Task Agnostic Continual Learning via Meta Learning
While neural networks are powerful function approximators, they suffer from catastrophic forgetting when the data distribution is not stationary. One particular formalism that studies learning under non-stationary distribution is provided by continua…
Authors: Xu He, Jakub Sygnowski, Alex
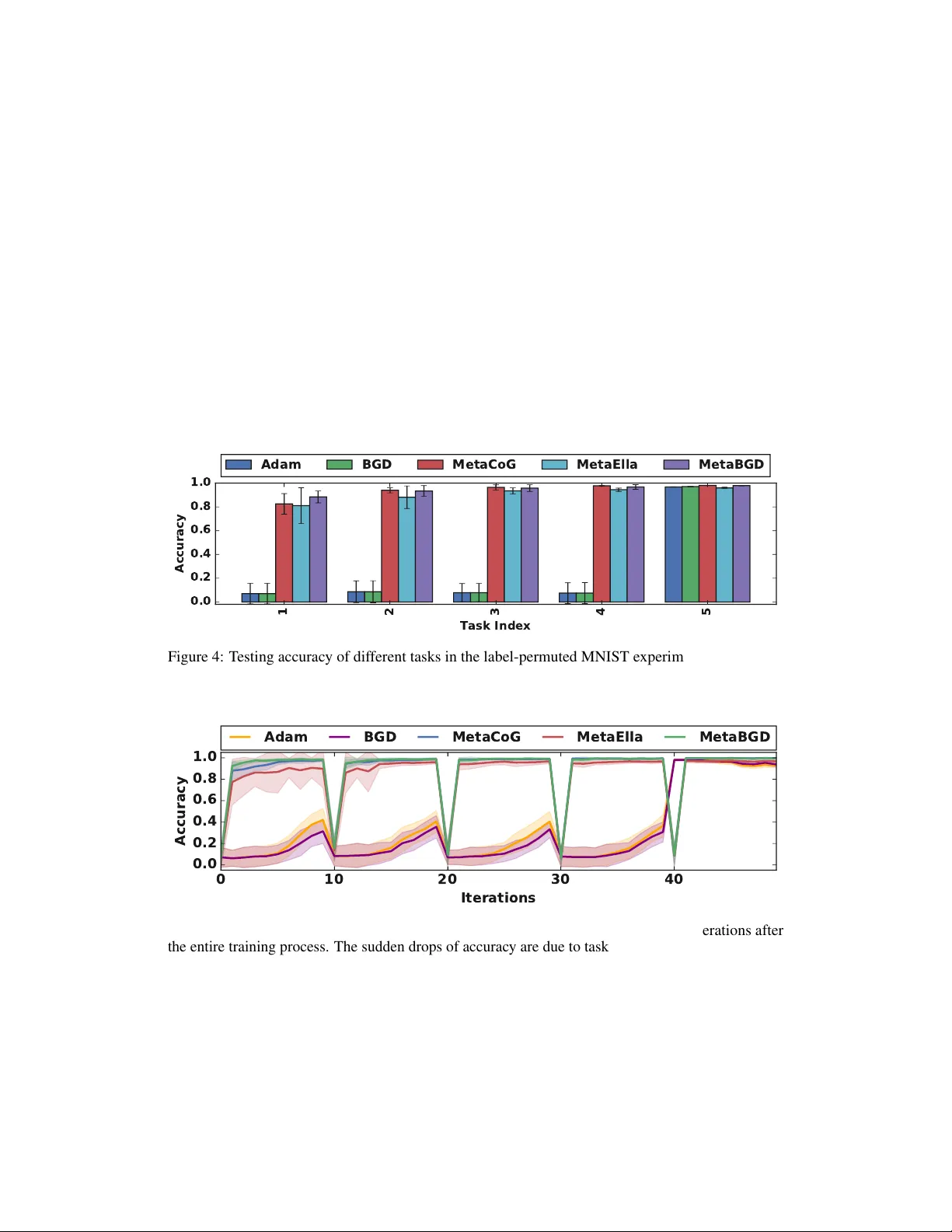
T ask Agnostic Continual Lear ning via Meta Lear ning Xu He, Jakub Sygnowski, Alexandr e Galasho v , Andrei A. Rusu, Y ee Whye T eh, Razvan Pascanu DeepMind, London, UK {hexu, sygi, agalashov, andreirusu, ywteh, razp}@google.com Abstract While neural networks are po werful function approximators, they suf fer from catastrophic forgetting when the data distrib ution is not stationary . One particular formalism that studies learning under non-stationary distribution is provided by continual learning, where the non-stationarity is imposed by a sequence of distinct tasks. Most methods in this space assume, howe ver , the knowledge of task bound- aries, and focus on alleviating catastrophic for getting. In this work, we depart from this view and mov e the focus tow ards faster r emembering – i.e measuring how quickly the network recov ers performance rather than measuring the network’ s performance without any adaptation. W e argue that in man y settings this can be more effecti ve and that it opens the door to combining meta-learning and continual learning techniques, lev eraging their complementary advantages. W e propose a framew ork specific for the scenario where no information about task boundaries or task identity is given. It relies on a separation of concerns into what task is being solved and how the task should be solv ed. This framework is implemented by dif ferentiating task specific parameters from task agnostic parameters, where the latter are optimized in a continual meta learning fashion, without access to multiple tasks at the same time. W e showcase this framework in a supervised learning scenario and discuss the implications of the proposed formalism. 1 Introduction A common assumption made by many machine learning algorithms is that the observ ations in the dataset are independent and identically distributed (i.i.d). Howe ver , there are many scenarios where this assumption is violated because the underlying data distrib ution is non-stationary . For instance, in reinforcement learning (RL), the observations depend on the current polic y of the agent, which may change over time. In addition, the environments with which the agent interacts are usually non-stationary . In supervised learning tasks, due to computational or leg al reasons, one might be forced to re-train a deployed model only on the recently collected data, which might come from a different distrib ution than that of the previous data. In all these scenarios, blindly assuming i.i.d will not only lead to inefficient learning procedure, b ut also catastrophic interference [19]. One research area that addresses this problem is continual learning, where the non-stationarity of data is usually described as a sequence of distinct tasks. A list of desiderata for continual learning [ 33 ] include the ability to not for get, forward positiv e transfer (learning new tasks faster by le veraging previously acquired kno wledge), and backwards positi ve transfer (improv ement on previous tasks because of new skills learned), bounded memory b udget re gardless the number of tasks and so forth. Since these desiderata are often competing with each other , most continual learning methods aim for some of them instead of all, and to simplify the problem, they usually assume that the task labels or the boundaries between different tasks are kno wn. In this work, we aim to develop algorithms that can continually learn a sequence of tasks without kno wing their labels or boundaries. Furthermore, we argue that in a more challenging scenario where the tasks are not only different b ut also conflicting with each other , most existing approaches will Preprint. Under re view . fail. T o o vercome these challenges, we propose a frame work that applies meta-learning techniques to continual learning problems, and shift our focus from less forgetting to faster remembering: to rapidly recall a previously learned task, gi ven the right context as a cue. 2 Problem Statement W e consider the online learning scenario studied by [ 10 , 36 , 22 ], where at each time step t , the network recei ves an input x t and giv es a prediction ˆ y t := ˆ f ( x t , θ t ) using a model ˆ f parametrised by θ t . It then receiv es the ground truth y t , which can be used to adapt its parameters and to improv e its performance on future predictions. If the data distribution is non-stationary (e.g., x t , y t might be sampled from some task A for a while, then the task switches to B ), then training on the new data might lead to catastrophic forgetting – the ne w parameters θ 0 can solve task B but not task A anymore: ˆ f ( x B t ; θ 0 ) = y B t , ˆ f ( x A t ; θ 0 ) 6 = y A t . Many continual learning methods were proposed to alle viate the problem of catastrophic forgetting. Howe ver , most of these approaches require either the information of task index ( A or B ) or at least the moment when the task switches. Only recently , the continual learning community started to focus on task agnostic methods [ 37 , 2 ]. Howe ver , all these methods ha ve the underlying assumption that no matter what tasks it has been learning, at any time t , it is possible to find parameters θ t that fit all pre vious observ ations with high accurac y: ∃ θ t s.t. ∀ t 0 ≤ t, ˆ f ( x t 0 , θ t ) ≈ y t 0 . This assumption is, ho wev er, not v alid when the target y t depends not only on the observ ation x t but also on some hidden task (or context) v ariable c t : y t = f ( x t , c t ) , a common scenario in partially observable en vironments [ 21 , 4 ]. In this case, when the context has changed ( c t 6 = c t 0 ), even if the observation remains the same ( x t = x t 0 ), the targets may be dif ferent ( y t 6 = y t 0 ). As a result, it is impossible to find a single parameter vector θ t that fits both mappings: ˆ f ( x t ; θ t ) = y t = ⇒ ˆ f ( x t 0 ; θ t ) 6 = y t 0 . It follows that, in this case, catastrophic forgetting cannot be a voided without inferring the task v ariable c t . 3 What & How Framework Here we propose a framework for task agnostic continual learning that e xplicitly infers the current task from some context data D cxt t and predicts targets based on both the inputs x t and task representations c t . The framew ork consists of two modules: an encoder or task inference network F what : D cxt t → c t that predicts the current task representation c t based on the context data D cxt t , and a decoder F How : c t → ˆ f c t that maps the task representation c t to a task specific model ˆ f c t : x → ˆ y , which makes predictions conditional on the current task. Under this frame work, e ven when the inputs x t and x t 0 are the same, the predictions ˆ y t and ˆ y t 0 can differ from each other depending on the conte xts. In this work, we choose the recent k observations { ( x t − k , y t − k ) , · · · ( x t − 1 , y t − 1 ) } as the context dataset D cxt . This choice is reasonable in an envi- ronment where c t is piece-wise stationary or changes smoothly . An overvie w of this framew ork is illustrated in Figure 1a. (a) What & How frame work (b) MetaCoG (c) MetaELLA Figure 1: Schematic diagrams of the framework and its instances. 3.1 Meta Learning as T ask Inference A similar separation of concern can be found in the meta-learning literature. In fact, man y recently proposed meta-learning methods can be seen as instances of this framework. For example, Conditional Neural Processes (CNP) [ 6 ] embed the observation and tar get pairs in context data ( x i , y i ) ∈ D cxt t by 2 an encoder r i = h ( x i , y i ; θ h ) . The embeddings are then aggregated by a commutati ve operation ⊕ (such as the mean operation) to obtain a single embedding of the conte xt: r t = F What ( D cxt t ; θ h ) := L x i ,y i ∈D cxt t h ( x i , y i ; θ h ) . At inference time, the context embedding is passed as an additional input to a decoder g to produce the conditional outputs: F How ( r t ) := g ( · , r t ; θ g ) . Model-Agnostic Meta-Learning (MAML) [ 5 ] infers the current task by applying one or a fe w steps of gradient descent on the conte xt data D cxt t . The resulting task-specific parameters can be considered a high-dimensional representation of the current task returned by a What encoder: θ t = F What ( D cxt t ; θ init ) := θ init t − λ in ∇ θ L in ( ˆ f ( · ; θ ) , D cxt t ) , where θ init t are meta parameters, and λ in the inner loop learning rate. The How decoder of MAML returns the task specific model by simply parametrizing ˆ f with θ t : F How ( θ t ) := ˆ f ( · ; θ t ) . [ 29 ] proposed Latent Embedding Optimization (LEO) which combines the encoder/decoder structure with the idea of inner loop fine-tuning from MAML. The latent task embedding z t is first sampled from a Gaussian distrib ution N ( µ e t , diag ( σ e t 2 )) whose mean µ e t and v ariance σ e t 2 are generated by av eraging the outputs of a relation network: µ e t , σ e t = 1 |D cxt | 2 P x i ∈D cxt P x j ∈D cxt g r ( g e ( x i ) , g e ( x j )) , where g r ( · ) is a relation network and g e ( · ) is an encoder . T ask-dependent weights can then be sampled from a decoder g d ( · ) : w t ∼ N ( µ d t , diag ( σ d t 2 )) , where µ d t , σ d t = g d ( z t ) . The final task representation is obtained by a fe w steps of gradient descent: z 0 t = F What ( D cxt t ) := z t − λ in ∇ z 0 L in ( ˆ f ( · ; w t ) , D cxt t ) , and the final task specific weights w 0 t are decoded from z 0 : F How ( z 0 t ) = w 0 t ∼ N ( µ d 0 t , diag ( σ d 0 t 2 )) , where µ d 0 t , σ d 0 t = g d ( z 0 t ) . In Fast Context Adaptation via Meta-Learning (CA VIA) [ 38 ], a neural network model ˆ f takes a context v ector c t as an additional input: ˆ y = ˆ f ( x, c t ; θ ) . The context vector is inferred from context data by a few steps of gradient descent: c t = F What ( D cxt t ; θ ) := c init − λ in ∇ c L in ( ˆ f ( · , c ; θ ) , D cxt t ) . Then a context dependent model is returned by the Ho w decoder: F How ( c t ) := ˆ f ( · , c t ; θ ) . T able 1 in Appendix summarizes ho w these methods can be seen as instances of the What & Ho w framew ork. Under this framew ork, we can separate the task specific parameters of ˆ f from the task agnostic parameters of F What and F How . 3.2 Continual Meta Learning In order to train these meta learning models, one normally has to sample data from multiple tasks at the same time during training. Howe ver , this is not feasible in a continual learning scenario, where tasks are encountered sequentially and only a single task is presented to the agent at any moment. As a result, the meta models (What & Ho w functions) themselv es are prone to catastrophic for getting. Hence, the second necessary component of our framew ork is to apply continual learning methods to stabilize the learning of meta parameters. In general, any continual learning method that can be adapted to consolidate memory at e very iteration instead of at e very task switch can be applied in our framework, such as Online EWC [ 33 ] and Memory A ware Synapses (MAS) [ 1 ]. In order to highlight the effect of explicit task inference for task agnostic continual learning, we choose a particular method called Bayesian Gradient Descent (BGD) [ 37 ] to implement our frame work. W e sho w that by applying BGD on the meta-le vel models ( F What and F How ), the network can continually learn a sequence of tasks that are impossible to learn when BGD is applied to the bottom-le vel model ˆ f . Formally , let θ meta be the vector of meta parameters, (i.e. the parameters of F What and F How , for instance, θ init in MAML). W e model its distribution by a factorized Gaussian p ( θ meta ) = Q i N ( θ meta i | µ i , σ i ) . Given a conte xt dataset D cxt t and the current observ ations ( x t , y t ) , the meta loss can be defined as the loss of the task specific model on the current observations: L meta := L ( ˆ f t ( x t ) , y t ) , where ˆ f t = F How ◦ F What ( D cxt ; θ meta ) . With the meta loss defined, it is then possible to optimize µ, σ using the BGD update rules derived from the online v ariational Bayes’ rule and a re-parametrization trick ( θ meta i = µ i + σ i i , i ∼ N (0 , 1) ): µ i ← µ i − η σ 2 i E ∂ L meta ∂ θ meta i , σ i ← σ i s 1 + 1 2 σ i E ∂ L meta ∂ θ meta i i 2 − 1 2 σ 2 i E ∂ L meta ∂ θ meta i i , (1) 3 where ∂ L meta /∂ θ meta i is the gradient of the meta loss L meta with respect to sampled parameters θ meta i and η is a learning rate. The expectations are computed via Monte Carlo method: E ∂ L meta ∂ θ meta i ≈ 1 K K X k =1 ∂ L meta ( θ meta ( k ) i ) ∂ θ meta i , E ∂ L meta ∂ θ meta i i ≈ 1 K K X k =1 ∂ L meta ( θ meta ( k ) i ) ∂ θ meta i ( k ) i (2) An intuiti ve interpretation of BGD learning rules is that weights µ i with smaller uncertainty σ i are more important for the kno wledge accumulated so far , thus they should change slo wer in the future in order to preserve the learned skills. 3.3 Instantiation of the Framework Using the What & Ho w framework, one can compose arbitrarily many continual meta learning methods. T o show that this frame work is independent from a particular implementation, we propose two such instances by adapting previous continual learning methods to this meta learning framew ork. MetaCoG Context-dependent gating of sub-spaces [ 9 ], parameters [ 17 ] or units [ 34 ] of a single network hav e prov en ef fecti ve at alle viating catastrophic forgetting. Recently , [ 18 ] showed that combining context dependent gating with a synaptic stabilization method can achie ve even better performance than using either method alone. Therefore, we explore the use of conte xt dependent masks as our task representations, and define the task specific model as the sub-network selected by these masks. At e very time step t , we infer the latent masks m t based on the context dataset D cxt t by one or a fe w steps of gradient descent of an inner loop loss function L in with respect to m : m t := F What ( D cxt t ; θ ) = m init − λ in · ∇ m L in ( ˆ f ( · ; θ σ ( m )) , D cxt t ) , (3) where m init is a fixed initial v alue of the mask variables, σ ( · ) is an element-wise sigmoid function to ensure that the masks are in [0 , 1] , and is element-wise multiplication. In general, L in can be any objectiv e function. For instance, for a re gression task, one can use a mean squared error with an L 1 regularization that enforces sparsity of σ ( m ) : L in ( ˆ f ( · ; θ σ ( m )) , D cxt t ) := X x i ,y i ∈D cxt t ( ˆ f ( x i ; θ σ ( m )) − y i ) 2 + γ || σ ( m ) || 1 (4) The resulting masks m t are then used to gate the base network parameters θ t in order to make a context- dependent prediction: ˆ y t = ˆ f ( x t ; θ t σ ( m t )) . Once the ground truth y t is revealed, we can define the meta loss as the loss of the mask ed network on the current data: L meta ( ˆ f ( · ; θ σ ( m t )) , { ( x t , y t ) } ) and optimize the distribution q ( θ | µ, σ ) of task agnostic meta variable θ by BGD. The intuition here is that the parameters of the base network should allow fast adaptations of the masks m t . Since the context-dependent gating mechanism is trained in a meta-learning fashion, we call this particular instance of our framew ork Meta Context-dependent Gating (MetaCoG). W e note that while we draw our inspiration from the idea of selecting a subnetwork using the masks m t , in the formulated algorithm m t rather plays the role of modulating the parameters (i.e. in practice we noticed that entries of m t do not necessarily con verge to 0 or 1 ). Note that the inner loop loss L in used to infer the conte xt v ariable m t does not ha ve to be the same as the meta loss L meta . In fact, one can choose an auxiliary loss function for L in as long as it is informativ e about the current task. MetaELLA The second instance of the framew ork is based on the GO-MTL model [ 14 ] and the Efficient Lifelong Learning Algorithm (ELLA) [ 30 ]. In a multitask learning setting, ELLA tries to solve each task with a task specific parameter vector θ ( t ) by linearly combining a shared dictionary of k latent model components L ∈ R d × k using a task-specific coef ficient vector s ( t ) ∈ R k : θ ( t ) := Ls ( t ) , where L is learned by minimizing the objecti ve function L ella ( L ) = 1 T T X t =1 min s ( t ) n 1 n ( t ) n ( t ) X i =1 L ˆ f ( x ( t ) i ; Ls ( t ) ) , y ( t ) i + µ || s ( t ) || 1 o + λ || L || 2 F (5) 4 Instead of directly optimizing L ella ( L ) , we adapt ELLA to the What & How framework by con- sidering s ( t ) as the task representation returned by a What encoder and L as parameters of a How decoder . The objecti ve L ella can then be minimized in a continual meta learning fash- ion. At time t , current task representation s t is obtained by minimizing the inner loop loss L in ( ˆ f ( · ; Ls ) , D cxt ) := 1 |D cxt | P x i ,y i ∈D cxt L ( ˆ f ( x i ; Ls ) , y i ) + µ || s || 1 by one or a few steps of gradient descent from fixed initial v alue s init : s t := F What ( D cxt t ; L ) = s init − λ in · ∇ s L in ( ˆ f ( · ; Ls ) , D cxt t ) . Similar to MetaCoG, the parametric distribution q ( L | µ L , σ L ) = Q i N ( L i | µ L i , σ L i ) of the meta variable L can be optimized with respect to the meta loss L meta ( ˆ f ( · ; Ls t ) , { ( x t , y t ) } ) using BGD. 4 Related W ork Continual learning has seen a surge in popularity in the last few years, with multiple approaches being proposed to address the problem of catastrophic for getting. These approaches can be largely categorized into the follo wing types [ 24 ]: Rehearsal based methods rely on solving the multi-task objectiv e, where the performance on all pre vious tasks is optimized concurrently . They focus on techniques to either efficiently store data points from pre vious tasks [ 27 , 16 ] or to train a generativ e model to produce pseudo-examples [ 35 ]. Then the stored and generated data can be used to approxi- mate the losses of pre vious tasks. Structural based methods exploit modularity to reduce interference, localizing the updates to a subset of weights. [ 28 ] proposed to learn a new module for each task with lateral connection to pre vious modules. It pre vents catastrophic forgetting and maximizes forward transfer . In [ 7 ], pruning techniques are used to minimize the growth of the model with each observed tasks. Finally , Re gularization based methods draw inspiration from Bayesian learning, and can be seen as utilizing the posterior after learning a sequence of tasks as a prior to regularize learning of the ne w task. These methods differ from each other in how the prior and implicitly the posterior are parametrized and approximated. For instance, Elastic W eight Consolidation (EWC) [ 12 ] relies on a Gaussian approximation with a diagonal cov ariance, estimated using a Laplace approximation. V ariational Continual Learning (VCL) [ 23 ] learns directly the parameters of the Gaussian relying on the re-parametrization trick. [26] achieved better approximation with block-diagonal co variance. While eff ectiv e at preventing for getting, the above-mentioned methods either rely on kno wledge of task boundaries or require task labels to select a sub-module for adaptation and prediction, hence cannot be directly applied in the task agnostic scenario considered here. T o circumvent this issue, [ 12 ] used Forget-Me-Not (FMN) [ 20 ] to detect task boundaries and combined it with EWC to consolidate memory when task switches. Ho we ver , FMN requires a generativ e model that computes exact data lik elihood, which limits it from scaling to complex tasks. More recently , [ 2 ] proposed a rehearsal-based method to select a finite number of data that are representativ e of all data seen so far . This method, similar to BGD, assumes that it is possible to learn one model that fits all previous data, neglecting the scenario where dif ferent tasks may conflict each other , hence does not allow task-specific adaptations. Meta-learning , or learning to learn [ 32 ], assumes simultaneous access to multiple tasks during meta-training, and focuses on the ability of the agent to quickly learn a new task at meta-testing time. As with continual learning, different f amilies of approaches exist for meta-learning. Memory based methods [ 31 ] rely on a recurrent model (optimizer) such as LSTM to learn a history-dependent update function for the lower-le vel learner (optimizee). [ 3 ] trained an LSTM to replace the stochastic gradient descent algorithm by minimizing the sum of the losses of the optimizees on multiple prior tasks. [ 25 ] use an LSTM-based meta-learner to transform the gradient and loss of the base-learners on ev ery new example to the final updates of the model parameters. Metric based methods learn an embedding space in which other tasks can be solved ef ficiently . [ 13 ] trained siamese networks to tell if two images are similar by con verting the distance between their feature embeddings to the probability of whether they are from the same class. [ 36 ] proposed the matching network to improve the embeddings of a test image and the support images by taking the entire support set as conte xt input. The approaches discussed in Section 3.1 instead belong to the f amily of optimization based meta-learning methods. In this domain, the most relev ant work is from [ 22 ], where they studied fast adaptation in a non-stationary en vironment by learning an ensemble of networks, one for each task. Unlike our work, they used MAML for initialization of ne w networks in the ensemble instead of task inference. A drawback of this approach is that the size of the ensemble gro ws over time and is unbounded, hence can become memory-consuming when there are many tasks. 5 5 Experiments T o demonstrate the ef fectiveness of the proposed framework, we compare BGD and Adam[ 11 ] to three instances of this framework on a range of task agnostic continual learning experiments. The first instance is simply applying BGD on the meta variable θ init of MAML instead of on the task specific parameters. W e refer to this method as MetaBGD. The other two are MetaCoG and MetaELLA, introduced in Section 3.3. In all experiments, we present N tasks consecuti vely and each task lasts for M iterations. At every iteration t , a batch of K samples D t = { x t, 1 , · · · x t,K } from the training set of the current task are presented to the learners, and the context data used for task inference is simply the pre vious mini-batch with their corresponding tar gets: D cxt t = D t − 1 S { y t − 1 , 1 , · · · y t − 1 ,K } . At the end of the entire training process, we test the learners’ performance on the testing set of every task, gi ven a mini-batch of training data from that task as conte xt data. Since the meta learners take fiv e gradient steps in the inner loop for task inference, we also allow BGD and Adam to take fi ve gradient steps on the context data before testing their performances. W e focus on analyzing the main results in this section, experimental details are pro vided in the Appendix B. 5.1 Sine Curve Regr ession Task Index 0 1 2 3 4 5 6 7 8 MSE Adam BGD MetaCoG MetaElla MetaBGD Figure 2: T esting loss per task at the end of the entire learning phase. T ask 1 is the first seen task, and task 10 is the last. Lower MSE means better performance. W e start with a regression problem commonly used in meta learning literature, where each task corresponds to a sine curve to be fitted. In this experiment, we randomly generate 10 sine curves and present them sequentially to a 3-layer MLP . Figure 2 shows the mean squared error (MSE) of each task after the entire training process. Adam and BGD perform significantly worse than the meta learners, ev en though they ha ve taken the same number of gradient steps on the context data. The reason for this lar ge gap of performance becomes e vident by looking at Figure 3, which shows the learners’ predictions on testing data of the last task and the third task, given their corresponding context data. All learners can solve the last task almost perfectly , but when the context data of the third task is pro vided, meta learners can quickly remember it, while BGD and Adam are unable to adapt to the task they ha ve previously learned. 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 6 4 2 0 2 4 6 6 4 2 0 2 4 6 6 4 2 0 2 4 6 6 4 2 0 2 4 6 BGD Adam MetaCoG MetaELLA MetaBGD Target Figure 3: Predictions for the last task (left) and the third task (right) after the entire training process. 6 5.2 Label-Permuted MNIST A classical e xperiment for continual learning is permuted MNIST [ 8 , 12 ], where a ne w task is created by shuf fling the pixels of all images in MNIST by a fixed permutation. In this experiment, ho wever , we shuf fle the classes in the labels instead of the pixels in the images. The reason for this change is to ensure that it is not possible to guess the current task simply based on the images. In this way , we can test whether our framew ork is able to quickly adapt its behavior according to the current context. Fiv e tasks are created with this method and are presented sequentially to an MLP . W e test the learners’ classification accurac y of each task at the end of the entire learning process, using a mini-batch of training set as context data. As can be seen from Figure 4, all learners perform well on the last task. Howe ver , BGD and Adam have chance-le vel accuracy on pre vious tasks due to their incapability of inferring tasks from context data, while the meta learners are able to recall those tasks within 5 inner loop updates on the context data. Figure 5 displays the accuracy curve when we play the tasks again, for 10 iterations each, after the first training process. The tasks are presented in the same order as they were learned for the first time. It is clear that one iteration after the task changes, when the correct context data is av ailable, the meta learners are able to recall the current task to almost perfection, while Adam and BGD ha ve to re-learn each task from scratch. 1 2 3 4 5 Task Index 0.0 0.2 0.4 0.6 0.8 1.0 Accuracy Adam BGD MetaCoG MetaElla MetaBGD Figure 4: T esting accuracy of dif ferent tasks in the label-permuted MNIST experiment at the end of the entire training process. 0 10 20 30 40 Iterations 0.0 0.2 0.4 0.6 0.8 1.0 Accuracy Adam BGD MetaCoG MetaElla MetaBGD Figure 5: Accuracy curve when the label-permuted MNIST tasks are replayed for 10 iterations after the entire training process. The sudden drops of accurac y are due to task switching, when the context data are still from the previous task. 5.3 Omniglot W e hav e seen in previous tw o experiments that when the task information is hidden from the netw ork, continual learning is impossible without task inference. In this experiment, we show that our framew ork is fav ourable e ven when the task identity is reflected in the inputs. T o this end, we test our framew ork and BGD by sequential learning of handwritten characters from the Omniglot dataset [ 15 ], which consists of 50 alphabets with various number of characters per alphabet. Considering 7 ev ery alphabet as a task, we present 10 alphabets sequentially to a con volutional neural network and train it to classify 20 characters from each alphabet. Most continual learning methods (including BGD) require a multi-head output in order to ov ercome catastrophic forgetting in this set-up. The idea is to use a separate output layer per task, and to only compute the error on the current head during training and only make predictions from the current head during testing. Therefore, task index has to be av ailable in this case in order to select the correct head. Unlike these pre vious works, we e valuate our frame work with a single head of 200 output units in this experiment. Figure 6 summarizes the results of this experiment. For e very task, we measure its corresponding testing accuracy twice: once immediately after that task is learned (no forgetting yet), and once after all ten tasks are learned. Our frame work with a single head can achie ve comparable results as BGD with multiple heads, whereas BGD with a single head completely for gets pre vious tasks. Figure 6: T esting accuracy of the sequential Omniglot task. BGD (MH) uses a multi-head output layer , whereas BGD (SH) and all meta learners use a single-head output layer . In the bottom plot, the accuracy of BGD(SH) are 0 for all tasks e xcept the last one. 6 Conclusions In this work, we sho wed that when the objecti ve of a learning algorithm depends on both the inputs and context, catastrophic for getting is inevitable without conditioning the model on the context. A framew ork that can infer task information explicitly from context data w as proposed to resolve this problem. The frame work separates the inference process into two components: one for representing What task is expected to be solved, and the other for describing How to solve the giv en task. In addition, our framework unifies many meta learning methods and thus establishes a connection between continual learning and meta learning, and lev erages the advantages of both. There are two perspecti ves of viewing the proposed framew ork: from the meta learning perspectiv e, our frame work addresses the continual meta learning problem by applying continual learning tech- niques on the meta variables, therefore allo wing the meta knowledge to accumulate ov er an extended period; from the continual learning perspectiv e, our framew ork addresses the task agnostic continual learning problem by explicitly inferring the task when the task information is not a vailable, and this allo ws us to shift the focus of continual learning from less for getting to faster remembering, gi ven the right context. For future w ork, we would like to test this frame work for reinforcement learning tasks in partially observable en vironments, where the optimal policy has to depend on the hidden task or context information. 8 References [1] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny , Marcus Rohrbach, and T inne T uyte- laars. Memory aware synapses: Learning what (not) to for get. In Pr oceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 139–154, 2018. [2] Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Y oshua Bengio. Online continual learning with no task boundaries. arXiv pr eprint arXiv:1903.04476 , 2019. [3] Marcin Andrycho wicz, Misha Denil, Ser gio Gomez, Matthew W Hof fman, David Pfau, T om Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Pr ocessing Systems , pages 3981–3989, 2016. [4] Anthony R Cassandra, Leslie Pack Kaelbling, and Michael L Littman. Acting optimally in partially observable stochastic domains. In AAAI , 1994. [5] Chelsea Finn, Pieter Abbeel, and Sergey Le vine. Model-agnostic meta-learning for fast adapta- tion of deep networks. In International Confer ence on Machine Learning , pages 1126–1135, 2017. [6] Marta Garnelo, Dan Rosenbaum, Christopher Maddison, T iago Ramalho, Da vid Saxton, Murray Shanahan, Y ee Whye T eh, Danilo Rezende, and SM Ali Eslami. Conditional neural processes. In International Confer ence on Machine Learning , pages 1690–1699, 2018. [7] Siav ash Golkar , Michael Kagan, and K yunghyun Cho. Continual learning via neural pruning. arXiv pr eprint arXiv:1903.04476 , 2019. [8] Ian J Goodfello w , Mehdi Mirza, Da Xiao, Aaron Courville, and Y oshua Bengio. An empirical in vestigation of catastrophic for getting in gradient-based neural networks. arXiv pr eprint arXiv:1312.6211 , 2013. [9] Xu He and Herbert Jaeger . Overcoming catastrophic interference using conceptor-aided backpropagation. In International Confer ence on Learning Repr esentations , 2018. URL https://openreview.net/forum?id=B1al7jg0b . [10] Sepp Hochreiter , A. Stev en Y ounger , and Peter R. Conwell. Learning to learn using gradient descent. In Pr oceedings of the International Conference on Artificial Neural Networks , ICANN ’01, pages 87–94, London, UK, 2001. Springer-V erlag. ISBN 3-540-42486-5. URL http: //dl.acm.org/citation.cfm?id=646258.684281 . [11] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [12] James Kirkpatrick, Razvan Pascanu, Neil Rabino witz, Joel V eness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, T iago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic for getting in neural networks. Proceedings of the national academy of sciences , 114(13):3521–3526, 2017. [13] Gregory Koch. Siamese neural networks for one-shot image recognition. In ICML Deep Learning workshop , 2015. [14] Abhishek Kumar and Hal Daume III. Learning task grouping and o verlap in multi-task learning. arXiv pr eprint arXiv:1206.6417 , 2012. [15] Brenden M Lake, Ruslan Salakhutdinov , and Joshua B T enenbaum. Human-lev el concept learning through probabilistic program induction. Science , 350(6266):1332–1338, 2015. [16] David Lopez-Paz et al. Gradient episodic memory for continual learning. In Advances in Neural Information Pr ocessing Systems , pages 6467–6476, 2017. [17] Arun Mallya and Svetlana Lazebnik. P acknet: Adding multiple tasks to a single network by iterativ e pruning. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 7765–7773, 2018. 9 [18] Nicolas Y . Masse, Gregory D. Grant, and David J. Freedman. Alleviating catastrophic forgetting using context-dependent gating and synaptic stabilization. Pr oceedings of the National Academy of Sciences , 115(44):E10467–E10475, 2018. ISSN 0027-8424. doi: 10.1073/pnas.1803839115. URL https://www.pnas.org/content/115/44/E10467 . [19] Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation , volume 24, pages 109–165. Elsevier , 1989. [20] Kieran Milan, Joel V eness, James Kirkpatrick, Michael Bowling, Anna Koop, and Demis Hassabis. The forget-me-not process. In Advances in Neural Information Pr ocessing Systems , pages 3702–3710, 2016. [21] George E Monahan. State of the art—a survey of partially observ able markov decision processes: theory , models, and algorithms. Mana gement Science , 28(1):1–16, 1982. [22] Anusha Nagabandi, Chelsea Finn, and Serge y Levine. Deep online learning via meta-learning: Continual adaptation for model-based RL. In International Conference on Learning Repr esen- tations , 2019. URL https://openreview.net/forum?id=HyxAfnA5tm . [23] Cuong V Nguyen, Y ingzhen Li, Thang D Bui, and Richard E T urner . V ariational continual learning. arXiv pr eprint arXiv:1710.10628 , 2017. [24] German I Parisi, Ronald Kemk er , Jose L Part, Christopher Kanan, and Stefan W ermter . Continual lifelong learning with neural networks: A revie w . Neural Networks , 2019. [25] Sachin Ra vi and Hugo Larochelle. Optimization as a model for few-shot learning. International Confer ence on Learning Representations , 2016. [26] Hippolyt Ritter , Aleksandar Bote v , and David Barber . Online structured laplace approximations for ov ercoming catastrophic forgetting. In Advances in Neural Information Pr ocessing Systems , pages 3738–3748, 2018. [27] Anthony Robins. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science , 7 (2):123–146, 1995. [28] Andrei A Rusu, Neil C Rabino witz, Guillaume Desjardins, Hubert Soyer , James Kirkpatrick, K oray Kavukcuoglu, Razv an Pascanu, and Raia Hadsell. Progressiv e neural networks. arXiv pr eprint arXiv:1606.04671 , 2016. [29] Andrei A. Rusu, Dushyant Rao, Jakub Sygnowski, Oriol V inyals, Razvan Pascanu, Simon Osindero, and Raia Hadsell. Meta-learning with latent embedding optimization. In International Confer ence on Learning Repr esentations , 2019. URL https://openreview.net/forum? id=BJgklhAcK7 . [30] Paul Ruvolo and Eric Eaton. Ella: An ef ficient lifelong learning algorithm. In International Confer ence on Machine Learning , pages 507–515, 2013. [31] Adam Santoro, Sergey Bartuno v , Matthew Botvinick, Daan W ierstra, and T imothy Lillicrap. Meta-learning with memory-augmented neural netw orks. In International conference on machine learning , pages 1842–1850, 2016. [32] Juergen Schmidhuber . Evolutionary principles in self-referential learning. Diploma thesis, TU Munich , 1987. [33] Jonathan Schwarz, W ojciech Czarnecki, Jelena Luketina, Agnieszka Grabska-Barwinska, Y ee Whye T eh, Razv an P ascanu, and Raia Hadsell. Progress & compress: A scalable framework for continual learning. In International Conference on Machine Learning , pages 4535–4544, 2018. [34] Joan Serra, Didac Suris, Marius Miron, and Alexandros Karatzoglou. Overcoming catastrophic forgetting with hard attention to the task. In International Confer ence on Machine Learning , pages 4555–4564, 2018. 10 [35] Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generativ e replay . In Advances in Neural Information Pr ocessing Systems , pages 2990–2999, 2017. [36] Oriol V inyals, Charles Blundell, T imothy Lillicrap, Daan W ierstra, et al. Matching networks for one shot learning. In Advances in neural information pr ocessing systems , pages 3630–3638, 2016. [37] Chen Zeno, Itay Golan, Elad Hof fer, and Daniel Soudry . Bayesian gradient descent: Online variational bayes learning with increased rob ustness to catastrophic for getting and weight pruning. arXiv pr eprint arXiv:1803.10123 , 2018. [38] Luisa M Zintgraf, Kyriacos Shiarlis, V italy Kurin, Katja Hofmann, and Shimon Whiteson. CA VIA: Fast context adaptation via meta-learning, 2019. 11 A Meta Learning as T ask Inferences T able 1: Meta learning methods as instances of the What & Ho w frame work Methods c t := F What ( D cxt t ) F How ( c t ) MAML θ t := θ init t − λ in ∇ θ L in ( ˆ f ( · ; θ ) , D cxt t ) ˆ f ( · ; θ t ) CNP r t := L x i ,y i ∈D cxt t h θ ( x i , y i ) g θ ( · , r t ) LEO z 0 t := z t − λ in ∇ z 0 L in ( ˆ f ( · ; w t ) , D cxt t ) w 0 t ∼ N ( µ d 0 t ( z 0 t ) , diag ( σ d 0 t ( z 0 t ) 2 )) CA VIA c t := c init − λ in ∇ c L in ( ˆ f ( · , c ; θ ) , D cxt t ) ˆ f ( · , c t ; θ ) B Experiment Details B.1 Model Configurations In all experiments, the number of samples K in Eq. 2 is set to 10. In MetaCoG, the initial v alue of masks m init i is 0. In MetaELLA, we use k = 10 components in the dictionary , and the initial value of latent code s init i is set to 1 /k = 0 . 1 . Adam baseline were trained with the default hyperparameters recommended in [ 11 ]. The hyperparameters of other methods are tuned by a Bayesian optimization algorithm and are summarized in T able 2. Error bars for all experiments are standard de viations computed from 10 trials with different random seeds. B.2 Sine Curve Regr ession The amplitudes and phases of sine curves are sampled uniformly from [1 . 0 , 5 . 0] and [0 , π ] , respectiv ely . For both training and testing, input data points x are sampled uniformly from [ − 5 . 0 , 5 . 0] . The size of training and testing sets for each task are 5000 and 100, respectiv ely . Each sine curve is presented for 1000 iterations, and a mini-batch of 128 data points is provided at ev ery iteration for training. The 3-layer MLP has 50 units with tanh( · ) non-linearity in each hidden layer . B.3 Label-Permuted MNIST All tasks are presented for 1000 iterations and the mini-batch size is 128. The network used in this experiment was a MLP with 2 hidden layers of 300 ReLU units. B.4 Omniglot W e use 20 characters from each alphabet for classification. Out of the 20 images of each character , 15 were used for training and 5 for testing. Each alphabet was trained for 200 epochs with mini-batch size 128. The CNN used in this experiment has tw o conv olutional layers, both with 40 channels and kernel size 5. ReLU and max pooling are applied after each conv olution layer, and the output is passed to a fully connected layer of size 300 before the final layer . 12 T able 2: Summary of hyperparameters used for the experiments. λ in are inner loop learning rates. σ 0 are initial values for standard deviation of the factorized Gaussian. η is the learning rate of the mean in BGD update rule. γ is the regularization strength for L1 norm of masks in MetaCoG. µ is the regularization strength for L1 norm of latent code in MetaELLA. Hyperparameters Sine Curve Label-Permuted MNIST Omniglot MetaBGD λ in 0.0419985 0.45 0.207496 σ 0 0.0368604 0.050 0.0341916 η 5.05646 1.0 15.8603 MetaCoG λ in 0.849212 10.000 5.53639 σ 0 0.0426860 0.034 0.0133221 γ 1.48236e-6 1.000e-5 3.04741e-6 η 38.6049 1.0 80.0627 MetaElla λ in 0.0938662 0.400 0.346027 σ 0 0.0298390 0.010 0.0194483 µ 0.0216156 0.010 0.0124128 η 42.6035 1.0 24.7476 BGD σ 0 0.0246160 0.060 0.0311284 η 20.3049 1.0 16.2192 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment