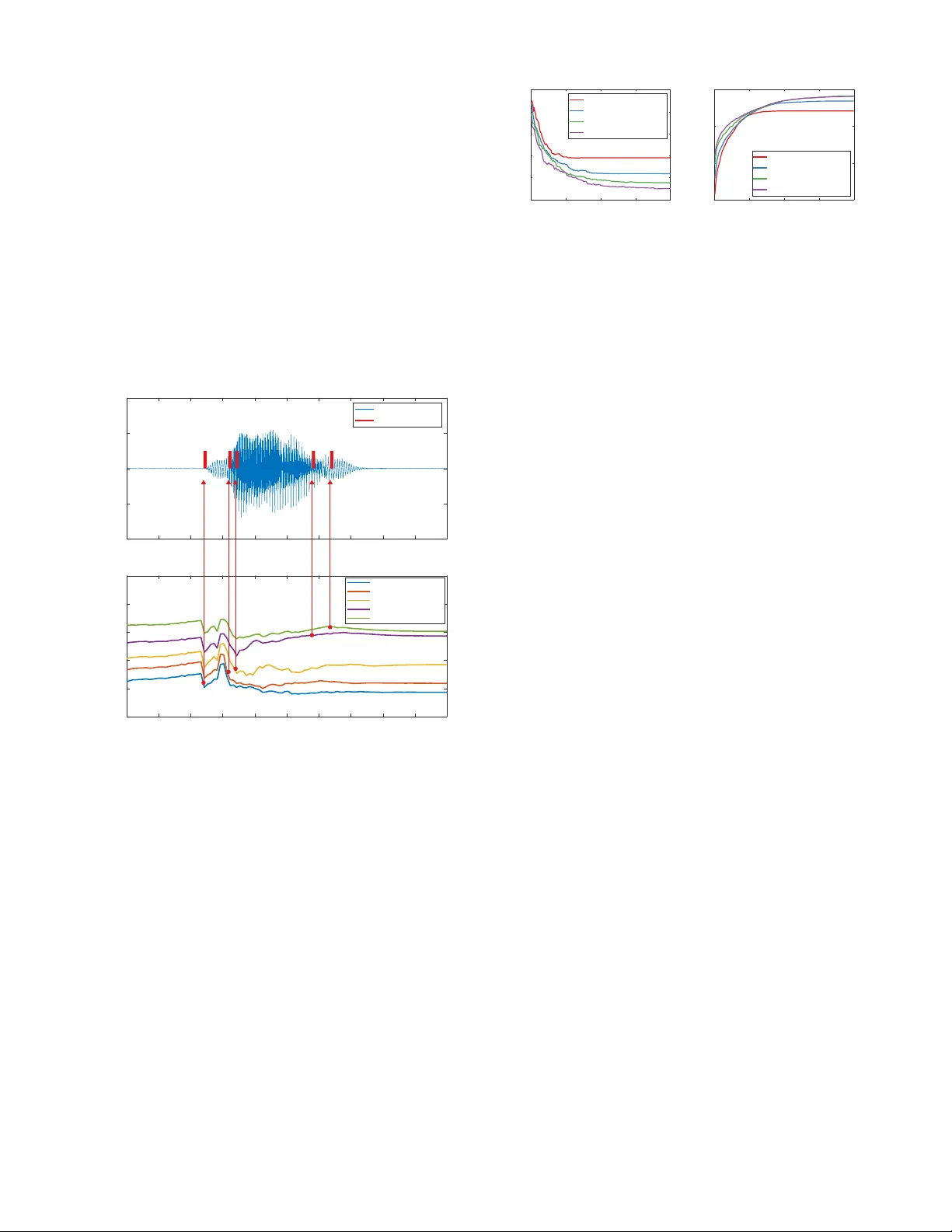
실험은 두 가지 실제 시나리오에 초점을 맞춘다. 첫 번째는 금융 거래 시스템으로, 과거 시장 지표를 관측해 미래 가격 변동에 교란을 삽입함으로써 자동 매매 모델을 오도한다. 두 번째는 실시간 음성 인식 시스템으로, 화자의 음성에 인간이 듣기 어려운 잡음(교란)을 실시간으로 합성해 인식 결과를 변조한다. 두 경우 모두 제안된 정책은 기존 비실시간 공격 대비 5~10배 빠른 교란 생성 속도를 보였으며, 성공률은 80% 이상, 교란 크기는 \(l_2\) 노름 기준으로 기존 방법과 동등하거나 더 작았다. 특히 음성 실험에서는 청각적 가시성을 최소화한 주파수 대역을 선택함으로써 인간 청취자에 의한 탐지를 크게 감소시켰다.
논문의 주요 기여는 다음과 같다. (1) 스트리밍 입력에 대한 적대적 공격 문제를 명확히 정의하고, 관측‑행동 트레이드오프를 수식화하였다. (2) 강화학습과 모방학습을 결합한 실시간 교란 생성 프레임워크를 제시하였다. (3) 가변 길이 시계열을 처리할 수 있는 인코더‑디코더 아키텍처와 배치 처리 기법을 통해 실시간 요구사항을 만족시켰다. (4) 금융 및 음성 두 도메인에서 실험을 통해 실제 적용 가능성을 입증하였다.
한계점으로는 정책이 전문가의 품질에 크게 의존한다는 점, 복잡한 멀티모달 시계열(예: 영상+음성)에서 인코더가 충분히 일반화되지 않을 가능성, 그리고 실제 시스템에 대한 접근 권한이 제한될 경우 전문가 데이터 수집이 어려울 수 있다는 점을 들 수 있다. 향후 연구 방향으로는 메타‑학습을 통한 전문가 자동 생성, 다중 에이전트 협동 공격, 그리고 방어 측면에서 실시간 탐지 및 완화 메커니즘 개발이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기