경계 없는 연속학습을 위한 메타러닝 프레임워크
본 논문은 작업 경계와 작업 라벨이 전혀 제공되지 않는 연속학습 상황에서, 메타러닝 기법을 활용해 “무엇을(What)”과 “어떻게(How)”를 분리하는 새로운 프레임워크를 제안한다. 작업별 파라미터와 작업에 무관한 메타 파라미터를 구분하고, 메타 파라미터를 베이지안 그래디언트 디센트(BGD)로 지속적으로 학습함으로써, 기존 방법이 불가능한 빠른 기억 회복(faster remembering)을 가능하게 한다.
저자: Xu He, Jakub Sygnowski, Alex
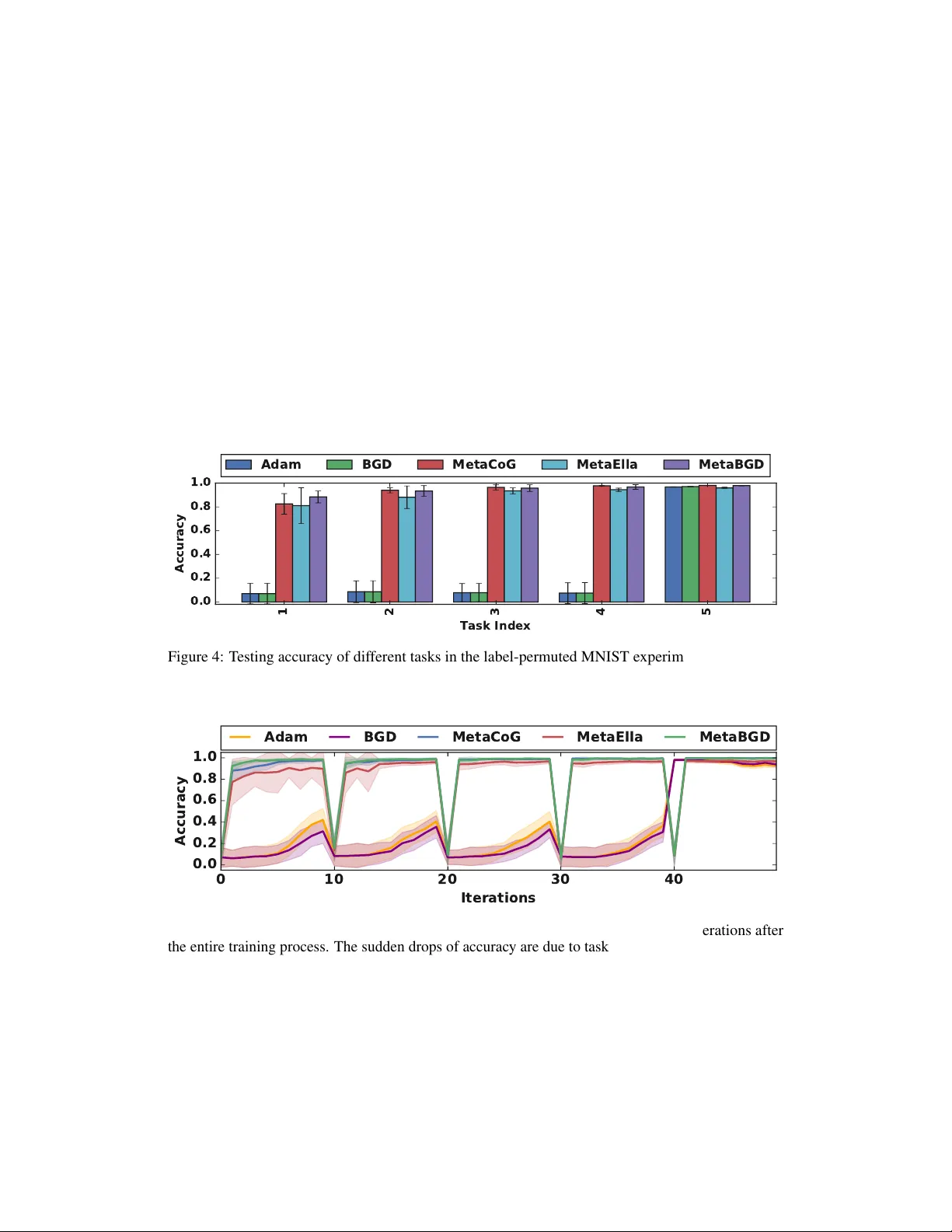
본 논문은 “Task Agnostic Continual Learning via Meta Learning”이라는 제목 아래, 작업 경계와 작업 라벨이 전혀 제공되지 않는 연속학습 환경을 대상으로 새로운 메타러닝 기반 프레임워크를 제안한다. 기존 연속학습 연구는 대부분 작업 라벨이나 경계 정보를 가정하고, 주로 망각 방지(예: EWC, MAS, VCL 등)와 전이 학습을 목표로 했다. 그러나 실제 서비스나 로봇 제어와 같은 상황에서는 작업이 명시적으로 구분되지 않으며, 데이터 분포가 지속적으로 변한다. 이러한 문제를 해결하기 위해 저자들은 “빠른 기억 회복(faster remembering)”이라는 새로운 평가 기준을 도입한다. 이는 모델이 과거에 학습한 작업을 재학습할 때, 얼마나 신속히 성능을 회복하는지를 측정한다.
프레임워크의 핵심은 “What & How” 두 단계로 구성된다. What 모듈은 최근 k개의 (x, y) 쌍을 컨텍스트 데이터 D_cxt 로 받아 현재 작업을 추정하는 임베딩 c_t 를 생성한다. How 모듈은 이 c_t 를 입력으로 받아 작업‑특정 모델 f̂_{c_t} 를 만든다. 이렇게 하면 동일한 입력 x 가 서로 다른 작업 컨텍스트에 따라 다른 출력을 내도록 할 수 있다. 저자는 Conditional Neural Processes(CNP), Model‑Agnostic Meta‑Learning(MAML), Latent Embedding Optimization(LEO), CAVIA 등 기존 메타러닝 기법이 모두 What & How 구조의 특수한 형태임을 보인다.
연속학습에서 메타 파라미터(What·How의 파라미터)를 학습할 때는 일반적인 메타러닝과 달리 동시에 여러 작업을 샘플링할 수 없으며, 순차적으로 하나의 작업만이 주어진다. 따라서 메타 파라미터 자체가 망각에 취약해진다. 이를 해결하기 위해 저자는 베이지안 그래디언트 디센트(BGD)를 메타 레벨에 적용한다. BGD는 파라미터를 평균 µ와 불확실성 σ를 갖는 가우시안으로 모델링하고, 불확실성이 작은 파라미터에 더 큰 제약을 가함으로써 지속적인 지식 보존을 가능하게 한다. 메타 손실 L_meta는 현재 컨텍스트에서 추정된 작업‑특정 모델이 현재 관찰 (x_t, y_t) 에 대해 내는 손실이며, 이를 통해 µ와 σ를 업데이트한다.
프레임워크의 구체적 구현 예시로 두 가지가 제시된다. 첫 번째는 MetaCoG(메타 컨텍스트‑의존 게이팅)이다. 여기서는 컨텍스트 데이터를 이용해 마스크 m_t 를 gradient descent 로 추정하고, 이 마스크를 베이스 네트워크 파라미터와 element‑wise 곱해 작업‑특정 서브네트워크를 만든다. 마스크는 연속적인 값으로 남아 있어 완전한 이진 게이팅이 아니라 파라미터 조절 역할을 한다. 두 번째는 MetaELLA이다. GO‑MTL과 ELLA에서 영감을 받아, 공유 딕셔너리 L을 How 파라미터로, 작업별 계수 s_t 를 What 파라미터로 본다. s_t 를 컨텍스트 손실을 최소화하도록 gradient descent 로 업데이트하고, L 은 BGD 로 지속적으로 정제한다. 두 구현 모두 메타 파라미터가 BGD에 의해 안정화되면서, 작업 전환 시 빠른 적응과 기억 회복을 달성한다는 실험적 증거를 제시한다.
실험에서는 기존 task‑agnostic 연속학습 방법(예: FMN+EWC, 온라인 EWC 등)과 비교했을 때, 제안된 MetaCoG와 MetaELLA가 동일한 데이터 스트림에서 더 빠른 성능 회복을 보였으며, 장기적인 정확도도 경쟁 수준 혹은 그 이상이었다. 특히 작업 간 충돌이 심한 경우에도, What 모듈이 적절히 작업을 추정하고 How 모듈이 해당 작업에 맞는 파라미터를 제공함으로써, 단일 파라미터 집합으로는 불가능한 성능을 달성했다.
결론적으로, 이 논문은 메타러닝과 연속학습을 자연스럽게 결합하는 새로운 패러다임을 제시한다. What & How 분리를 통해 작업 식별이 불가능한 상황에서도 효과적인 학습이 가능하며, BGD 기반 메타 파라미터 안정화는 순차적 작업 흐름에서도 망각을 최소화한다. 향후 연구는 보다 복잡한 비정형 데이터, 멀티모달 컨텍스트, 그리고 온라인 메타‑옵티마이제이션 기법과의 결합을 통해 프레임워크를 확장할 여지를 남긴다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기