Iterative subtraction method for Feature Ranking
Training features used to analyse physical processes are often highly correlated and determining which ones are most important for the classification is a non-trivial tasks. For the use case of a search for a top-quark pair produced in association wi…
Authors: Paul Glaysher, Judith M. Katzy, Sitong An
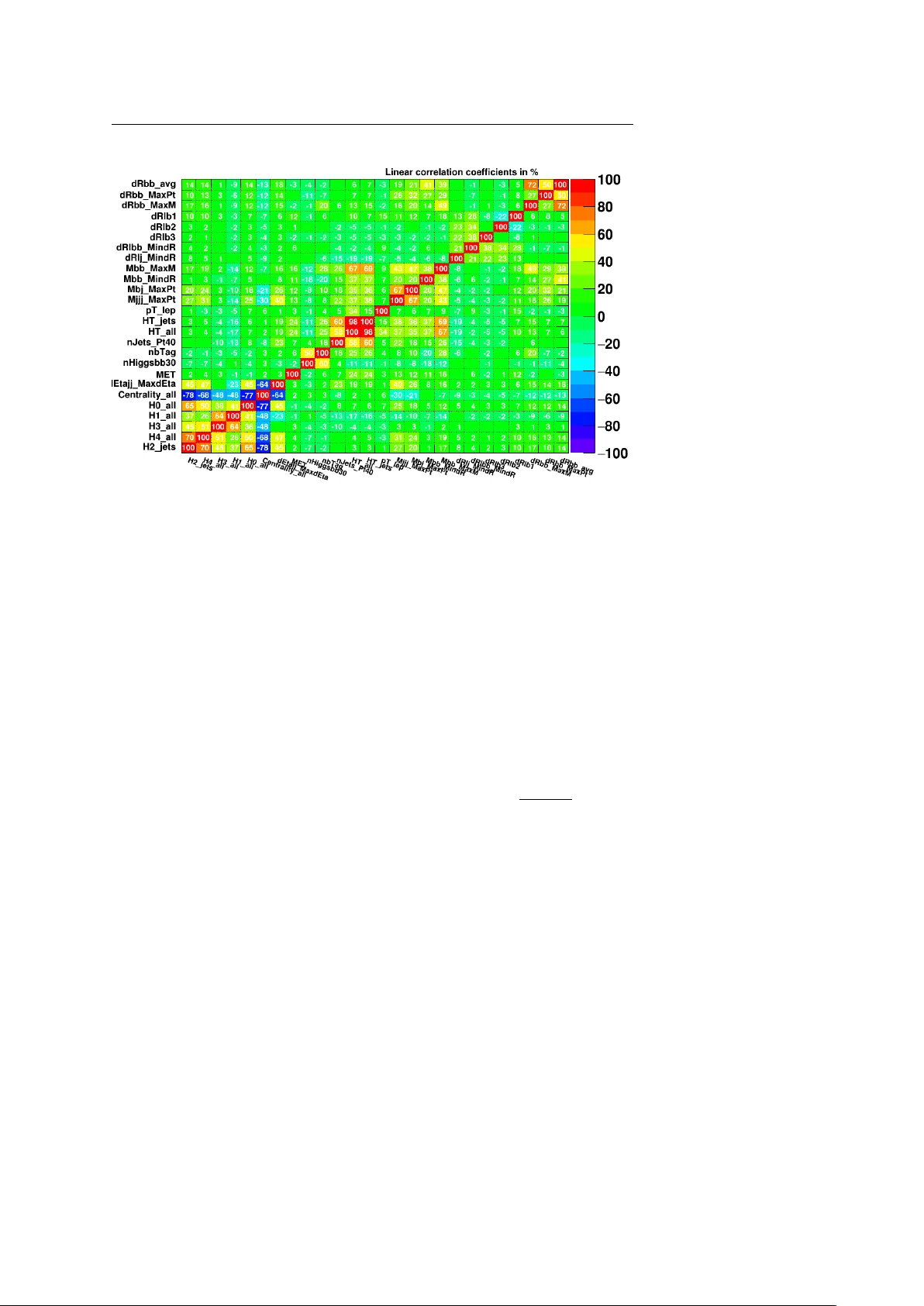
Noname man uscript No. (will b e inserted b y the editor) Iterativ e subtraction metho d for F eature Ranking P aul Gla ysher · Judith M. Katzy · Sitong An Received: date / Accepted: date Abstract T raining features used to analyse ph ysical pro cesses are often highly correlated and determining which ones are most important for the classification is a non-trivial tasks. F or the use case of a searc h for a top-quark pair pro duced in asso ciation with a Higgs b oson decaying to b ottom-quarks at the LHC, w e compare feature ranking metho ds for a classification BDT. Ranking metho ds, suc h as the BDT Selection F requency commonly used in High Energy Ph ysics and the P erm utational Performance, are compared with the computationally exp ense Iterativ e Addition and Iterativ e Remov al pro cedures, while the latter w as found to b e the most p erformant. Keyw ords Machine Learning · F eature Ranking · Bo osted Decision T rees · LHC · P ermutational P erformance · Iterativ e Remov al · V ariable imp ortance · Higgs 1 In tro duction Man y measurements and searc hes for new phenomena performed b y the exp eri- men ts at the Large Hadron Collider (LHC) use a Bo osted Decision T ree (BDT) to discriminate the physics pro cess of interest (signal) from other ph ysics pro- cesses with similar signature (background). The input v ariables (called fea- tures) to these BDTs are reconstructed from detector signals at different level of sophistication, hence forming low level and high level features. The v ariables are usually chosen based on the understanding of the physical pro cesses. The DESY Notkestr.85, 22607 Hamburg, Germany T el.: +49-40-89980 E-mail: paul.gla ysher@desy .de E-mail: judith.k atzy@desy .de E-mail: s.an@cern.c h All figures and pictures b y the author(s) under a CC BY 4.0 license. 2 Paul Glaysher et al. BDTs are t ypically trained by sup ervised learning on lab eled ev ents of simu- lated signal and bac kground pro cesses using the Mon te Carlo (MC) tec hnique. The resulting trained BDT is applied to unlabelled data to obtain measure- men t results. Kno wing the relativ e imp ortance of the input v ariables, i.e. ranking the features, helps in v arious aspects. Firstly , it allo ws to reduce unnecessary di- mensionalit y which is particularly imp ortan t when dealing with small training samples. This is often the case when machine learning algorithms are used to classify ph ysics pro cesses whic h are CPU exp ensive to simulate and hence only a limited sample size exist for training and testing. Reducing dimensionality also helps for faster training. F or example, the run time complexit y , i.e. the CPU time needed to construct a decision tree scales linearly with n umber of training v ariables [1]. While this may still b e manageable for BDTs, exp eri- ence shows that the training time for other machine learning algorithms (ML) suc h as neural netw orks ma y significantly increase with the n umber of input v ariables used. F eature ranking is also used as one p ossibility to gain insight in to the underlying model of a physical pro cess, i.e. the imp ortance of the selected v ariables for the analysis. It allows for analysis optimisation such as v alidating the mo delling of the inputs. Often potential training bias of the BDT response due to the particular MC generator used is estimated b y using alternative MC sim ulations leading to a slightly modified BDT resp onse which is then propagated into the uncertain ty of the measurements. F eature ranking will lead to a b etter understanding of the source of this difference and help reduce the measuremen t uncertainties. Ho wev er, the question whic h training features are most imp ortant for the classification ma y not ha v e a unique answ er, in particular when the input v ariables are highly correlated. Ranking v ariables to reduce dimensionalit y can be prob ed with training BDTs on a sub-set of v ariables with algorithms optimised to find the optimal sub-set. While the imp ortance of a v ariable for a giv en BDT classification migh t b etter b e prob ed b y using ranking algorithms estimating the effect of single v ariables on the classification of the BDT trained with the full set of input v ariables. This pap er studies v arious existing and new algorithm to select the b est v ariables to b e used for training. 2 Input v ariables and set-up The current study is inspired by the example of a classification BDT used in the search for the pro cess of top-quark-pair pro duction in asso ciation with a Higgs b oson (ttH) performed by the A TLAS experiment at LHC [2]. This searc h w as p erformed in the Higgs deca y c hannel where the Higgs deca ys to a pair of b ottom ( b ) quarks. The signal even ts con tain one electron or m uon, at least six jets and 4 b -quark jets. The dominant background is top-quark Iterative subtraction method for F eature Ranking 3 pair pro duction in asso ciation with a b -quark pair from gluon splitting which con tains the same final state ob jects ho wev er, with slightly differen t kinematic prop erties. W e use MC samples provided b y the HepSim Group[3]. The ttH signal sample containing 13 · 10 6 ev ents was generated with MadGrap h [4] matc hed to the Herwig6 parton sho wer [5]. Two bac kground samples w ere generated: 2 · 10 6 ev ents of top-pair pro duction with additional ligh t quarks using Mad- Graph matched to the Herwig6 and 10 · 10 6 ev ents of top-pair pro duction with additional b -quarks using MadGraph matched to Pythia6[6] . The t wo back- ground samples are orthogonal and are merged in to one bac kground sample with the differen t pro cesses weigh ted by their cross section. The A TLAS de- tector resp onse w as sim ulated using Delphes simulation [7]. F or this study , reconstructed jets and b -quark jets (called b -jets in the following) are used. The reconstructed b -jets ha ve a 70% tagging probabilit y . The corresp onding ligh t jet/c-jet rejection probability is parameterised according to [8]. Ev ents selected for the BDT training w ere required to fulfil the follo wing criteria: – one electron or muon with transverse momentum p T ≥ 20 GeV – at least 5 jets with p T ≥ 25 GeV – at least 3 b -jets. After this selection 700 000 signal even ts and 275000 background even ts remain. F rom these ev en ts t wo thirds are used for training a BDT and one third to test the BDT. The c hoice of training v ariables is inspired by the reference analysis [2], with a few additional v ariables and removing v ariables that could not easily b e reconstructed from the a v ailable information. In total 26 input v ariables are considered ranging from basic ob jects lik e angular distance dR betw een differen t jets or leptons, mass of v arious jet and/or lepton systems, scalar sum of the p T of jets and leptons and the full even t top ology . The complete list of v ariables is given in T ab.1. Figure 1 sho ws distributions of input v ariables in the signal and the background sample. The separation, defined as the in tegral o ver the absolut v alue of the difference b etw een signal and background, v aries b et ween 1% and 8 %. Figure 2 shows the correlation of the v ariables, ranging from almost no correlation to v ery high (anti-) correlation. The TMV A [10] implementation of the BDT co de is used with 400 trees, a maximal depth (”MaxDepth”) of 5 and the Ada b o osting algorithm (”Ad- aBo ostBeta=0.15) and 80 Cuts (”nCuts=80”). In the following, the feature ranking of the N = 26 input v ariables are compared using different methods. F or each method, BDTs are trained for the set of the n highest ranked v ariables and the area under the receiver operation curv e (A UROC) is tak en as the p erformance measure for comparison. The difference in ranking may lead to a differen t sub-set of v ariables from the full set of v ariables for a given fixed n umber n of v ariables. Ho wev er, for each metho d the list of v ariables used builds up sequen tially for each algorithm, i.e. exact one v ariable is added to the existing sample going from n to n + 1 4 Paul Glaysher et al. dRbb avg av erage dR of all b -jet pairs dRbb MaxPt dR of the b -jet pair with the highest sum of p T dRbb MaxM dR of the b -jet pair with the highest inv ariant mass dRlb1-dRlb3 dR of the charged lepton and the b -jet with the 1st-3rd largest p T dRlbb MindR dR of the charged lepton and total b -jet pair system which has the smallest dR dRlj MindR minimum dR between the charged lepton and any jet Mbb MaxM maximum inv arian t mass of any b -jet pair Mbb MindR inv arian t mass of b -jet pair which has the smallest dR Mb j MaxPt inv arian t mass of tw o jets with the largest p T sum, where exactly one of the jets is a b -jet Mjjj MaxPt inv arian t mass of any three jets with the largest p T sum pT lep transverse momentum of the charged lepton HT jets sum of transverse momentum of all jets HT all sum of transverse momentum of all jets and the charged lepton nJets Pt40 num b er of jets with p T ≥ 40 GeV nbT ag num b er of b -jets nHiggsbb30 num b er of b -jet pairs with an inv ariant mass within 30 GeV of the Higgs b oson mass of 125 GeV MET missing transverse energy dEta jj MaxdEta largest difference in longitudinal angle η of any two jets Centralit y all ratio of momentum sum ov er the energy sum of all ob jects H i all, H2 jets 1st-5th F o x W olfram transv erse moment [9] of all ob jects T able 1 Input v ariables used for the BDT. 1 2 3 4 5 dRbb_avg [1] 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 0.126 1 / (1/N) dN Signal Background U/O-flow (S,B): (0.0, 0.0)% / (0.0, 0.0)% Input variable: dRbb_avg 500 1000 1500 2000 2500 HT_all [1] 0 0.0005 0.001 0.0015 0.002 0.0025 62.2 1 / (1/N) dN U/O-flow (S,B): (0.0, 0.0)% / (0.0, 0.0)% Input variable: HT_all 200 400 600 800 1000 1200 1400 1600 1800 2000 2200 Mbb_MaxM [1] 0 0.0005 0.001 0.0015 0.002 0.0025 0.003 0.0035 0.004 58.9 1 / (1/N) dN U/O-flow (S,B): (0.0, 0.0)% / (0.1, 0.1)% Input variable: Mbb_MaxM 0.5 1 1.5 2 2.5 3 3.5 4 dRlj_MindR [1] 0 0.2 0.4 0.6 0.8 1 0.0927 1 / (1/N) dN U/O-flow (S,B): (0.0, 0.0)% / (0.0, 0.0)% Input variable: dRlj_MindR 0.97 0.975 0.98 0.985 0.99 0.995 1 H0_all [1] 0 20 40 60 80 100 120 140 160 180 0.000833 1 / (1/N) dN U/O-flow (S,B): (0.0, 0.0)% / (0.0, 0.0)% Input variable: H0_all 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Centrality_all [1] 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 0.0237 1 / (1/N) dN U/O-flow (S,B): (0.0, 0.0)% / (0.0, 0.0)% Input variable: Centrality_all Fig. 1 Input v ariables to the BDT from signal (blue) and background (red) samples, for v ariable definition see text. v ariables and hence defines the ranking. Only for the random selection the sub-samples for different num b er of v ariables don’t hav e to ha ve any ov erlap as at each n the random selection computed from all p ermutations for n ≤ 3, and for 1000 randomly selected trials for n > 3. Iterative subtraction method for F eature Ranking 5 Fig. 2 Matrix of linear correlation co efficents of the input v ariables to the BDT. 3 F eature ranking algorithms Differen t algorithms for ranking the imp ortance of a feature (i.e. input v ari- able) exist whic h largely v ary in their metho ds. Some methods ev aluate the v ariable imp ortance by adding or subtracting input v ariables from or to a set of reference v ariables and measure the c hange in BDT performance. Other metho ds estimate the imp ortance for a given set of v ariables based on the information used in the training of the BDT trained on all N features. The c hoice of method ma y also dep end on the particular use case. The methods v ary largely in their computing needs, some are very computationally exp en- siv e. Random Selection F or the first n = 3 v ariables, all N ! n !( N − n )! p ossible com binations are considered and the one with the b est AUR OC is selected (”maxim um”). This corresponds to the b est possible AUR OC for the giv en n umber of v ariables. How ever, since the n umber of com binations raises fast, for n ≥ 4 only a random selection out of all combinations is choosen 1000 times, to limit CPU consumption on the BDT trainings. The median and the b est A UROC of all trails is rep orted to serve as a reference. Separation based Rank v ariables b y o verlap of their signal v ersus bac k- ground predictions, i.e. the integral ov er their difference. This metho d does not in volv e any BDT training. F or the comparisons presented here, the AUR OC 6 Paul Glaysher et al. v alues are calculated from a BDT trained with the n selected v ariables. Correlation based Rank the v ariables based on their correlation to the BDT score computed with all v ariables. Computationally cheap as it only in- v olves only one BDT training with all N v ariables. BDT Selection F requency T rain the BDT on all N v ariables and rank b y ho w often a v ariable provided the optimal decision in the BDT [10]. Com- putationally cheap as it inv olves only one BDT training. This is the default ranking pro cedure implemen ted in the TMV A BDT co de used here. P erm utational Performance or Mean Decrease Accuracy ( MDA ) In order to a void the high CPU costs of the iterative remo v al and gives insigh t in to a blac k-b ox estimator for the set of N v ariables, this metho d calculates the feature imp ortance by replacing a feature with random noise instead of re- mo ving the feature. The random noise is drawn from the same distribution as original feature v alues but taken from other even ts feature v alues. This av oids out of range v alues which ma y lead to a failure of the algorithm but the v alues are random and uncorrelated to the ev ents [11] Iterativ e Addition The idea is to measure the importance by lo oking at how m uc h the score increases when a feature is added. It starts with the single input v ariable with highest AUR OC and successively adds the v ariable of the remaining N − n v ariables with the highest AUR OC, as is done e.g. in [12]. This inv olves training the BDT for eac h of the N − n com binations to determine the AUR OC and find the best performance. The total num b er of BDTs to be trained are P N n =0 ( N − n ) = N · ( N − 1) / 2 = 406. Ho wev er this ignores p oten tial correlations b etw een the added v ariables. F or example, t wo correlated v ariables might only provide separation p ow er when b oth are presen t in the training. Iterativ e Remov al The idea is to measure the feature imp ortance by lo oking at ho w m uch the score decreases when a feature is remov ed. This w ay , correlations b et ween v ariables are b etter taken into account than for the additiv e metho d. How ever, since the set of n v ariables is retrained, it sho ws what may b e imp ortant within the dataset, not necessarily what is imp ortant within a concrete trained mo del. This metho d starts with training on all N v ariables and successiv ely re- mo ve the v ariable that degrades the p erformance the least. As for the iterativ e addition, this inv olves training the BDT for eac h of the N − n com binations to determine the AUR OC and find the best p erformance, leading in total to the same num b er of trainings as for the iterative addition. How ever, since the metho d starts with a larger n umber of v ariables in the BDT, the ov erall CPU consumption is high and even higher than the iterative addition. The code is publicly a v ailable [13]. Iterative subtraction method for F eature Ranking 7 No. of Training Variables 0 5 10 15 20 25 Relative Performance (AUROC) 58 60 62 64 66 68 70 72 74 76 Ranking method Iterative Removal Iterative Addition Permutation Importance BDT Selection Frequency Correlation based Separation based Random selection, 1000 trials Maximum Median ROC Integral vs No. of Variables Fig. 3 Comparison of p erformance of different feature ranking algorithms. The area under the receiver-operater curve (AUR OC) is shown as a function of the num b er of v ariables. F or details of the selected num b er of training variables, see text. 4 Results Rank Iterativ e Remov al P ermutation Imp ortance BDT Selection Best F requency 1 dRbb av dRbb av dRbb av dRbb av 2 HT jets HT all Mbb MaxM Mbb MaxM 3 nHiggsbb30 H0 all HT jets nHiggsbb30 4 Mbb MaxM Mbb MindR H0 all - 5 n bT ag dRlj MindR nJets Pt40 - 6 Mbb MinR Mbb MaxM dRlb2 - 7 dRlb3 Centralit y all Mjjj MaxPt - 8 H2 jets Mb j MaxPt pT lep - 9 H0 all HT jets dEta jj MaxdEta - 10 Mjjj MaxPt H2 jets dRlb1 - T able 2 Highest ranked v ariables for Iterative Remov al, Perm utation Imp ortance, BDT Selection F requency and b est combination for up to 3 input v ariables. Even though the b est combination is determined considering all com binations for eac h n umber of v ariables, the resulting b est combination included the previously ranked v ariables. All algorithms show similar p erformance if 24 out of 26 v ariables are used. Ho wev er, the different algorithms approac h this plateau of maximal AUR OC differen tly as a function of num b er of v ariables. There are tw o groups of algo- rithms with similar performance: The first group of algorithms are the Iterativ e 8 Paul Glaysher et al. Remo v al, Iterative Addition, the BDT Selection F requency and the Perm uta- tion Imp ortance. These algorithms start with a higher AUR OC and approac h the plateau faster. Among these the newly proposed Iterativ e Remo v al p er- forms b est ov er the full range and approaches the plateau up to a lev el of 99% already with 12 v ariables. This is b etter than the similar algorithm of iterativ e addition and the P erm utational importance whic h reach this performance only with 16 v ariables, or the BDT selection frequency whic h needs 17 v ariables. Bet ween these metho ds the largest differences are observed b etw een 5 and 16 v ariables. The b etter p erformance of the iterative remov al comes at high CPU costs and it is interesting to note that Perm utation imp ortance which is com- putational cheap has the 2nd b est p erformance o verall and yields similar go o d results as iterativ e remo v al for more than 16 v ariables. The BDT selection frequency which is also computational c heap is only sligh tly worse than the P ermutation imp ortance. The second group consists of the Median of the Random Selection, separa- tion based and correlation based selections start with a low AUR OC and only slo wly approach the plateau with 24 v ariables. Among these algorithms, the separation based is the p o orest ranking metho d o v er the full range as might b e expected since this metho d ignores the correlation betw een the v ariables. The correlation based outp erforms the random choice when approaching the plateau and has similar p erformance at lo w num b er of v ariables. The Maxim um of the Random Selection apparently largely dep ends on the randomly selected v ariables for 4 up to approximately 18 v ariables. 1000 trials is not enough to appro ximate the b est result, and the dependence on the particular selection of v ariables is still large, hence more v ariables sometimes yield a smaller A UROC. The b etter reference is the median whic h shows steady raising AUR OC. It is interesting to note that the separation based selection is lo w er than the median of the Random Selection for almost all num b ers of v ariables b elow n =15, indicating that separation is a not a go o d quantit y for feature ranking in con trast to intuition. When selecting the highest ranked v ariables to reduce dimensionality it is in teresting to know how muc h the different ranking algorithms ov erlap. T able 2 lists the highest ranked v ariables for the b est p erforming algorithms. It is w orth noting that they all agree for the highest ranked v ariable, but largely v ary in the order of the rest of the v ariables. The v ariations p ersist in the best 5 v ariables, but the Iterativ e Remov al and the P ermutation Importance ha ve 6 v ariables in common among the b est 10. Tw o out of the 4 v ariables that w ere not included in P ermutation Importance hav e high linear correlation co efficien ts with v ariables that w ere in the list of Iterativ e Remov al, there is a large ov erlap for 8 out of 10 v ariables. Similar conclusions hold for the comparison of BDT Selection F requency with the Iterative Remov al. Iterative subtraction method for F eature Ranking 9 5 Conclusion Differen t metho ds for ranking input v ariables for BDT classification w ere compared. The computationally most exp ensive metho d of Iterative Remov al sho wed the b est classification p ow er measured in terms of AUR OC. How ever, when selecting 16 out of 26 v ariables, other metho ds such as Perm utation Im- p ortance and BDT Selection F requency which are computationally v ery cheap giv e very similar results. Interestingly these metho ds select the same v ariable as b eing b est. Difference in p erformance b etw een 2 and 16 v ariables for the 3 metho ds are of the order of 1-2% in AUR OC for the same num b er of v ariables and should be compared to the computational costs for the sp ecific use case. The v ariables selected to b e the b est 10 agree to large extend betw een these t wo metho ds which may allo w for reducing dimensionality with the less CPU exp ensiv e metho d. But the best 5 v ariables v ary largely , which will mak e it difficult to draw firm conclusions on the impact of first few v ariables on the classification p o wer. References 1. I. H. Witten, E. F rank and M. A. Hall ”Data Mining : Practical Machine Learning T o ols and T echniques” Elsevier Science, 2011. 2. M. Aab oud et al. [A TLAS Collaboration], Phys. Rev. D 97 (2018) no.7, 072016 doi:10.1103/PhysRevD.97.072016 [arXiv:1712.08895 [hep-ex]]. 3. S. V. Chekano v [HepSim Group], [arXiv:1403.1886 [hep-ph]]. 4. J. Alwall, M. Herquet, F. Maltoni, O. Mattelaer and T. Stelzer, JHEP 1106 (2011) 128 doi:10.1007/JHEP06(2011)128 [arXiv:1106.0522 [hep-ph]]. 5. G.Corcella, I. G Knowles, G. Marchesini, S. Moretti, K. Odagiri, P . Richardson, M. H .Seymour, B. R. W ebber JHEP 2001 (2001)010, doi:10.1088/1126-6708/2001/01/010 6. T. Sjostrand, S. Mrenna and P . Z. Sk ands, JHEP 0605 (2006) 026 doi:10.1088/1126- 6708/2006/05/026 [hep-ph/0603175]. 7. J. de F a vereau et al. [DELPHES 3 Collab oration], JHEP 1402 (2014) 057 doi:10.1007/JHEP02(2014)057 [arXiv:1307.6346 [hep-ex]]. 8. M. Aaboud et al. [A TLAS Collaboration], JHEP 1808 (2018) 089 doi:10.1007/JHEP08(2018)089 [arXiv:1805.01845 [hep-ex]]. 9. G.C. F ox and S. W olfram, Nucl. Phys. B149 (1979) 413. 10. A.Ho eck er et al. TMV A - T o olkit for Multiv ariate Data Analysis [arXiv:physics/0703039] 11. M. Korob ov, K. Lopuhin Revision 371b402a. https://eli5.readthedocs.io/en/latest/blackbox/permutation importance.html 12. M. Aaboud et al. [A TLAS Collaboration], Eur. Ph ys. J. C 79 (2019) no.5, 375 doi:10.1140/ep jc/s10052-019-6847-8 [arXiv:1808.07858 [hep-ex]]. 13. S.An Github vSearch rep ository: A parallelised script for v ariable selection and the iterativ e remov al metho d https://gith ub.com/sitongan/vSearch
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment