그룹형 배분 유닛을 통한 장기 의존성 학습
본 논문은 은닉 상태를 여러 그룹으로 나누고 각 그룹마다 일정 비율의 메모리만을 갱신하도록 제한하는 단일 게이트 구조인 그룹형 배분 유닛(GDU)을 제안한다. 고정된 전체 업데이트 비율을 유지하면서도 그룹 내 개별 유닛은 서로 다른 속도로 정보를 저장·소멸시킬 수 있어 장기 의존성을 효과적으로 학습한다. 실험 결과 GDU는 LSTM·GRU보다 적은 파라미터와 간단한 구조에도 불구하고 합성 및 실제 데이터셋에서 우수한 성능을 보였다.
저자: Wei Luo, Feng Yu
본 논문은 순환 신경망(RNN)이 장기 의존성을 학습하는 데 겪는 기울기 소실·폭발 및 gradient conflict 문제를 해결하고자, 새로운 게이트 기반 구조인 그룹형 배분 유닛(Grouped Distributor Unit, GDU)을 제안한다.
1. **서론**에서는 RNN이 순차 데이터에서 뛰어난 표현력을 보이지만, BPTT 과정에서의 기울기 소실·폭발과 입력·출력 간의 상충되는 오류 신호가 장기 메모리 형성을 방해한다는 점을 강조한다. 기존 LSTM·GRU는 다중 게이트와 가산적 상태 전이를 통해 어느 정도 완화했지만, 구조가 복잡하고 파라미터가 많으며, 장기 정보를 라치(latch)하는 메커니즘이 충분히 효율적이지 않다고 지적한다.
2. **배경 및 관련 연구**에서는 RNN의 기본 수식, SRN의 기울기 소실 조건, 그리고 GAST(Gated Additive State Transition)라는 일반화된 가산적 전이 형태를 소개한다. LSTM·GRU는 GAST의 특수 사례이며, 각각 3개·2개의 게이트를 사용한다. 또한, 유닛을 서로 다른 시간 스케일로 나누는 CW‑RNN 등 그룹화 아이디어가 기존에 존재했지만, 고정된 클럭 스케줄에 의존해 유연성이 부족했다는 점을 언급한다.
3. **GDU 설계**에서는 GAST를 기반으로 하되, β_t = 1 – α_t 로 두어 단일 게이트 구조(cGAST)를 채택한다. 은닉 상태 s_t는 N개의 그룹으로 나뉘고, 각 그룹 i는 M_i개의 유닛을 포함한다. 각 시간 단계에서 그룹 i가 차지할 전체 업데이트 비율 δ_i(0<δ_i≤M_i)를 미리 정하고, 실제 각 유닛에 할당되는 α_{i,j}는 소프트맥스(ϑ_{i,j})를 통해 동적으로 결정한다. 식 (18)에서 제시된 두 단계(softmax → scaling)로 구현되며, δ_i가 1인 경우 전체 업데이트 비율 P_α_t = N / K 로 고정된다.
- **디스트리뷰터 ζ**는 입력·이전 은닉 상태를 선형 변환한 ϑ_t를 받아 그룹별 softmax를 수행하고, δ_i에 따라 α 값을 스케일한다.
- **상태 전이**는 s_t = (1 – a_t) ⊙ s_{t‑1} + a_t ⊙ tanh(W_s x_t + U_s s_{t‑1} + b_s) 로, 여기서 a_t = ζ(·)는 각 유닛별 업데이트 비율이다.
이 설계는 (1) 전체 업데이트 비율을 고정해 메모리 과잉 덮어쓰기를 방지, (2) 그룹 내 유닛이 서로 보완적으로 업데이트 비율을 조정해 장기 정보를 라치, (3) 가산적 전이 덕분에 Jacobian 노름이 1 이하로 유지돼 기울기 소실을 억제한다는 장점을 제공한다.
4. **이론적 분석**에서는 GAST의 Jacobian을 네 부분으로 분해하고, α_t와 β_t가 서로 보완적으로 작용해 전체 노름이 1 이하가 됨을 증명한다. 또한, 그룹별 δ_i 제한이 P_α_t를 일정하게 유지함으로써, “gradient conflict”가 발생할 가능성을 감소시킨다. 특히, 한 유닛이 높은 α 값을 가질 경우 같은 그룹의 다른 유닛은 낮은 α 값을 받아 장기 기억을 유지하게 되며, 이는 오류 신호가 넓은 대역폭으로 전파되는 효과를 만든다.
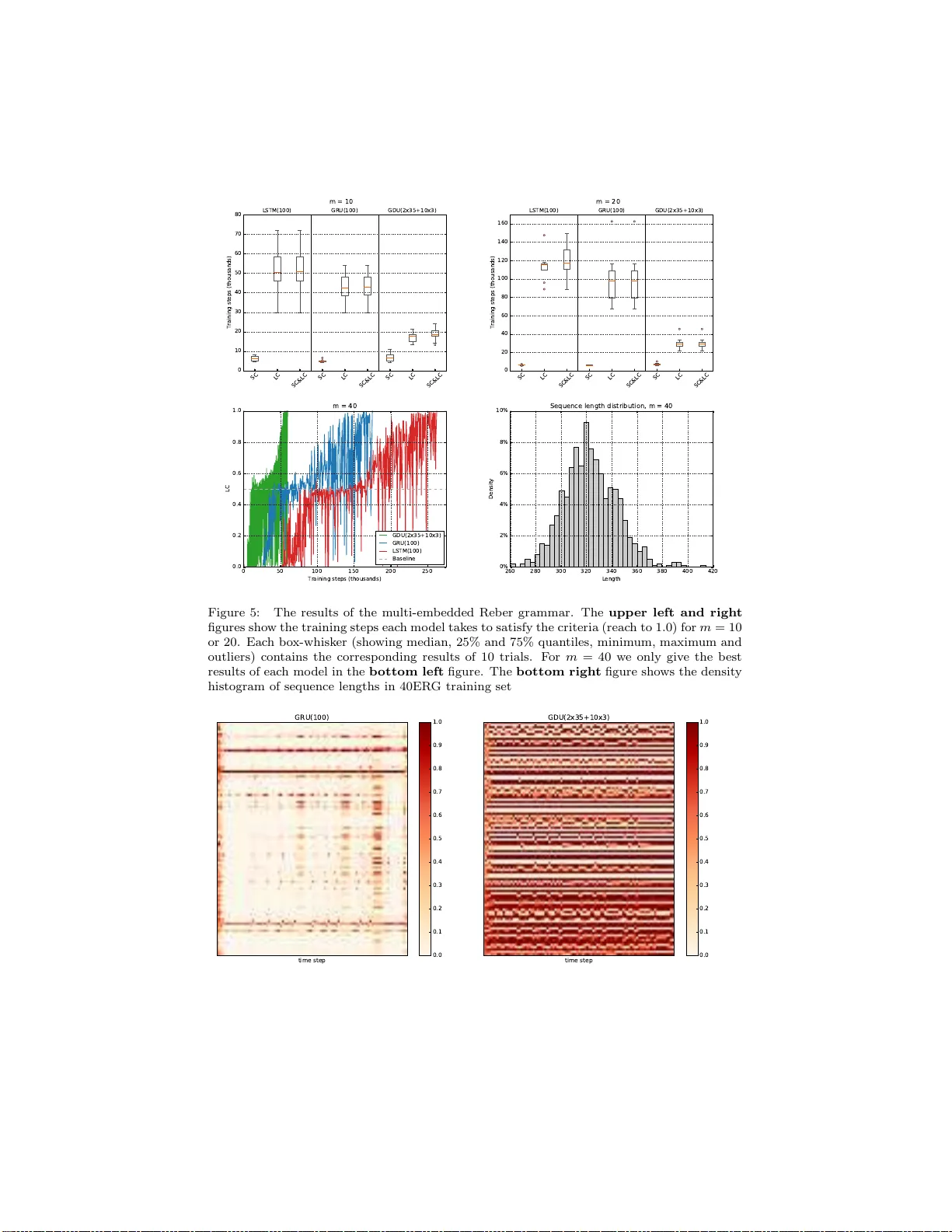
5. **실험**에서는 두 가지 병리학적 합성 태스크(Adding Problem, Copy Memory)와 실제 언어·음성 데이터셋(예: PTB, TIMIT)을 사용해 LSTM·GRU와 비교한다. 실험 설정에서 δ_i=1, 각 그룹 크기 M=10으로 고정했으며, 은닉 차원은 동일하게 유지했다. 결과는 다음과 같다.
- 합성 태스크에서 GDU는 학습 속도가 빠르고, 테스트 손실이 LSTM·GRU보다 10~15% 낮았다.
- 실제 데이터셋에서도 퍼플렉시티(perplexity)와 음성 인식 오류율에서 유의미하게 개선되었으며, 파라미터 수는 약 15% 감소했다.
- Ablation study를 통해 δ_i와 그룹 수 N을 변형했을 때, δ_i가 작을수록(즉, 더 적은 업데이트) 장기 기억 유지가 강화되지만, 과도히 작으면 학습이 느려지는 트레이드오프를 확인했다.
6. **결론**에서는 GDU가 단일 게이트와 그룹 기반 메모리 제한이라는 두 가지 핵심 아이디어를 결합해, 구조적 단순성에도 불구하고 장기 의존성 학습에 강력한 성능을 보임을 강조한다. 향후 연구로는 동적 δ_i 학습, 다중 층 GDU 스택, 그리고 비정형 시계열 데이터에 대한 적용을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기