Real-Time Adversarial Attacks
In recent years, many efforts have demonstrated that modern machine learning algorithms are vulnerable to adversarial attacks, where small, but carefully crafted, perturbations on the input can make them fail. While these attack methods are very effe…
Authors: Yuan Gong, Boyang Li, Christian Poellabauer
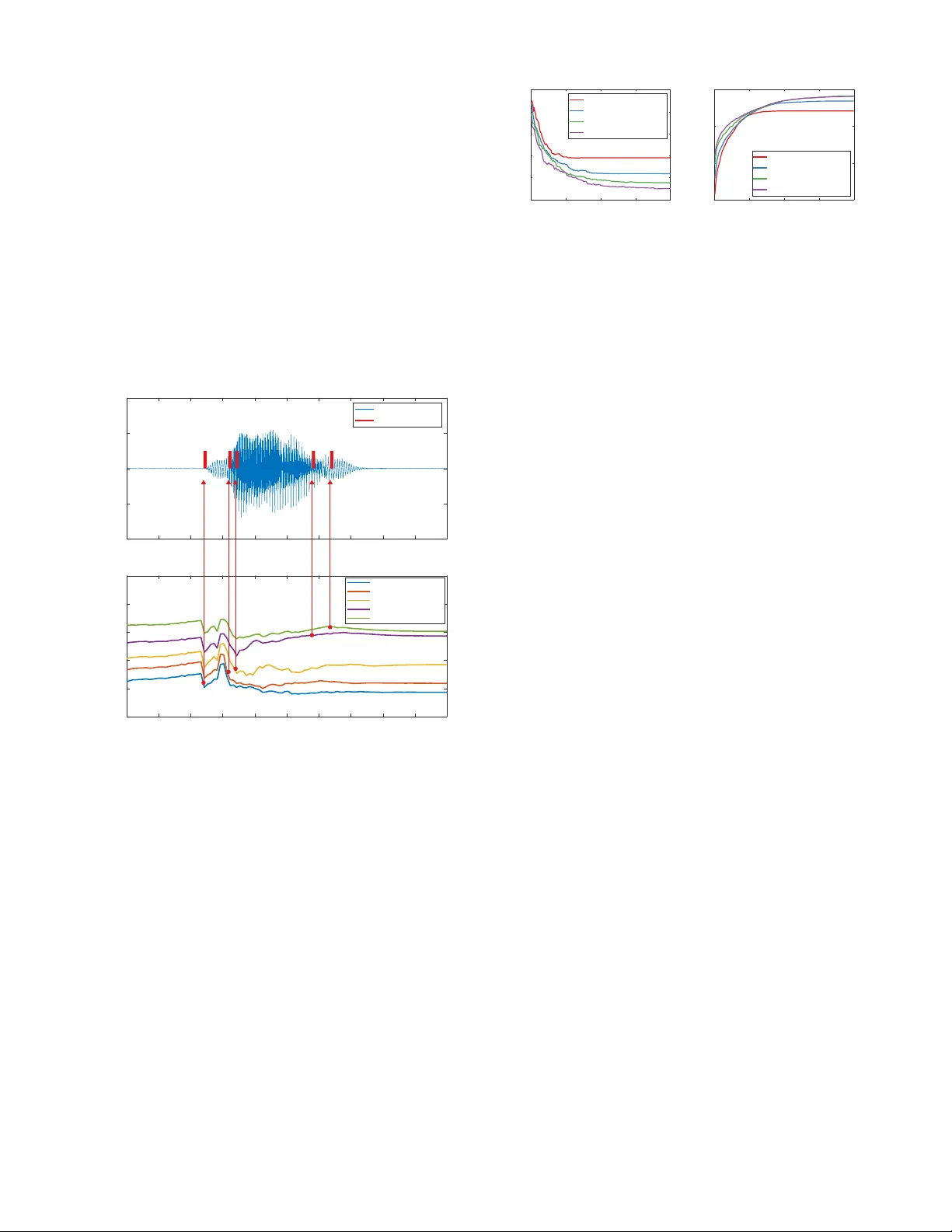
Real-T ime Adversarial Attacks Y uan Gong , Boyang Li , Christian Poellabauer and Y iyu Shi Uni versity of Notre Dame { ygong1, bli1, cpoellab, yshi4 } @nd.edu Abstract In recent years, many ef forts ha ve demonstrated that modern machine learning algorithms are vul- nerable to adversarial attacks, where small, but carefully crafted, perturbations on the input can make them fail. While these attack methods are very ef fecti v e, they only focus on scenarios where the target model takes static input, i.e., an at- tacker can observe the entire original sample and then add a perturbation at any point of the sample. These attack approaches are not applicable to situ- ations where the target model takes streaming in- put, i.e., an attacker is only able to observe past data points and add perturbations to the remaining (un- observed) data points of the input. In this paper, we propose a real-time adversarial attack scheme for machine learning models with streaming inputs. 1 Introduction Over the last decade, machine learning has made great ad- vances and has been widely adopted for many div erse ap- plications, including security-sensitive applications such as identity verification and fraud detection. Howe ver , recent re- search has also shown that many machine learning algorithms (specifically deep neural networks) are vulnerable to adver- sarial attacks , where small, b ut carefully designed, perturba- tions are added to original samples, leading the target model to make wrong predictions [ Szegedy et al. , 2013 ] . Such ad- versarial attack algorithms hav e been proposed for a vari- ety of tasks, such as image recognition, speech processing, text classification, and malware detection, where they have also been shown to be highly ef fecti ve [ Moosavi-Dezfooli et al. , 2016; Cisse et al. , 2017; Gong and Poellabauer , 2017; Alzantot et al. , 2018; Carlini and W agner , 2018; Sch ¨ onherr et al. , 2018; Ebrahimi et al. , 2017; Grosse et al. , 2017 ] . Most existing adversarial example generation algorithms require that the entire original data sample that is fed into the target model is observed and that any part of the sample can then be modified. For example, speech adversarial attack algorithms typically design a perturbation for a gi v en speech sample, add the perturbation to the original sample, and then feed the resulting sample into the target speech recognition + Stre am ing I nput Uno bserved Data Obs er ved Data Target System Perturbaon Re al - me Adversar ial P er turbaon G ene rator x 1 x 2 ... x 3 x t - 2 x t - 1 x t x t+1 x t+2 Enc oder Op onal Fra ming Enc oding Dec oder r t+d+1 ... r t+d r t+d - 1 r 3 r 2 r 1 Connuo u s Pro ce ssing Figure 1: An illustration of the real-time adversarial attack scheme. The target system takes streaming input; only past data points can be observed and adversarial perturbation can only be added to future data points. The adversarial perturbation generator continuously uses observed data to approximate an optimal adversarial perturba- tion for future data points. system. Howe ver , this approach is not al ways feasible, partic- ularly when the tar get system requires str eaming input , where the input is continuously processed as it arrives. In this real- time processing scenario, an attacker can only observe past parts of the data sample and can only add perturbations to future parts of the data sample, while the decision of the target model will be based on the entire data sample. A few concrete scenarios that operate this way are as follo ws: Financial T rading Systems. Financial institutions make trading decisions using automatic machine learning algo- rithms based on a sequence of observations of some market conditions (e.g., variations in the stock index). An attacker may influence the trading model’ s outcomes by carefully per- turbing the corresponding market conditions. Howe ver , while the target trading model usually makes decisions based on a long sequence of observations, the attacker cannot change any historical data. Instead, the attack can only add pertur- bations to future (yet to be observed) market conditions, e.g., using market manipulations. Real-time Speech Processing Systems. Machine learn- ing based real-time speech processing systems (e.g., speech recognition and automatic translation systems) have been adopted widely , including many security-sensitiv e applica- tions. An attacker may want to change the output of such systems by playing a carefully designed noise that is un- noticeable by the human ear, but will be superimposed on the speech generated by a human speaker through the air . The attacker can only design such noise signals based on past speech signals and superimpose the noise only on fu- ture speech signals, while the speech processing system will perform its task using the entire speech segment (e.g., a w ord or a sentence). When attacking a real-time system, the attacker faces a trade-off between observation and action space . That is, as- sume that the target system takes a sequential input x , the attacker could choose to design adversarial perturbations at the beginning. Howe v er , in this case, the attacker does not hav e any observation of x , but perturbations can be added to any time point of x , i.e., the attacker has minimum observa- tion and maximum action space . In contrast, if the attacker chooses to add adversarial perturbations at the end, the at- tacker has a full observation of x , but cannot add perturba- tions to the data (i.e., the attacker has maximum observation , but minimum action space ). In the first case, it is hard to find an optimal perturbation for x without having any observa- tions, while in the second case, the attack cannot be imple- mented at all. T o address this dilemma, we propose a new attack scheme that continuously uses observed data to ap- proximate an optimal adversarial perturbation for future time points using a deep reinforcement learning architecture (illus- trated in Figure 1). In this paper , we refer to such attacks as real-time adversarial attacks . T o the best of our kno wledge, this is the first study of dynamic real-time adversarial attacks, which have not yet receiv ed the attention they deserve. The closest related concept is universal adversarial perturbation , presented in [ Moosavi-Dezfooli et al. , 2017; Li et al. , 2018; Neekhara et al. , 2019 ] , where the authors design a fixed ad- versarial perturbation that is ef fecti ve for different samples. The main difference to our work is that the universal adver- sarial perturbation is b uilt offline and does not take advantage of observations in real-time to further improve the perturba- tion for a specific target input. 2 Real-time Adversarial Attacks 2.1 Problem Formalization Let x = { x 1 , x 2 , x 3 , ..., x n } ∈ R m × n denote an n -point time-series data sample, where each point x i ∈ R m ; f : R m × n − → { 1 . . . k } is a classifier mapping the time-series sample x to a discrete label set. The goal of the attacker is to design a real-time adversarial perturbation generator g ( · ) that continuously uses observed data { x 1 , x 2 , ..., x t } to approxi- mate an optimal adversarial perturbation r t + d +1 for a future time point t + d + 1 , where d is the delay caused by processing the data or emitting the adversarial perturbation. That is, r t = g ( { x 1 , x 2 , ..., x t − d − 1 } ) d + 1 < t ≤ n 0 else (1) W e define a metric m ( · ) to measure the perceptibility of the adversarial perturbation; a common choice for m is the induced metric of l p ( p ∈ { 0 , 1 , 2 , inf } ) norm. W e then aim to solve the following optimization problem for non-targeted adversarial attacks: minimize m ( r = { r 1 , r 2 , ..., r n } ) s.t. f ( x + r ) 6 = f ( x ) (2) Equation 1 implies the constraint that adversarial perturba- tion is crafted only based on the observed part of the data sample and can only be applied to the unobserved part of the data sample. Equation 2 implies that the attacker wants to make the perturbation as imperceptible as possible on the premise that the attack succeeds. Even without the con- straint of Equation 1, directly solving Equation 2 is usually intractable when f is a deep neural network due to its non- con v exity . Nev ertheless, previous efforts hav e found effecti v e approximation methods such as the fast gradient sign method (FGSM) [ Goodfellow et al. , 2014 ] , DeepF ool [ Moosavi- Dezfooli et al. , 2016 ] , and the algorithm proposed in [ Car- lini and W agner , 2018 ] . Ho we v er , all these methods require full observation and the freedom of changing any point of the original data sample, and therefore these methods are not compatible with the constraint imposed by Equation 1. Alternativ ely , a more natural way of describing this prob- lem is to view the adversarial perturbation generator as an agent and model the problem as a partially observable de- cision pr ocess problem, i.e., the generator continuously ob- serves the streaming data and makes a sequence of decisions of how to make the perturbation. This formalism is equiva- lent to Equations 1 and 2, b ut allo ws us to use the many tools av ailable for reinforcement learning (RL) [ Sutton et al. , 1998 ] to solve the problem. Then, the problem can be described us- ing a tuple h O , S, A, T , R i , where: 1. Observation O : o t = { x 1 , x 2 , ..., x t } . 2. State S : unobservable hidden state. 3. Action A : a t = r t + d +1 , i.e., adding the perturbation to the original sample at time t + d + 1 . 4. T ransition T : unknown. 5. Reward R : I f ( x + r ) 6 = f ( x ) − m ( r ) . This means that the attacker performs an action a t to emit the perturbation valued r t + d +1 at t + d + 1 based on the ob- servation o t , which will change the internal hidden state ac- cording to an unknown transition rule (e.g., the state can be the attack success probability , and an action could make it in- crease or decrease). The adversarial generator will only get the reward at the end. The goal of RL is to learn an optimal policy π g : a t = g ( o t ) that maximizes the expectation of the rew ard. In this problem, the en vironment is the target model f , and the input data distribution P x . 2.2 Adversarial Attacks Using Reinfor cement Learning As discussed in the previous section, real-time adversarial at- tacks can be described as reinforcement learning problems, which are usually solved by using deep neural networks (DNNs). RL-DNN based adversarial attacks and conv en- tional optimization based adversarial attacks (e.g., FGSM and DeepFool) differ in that the former treats the original exam- ple and the corresponding adversarial perturbation as the in- put and output of an unknown nonlinear mapping and then use a DNN to approximate it, i.e., use learning to substitute optimization . In geometric terms, the attack model is trying to predict the direction that pushes the original example x out of the correct decision region using the shortest distance. x 1 x 2 E s ti m a ted Gr o u n d - T r u th x 1 x 2 Est i m a ted Gr o u n d - T r u th R 1 R 2 C 2 C 1 Figure 2: A low dimensional illustration of how the attack model predicts perturbations for future data points based on already ob- served data points. The attacker is trying to push the original data samples (shown as solid dots) from the decision region R 1 to R 2 . W ithout observ ation of x 1 , the attack er indeed has no idea about the optimal perturbation direction on x 2 , but after observing x 1 , the at- tacker knows the optimal perturbation direction on x 2 , i.e., up if x is in cluster C 1 and down if x is in cluster C 2 . A challenge for the attack model is to “forecast” future per- turbations on yet unobserved data. Ho we v er , this is feasible since, giv en a specific machine learning task, the input sam- ple, although yet unobserved, will obey some fixed distribu- tion (e.g., distribution of natural speech), and there usually exist dependencies among the data points of the data sample, which can be used to forecast some characteristics of future data points based on already observ ed data points. W e expect that such characteristics contain information that can be used to estimate an optimal perturbation for future points, which is illustrated in Figure 2. Further , another challenge of using RL to implement real- time adversarial attacks is the sparse r ewar ds pr oblem , i.e., the agent only receiv es the reward at the end and it is dif ficult to obtain an estimation of the re ward at each time point based on the observed data and past actions. For example, estimat- ing the expected re w ard at a time point simply based on feed- ing the observed (partial) input at that time, superimposed with the corresponding perturbation, into the target model f (if accessible) and using the classification confidence to cal- culate the re ward will not yield reliable results, because the model’ s prediction is not reliable when only partial input is giv en. In fact, although there ha v e been man y ef forts to solve the sparse rew ard problem, many tasks still suffer from high computational ov erhead and training instability . Howe ver , for the adversarial example crafting problem, we could generate many trajectories of observ ation-action pairs using state-of- the-art non-real-time adversarial generation algorithms. This naturally leads us to use an imitation learning and behavior cloning [ Atkeson and Schaal, 1997 ] strategy to o vercome the sparse re ward problem. W e discuss it in the following section. 2.3 Imitation Learning Strategy Imitation learning is an RL technique that learns an optimal policy π g by imitating the behavior of an expert. Specifi- cally , imitation learning requires a set of decision trajecto- ries { τ 1 , τ 2 , ... } generated by an expert, where each deci- sion trajectory consists of a sequence of “observ ation-action” pairs, i.e., τ i = h o i 1 , a i 1 , o i 2 , a i 2 , ..., o i n , a i n i . Such trajectories serve as demonstrations to teach the agent how to behave giv en an observation. W e can extract all expert observation- action pairs from the trajectories and form a new dataset D = { ( o 1 1 , a 1 1 ) , ( o 1 2 , a 1 2 ) , ..., ( o 1 n , a 1 n ) , ( o 2 1 , a 2 1 ) , ( o 2 2 , a 2 2 ) , ... } . By treating o as the input feature and a as the output label, we could learn π g : a t = g ( o t ) in a supervised learning man- ner using traditional algorithms. Specifically for the adversarial example crafting problem, we can use state-of-the-art non-real-time attack models to generate “sample-perturbation” pairs h ( x 1 , r 1 ) , ( x 2 , r 2 ) , ... i as decision trajectories by feeding different original samples x i and collecting the corresponding output perturbations r i . Here, both x i and r i consist of a sequence of x and r , using the definition of observation o and action a in Section 2.1. W e can con v ert each x and r to o and a , and then build a training set D and use supervised learning to learn π g . Choice of Expert W e use a state-of-the-art non-real-time adversarial example crafting technique as the expert. Over the last few years, many ne w attack techniques hav e been dev eloped and sho wn to be ef fectiv e. These techniques can be roughly classified into two categories. The first category includes gradient- based methods such as FGSM, DeepFool, and the method presented in [ Carlini and W agner , 2018 ] ; these are typically based on deterministic optimization algorithms. The second category consists of gradient-free methods such as the meth- ods presented in [ Alzantot et al. , 2018; Su et al. , 2019 ] ; these are typically based on stochastic optimization algorithms. Which method works better as an expert depends not only on the attack success rate; other important criteria include: 1. Flexibility of adding additional constraints. There are two reasons why we prefer an expert that provides some flexibility of adding additional constraints besides making the perturbation imperceptible. First, we ultimately need to learn π g from the trajectories generated by the expert using some supervised learning method, which inevitably will contain some error . W e can add some regularization on the trajecto- ries (e.g., perturb only after a specific time point) to simplify the supervised learning task, which requires additional con- straints on the expert. Second, in realistic attack scenarios, the attacker usually faces additional constraints, e.g., when an attacker attempts to fool a speech recognition system by playing the perturbation over the air using a speaker , the fre- quency range of the perturbation is subject to the characteris- tics of the speaker . In general, stochastic optimization algo- rithms are more flexible than deterministic optimization algo- rithms for adding additional complex constraints. 2. Attacker’s knowledge. The attacker’ s kno wledge re- quired for the proposed real-time adversarial attack follows exactly the chosen expert policy . Hence, the attacker should choose the expert polic y according to the attack scenario. 3. Determinism of the expert. While state-of-the-art ad- versarial example crafting approaches are highly effecti v e in terms of success rate, there is no guarantee that the gener - ated perturbation is globally optimal. Specifically , perturba- tions generated for the same input sample using a stochastic optimizing algorithm can vary with the random seed since the optimization solutions might stop at different sub-optimal points, which will make the mapping o 7→ a ill-defined and increase the difficulty of training π g . Therefore, a determin- istic expert is preferred. x 1 x 2 o t ... x 3 x t - 2 x t - 1 x t x t+ 1 x t+2 E n c od er E n c odi ng Dec oder a t ... a t - 1 a t - 2 a 3 a 2 a 1 Figure 3: Illustration of the training process. Note that the output action only depends on the current observation o t . Computational Overhead and Speed Existing adversarial example crafting techniques can be com- putationally expensiv e due to the complexity of optimiza- tion, e.g., the method in [ Carlini and W agner , 2018 ] requires about one hour to craft a single speech adversarial example. Stochastic optimization algorithms typically need to call the target model (or the substitute model) hundreds or thousands of times to find the solution. Howe ver , since we use a deep neural network g to substitute optimization, no matter which expert we choose to imitate, the computational ov erhead for generating an adversarial perturbation for one time point is fixed to be the inference time of g (denoted by t g , which is the computational delay). In the real-time scenario, if the in- put sample frequency is higher than 1 t g , then the generator is not fast enough to catch up with the streaming input. The attacker then needs to lo wer the update frequenc y by modify- ing g to do batch processing, i.e., generate a batch of n batch actions for n batch future points in one inference, which could lower the delay requirement by n batch times. 2.4 Implementation Once we form the dataset D = { ( o 1 , a 1 ) , ( o 2 , a 2 ) , ... } con- sisting of observation-action pairs from the expert’ s decision trajectory , we form the real-time adversarial generator g as a deep neural network and learn from the dataset. Note that each input o is a sequence of variable length; so it is natural to use a recurrent neural netw ork as part of the network. Specif- ically , the neural network can be divided into two parts: the encoder and the decoder . The encoder is a recurrent neural network that maps a v ariable length input into a fixed dimen- sional encoding. W e expect that the learned encoding con- tains useful features from o ; the decoder then makes the deci- sion of the action, e.g., in the example in Figure 2, we expect that the encoding expresses which cluster the data sample be- longs to, and the decoder can find the optimal perturbation based on this information. W e can then calculate the error between the predicted action and the ground truth action and use standard back-propagation to update g . Assume that we hav e n t trajectories and each trajectory consists of n observ ation-action pairs. The dataset has n × n t samples, which can be very large and will make the training slow . In fact, observations from the same trajectory are highly dependent, i.e., the only difference between o t +1 and o t is that o t +1 has one more observed point x t +1 ; therefore there will be a lot of repetitiv e computation of the recurrent neural network (i.e., the encoder). In order to expedite the training, we should train observation-action pairs from the same tra- Algorithm 1 Real-time Adversarial Attack Require: Original dataset X = { x i } where each x i = { x i t } Non-real-time adversarial example generator (expert) g e Phase 1: Generate Expert Demonstrations Input: Original sample set X Output: Expert decision trajectory set D 1: initialize D as an empty set 2: for each x i ∈ X do 3: r i = { r i t } = g e ( x i ) 4: initialize trajectory τ i as an empty set 5: for each time point t of x i do 6: o i t = { x i 1 , x i 2 , ...x i t } 7: a i t = r i t + d +1 8: add ( o i t , a i t ) to τ i 9: end for 10: add τ i to D 11: end for 12: retur n D Phase 2: T rain Realtime Adversarial Example Generator Input: Expert decision trajectory set D Output: Real-time adversarial example generator g r 13: initialize g r as a recurrent network with parameter θ 14: for each trajectory τ i ∈ D do maintain RNN states for each t to expedite computing 15: for each time point t do 16: calculate the predicted action ˆ a i t = g r ( o i t ) 17: calculate the loss l between the predicted action ˆ a i t and the expert’ s action a i t 18: update θ to minimize the loss l 19: end for 20: end for 21: retur n g r Phase 3: Conduct Real-time Adversarial Attack Input: Streaming observations o = { o 1 , o 2 , ..., o t , ... } 22: at each time point t do 23: a t = g r ( o t ) 24: ex ecute action a t jectory in a batch, i.e., after obtaining a t from feeding input o t into g , we do not feed a new input o t +1 into g . Instead, we feed x t +1 into g and obtain the output of g as a t +1 . Figure 3 illustrates this training process. Specifically , this approach av oids any repetiti v e encoder computation and can be vie wed as a sequence to sequence training. Note that the predicted actions are only dependent on the current observ ation (i.e., they are not based on any future observations), which is dif- ferent from standard sequence to sequence training used in other applications such as machine translation where the in- termediate encoding contains information of the entire input sample. The pseudocode of the proposed algorithm is shown in Algorithm 1. It is worth mentioning that although in this paper , we focus on using the basic behavior cloning algorithm for simplicity , there are many more advanced algorithms (e.g., Dataset Ag- gregation [ Ross et al. , 2011 ] ) in imitation learning and rein- forcement learning that can further improve the attack perfor- mance, e.g., it is possible to design a remedy mechanism for the real-time adversarial perturbation generator that allows it to adjust its future strategy if it realizes it has pre viously made a wrong decision. Hence, formalizing the real-time attack into a reinforcement learning problem is not only natural, but also allows us to apply e xisting tools and algorithms. 3 Case Study: Attacking a V oice Command Recognition System In the previous section, we introduced the general real-time adversarial attack framew ork in a relatively abstract way; in this section, we further show how to adopt the framework in a realistic task: the audio adversarial attack 1 . 3.1 T arget Model and Attack Scenario The goal is to attack a voice command recognition system based on a con v olutional neural network [ Sainath and P arada, 2015 ] . This model is used as an official example for T ensor- flow 2 , it is easy to reproduce, and has also been used as the target model for attacks in [ Alzantot et al. , 2018 ] . W e train the voice command recognition model exactly as in the im- plementation of the T ensorflow example using the v oice com- mand dataset [ W arden, 2018 ] , except that we only use 80% of the data for training, allowing us to use the other 20% for testing. Most audio samples are of exact 1-second length with a sampling rate of 16 kHz; all other samples are padded to be also of 1 second for consistency . The model can classify ten keyw ords: “yes”, “no”, “up”, “down”, “left”, “right”, “on”, “off ”, “stop”, and “go”. The trained model achiev es 88.7% accuracy on the v alidation set. The proposed real-time scheme can greatly increase the real-world threat of the audio adversarial attack. As illus- trated in Figure 4, compared to previous non-real-time au- dio adversarial attack technologies presented in [ Carlini et al. , 2016; Y akura and Sakuma, 2018; Gong and Poellabauer, 2018; Qin et al. , 2019 ] , the key advantage of the real-time audio adversarial attack scheme is that only by using this scheme the attacker is able to conduct attacks to an on-going session, i.e., an on-going human-computer interaction, and interfere with the voice command currently being spok en by a human speaker . This is because previous non-real-time adver - sarial attack approaches needed a “preparation stage”, where the attacker obtains a complete original speech sample, de- signs specific adversarial perturbations for this sample, and adds a perturbation to the original sample to build a mali- cious adversarial example. Then, in the “attack phase”, the attacker needs to initialize a new session with the target sys- tem and then replay the prepared malicious adversarial exam- ple. The application of such an attack is relati vely limited, because during the attack phase, if the user is near the tar- get system, then no matter how close the malicious sample 1 Code and demos are av ailable at https://github.com/ YuanGongND/realtime- adversarial- attack 2 www.tensorflow.org/tutorials/sequences/ audio_recognition Target Devic e Sp eaker Rec or der Prepara tio n P ha se Aud io Ad ver sarial Ex a m pl e Attack Pha se Physic al En vir onm ent Rea l - time Att ack Device Target Devic e Sp eec h Sig nal ( B ) Real - time Aud io Adv er s aria l Atta ck Rea l - time Ad versarial Pert ur batio n Physic al Environm en t ( A ) Non - r eal - time Audi o Adv er sa rial Atta ck Non - real - time Adv ersa rial Exa m ple Ge n era tor Co m pl ete Sp eec h Sig nal Figure 4: Illustration of the non-real-time (upper figure) and real- time (lower figure) audio adv ersarial attack. sounds to a benign sample, it will be suspicious to the user; if the user is not near the target system, then it is not necessary to make the malicious sample imperceptible to humans. Fur- ther , it is not always easy or ev en possible to initiate a new session in security-sensitive systems. In contrast, the real- time adversarial attack scheme does not need a preparation phase; instead, it continuously processes the speech spoken by the user and emits the adversarial perturbation, which is superimposed with the original signal over the air in a real- time manner . In practice, the attack can be implemented by placing a device (e.g., a smartphone) equipped with a micro- phone and a speaker and installed with the real-time attack software near the tar get de vice. 3.2 Adversarial Attack Settings W e perform the non-targeted attack in a semi-black box set- ting, i.e., we assume that the attacker can call the tar get model an unlimited number of times and get the corresponding pre- dictions and confidence score, but has no knowledge about the model details (architectures, algorithm, and parameters). It is a realistic setting for speech recognition system attacks, because the loss function of many speech recognition models cannot be differentiable with respect to the input, and most state-of-the-art systems are cloud-based, which makes it dif- ficult to obtain full knowledge of the model and perform a white-box attack. F or example, the front end of our target model is not a neural network, b ut a set of filter banks e xtract- ing Mel-frequency cepstrum features, so it is hard to calcu- late the gradient of the loss function with respect to the input wa veform, ev en when we have a copy of the model [ Alzan- tot et al. , 2018 ] ; Google Speech is a commercial cloud-based model which is hard for the attacker to obtain full knowledge about its design. Ho we v er , it allows users to upload speech samples and freely obtain predictions and confidences scores, which provides opportunities for semi-black box attacks. In order to emulate a realistic situation, in this example, we apply the following constraints to the adversarial pertur- bation. First, we constrain the l 0 norm of the adversarial perturbation, i.e., we limit the number of non-zero points of the perturbation. This is because limiting the l 1 or l 2 norm will make the amplitude of the noise small and does not pose an ov er-the-air threat; so it is more reasonable to generate short, but relatively loud perturbations. Second, we require that the non-zero points of the perturbations must form clus- ters as consecutive noise segments. This is because it is im- possible for an electronic speaker to generate a signal of a few non-consecutiv e non-zero points due to the limitation of its dynamic characteristics. In this sample, we perturb fiv e 0.01-second segments and, for simplicity , the scales of the points in one segment are fixed and identical (i.e., the noise frequency is an integral multiple of the sampling frequency), but each noise segment can be any physically realizable sig- nal the attack desires. Data points that hav e amplitudes over 1 are clipped to 1. These two constraints also greatly lower the computational complexity for the real-time adversarial per- turbation generator , which now only needs to decide the tim- ing of emitting each of the fiv e noise segments. In this sam- ple, we focus on the decision-making process, so we do not consider the signal attenuation and distortion during transmis- sion through the air . An illustration of the proposed adversar - ial perturbation is shown in the upper part of Figure 5. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Time (seconds) -1 -0.5 0 0.5 1 Amplitude original signal adversarial noise 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Time (seconds) 0 0.2 0.4 0.6 0.8 1 Predicted Inject Timing (seconds) 1st noise segment 2nd noise segment 3rd noise segment 4th noise segment 5th noise segment Figure 5: Illustration of the proposed real-time audio adversarial attack using a real sample. The real-time perturbation generator continuously predicts the best timing to emit each of the fiv e 0.01- second adversarial noise segments based on the observation, and conducts emission immediately once the predicted timing is equal to or earlier than the current time point. W e can observe that the pre- diction changes dramatically when the speech signal is observed, b ut barely changes when the silent period is observed, indicating that the generator makes decisions mainly based on the informative part of the signal, and is able to correct them given more observation. The actual emission time points are sho wn with red dots in the lower fig- ure; they are unlikely to be the optimal choice with full observ ation, but are the best guess at that time gi v en partial observation. 3.3 The Expert Since we are performing a semi-black box attack, and to en- sure realism, we add non-standard constraints to the optimiza- tion problem. Follo wing the discussion in Section 2.3, we choose a stochastic optimization based adversarial example crafting technique as the expert. Specifically , we take the differ ential evolution optimization [ Storn and Price, 1997 ] , 0 50 100 150 200 Number of Optimization Iterations 0.02 0.04 0.06 0.08 0.1 0.12 Std of Optimization Result (secs) Population size = 10 Population size = 20 Population size = 50 Population size = 100 0 50 100 150 200 Number of Optimization Iterations 0.4 0.5 0.6 0.7 Confidence Drop Population size = 10 Population size = 20 Population size = 50 Population size = 100 Figure 6: The standard deriv ation of the optimization result using different random seeds (left figure) and the confidence score drop of the original class led by the expert attack (right figure) with different numbers for optimization iterations and population size. which was previously used for the “one-pixel” attack [ Su et al. , 2019 ] on image recognition systems with similar con- straints to our proposed attack. W e extend it for use as audio attacks, and then use it as the expert. In our case, the can- didate solution of the optimization is a 5-tuple consisting of the starting points of each noise segment (sorted). The op- timization objectiv e is to minimize the confidence score of the original label. At each iteration, the fitness of each can- didate solution is calculated and new candidate solutions are produced using the standard differential e volution formula. The dif ferential e v olution algorithm has two main parame- ters: the population size and the number of iterations. On one hand, we want the optimization result to be optimal and deter- ministic (i.e., the result is inv ariant to random seeds), which requires large parameters. On the other hand, the computa- tional overhead is linearly proportional to the population and the iteration number , and ev aluating the fitness of each can- didate solution requires calling the DNN based target model once. Therefore, in order to generate the dataset consisting of over 20,000 trajectories for imitation learning over a rea- sonable time, we hav e to limit the population and the itera- tion number . As shown in Figure 6, we test the performance and the standard deriv ation of the optimization result with dif- ferent random seeds. W e find that population size = 10 and iteration number = 75 provide a good balance between per- formance and computational overheads and use these values in our experiments. For each audio in the training set, we use the expert to generate a perturbation in the form of a 5-tuple. Note that each audio consists of 16,000 observations, and thus forms 16,000 observation-tuple pairs (a decision trajectory), where the tuple is identical for all observations since the op- timal perturbation does not change with the observation. 3.4 T raining the Real-time Adversarial Perturbation Generator Input and Output of the Network The real-time adv ersarial perturbation generator is imple- mented using a deep neural network; the input of the network is simply an observation o (of variable length), the output of the network is a 5-tuple of the same definition as the solu- tion of the differential evolution optimization algorithm, i.e., 5 time points to emit noise segments. The tuple can be easily con v erted to action a using the following rule: if the current estimated best emission timing is equal to or earlier than the current time point, then immediately emit the noise. Layer Name Output Dimension Input (t, 1) Framing ( d t/ 160 e , 160) Con v1 / Pooling ( d t/ 160 e , 80, 16) Con v2 / Pooling ( d t/ 160 e , 40, 32) Con v3 / Pooling ( d t/ 160 e , 20, 48) Con v4 / Pooling ( d t/ 160 e , 10, 64) Flatten ( d t/ 160 e , 640) LSTM * 3 (256) Dense 1 (256) Dense 2 (128) Output (5) T able 1: The netw ork details and the output dimension of each layer . Batch Processing The frequency of the speech signal (i.e., 16 kHz) is much higher than the possible update speed of the real-time adver - sarial perturbation generator . Therefore, we apply batch pro- cessing as mentioned in Section 2.3; specifically , the adver- sarial generator updates every 0.01 second and each update makes a decision on the actions for 0.01 seconds, so the de- lay is also 0.01 seconds. Note that while the update period and noise segment length are identical, the y are not related. The Network Architectur e As shown in T able 1, we use an end-to-end neural network. Since the input is an observation of v ariable length t , as a standard signal processing technique, we cut it into d t/ 160 e frames, where 160 is the frame length. W e then use a se- ries of con v olution and pooling layers to extract the features. The features of each frame are then sequentially fed into the long short-term memory (LSTM) [ Hochreiter and Schmidhu- ber , 1997 ] layers to obtain the encoding, and two dense layers decode the encoding as the output. This basically follows the architecture shown in Figure 3: the layers before the LSTM layers are the encoder , and those after the LSTM layers are the decoder . W e use 1e-3 as the learning rate, mean square loss, and AD AM optimizer [ Kingma and Ba, 2014 ] for train- ing. W e train data samples in the same trajectory in a batch to expedite the computations as discussed in Section 2.4. 3.5 Experiments In our experiments, we test the dataset and target model men- tioned in Section 3.1. The data is split as follows: we first hold out 20% of the data as the test set (test set 2) for ev al- uating the attack performance; so it is not seen by the target model and the attack model. W e use the other 80% of the data to train the target voice recognition model; this same set is then reused to dev elop the attack model. Specifically , we use 75% of this set to train the attack model (attack train- ing set), 6.25% for v alidation, and 18.75% for testing (test set 1). Therefore, test set 1 is seen by the target model, but not seen by the attack model. W e then generate the expert demonstration of optimal emission timing using the method mentioned in Section 3.3 for each speech sample in the attack train set. Since in our setting, the amplitude of each noise seg- ment is a giv en fixed value, it is expected (and is proven by our experiments later) that the expert demonstration of the op- timal emission timing varies with the giv en amplitude value because the emission strategy may be different for different noise amplitude. In this experiment, we generate two ver - sions of expert demonstrations using noise amplitude of 0.1 0 0.2 0.4 0.6 0.8 1 Perturbation Scale 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Attack Success Rate Expert - 0.5 Expert - 0.1 Real-time - 0.5 Real-time - 0.1 Random Noise 0 0.2 0.4 0.6 0.8 1 Perturbation Scale 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Confidence Drop Expert - 0.5 Expert - 0.1 Real-time - 0.5 Real-time - 0.1 Random Noise Figure 7: The attack successful rate and the confidence score drop led by the attack with different perturbation scale. 0 0.2 0.4 0.6 0.8 1 Time (seconds) 0.09 0.1 0.11 0.12 0.13 0.14 0.15 Error (seconds) 1s t noise segment 2nd noise segment 3rd noise segment 4th noise segment 5th noise segment Trial Time Ground Truth Figure 8: Left: the adversarial perturbation generator’ s estimate on the optimal noise emission timing (shown by color; dark represents later time, light represents earlier time) of the first noise segment at each time point. Each row represents one attack trial and 64 trials are shown in total. Right: the mean prediction error over time. and 0.5, respecti vely . Note that although the expert demon- stration of optimal emission time points are optimized based on a giv en noise amplitude, the attacker can emit noise of any amplitude as desired at these time points in the test phase, which might lead to a sub-optimal attack performance. W e discuss it in detail in the next section. W e then train the real-time adversarial perturbation gen- erator to learn from the expert demonstrations using the ap- proach described in Section 3.4. W e use two metrics to ev al- uate the attack performance: 1) attack success rate (in the non-targeted attack setting, success means that the prediction of the perturbed sample is different from that of the original sample) and 2) confidence score drop of the original class led by the attack (which measures the confidence of the attack). Overall Result W e show the attack performance on test set 1 of two non-real- time e xperts (optimized for perturbation amplitude of 0.1 and 0.5, respectiv ely) and corresponding learned real-time adver- sarial perturbation generators in Figure 7. W e observe that: First, the attack success rate of the adversarial perturbation generator is up to 43.5% (when perturbation amplitude is 1), which is about half of the best non-real-time expert (90.5%) and clearly outperforms the random noise. For most perturba- tion amplitudes, the attack success rate of the real-time attack is 30%-50% of that of the expert. Second, the attack performance of the expert v aries with the perturbation amplitude it is optimized for . It is not surpris- ing that the expert optimized for small noise amplitude of 0.1 performs better when the actual emission amplitude is small ( < 0.23) while the expert optimized for large amplitude of 0.5 performs better when the actual emission amplitude is large ( ≥ 0.23). This difference also shows in the corresponding real-time adversarial perturbation generators, but the impact is much smaller , which giv es the attacker a nice property that the attack performance does not drop much when the actual and expected noise amplitude are different (e.g., for audio ad- versarial attacks, it is hard for the attacker to know the actual amplitude of the noise signal recei ved by the target system due to signal attenuation, but it does not matter). Third, we further conduct the same test on the test set 2 (attack success rate up to 42.2%) and have not found a sub- stantial difference between the result of test set 1 and 2, in- dicating the attack model can be generalized to data samples that hav e not been seen by the tar get model. Real-time Dynamics W e next discuss ho w the proposed adversarial perturbation generator works in a real-time manner; tow ards this end, we plot the dynamics of 64 attack trials for 64 different input samples in the left part of Figure 8. Each row represents one attack trial, which sho ws the adversarial perturbation genera- tor’ s estimate on the optimal emission timing of the first noise segment at each time point. W e place the ground truth on the right for reference. At the beginning of each attack, when no data is observed yet, the adversarial perturbation generator outputs a prior guess which has similar values for different samples, but with more data observed, the estimate gradu- ally improv es and finally approaches the ground truth. W e can also observe that the amount of observations needed for correct estimates differs among the trials. This is because the voice command samples have different lengths of silence periods at the beginning, which does not contain information helpful to predict an adv ersarial perturbation. This can be fur - ther v erified by the detailed dynamics of a real sample sho wn in Figure 5, where we can find that the estimation of the ad- versarial perturbation generator changes dramatically when the speech signal is observed, but barely changes when the silent period is observed, indicating the generator makes de- cisions mainly based on the informativ e part of the signal, and is able to correct them given more observ ation. In this sample, the estimation does not become stable until half of the speech signal is observ ed, b ut three noise se gments are already emit- ted by this time point, showing the trade-off between the ob- servation and action space, i.e., the attacker needs to emit the adversarial noise immediately when the current best-guess timing with partial observation arrives, otherwise the timing will pass and the emission cannot be implemented. W e also show the mean absolute prediction error over time in the right part of Figure 8, which demonstrates that the adversarial gen- erator indeed improv es with more observ ations. Error Analysis Finally , we analyze the error of the real-time adv ersarial gen- erator . There are two main types of errors causing the per- formance gap between the expert and the real-time adversar- ial generator: prediction error and real-time decision error . The proposed real-time generator essentially tries to b uild the -1 -0.5 0 0.5 1 Timing Error (seconds) 0 0.05 0.1 Probability Figure 9: The distribution of the actual emission timing errors. mapping between the (partial) input and output of the differ - ential ev olution optimization, while this substantially speeds up the computing, it is challenging to learn such a map- ping. Specifically , in our setting, the output of the stochas- tic optimization algorithm adopted by the expert is not de- terministic (shown in the left part of Figure 6), which makes learning such a mapping e ven harder . As shown in the right part of Figure 8 and, ev en after the real-time generator ob- serves the full data, its prediction still has a certain amount of prediction errors. Further , as discussed in the previous sec- tion, the real-time adversarial generator may emit noise seg- ments when it does not have a reliable estimation due to the observation-action space tradeoff. W e show that the distri- bution of the actual timing error in Figure 9, which obeys a zero-centered bell-shaped distrib ution, and the errors of most trials are small. Statistically , the mean actual timing error (i.e., the difference between the actual emission time point and the expert’ s demonstration) is 0.1135 seconds, which is slightly larger than the prediction error (i.e., the dif ference between the predicted emission time point with full observa- tion and the expert’ s demonstration) of 0.1091 seconds. This indicates that the main error of our attack model is the pre- diction error, which can be improved by further reducing the instability of the expert and optimizing the deep neural net- work architecture. The proposed adversarial perturbation is audible even when the amplitude is small. It sounds simi- lar to “usual” noise experienced by electronic speakers (e.g., buzzing, interference, etc.), which makes the perturbation ap- pear not suspicious. 4 Conclusions and Future W ork In this work, we propose the concept of real-time adversarial attacks and show how to attack a streaming-based machine learning model by designing a real-time perturbation gener- ator that continuously uses observed data to design optimal perturbations for unobserved data. W e use imitation learning and beha vioral cloning algorithm to train the real-time adver - sarial perturbation generator through the demonstrations of a state-of-the-art non-real-time adversarial perturbation gener- ator . The case study (voice command recognition) and re- sults demonstrate the effecti v eness of the proposed approach. Nev ertheless, we observe a certain performance gap between the real-time and the non-real-time adversarial attack when the basic behavior cloning algorithm is used. In our future research, we plan to study how to adopt more advanced rein- forcement learning tools to improve the performance of deci- sion making process, e.g., when the real-time adversarial per- turbation generator realizes it has previously made a wrong decision, could it adjust its future strategy to make it up? On the other hand, we plan to study the defense strategy to protect real-time systems against such real-time adversarial attack. References [ Alzantot et al. , 2018 ] Moustafa Alzantot, Bharathan Balaji, and Mani Sriv astav a. Did you hear that? adversarial exam- ples against automatic speech recognition. arXiv preprint arXiv:1801.00554 , 2018. [ Atkeson and Schaal, 1997 ] Christopher G Atkeson and Ste- fan Schaal. Robot learning from demonstration. In ICML , volume 97, pages 12–20. Citeseer , 1997. [ Carlini and W agner , 2018 ] Nicholas Carlini and Da vid W agner . Audio adversarial examples: T argeted attacks on speech-to-text. In 2018 IEEE Security and Privacy W orkshops (SPW) , pages 1–7. IEEE, 2018. [ Carlini et al. , 2016 ] Nicholas Carlini, Pratyush Mishra, T a vish V aidya, Y uankai Zhang, Micah Sherr , Clay Shields, David W agner , and W enchao Zhou. Hidden voice commands. In 25th { USENIX } Security Symposium ( { USENIX } Security 16) , pages 513–530, 2016. [ Cisse et al. , 2017 ] Moustapha Cisse, Y ossi Adi, Natalia Nev ero v a, and Joseph Keshet. Houdini: Fooling deep structured prediction models. arXiv preprint arXiv:1707.05373 , 2017. [ Ebrahimi et al. , 2017 ] Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adver- sarial examples for text classification. arXiv pr eprint arXiv:1712.06751 , 2017. [ Gong and Poellabauer , 2017 ] Y uan Gong and Chris- tian Poellabauer . Crafting adversarial examples for speech paralinguistics applications. arXiv pr eprint arXiv:1711.03280 , 2017. [ Gong and Poellabauer , 2018 ] Y uan Gong and Christian Poellabauer . An overvie w of vulnerabilities of voice con- trolled systems. arXiv pr eprint arXiv:1803.09156 , 2018. [ Goodfellow et al. , 2014 ] Ian J Goodfellow , Jonathon Shlens, and Christian Szegedy . Explaining and harnessing adversarial examples. arXiv pr eprint arXiv:1412.6572 , 2014. [ Grosse et al. , 2017 ] Kathrin Grosse, Nicolas Papernot, Prav een Manoharan, Michael Back es, and Patrick Mc- Daniel. Adversarial examples for malw are detection. In Eur opean Symposium on Researc h in Computer Security , pages 62–79. Springer , 2017. [ Hochreiter and Schmidhuber , 1997 ] Sepp Hochreiter and J ¨ urgen Schmidhuber . Long short-term memory . Neural computation , 9(8):1735–1780, 1997. [ Kingma and Ba, 2014 ] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [ Li et al. , 2018 ] Shasha Li, Ajaya Neupane, Sujoy Paul, Chengyu Song, Srikanth V Krishnamurthy , Amit K Roy Chowdhury , and Ananthram Swami. Adversarial perturba- tions against real-time video classification systems. arXiv pr eprint arXiv:1807.00458 , 2018. [ Moosavi-Dezfooli et al. , 2016 ] Seyed-Mohsen Moosa vi- Dezfooli, Alhussein Fa wzi, and Pascal Frossard. Deep- fool: a simple and accurate method to fool deep neural networks. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 2574–2582, 2016. [ Moosavi-Dezfooli et al. , 2017 ] Seyed-Mohsen Moosa vi- Dezfooli, Alhussein Fa wzi, Omar Fa wzi, and Pascal Frossard. Uni versal adversarial perturbations. In Pro- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 1765–1773, 2017. [ Neekhara et al. , 2019 ] Paarth Neekhara, Shehzeen Hussain, Prakhar Pandey , Shlomo Dubnov , Julian McAuley , and Farinaz K oushanfar . Univ ersal adversarial perturba- tions for speech recognition systems. arXiv pr eprint arXiv:1905.03828 , 2019. [ Qin et al. , 2019 ] Y ao Qin, Nicholas Carlini, Ian Goodfel- low , Garrison Cottrell, and Colin Raffel. Imperceptible, robust, and targeted adversarial examples for automatic speech recognition. arXiv pr eprint arXiv:1903.10346 , 2019. [ Ross et al. , 2011 ] St ´ ephane Ross, Geoffre y Gordon, and Drew Bagnell. A reduction of imitation learning and struc- tured prediction to no-regret online learning. In Pr oceed- ings of the fourteenth international conference on artificial intelligence and statistics , pages 627–635, 2011. [ Sainath and Parada, 2015 ] T ara Sainath and Carolina Parada. Conv olutional neural networks for small-footprint keyw ord spotting. 2015. [ Sch ¨ onherr et al. , 2018 ] Lea Sch ¨ onherr , Katharina Kohls, Steffen Zeiler, Thorsten Holz, and Dorothea K olossa. Adversarial attacks against automatic speech recogni- tion systems via psychoacoustic hiding. arXiv pr eprint arXiv:1808.05665 , 2018. [ Storn and Price, 1997 ] Rainer Storn and K enneth Price. Differential e volution–a simple and efficient heuristic for global optimization over continuous spaces. Journal of global optimization , 11(4):341–359, 1997. [ Su et al. , 2019 ] Jiawei Su, Danilo V asconcellos V argas, and K ouichi Sakurai. One pixel attack for fooling deep neural networks. IEEE T ransactions on Evolutionary Computa- tion , 2019. [ Sutton et al. , 1998 ] Richard S Sutton, Andre w G Barto, et al. Intr oduction to r einfor cement learning , volume 135. MIT press Cambridge, 1998. [ Szegedy et al. , 2013 ] Christian Szegedy , W ojciech Zaremba, Ilya Sutske ver , Joan Bruna, Dumitru Erhan, Ian Goodfellow , and Rob Fergus. Intriguing properties of neural networks. arXiv preprint , 2013. [ W arden, 2018 ] Pete W arden. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv preprint arXiv:1804.03209 , 2018. [ Y akura and Sakuma, 2018 ] Hiromu Y akura and Jun Sakuma. Robust audio adversarial example for a physical attack. arXiv pr eprint arXiv:1810.11793 , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment