Learning Longer-term Dependencies via Grouped Distributor Unit
Learning long-term dependencies still remains difficult for recurrent neural networks (RNNs) despite their success in sequence modeling recently. In this paper, we propose a novel gated RNN structure, which contains only one gate. Hidden states in th…
Authors: Wei Luo, Feng Yu
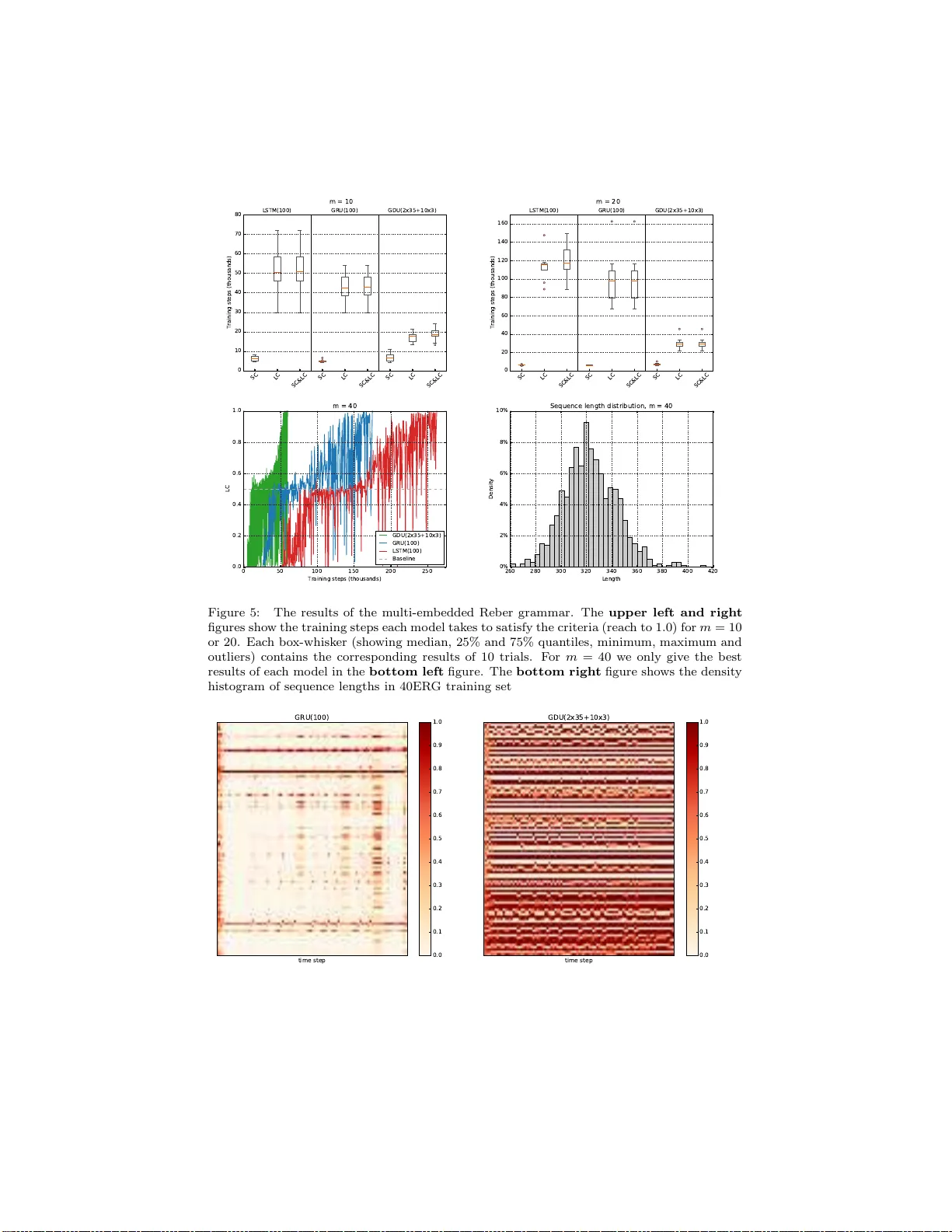
Learning Longer-t erm Dependenci es via Group ed Distribut or Unit W ei Luo a , F eng Y u a, ∗ a Col le ge of Biome dic al Engine ering and Instrument Science, Y u quan c ampus, Zhejiang University, 38 Zhe da R o ad, Hangzhou 31002 7, China Abstract Learning long-term dep e ndencies still remains difficult for re c urrent neural net- works (RNNs) despite their success in sequence mo deling r ecently . In this paper , we prop o s e a no v el gated RN N structure, which con tains only one gate. Hid- den states in the prop osed group ed distributor unit (GDU) are partitioned into groups. F or each group, the propo rtion of memory to b e overwritten in each state tr a nsition is limited to a constant and is adaptively distributed to each group member. In other word, every separa te gr oup ha s a fixed ov erall up date rate, yet all units are allowed to have differ ent paces. Information is there- fore forced to b e latched in a flexible wa y , which helps the mo del to ca pture long-term dependencie s in data. Besides ha ving a simpler structure , GDU is demonstrated experimentally to outp erfor m L STM and GR U on tas ks includ- ing b oth patho logical pr oblems and natur al da ta s e t. Keywor d s: Recurrent neural netw ork, Sequence lear ning, Long- term memory 1. In troduction Recurrent Neural Netw orks (RNNs, [1, 2]) are p owerful dyna mic systems for tasks that in volv e seq ue ntial inputs, such as audio classifica tion, machin e translation and speech generation. As they pro cess a sequence one elemen t at a time, in ternal states are ma intained to store information computed fro m the past inputs which makes RNNs capable of mo deling tempo r al correla tions betw een element s from any distance in theory . In practice, howev er, it is difficult fo r RNNs to lear n long -term dep enden- cies in da ta b y using ba ck-propagation through time (BPTT, [1]) due to the well known vanishing and explo ding gr adient problem [3]. Besides, training RNNs s uffers fro m gr adient conflicts (e.g. input c onflict and output c onflict [4 ]) which make it challenging to la tch long-term infor mation while k eeping mid- and short-ter m memory s im ultaneously . V arious a ttempts hav e b een made to ∗ Corresp onding author Email addr ess: willi4m@zj u.edu.cn (W ei Luo) Pr eprint increase the tempor a l ra nge that credit assignment takes e ffect for recurrent mo dels during training, including adopting a mu ch more sophisticated Hessia n- F ree optimizatio n method instead of sto chastic gra dient descent [5 , 6], using ortho gonal weigh t matric e s to assist optimization [7, 8] and a llowing direct con- nections to mo del inputs or states fro m the distant past [9, 10, 11]. Long short-term memory (LSTM, [4]) and its v aria nt , k nown as gated recurr ent units (GR U, [12]) mitiga te gr adient conflicts by using m u ltiplic ative gate units . More- ov er , the v a nis hing gr a dient pro blem is allev iated by the additivity in their state transition op era tor. Simplified gated units hav e be e n prop osed [13, 14] yet the ability of capturing long-term dep endencies has not been impro ved. Recen t work a lso s uppo rts the idea o f partitioning the hidden units in a n RNN into separate modules with differe n t pr o cessing per io ds [15]. In this pa p er , we intro duce Group ed Distributor Unit (GDU), a new g a ted recurrent architecture with a dditive state transition and only one g a te unit. Hidden states inside a GDU are partitioned into groups, each of which keeps a constant prop ortion o f pre vious memor y at each time step, forcing informa tion to b e la tch ed. The v anishing gradie nt problem, toge ther with the issue of gr a - dient conflict, which imp ede the extr action of long-ter m depe ndencie s are thus alleviated. W e empirically ev aluated the pr op osed mo del aga inst LSTM a nd GRU on bo th synthetic pr oblems which ar e desig ned to b e pa thologically difficult and natural dataset containing long-ter m comp onents. Results reveal that our pro- po sed mo del outp er fo rms LSTM a nd GR U on these tasks with a simpler s truc- ture a nd less pa rameters. 2. Bac kground and rel ated work An RNN is a ble to enco de sequences of ar bitr ary length into a fixed-length representation b y folding a new obser v ation x t int o its hidden state s t using a transition op erator T a t each time step t : s t = T ( x t , s t − 1 ) 1 (1) Simple recur rent net works (SRN, [16]), known as one of the earliest v ar iants, make T as the comp osition o f an e le ment-wise nonlinear it y with an affine tr ans- formation o f both x t and s t − 1 : s t = φ s ( W s x t + U s s t − 1 + b s ) (2) where W s is the input-to-state weigh t matrix, U s is the state-to-state recur - rent weigh t matrix, b s is the bias a nd φ s is the no nlinear activ ation function. F or the convenience o f the following descriptio ns , we deno te this kind of op er- ators as η ( · , · , φ ), a nd a subscr ipt can be added to distinguis h different net work comp onents. Thus in SRN, s t = η s ( x t , s t − 1 , φ s ). 1 W e do not consider RNNs with connections f rom the past suc h as NA R X RNN [9]. 2 During training v ia B P TT, the erro r obtaine d from the o utput of a n RNN at time step t (denoted as L t ) trav els backw a rd thro ug h e a ch state unit. The corres p o nding erro r signal propag ated back to time step τ (denoted as ε τ ← t = ∂ L t ∂ s τ 2 , τ < t ) contains a pro duct o f t − τ Jac obian matrice s: ε τ ← t = ε t ← t Y t ≥ i>τ ∂ s i ∂ s i − 1 (3) F rom Eq . (3) we c a n easily find a sufficient c ondition for the vanishing gr adient problem to o ccur , i.e. ∀ τ < i ≤ t, ∂ s i ∂ s i − 1 < 1. Under this c o ndition, a b o und ξ ∈ R can b e found such that ∀ i, ∂ s i ∂ s i − 1 ≤ ξ < 1 , and k ε τ ← t k = ε t ← t Y t ≥ i>τ ∂ s i ∂ s i − 1 ≤ ξ t − τ k ε t ← t k (4) As ξ < 1, long term contributions (for whic h t − τ is larg e ) go to 0 exp onentially fast with t − τ . In SRN, ∂ s i ∂ s i − 1 is given by U T s diag ( φ ′ s ( W s x t + U s s t − 1 + b s )). As a result, if the der iv ative of the nonlinear function is b ounded in SRN, namely , ∃ κ ∈ R , s.t. | φ ′ s ( x ) | ≤ κ , it will b e sufficient for λ 1 < 1 κ , wher e λ 1 is the lar g est sing ular v alue of the recurrent w eight matrix U s , for ε τ ← t to v anish (as t → ∞ )[17]. An y RNN architecture with a long-term memory ability should at least b e designed to mak e sure the norm of its transition Jacobian will not easily b e bo unded b y 1 for a long time span as it go es thro ug h a sequence. 2.1. Gate d additive state tr ansition (GAST) Long s ho rt-term memory (LSTM, [4]) introduced a memor y unit with se lf- connected structure which can maintain its state ov er time, a nd non-linear gat- ing units (orig inally input and o utput g a tes) which control the informa tion flow int o and out of it. Since the initial pro po sal in 1997, man y improv ements have bee n made to the LSTM architecture [1 8, 19]. In this pap er, we refer to the v ari- ant with fo rget ga te and without p eephole connections, which has a compar able per formance w ith mor e co mplex v ariants [20]: f t = η f ( x t , h t − 1 , σ ) (5a) i t = η i ( x t , h t − 1 , σ ) (5b) o t = η o ( x t , h t − 1 , σ ) (5c) ¯ s t = η ¯ s ( x t , h t − 1 , tanh) (5d) s t = f t ⊙ s t − 1 + i t ⊙ ¯ s t (5e) h t = o t ⊙ tanh( s t ) (5f ) 2 ∂ L t ∂ s τ = ( ∂ L t ∂ s 1 τ , ∂ L t ∂ s 1 τ , · · · , ∂ L t ∂ s M τ ) T , in whic h M is the state size and the k -th comp onent ∂ L t ∂ s k τ represen ts the s ensi tivi t y of L t to small p erturbations i n the k -th state unit at time step τ . 3 Here σ deno tes the sigmoid a ctiv ation and ⊙ denotes element-wise m ultiplica- tion. Note that h t should also be co ns idered as hidden state b esides s t . Cho et al. [12] prop o s ed a similar architecture with g a ting units called gated recurrent unit (GRU) . Different fro m LSTM, GR U exp oses all its states to the output and use a linear interp olation b etw een the previo us state s t − 1 and the candidate state ¯ s t : r t = η r ( x t , s t − 1 , σ ) (6a) z t = η z ( x t , s t − 1 , σ ) (6b) ¯ s t = η ¯ s ( x t , r t ⊙ s t − 1 , tanh) (6c) s t = z t ⊙ s t − 1 + (1 − z t ) ⊙ ¯ s t (6d) Previous work has clea rly indicated the a dv antages o f the g ating units ov er the more tra ditional recur rent units [21]. Both LSTM and GRU p er fo rm well in tasks that requir e capturing long- ter m dependencies. How ever, the choice of these t wo structure s may depend heavily on the dataset and corres p o nding task. s k t − 1 ˜ s k t − 1 ¯ s k t s k t γ k t α k t β k t s i, 1 t − 1 ¯ s i, 1 t α i, 1 t s i, 1 t 1 − α i, 1 t Distributor 0 . 1 0 . 1 0 . 8 α i, 2 t 1 − α i, 2 t α i, 3 t 1 − α i, 3 t Figure 1: Left : The gated additive state transition (GAST). Inputs and outputs are not sho wn. Superscr i pt k denotes the ordinal num ber of a s tate unit. In LSTM, ˜ s k t − 1 corresponds to h k t − 1 . In GRU, β k t = 1 − α k t . Right : The GAST in a GDU group with size 3 and δ i = 1 . 0. Compared to LSTM and GR U, gate operator γ t is remov ed and gate op erators { α i,k t } k inside the group is correlated, i.e. P k G i,k α t = δ i = 1. Any unit assigned with a high G i,k α t will force other group members to latch i nf ormation. It is easy to notice that the mo st prominent feature shar ed b etw een these units is the additivity in their state trans itio n op er a tors. In a nother w ord, bo th LSTM and GRU keep the existing states and a dd the new s tates o n top of it instead o f repla c ing previous states dire c tly , as it did in tr a ditional recurrent units lik e SRN. Another important ing redient in their transition op erator is the gating mec hanism, which reg ulates the information flow and enables the net work to form s kip connections adaptively . In this pap er we r e fer to this kind of tr ansition op er a tors as the Gate d A dditive State T r ansit ion (GAST) with a 4 general formula: ¯ s t = η ¯ s ( x t , γ t ( s t − 1 ) , φ ) (7a) s t = β t ( s t − 1 ) + α t ( ¯ s t ) (7b) where α t , β t and γ t are called gate op er ators with s ubs c ript t indica ting that v alues of the co rresp onding gating units change over time (see Fig . 1 (left)). In LSTM: γ t ( s t − 1 ) = o t − 1 ⊙ tanh( s t − 1 ) (8a) β t ( s t − 1 ) = f t ⊙ s t − 1 (8b) α t ( ¯ s t ) = i t ⊙ ¯ s t (8c) whilst in GR U: γ t ( s t − 1 ) = r t ⊙ s t − 1 (9a) β t ( s t − 1 ) = z t ⊙ s t − 1 (9b) α t ( ¯ s t ) = (1 − z t ) ⊙ ¯ s t (9c) W e denote the gate vector used in a gate o p er ator T at time step t as G T t . Note that except E q. (8a), gate op erato rs T t hav e a co mmon for m 3 : T t ( s ) = G T t ⊙ s (10) where s is a state vector to b e g a ted. W e use β t = 1 − α t to indicate G β t = 1 − G α t as in the ca s e of GRU. Accor ding to Eq. (7b), the tra ns ition Ja cobian of a GAST can b e r esolved in to 4 par ts: ∂ s t ∂ s t − 1 = J s t − 1 + J ¯ s t + J G α t + J G β t (11) in whic h J s t − 1 = diag ( G β t ) (12a) J ¯ s t = ∂ ¯ s t ∂ s t − 1 · diag ( G α t ) (12b) J G β t = ∂ G β t ∂ s t − 1 · diag ( s t − 1 ) (12c) J G α t = ∂ G α t ∂ s t − 1 · diag ( ¯ s t ) (12d) The gradient prop erty o f GAST is muc h b etter than tha t of SRN since it ca n easily preven t its tra nsition Jacobia n norm to b e b ounded within 1 b y satura ting 3 In the foll owing part of this paper, gate op er ators are referred to as b eing in this form. 5 part o f units in G β t nearly at 1. Intuit ively , when this happ ens, the corres po nd- ing comp o nents of erro r signal are allow ed to b e back-propa g ated e a sily through the shortcut cr e ated by the additive character of GAST without v anishing too quickly . The or iginal LSTM [4 ] uses ful l gate r e curr enc e [22], which means that all neurons r eceive r ecurrent inputs fro m all gate activ ations at the prev ious time step b esides the blo ck outputs. Nevertheless, it still follows E qs. (7). Another difference is that the o riginal LSTM do es not use forg et ga te, i.e. β t ( s t − 1 ) = s t − 1 , thus in Eq. (12a), J s t − 1 is a unit diagonal matrix I . In addition, gradients are truncated by replac ing the other comp onents in its transitio n Jaco bia n, i.e. Eqs. (12b), (12c) and (12d), by zer o , forming a c onstant err or c arr ousel (CEC) wher e ∂ s t ∂ s t − 1 = I . It is noticea ble, howev er , that if the gr adients a re not truncated, Eq. (3) do e s not ho ld for LSTMs s ince the gate vector o t − 1 used in γ t is calcula ted at the previous time step, see E q . (8a ). In this co ndition, a concatenation of s t and h t = γ t ( s t ) should b e used in analysis of its tra nsition Jacobian, as in Fig . 7. Simplifying GAST has drawn interest of resea rchers recently . GR U itself reduces the g a te units to 2 co mpa red to LSTM which ha s 3 g a te units b y co u- pling for get gate and input gate into one up date gate, namely making the gate op erator β t equals to 1 − α t . In this pap er w e denote this kind of GAST as c GAST, with the prefix c short for c ouple d . Based on GRU, the Minimal Gated Unit (MGU, [14]) reduced the gate num b er further to only 1 b y letting γ t = β t = 1 − α t without losing GRU’s a ccuracy bene fits. The Upda te Gate RNN (UGRNN , [13]) entirely r emov ed γ t op erator . How ever, none of these mo dels has shown sup erior ity over LSTM and GRU o n long-term ta sks with single-layer hidden states. 2.2. Units p artitioning Although the capacity of capturing long- term dep endencies in sequences is of crucia l imp ortance of RNNs, it is worth while to notice that the flowing data is usually embedded with b oth slow-moving and fast-moving information, o f which the former corresp onds to long-term dep endencies. Along with the existence of b oth long - and shor t- ter m information in sequences, the training pro ces s alwa ys ha s gr adient c onflict e xisting. Here gr adient c onflict mainly refers to the contradiction b etw ee n err or sig nals ba ck-propagated to a sa me time step, but injected at different time steps during training via BP TT . This issue may hinder the establish of lo ng-term memo ry even without the g radient v anishing problem. Consider a task in which a GRU is g iven o ne da ta po in t at a time and as- signed to predict the next, e.g . m E R G (se e Sec tio n 4.3 ). If the correc t prediction at time s tep t 1 is heavily dep ending on the data p oint app ear e d at time step t 0 , namely x t 0 , where t 0 ≪ t 1 , we can say a long -term dep endency ex is ts b etw een x t 0 and x t 1 +1 . GRU can capture this kind of dep endency b y learning to enco de x t 0 int o s ome state units and la tch it un til t 1 . F o r simplicity , let us fo cus on a single sta te unit s k and assume that the information of x t 0 has be e n sto red in 6 s k t 0 . At time step t ( t 0 < t < t 1 ), state unit s k t will often receive c o nflicting er ror signals. The error signal ε k t ← t 1 injected a t time step t 1 may attempt to make s k t keep its v alue until t 1 . While other error signa ls injected b efore t 1 , say , t 2 , may hop e that s k t 2 helps to do the prediction at time step t 2 , thus it may a ttempt to make s k t to be overwritten by a new v alue. This conflict makes the GRU mo del hesitate to shut the up date ga te for s k by setting G k α t to 0. In GRU, we also obs erved that state units latching long-ter m memories (with co rresp onding neurons in G β t staying active for a long time) ar e usually sparse (see Fig. 6 (left)), which imp edes the ba ck-propagation of effective lo ng -term error signals, since s hort-term error s ignals dominate. As a result, learning can b e slow. El Hihi and Bengio firs t showed that RNNs can learn bo th long- and sho rt- term dep endencies mo re eas ily and efficiently if state units ar e partitioned into groups with different timescales [23 ]. The clo ckwork RNN (CW-RNN) [15] implemen ted this by assig ning each state unit a fixed temp ora l gra nularit y , making state transition ha ppens o nly at its prescr ibe d clo ck r ate. It ca n also be seen a s a member of cGAST family . More specific a lly , a UGRNN with a sp ecia l gate op erator β t in which each gate vector v alue G k β t is explicitly scheduled to saturate a t either 0 o r 1. CW-RNN do es not suffer from gradient co nflict for it inherently has the ability to latch informa tion. Ho wev er, the clo ck rate schedule should b e tuned for each task. 3. Group e d Distributor Unit As intro duce d in Section 2, a net work co mb ining the adv antages o f GAST and the idea to partition sta te units into gro ups see ms promising. F ur ther, we argue that a dynamic system with memory do es not need to ov er write the v ast ma jority of its memor y bas ed o n r elatively little input da ta . F or cGAST mo dels whose β t = 1 − α t , we define the prop ortion of states to b e ov erwritten at time step t as : P α t = 1 K K X k =1 G k α t (13) where K is the state size. On the other hand, the prop or tion of previous states to b e kept is : P β t = 1 K K X k =1 G k β t = 1 − P α t (14) Hence in our vie w , if a mo del input x t contains small amount of information compared to system memory s t − 1 , P α t should be kept low to pr otect the previ- ous states. F or cGAST family members, a low er P α t leads to more a ctive units in G β t (see Fig.6 (right)) and thus less pr one to be affected by gra dient co nflict. T o put a limit on P α t , we star t by a plain UGRNN and partition its state units in to N gr oups: s t = n s i,j t o M i j =1 N i =1 (15) 7 where the i -th gro up contains M i units. A t each time step, for each i , we let a po sitive constant δ i < M i to b e dis tributed to the co rresp onding comp onents in G α t , namely M i X j =1 G i,j α t = δ i , i = 1 , 2 , · · · , N (16) Thu s P α t bec omes a constant given b y P α t = P N i =1 δ i P N i =1 M i = 1 K N X i =1 δ i ∈ (0 , 1) (17) See Fig .1 (rig ht ), the distribution work in ea ch g roup is done by a distributor , hence the prop osed structur e is c a lled Gr oup e d Distributor Unit (GDU) . The distributor is implemented by utilizing the so ftmax activ a tion ov er each gro up individually in ca lculating G α t : ϑ t = W α x t + U α s t − 1 + b α (18a) d i,j t = exp( ϑ i,j t ) P M i j =1 exp( ϑ i,j t ) (18b) G i,j α t = ( δ i · d i,j t if δ i ∈ (0 , 1 ] M i − δ i M i − 1 · d i,j t + δ i − 1 M i − 1 if δ i ∈ (1 , M i ) (18c) here 1 ≤ i ≤ N , 1 ≤ j ≤ M i and ϑ t = ( ϑ 1 , 1 t , · · · , ϑ 1 ,M 1 t , · · · , ϑ N , 1 t , · · · , ϑ N ,M N t ) T . 4 Note tha t G i,j α t ∈ [0 , δ i ) when δ i ∈ (0 , 1] and G i,j α t ∈ ( δ i − 1 M i − 1 , 1] when δ i ∈ (1 , M i ). The r e sulting GDU is given by a t = ζ ( W α x t + U α s t − 1 + b α ; { δ i , M i } N i =1 ) (19a) s t = (1 − a t ) ⊙ s t − 1 + a t ⊙ tanh( W s x t + U s s t − 1 + b s ) (19b) where ζ ( · , { δ i , M i } N i =1 ) denotes distributor op era tor with g r oup co nfiguration { δ i , M i } N i =1 as is detailed in Eq s. (18). In this pape r , we let δ i = 1 , i = 1 , 2 , · · · , N . As a cons equence, P α t = N P N i =1 M i = N K (20) If the size of each state gr oup is set to a c onstant M , P α t will b e further r educed to 1 M . GDU has an inherent strength to keep a lo ng-term memo r y since any satu- rated state unit s i,j will force a ll other gro up members to la tch information. As 4 The p ermuta tion of n ϑ i,j t o M i j =1 N i =1 can b e arbitrary . 8 a r esult, “bandwidth” is wider for long - term informatio n to travel forward and error sig nals to back-propag ate (see Fig .6 (right) ). Like CW- RNN, we set a n ex plicit r ate δ i for ea ch group. How ever, instea d of mak ing all gr oup members act in the same wa y , we allow each unit to find its own r ate by learning. 4. Exp e riment s W e ev a luated the prop osed GDU on b oth pathologic al synthetic tasks and natural data set in compariso n with LSTM and GRU. I t is imp o rtant to po int out that although LSTM and GRU have similar p erformanc e in na ture da ta set [21], one model may outp erfor m ano ther by a huge gap in different pathologica l tasks lik e the adding pr o blem (see 4.1) at which GRU is go o d and the temp ora l order problem (see 4 .2) in which LSTM p erfor ms b etter. If no t otherwise sp ecified, all netw orks have one hidden layer with a same state size. W eigh t v aria bles were initialized v ia Xavier unifor m initializer [24], and the initia l v alues o f all internal state v ar iable were s et to 0. All netw orks were trained using Adam o ptimization metho d [2 5] v ia BPTT, and the mo dels were implemented using T ensor flow [26]. In GDU mo dels, δ i = 1 a pply to a ll groups. 4.1. The adding pr oblem The adding pro blem is a seq ue nce r e gressio n problem which was originally prop osed in [4] to exa mine the a bilit y of recurr e nt mo dels to ca pture long-ter m depe ndencie s. Two sequences o f length L a r e taken as input. The firs t o ne consists of r eal num b ers s a mpled from a unifor m distribution in [0 , 1 ]. While the second sequence serves as indicators with exactly tw o entries b eing 1 and the remaining being 0. W e follow e d the s ettings in [27] wher e L is a constant and the first 1 entry is lo cated uniformly at r andom in the first half o f the indicator sequence, whilst the second 1 e n try is lo cated uniformly at rando m in another half. The targ et of this problem is to add up the tw o entries in the first sequence whose corresp onding indicator in the second sequence is 1. A na ive strategy of outputting 1 rega rdless of the inputs yields a mean squar ed err or of 0 . 167, whic h is the v ar iance of the sum of tw o independent uniform distributio ns ov er [0 , 1]. W e to ok it a s the bas eline. F our different lengths o f sequences, L ∈ { 200 , 10 00 , 5 0 00 , 1 0000 } were used in this exp eriment. F or each length, 50 0 sequences were generated for testing, while a batch of 20 sequences were randomly generated at each training step. F our mo dels, an LSTM with 1 00 hidden states, a GRU with 10 0 hidden states, a GDU with 10 groups o f size 10 and a GDU with only 1 gro up of size 10 were compared, with the corres po nding par a meter nu mber 41 . 3 K , 31 . 0 K , 20 . 7 K and 271. A simple linea r lay er without activ ation is stack ed on top of the recurr ent lay er in ea ch mo del. The res ults are shown in Fig . 2. O bviously GRU outp erforms LSTM in these tria ls. LSTM fa ils to co n verge w ithin 10 0 00 tra ining steps when L is 1 000 9 5 0 0 1 0 0 0 1 5 0 0 T ra i ni n g st e p s 0 .0 0 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 T e st M S E S e q u e n c e l e n g t h = 2 0 0 B a s e l i n e L S T M ( 1 0 0 ) G R U ( 1 0 0 ) G D U ( 1 0 x 1 0 ) G D U ( 1 0 x 1 ) 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 T ra i ni n g st e p s 0 .0 0 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 T e st M S E S e q u e n c e l e n g t h = 1 0 0 0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 T ra i ni n g st e p s 0 .0 0 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 T e st M S E S e q u e n c e l e n g t h = 5 0 0 0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 T ra i ni n g st e p s 0 .0 0 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 T e st M S E S e q u e n c e l e n g t h = 1 0 0 0 0 Figure 2: The results of the adding problem on differen t sequence lengths. The legends for all s ub-figures are the same th us are only shown in the first s ub-figure, in whic h state sizes are specified following mo del names. F or a GDU mo del, ( M × N ) means it has N groups of size M . Eac h training tri al wa s stopp ed when the test MSE r eac hed b elow 0 . 002, as indicated b y a short vertical bar. When training with sequences of length 1000, LSTM(100) failed to con v erge within 10000 steps and only the curve of the first 2000 steps is shown. 10 while GRU can learn this task within 130 0 steps even tra ined with seq ue nc e s of length 1000 0 . Our GDU mo dels per form slightly b etter than GRU with less parameters . As L increas es, this adv antage b ecomes more obvious. Note that a GDU with only one group of size 10 has compar able p erforma nce with a muc h bigger one, which indicates that GDU ca n efficiently capture simple long-term depe ndencie s even with a tiny mo del. 4.2. The 3-bit temp or al or der pr oblem The 3-bit temp oral order problem is a sequence clas sification pro ble m to examine the a bility of recurrent mo dels to extract information convey ed by the tempo ral order of widely separ ated inputs of r e c urrent mo dels [4]. The input sequence consists of rando mly c hosen symbols fro m the set { a, b, c, d } except for thr ee elements at p osition t 1 , t 2 and t 3 that are either X or Y . Position t k is randomly chosen b e t ween ⌊ ( k − 1) · L 3 ⌋ a nd ⌊ ( k − 1) · L 3 ⌋ + 10, wher e k = 1 , 2 , 3 and L is the sequence leng th. The target is to cla ssify the or der (either XXX, XXY, XYX, XYY, YXX, YXY, YYX, YYY) which is r epresented lo cally using 8 units, a s well as the input symbol (repres ent ed using 6 units). F our different lengths of s equences, L ∈ { 10 0 , 20 0 , 50 0 , 10 0 0 } were us ed in this exper imen t. Same with the settings in 4.1, w e gener ated 500 testing se- quences for e ach length, and randomly genera ted a batch of 2 0 sequences for each training step. Accura cy is used as the metric on testing set, a nd the base- line is 0 . 125. W e compared an LSTM mo del with 100 hidden s tates, a GR U mo del with 10 0 hidden states and a GDU with 1 0 gr o ups o f s ize 10 o n these data sets. The parameter nu mbers are 43 . 6 K , 32 . 9 K and 2 2 . 2 K resp ectively . The results a re s hown in Fig.3. In co n trast to the results of the a dding problem, LSTM outperforms GRU on this task. Ho wev er, b oth LSTM and GR U fail in learning to disting uis h the tempor al order when the sequence leng th increases to 500. The GDU mo del with P α t = 0 . 1 a lwa y s s tarts learning earlier . When trained with relatively long er sequences , GDU outp erfor ms these 2 mo dels by a la r ge mar gin with muc h les s parameters. 4.3. Multi-emb e dde d Reb er gr ammar Embeded Reb er gr ammar (ERG) [2 8, 4] is a go o d example containing de- pendenc ie s with differen t time scales . This task needs RNNs to read s trings, one symbol a t a time, and to predict the nex t symbol (error signals o ccur at every time s tep). T o cor r ectly predict the symbol b efore last, a mo del has to remember the seco nd symbo l. How ever, sinc e it allows for training seq uences with short time lags (of as few as 9 s teps), using it to ev aluate a mo del’s ability to lear n long-ter m dependenc y is not appropria te. In order to make the tr ain- ing sequences longer, we mo dified the ERG by having multiple Reb er s trings embedded betw een the s econd a nd the last but one symbols (See Fig.4). W e refer to this v a r iant as the mult i-emb e dde d R eb er gr ammar (mERG) and simply use the prefix m to indicate the num b er of em b e dded Re b er strings . F or example, “BT(BPVVE)(BTSXSE)(BTXXVVE)TE” is a 3ERG sequence. 11 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 2 5 0 0 T r a i ni n g st e p s 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T e st Ac c u r a c y S e q u e n c e l e n g t h = 1 0 0 B a s e l i n e L S T M ( 1 0 0 ) G R U ( 1 0 0 ) G D U ( 1 0 x 1 0 ) 2 0 0 0 4 0 0 0 6 0 0 0 8 0 0 0 1 0 0 0 0 T ra i ni n g st e p s 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T e st Ac c u r a c y S e q u e n c e l e n g t h = 2 0 0 1 0 0 0 2 0 0 0 3 0 0 0 4 0 0 0 5 0 0 0 6 0 0 0 T ra i ni n g st e p s 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T e st Ac c ura c y S e q u e n c e l e n g t h = 5 0 0 1 0 0 0 2 0 0 0 3 0 0 0 4 0 0 0 5 0 0 0 6 0 0 0 T ra i ni n g st e p s 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 T e st Ac c ura c y S e q u e n c e l e n g t h = 1 0 0 0 Figure 3: The results of the 3- bits tempor al or der problem on differen t sequence lengths. The legends containing the information of model size are only shown in the first sub-figure. Eac h trial was stopp ed if all sequences in testing set are classified correctly , as indicated by a dashed ve rtical line. When sequence l ength is 500, b oth LSTM and GRU failed within 50000 training steps, and their accuracy curves, which k eeps fluctuating around the baseline are partially plotted. B E T P S V T X X V P S B E T P T P REBER GRAMMA · · · REBER GRAMMA REBER GRAMMA · · · REBER GRAMMA m Reb er strings Figure 4: Left : T rainsition diagram f or the Reber grammar . Right : T ransi tion diagram for the multi-em bedded Reber grammar. Each b ox represents a Reb er stri ng. 12 Since each Reb er str ing has a minimal length 5 , the shortes t m ERG sequence has a leng th of 5 m + 4. Learning m ERG requir es a recurrent mo del to ha ve the ability to latch long- term memory while keeping mid- and sho rt-term memory (provided m is big) in the meant ime. F ur ther, there may b e tw o leg al successors fro m a g iven symbol and the mo del will never be able to do a perfect job of prediction. During training, the rules defining the gra mmar are never prese nted. Thus the mo del will see contradictory examples , sometimes with one successor a nd sometimes the other, whic h requir es it to learn to activ ate both legal o utputs. Wha t’s more, a mo del m ust remember how man y Reb er strings it has read to make a correct pr ediction o f the next sym b ol if the current symbo l is an E. In other words, mo de ls m ust lea rn to coun t . W e set m to be 10, 20 and 40 for this task, with the minimal s equence length 54, 104 and 204 r esp ectively . One sequence is given at a time. As for the symbols with 2 legal successors, a prediction is considered correct if the t wo desired outputs ar e the tw o with the largest v a lues. F or ea ch m w e genera ted 1000 sequences for training and 256 sequences for testing . The seq ue nc e s in testing set a re unique and hav e never app eared in tra ining set. The same training and testing s ets are used for compa ring all mo dels. W e also defined tw o criteria to test the mo del’s ability to captur e long- and short-term dep endencies separa tely . The one for s hort-term dep endency is S C (short for short- ter m criterio n) defined a s the p ercentages of tes ting seq uences each symbol of which is predicted cor r ectly b y the mo del exce pt fo r the one befo re last. The other is LC (short for long-term criter ion) defined as the per centages of testing sequences whose last but one symbo l is pr edicted corr ectly . W e stopp ed the training when b oth S C and LC are sa tisfied (rea ch to 1), namely all s ymbols in a ll testing sequences are predicted correctly . A naive stra tegy of predicting the symbol befor e last a s T or P gives an exp ected LC o f 0 . 5 , which serves as the baseline. An LSTM mo del and a GRU mo del b oth with 1 00 hidden states were chosen to be compa red a s previous, with corres po nding para meter n umbers 43 . 9 K and 33 . 1 K . As for GDU, we chose a mo del with 35 groups of size 2 and 3 groups of s ize 10 (denoted a s GDU(2x35+10 x 3)), totally 10 0 hidden units and 22 . 3 K parameters . F rom the results presented in Fig. 5, we can see for m ERG, mo dels alwa ys learn to capture the short-term dep endencies first. While the long- term dep en- dency is muc h mor e difficult to lea rn. GRU outp erforms LSTM this time, no matter from the asp ect of which c r iterion. GDU is slig ht ly inferio r to LSTM and GR U in ter ms o f S C . How ever, on asp ect of L C , it has a n o bvious adv antage. As discussed in Sec tio n 2, learning to latc h lo ng-term informa tion in the presence of s hort-term dep endencies is difficult for a tra ditional GAST mo del due to the gra dient conflict. GDU g r eatly a lleviate this problem by limiting P α t in cGAST, namely the prop or tion of states to be ov erwritten, which results in a br oader “bandwidth” for long- term information flow. Fig. 6 illustr ates this by visualizing the G β t activ ation of GAST mo dels on a sa me 10 ERG s equence after the L C has been satisfied. 13 S C LC S C & L C 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 T ra i n in g st e p s (t h o u sa nd s) L S T M ( 1 0 0 ) S C LC S C & L C GR U(1 0 0 ) S C LC S C & L C G DU(2 x 3 5 + 1 0 x3 ) m = 1 0 S C LC S C & L C 0 2 0 4 0 6 0 8 0 1 0 0 1 2 0 1 4 0 1 6 0 T ra i n in g st e p s (t h o u sa nd s) L S T M (1 0 0 ) SC LC S C & L C GR U(1 0 0 ) S C LC S C & L C GDU(2 x 3 5 + 1 0 x 3 ) m = 2 0 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 T r a i n in g ste p s (t h o u sa n d s) 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 L C m = 4 0 GDU (2 x3 5 + 1 0 x 3 ) GR U(1 0 0 ) L S T M (1 0 0 ) Ba se li n e 2 6 0 2 8 0 3 0 0 3 2 0 3 4 0 3 6 0 3 8 0 4 0 0 4 2 0 L e ng th 0 % 2 % 4 % 6 % 8 % 1 0 % De n si ty S e q u e n c e l e n g t h d i s t r i b u t i o n , m = 4 0 Figure 5: The results of the multi-em bedded Reber gr ammar. The upper left and righ t figures sho w the training steps eac h mo del tak es to satisfy the criteri a (reach to 1.0) for m = 10 or 20. Eac h b o x-whisker (sho wing median, 25% and 75% quan tiles, minimum, maximum and outliers) con tains the corresponding r esults of 10 trials. F or m = 40 we only giv e the b est results of each mo del in the bot tom left figure. The b ott om r ight figure shows the density histogram of sequence lengths in 40ERG training set. time ste p G R U ( 1 0 0 ) 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 t i me ste p G D U ( 2 x 3 5 + 1 0 x 3 ) 0 .0 0 .1 0 .2 0 .3 0 .4 0 .5 0 .6 0 .7 0 .8 0 .9 1 .0 Figure 6: T he activ ation of G β t of GRU(1 00) ( left ) and GDU(2x35+10x3) ( rig h t ) on a same sequence from 10ERG testing set. Eac h column corresponds to the gate activ ation at one time step. Each row with contin uous dark color corresp onds to a gate unit whi c h kee ps activ e and th us latches information. 14 Mo del # parameters ( ≈ , K ) T est Accura cy LSTM(128) 67.9 91.2 GR U(128) 51.2 90.6 GDU(4x32) 34.6 93.5 GDU(5x25) 33.0 93.0 LSTM(256) 266.8 91.8 GR U(256) 200.7 92.6 GDU(4x62) 134.7 94.7 GDU(5x51) 133.6 94.8 T able 1: Results f or p ermut ed pixel-by-pixel MNIST. Best result i n each mo del set are b old. 4.4. Se quential pMNIST classific ation The seq uent ial MNIST task [8] can b e seen as a s equence clas s ification task in which 28 × 2 8 MNIST ima g es [29] of 1 0 digits a re rea d pixel by pixel from left to rig ht, top to b ottom. While the sequential p MNIST [8] is a challenging v ariant where the pixels are p ermuted by a same rando mly gener ated pe r mut a- tion matrix. This creates many longe r term dep endencies a cross pixels than in the origina l pixel ordering, which makes it necessa ry for a mo del to learn and remember more co mplica ted dependencie s em b edded in v a rying time scales. All models ar e trained with batch size of 10 0 and the learning rate is se t to 0 . 001. No tricks, s uch as drop out [30], g radient clipping [17], r ecurrent batch normalizatio n [31], etc., ar e used since we a re not fo cusing on achieving absolute high accura cy . W e trained tw o sets of mo dels with 1 28 a nd 256 hidden states resp ectively . Again, GDU o utper forms LSTM a nd GRU with less par a meters in this task a s shown in T able 1. 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 T i m e ste p t 1 0 -4 1 0 -3 1 0 -2 1 0 -1 1 0 0 1 0 1 No rm a l i ze d g r a d i e nt n o r m A f t e r 5 e p o c h s L S T M ( 1 2 8 ) G R U ( 1 2 8 ) G D U ( 4 x 3 2 ) G D U ( 5 x 2 5 ) 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 T i me st e p t 1 0 -4 1 0 -3 1 0 -2 1 0 -1 1 0 0 1 0 1 No rma l i ze d g r a d i e nt n o r m A f t e r 5 0 e p o c h s Figure 7: Nor ms of the error signal bac k-propagated to eac h time step, i. e. k ε t ← 784 k = L s t after 5 ep o c hs ( left ) and 50 ep o chs ( rig h t ). F or LSTM model, we calculate L ˆ s t instead of L s t , where ˆ s t is a concatenat ion of s t and h t = γ t ( s t ). As discuss ed in Se c tio n 2, controlling L s t is the k ey to av oid the v a nishing gradient issue, so that lo ng-term dep endencies can b e lear ned. W e ex plo red how 15 each mo del propa gated gradients by ex a mining L s t as a function of t , where L is the prediction loss. Gra dient nor ms were computed after 5 and 5 0 epo chs and the no rmalized curves a re plotted in Fig. 7 . F or LSTM a nd GRU, we can see tha t error signals have trouble in r eaching far from where they are injected at the ea r ly stage . This problem is r educed a fter tra ining fo r doze ns of ep o chs. GDU mo dels hav e b etter gradient prop erties than LSTM a nd GR U be c ause of the distributor mec hanism in Eqs. (18). 5. Conclus ions and future work W e prop osed a nov el RNN ar chitecture with ga ted additive sta te tr ansition which co nt ains only o ne ga te unit. The issues of g radient v anishing and co nflict are mitiga ted b y explicitly limiting the pr o p ortion of s tates to b e overwritten at each time step. Our exp eriments mainly fo cused on challenging pathological problems. The results were consistent over different task s and clearly demon- strated that the prop osed g roup ed distributor architecture is helpful to extract long-term de p endencies em b edded in data. A plethor a of further ideas ca n b e explored based o n o ur findings. F or example, v a rious combinations of g roups with differ ent sizes and ov er write pr o- po rtions can b e explored. F urther, the ov erwrite prop or tio n δ can b e traine d. What’s more in teresting is that the gr oup ed distributor structure can b e used spatially to ease gr adient-based training of very deep net works. T o b e mor e sp e- cific, this work c an base o n the highway network [32] in which the distributor op erator ca n b e used to calc ula te the tr ansform gate . T estings of the stack ed GDU o n other data se ts are also planned. References [1] Da vid E . Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Lear ning representations by back-propagating er rors. Natur e , 32 3:533– 536, 1 986. [2] P aul J.W e r b os. Ge ner alization o f backpropaga tion with application to a recurrent ga s market mo del. N eur al N etworks , 1:339–3 56, 1988. [3] Sepp Ho chreiter, Y oshua Bengio, and Paolo F rasco ni. Gradient flow in re- current nets: the difficulty of learning long-ter m dep endencies. In J. Ko len and S. Kr emer, editors, Field Guide to Dynamic al Re curr ent N et works . IEEE Press , 2001 . [4] Sepp Ho chreiter and J ¨ urgen Sc hmidhuber. Long short-term memor y . Neu- r al Comput. , 9(8):173 5–178 0, 199 7. [5] James Martens . Deep lear ning via hessian- fr ee optimization. In Pr o c e e d- ings of t he 27th Intern at ional Confer enc e on International Confer enc e on Machine L e arning , ICML’10 , pa g es 73 5 –742 , USA, 20 10. O mnipr ess. 16 [6] James Ma rtens a nd Ily a Sutskever. Le a rning recurrent neur al net w orks with hessian-free optimiza tion. In Pr o c e e dings of the 28th International Confer enc e on International Confer enc e on Mach ine L e arning , ICML’11 , pages 1033 – 1040 , USA, 2011 . Omnipress. [7] Andrew M. Saxe, Ja mes L. McClella nd, and Surya Ganguli. Ex act so lutions to the no nlinear dynamics o f learning in deep linea r neur al netw orks , 2013 . [8] Quoc V. Le, Navdeep J aitly , and Geoffrey E. Hin ton. A simple w ay to initialize recurr e n t netw o rks o f rectified linea r units, 2 015. [9] Tsungnan Lin, B. G. Horne, P . Tino, and C. L. Giles. Learning long- term dep endencies in narx recur rent neural netw orks. T r ans. Neur. Netw. , 7(6):1329 –133 8, 199 6. [10] Shiyu Chang, Y ang Zhang, W ei Han, Mo Y u, Xiaoxiao Guo, W ei T an, Xi- ao dong Cui, Mic hael Witbro ck, Mar k A Haseg aw a -Johnson, and Thomas S Huang. Dilated r ecurrent neural netw orks. In I. Guyon, U. V. Lux burg, S. Bengio, H. W a llach, R. F erg us , S. Vishw ana tha n, and R. Gar ne tt, e di- tors, A dvanc es in Neur al Information Pr o c essing Systems 30 , pages 77 –87. Curran Asso ciates, Inc., 2017. [11] Rob er t DiPietro, Christian Rupprech t, Nassir Nav ab, a nd Gr egory D. Hager. Analyzing and exploiting NARX recurr ent neural netw o rks for long - term dep e ndencies, 2018 . [12] K y unghyun Cho , Bart v a n Merr ienbo er, Caglar Gulcehr e, Dzmitry Bah- danau, F ethi Bougar es, Holger Sch wenk, and Y os h ua Bengio. L e arning phrase repr esentations using RNN enco der -deco der for statistical machine translation, 2014 . [13] David Sussillo Jasmine Collins, Jascha So hl-Dickstein. Capa city and train- ability in re c urrent neural net works. In In ternational Confer en c e on L e arn- ing Re pr esentations , 20 16. [14] Guo- Bing Zhou, Jianxin W u, Chen-Lin Zha ng, and Zhi-Hua Zho u. Minimal gated unit for recurrent neural net works, 2016 . [15] Ja n Koutnik, K laus Greff, F a ustino Gomez, and J ue r gen Schmidh ub er. A clo ckw o rk RNN. In Eric P . Xing and T o ny Jebar a, e dito rs, Pr o c e e dings of the 31st International Confer en c e on Machine L e arning , volume 32 of Pr o- c e e dings of Machine L e arning R ese ar ch , pages 1863–1 8 71, Bejing, China, 2014. PMLR. [16] Je ffr ey L. Elman. Finding structur e in time. COGNITIVE SCIENCE , 14(2):179 –211 , 19 90. [17] Raz v an Pascanu, T omas Mikolov, a nd Y os hu a Beng io. On the difficulty of training r ecurrent neural netw orks . In Pr o c e e dings of the 30th In ternational Confer enc e on International Confer enc e on Machine L e arning - V olume 28 , ICML’13, pages I II– 1310 – I II – 1318 . JMLR.org , 2013. 17 [18] F elix A. Gers, J ¨ urgen A. Schmidh ube r , and F red A. Cummins. Le arning to forget: Con tinual prediction with lstm. Neur al Comput. , 12 (1 0):2451 –2471 , Octob er 2000. [19] F elix A. Ger s and Juergen Schmidh uber . Recurr ent nets that time and count. T echnical rep ort, 2000. [20] K la us Greff; Rup esh K. Sr iv astav a ; Jan Koutn ´ ık ; Bas R. Steunebrink ; J ¨ urgen Schmidh ube r. Lstm: A sea rch space o dy s sey . IEEE T r ansactions on N eu r al Networks and L e arning S ystems , 2 8(8):222 2–223 2, 201 7. [21] Junyoung Chung, Ca g lar Gulcehre, Kyung hyun Cho, and Y os hua B e ngio. Empirical e v aluation of ga ted recurr ent neural netw o r ks on sequence mo d- eling. In NIPS 2014 Workshop on De ep L e arning, De c emb er 2014 , 201 4. [22] K la us Greff, Rupesh Kuma r Sriv a stav a, Jan Koutnk, Ba s R. Steune- brink, and Jrgen Schmidh ub er. Lstm: A search spa ce o dys sey . CoRR , abs/15 03.040 69, 20 15. [23] Sala h E l Hihi and Y oshua Bengio. Hierar chical re c urrent neural netw orks for long-term depe ndencie s. 19 96. [24] Xavier Glo rot and Y oshua Bengio. Understanding the difficult y of training deep feedforward neur al netw orks . In In Pr o c e e dings of t he In ternational Confer enc e on Artificial Intel ligenc e and S tatistics (AIST A TS10). S o ciety for Artificial Int el ligenc e and Statistics , 20 1 0. [25] Diederik P . K ingma and Jimmy Ba . Adam: A method for sto chastic opti- mization. In ICLR , 201 5 . [26] Mar tn Abadi, Ashish Aga rwal, P aul Barham, Eugene Brevdo , Zhifeng Chen, Craig Citro, Gr eg Corrado, Andy Davis, Jeffrey Dean, Ma tthieu Devin, Sanjay Ghemaw a t, Ian Go o dfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Y a ng qing J ia , Rafal Jozefowicz, Luk a sz Ka iser, Manjunath Kudlur, Josh Leven b erg , Dan Man, Ra jat Mo nga, Sher ry Mo ore, Derek Murray , Chris Ola h, Mike Sch uster, Jonathon Shlens, Benoit Steiner , Ilya Sutskev er , K una l T a lwar, Paul T uck er , Vincent V a nhouck e , Vijay V as ude- v an, F ernanda Viga s, Oriol Vin yals, Pete W arden, Martin W attenberg, Martin Wic ke, Y uan Y u, and Xiao qiang Zheng. T ensorflow: Lar g e-scale machine lear ning on heterogeneous distributed systems, 2015. [27] Mar tin Arjovsky , Amar Shah, a nd Y oshua B engio. Unitary evolution r e - current neural netw or ks, 20 15. [28] Sco tt E. F ahlman. The recurrent casca de-corr elation ar chitecture. In R. P . Lippmann, J. E. Mo o dy , and D. S. T ouretzky , editors , A dvanc es in Neu- r al In formation Pr o c essing S ystems 3 , pages 190 –196. Mor gan-Ka ufmann, 1991. 18 [29] Y a nn Lecun, Lon Bottou, Y oshua Bengio, a nd Patrick Haffner. Gradient- based learning applied to do cument reco gnition. In Pr o c e e dings of the IEEE , pages 2278 –2324 , 1998 . [30] Nitish Sriv as tav a, Geoffrey Hinton, Alex Kr izhevsky , Ilya Sutskever, and Ruslan Salak hutdinov. Drop out: A simple wa y to pre vent neural netw o rks from overfitting. Journ al of Machi ne L e arning Re se ar ch , 15:192 9 –195 8, 2014. [31] Tim Co o ijmans, Nicola s Ba llas, C´ esar Laurent, and Aaron C. Courville. Recurrent batch normaliza tion, 20 16. [32] Rup esh Kumar Sr iv astav a , Klaus Gr eff, and J ¨ urgen Schmidh ub er. Highw ay net works, 201 5. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment