반복 제거 기반 특성 순위 매김: ttH 분석에서 최적 변수 선택
본 논문은 LHC ttH → bb̄ 검색에 사용된 26개의 입력 변수를 대상으로, BDT 성능을 기준으로 다양한 특성 순위 매김 방법을 비교한다. 반복 제거(Iterative Removal) 방식이 가장 높은 AUROC를 빠르게 달성하며, 12개의 변수만으로도 전체 성능의 99%에 도달함을 보였다. 그러나 CPU 비용이 가장 크게 소요되는 반면, 순열 중요도(Permutation Importance)와 BDT 선택 빈도(BDT Selection…
저자: Paul Glaysher, Judith M. Katzy, Sitong An
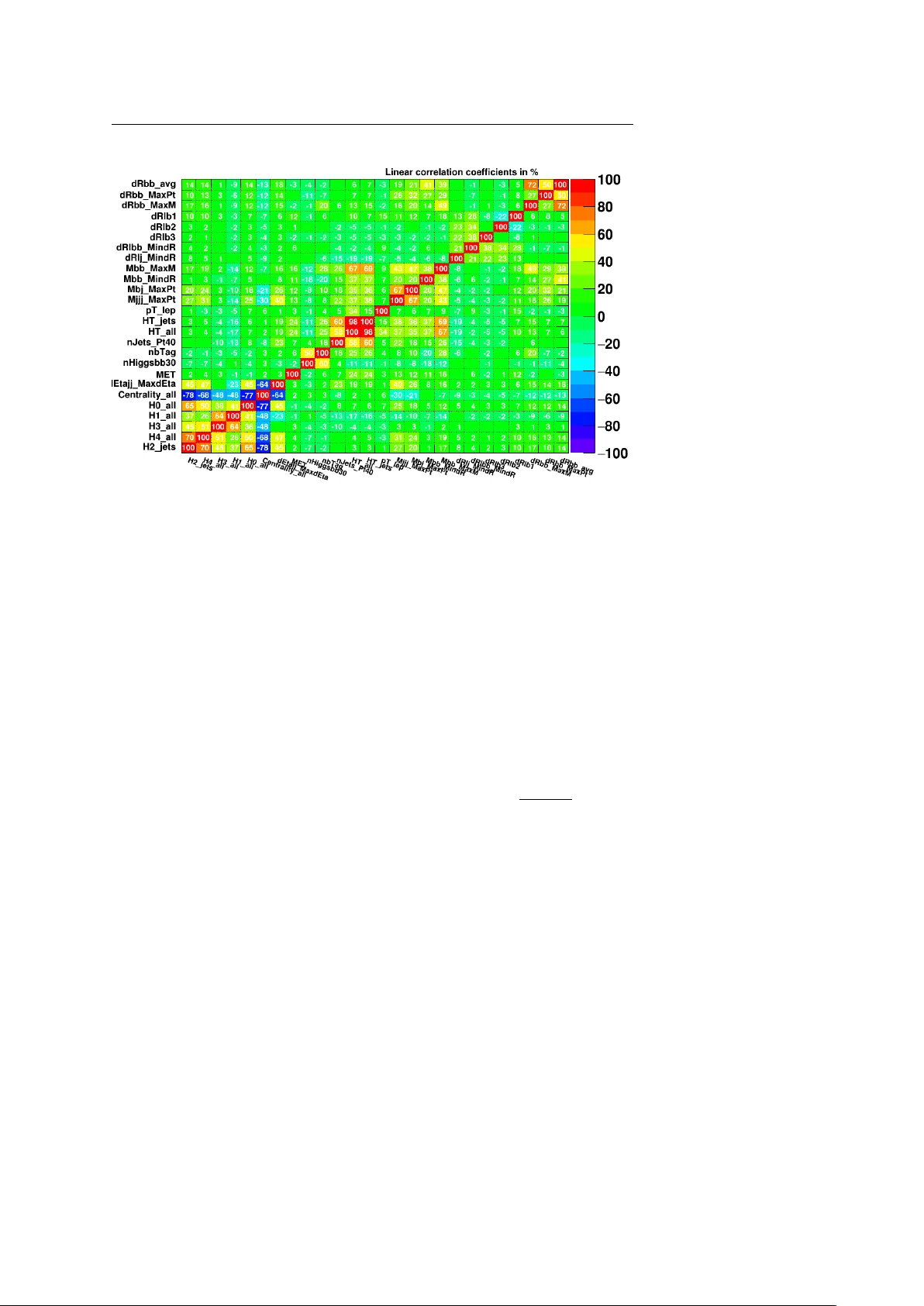
본 논문은 고에너지 물리 실험, 특히 LHC에서 수행되는 ttH → bb̄ 검색에 사용되는 부스티드 결정 트리(BDT) 분류기의 입력 변수(특성) 중요도를 평가하기 위해 다양한 특성 순위 매김 알고리즘을 비교·분석하였다. 연구 배경으로, 물리 분석에서 사용되는 변수들은 종종 높은 상관관계를 가지며, 어떤 변수가 실제 신호와 배경을 구분하는 데 가장 기여하는지 판단하는 것이 비단 모델 해석뿐 아니라 훈련 샘플이 제한된 상황에서 차원 축소와 학습 효율성을 위해서도 중요함을 제시한다.
데이터 셋은 ATLAS ttH → bb̄ 분석을 모방한 MC 샘플로, MadGraph와 Herwig6·Pythia6을 이용해 시그널(13 M 이벤트)과 두 종류의 배경(2 M·tt+light, 10 M·tt+bb̄)을 생성하고, Delphes를 통해 탐지기 시뮬레이션을 수행하였다. 전처리 단계에서 전자·뮤온 p_T ≥ 20 GeV, 최소 5개의 제트(p_T ≥ 25 GeV) 및 최소 3개의 b‑제트를 요구해 최종적으로 700 k 시그널·275 k 배경 이벤트를 확보하였다. 이들 이벤트에서 26개의 물리적 변수(예: dR_bb avg, HT_all, M_bb MaxM, nHiggs_bb30 등)를 추출했으며, 각 변수의 신호‑배경 구분력은 1%~8% 사이, 상관계수는 거의 무관함부터 강한 반(음)상관까지 다양했다.
BDT는 TMVA 구현을 사용해 400개의 트리, 최대 깊이 5, AdaBoost(β = 0.15), nCuts = 80으로 설정했으며, 전체 변수 집합(N = 26)으로 기본 모델을 학습하였다. 특성 순위 매김 방법은 다음과 같이 7가지로 구분된다.
1. **Random Selection** – n = 3까지는 모든 조합을 평가하고, n ≥ 4에서는 1000번의 무작위 조합을 샘플링해 평균·최대 AUROC를 기록한다.
2. **Separation based** – 변수별 신호‑배경 차이(절대값 적분)를 이용해 순위를 매기며, BDT 재학습 없이 평가한다.
3. **Correlation based** – 전체 BDT 점수와 각 변수의 피어슨 상관계수를 이용해 순위를 매긴다.
4. **BDT Selection Frequency** – 전체 변수로 BDT를 학습한 뒤, 각 트리에서 최적 분할을 담당한 횟수를 집계한다.
5. **Permutation Importance (Mean Decrease Accuracy)** – 변수 값을 동일 분포의 무작위 값으로 대체하고 AUROC 감소량을 측정한다.
6. **Iterative Addition** – 현재 집합에 가장 AUROC를 향상시키는 변수를 순차적으로 추가한다. 전체 조합 수는 N·(N‑1)/2 = 406번의 BDT 학습이 필요하다.
7. **Iterative Removal** – 전체 변수로 BDT를 학습한 뒤, 성능 저하가 가장 적은 변수를 단계적으로 제거한다. 역시 406번의 BDT 학습이 요구된다.
각 방법별로 n개의 상위 변수를 선택해 BDT를 재학습하고, AUROC를 성능 지표로 사용해 비교하였다. 결과는 다음과 같다.
- **Iterative Removal**는 12개의 변수만으로 전체 AUROC의 99%를 달성했으며, 전체 변수 사용 시와 거의 동일한 성능을 보였다. 이는 변수 간 상관관계를 가장 잘 반영하면서도 불필요한 변수를 효율적으로 제거한다는 점을 의미한다. 다만, 초기 26변수로 BDT를 학습하고 매 단계마다 재학습을 수행해야 하므로 CPU 비용이 가장 높다.
- **Permutation Importance**는 계산량이 적음에도 불구하고 두 번째로 높은 성능을 보였으며, 16개의 변수에서 99% 수준에 도달한다. 이는 무작위 대체 방식이 변수의 실제 기여도를 잘 추정하면서도 반복 학습을 최소화한다는 장점이 있다.
- **BDT Selection Frequency**는 17개의 변수에서 유사한 성능을 보였으며, 구현이 간단하고 한 번의 BDT 학습만 필요해 실무에서 널리 사용된다.
- **Iterative Addition**은 16개의 변수에서 99% 수준에 도달했지만, Iterative Removal에 비해 초기 성능이 다소 낮았다.
- **Correlation based**와 **Random selection (median)**은 중간 정도의 성능을 보였으며, 변수 수가 24개에 이를 때까지 plateau에 도달하지 못했다.
- **Separation based**는 전체 구간에서 가장 낮은 AUROC를 기록했으며, 변수 간 상관을 무시하는 단순 방법이 물리 분석에 부적합함을 확인시켜준다.
상위 10개 변수의 교집합을 살펴보면, Iterative Removal와 Permutation Importance가 6개의 변수를 공유하고, 모든 방법이 dR_bb avg를 1위에 선정한다는 점에서 이 변수가 ttH → bb̄ 신호 구분에 가장 핵심적인 역할을 함을 알 수 있다. 또한, HT_all, M_bb MaxM, nHiggs_bb30 등도 여러 방법에서 일관되게 상위에 위치한다.
연구의 의의는 두 가지이다. 첫째, 물리 분석에서 변수 선택을 위한 최적화 전략을 제시함으로써, 제한된 MC 샘플로도 높은 분류 성능을 유지할 수 있게 한다. 둘째, 계산 비용과 성능 사이의 트레이드오프를 명확히 제시해, 실험 협업팀이 자원 제약에 맞는 방법을 선택하도록 돕는다. 향후 연구에서는 Iterative Removal의 CPU 부담을 줄이기 위한 병렬화 혹은 샘플링 기반 근사 기법을 도입하거나, 딥러닝 기반 모델에 적용해 비교 분석하는 방향이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기