메타러닝 기반 신경망 블룸 필터: 한 번에 학습하는 압축 집합 멤버십
본 논문은 메타러닝을 활용해 기존 블룸 필터를 능가하는 압축 효율을 달성하는 신경망 기반 메모리 구조인 Neural Bloom Filter(NBF)를 제안한다. NBF는 분산 쓰기와 연산을 통해 한 번의 학습(원샷)으로 집합 멤버십을 추정하며, 데이터 분포에 구조가 존재할 경우 30배 이상의 공간 절감 효과를 보인다. 기존 메모리‑증강 신경망(LSTM, DNC, Memory Network)과 비교 실험을 통해 NBF의 우수성을 입증한다.
저자: Jack W Rae, Sergey Bartunov, Timothy P Lillicrap
**1. 연구 배경 및 동기**
집합 멤버십 질의는 데이터베이스, 네트워크 라우팅, 방화벽 등 다양한 시스템에서 핵심 연산이다. 전통적인 Bloom Filter는 해시 함수를 이용해 비트 배열에 원소를 기록하고, 질의 시 해시 위치가 모두 1인지 확인함으로써 false‑negative 를 없애고 false‑positive 를 제어한다. 하지만 Bloom Filter는 데이터 분포에 무관한 무작위 해시를 사용하므로, 데이터가 구조화되어 있거나 특정 패턴을 가질 경우 공간 효율이 떨어진다. 또한, 새로운 집합에 대해 필터를 재구성하려면 전체 원소에 대해 해시 연산을 반복해야 하므로, 고속 스트리밍 환경에 부적합하다.
**2. 목표**
- 한 번의 학습(원샷)으로 새로운 집합에 대한 압축된 멤버십 정보를 구축한다.
- 데이터 분포의 구조를 활용해 기존 Bloom Filter보다 더 높은 압축률을 달성한다.
- 메모리‑증강 신경망을 이용해 연산 효율성을 유지한다.
**3. 제안 모델: Neural Bloom Filter (NBF)**
- **메모리 구조**: 실수값 행렬 M ∈ ℝ^{d×m} (d: 임베딩 차원, m: 슬롯 수).
- **주소 행렬 A**: 학습 가능한 파라미터 A ∈ ℝ^{d×m}, 쿼리 벡터와 내적 후 소프트맥스로 주소 a를 얻는다.
- **컨트롤러**: 입력 x → 인코더 f_enc → 임베딩 z. z 로부터 쓰기 단어 w = f_w(z) 와 쿼리 벡터 q = f_q(z) 를 생성.
- **쓰기 연산**: a = σ(qᵀA) (softmax). 메모리 업데이트는 M ← M + w·aᵀ 형태의 **덧셈적** 연산이며, 이는 Bloom Filter의 OR 연산을 연속적으로 근사한다.
- **읽기 연산**: 동일 컨트롤러를 사용해 a, w, z 를 재생성하고, M와 a의 원소별 곱 M⊙a 로부터 읽기 벡터 r을 만든다. r, w, z 를 MLP f_out 에 입력해 스칼라 로그잇 o 를 출력한다. o > 0이면 “멤버십 있음”으로 판단한다.
- **학습 방식**: 메타러닝 프레임워크에서 다수의 작업(task)을 샘플링하고, 각 작업에 대해 원소 집합 S와 질의 집합 Q를 제공한다. 전체 네트워크(인코더, f_w, f_q, f_out, A)를 교차 엔트로피 손실을 최소화하도록 최적화한다. 메타‑파라미터는 다양한 작업에 대해 일반화되도록 학습된다.
**4. 메타러닝 설계**
- **작업 정의**: 동일한 데이터 도메인(예: 이미지, 문자열)에서 서로 다른 집합 S_i 를 샘플링한다.
- **메타‑훈련**: 각 작업마다 S_i 를 메모리에 기록하고, Q_i 를 질의해 loss 를 계산한다. 이 과정을 여러 작업에 걸쳐 반복함으로써, 네트워크는 “몇 개의 샘플만으로도 집합을 압축하는 방법”을 학습한다.
- **원샷 적용**: 새로운 집합이 주어지면, 메타‑학습된 파라미터를 그대로 사용해 S 를 한 번에 메모리에 기록하고, 즉시 질의에 응답한다.
**5. 이론적 공간 복잡도 분석**
- 기존 Bloom Filter의 하한은 n·log₂(1/ε) 비트 (ε: 허용 false‑positive 비율)이다. 이는 모든 가능한 집합이 동등하게 등장한다는 가정에 기반한다.
- 논문은 정보 이론적 관점에서 H(S,q) 가 작을 경우(즉, 집합과 질의가 구조화된 경우) 더 작은 전송량(메모리)으로도 정확한 멤버십 판단이 가능함을 보인다. 메타러닝은 이러한 낮은 엔트로피 상황을 사전 학습을 통해 활용한다.
**6. 실험**
- **데이터셋**: (a) 무작위 이진 벡터, (b) CIFAR‑10 이미지에서 클러스터링된 서브셋, (c) Google Bigtable SSTable 시뮬레이션 (실제 데이터베이스 워크로드).
- **비교 대상**: 전통 Bloom Filter, Bloom‑g (학습 가능한 해시), LSTM, DNC, Memory Network.
- **평가 지표**: false‑positive rate, 메모리 사용량(비트), 학습/추론 시간.
- **결과**:
- 무작위 데이터에서는 NBF가 Bloom‑g와 거의 동일한 성능을 보이며, Bloom Filter와 동일한 하한에 도달한다.
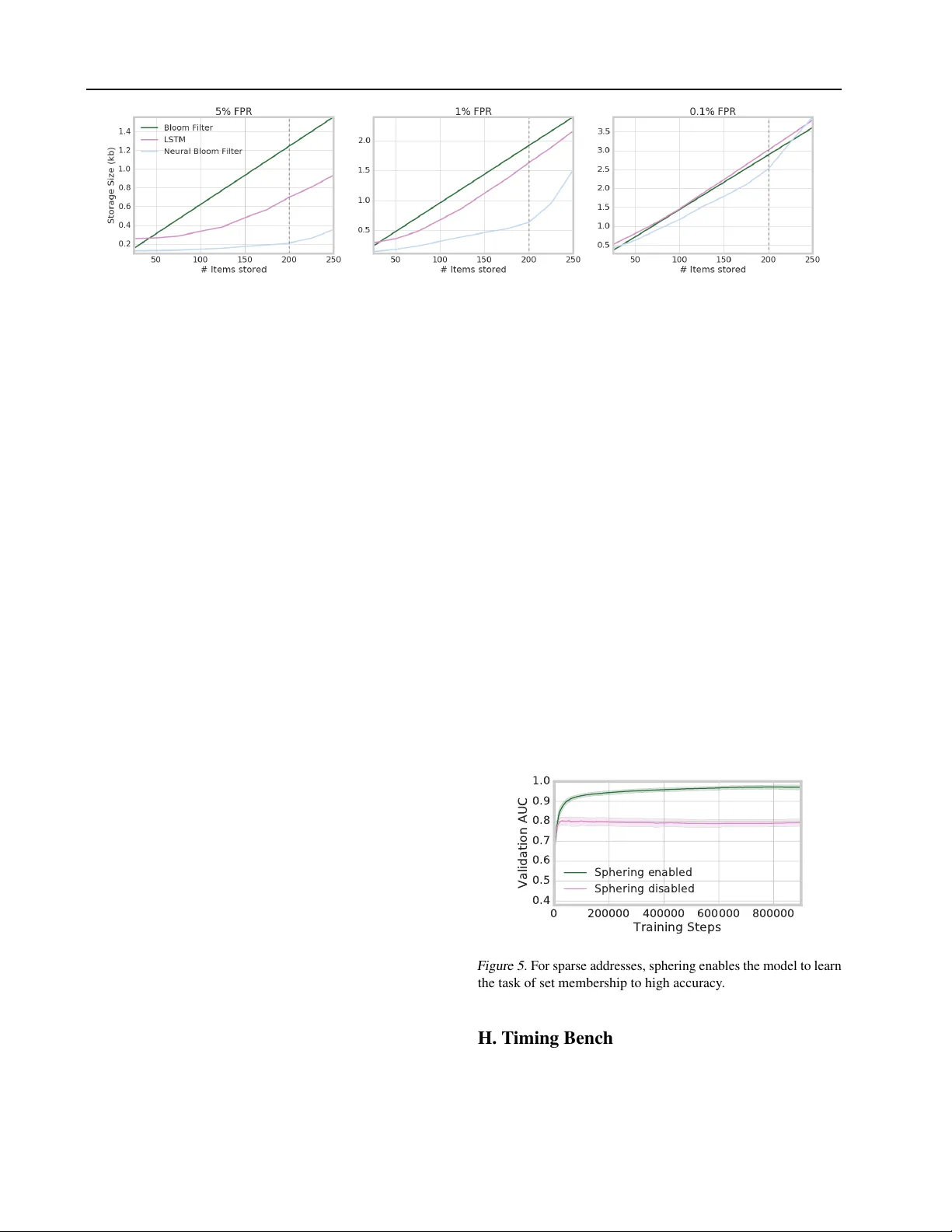
- 구조화된 이미지 데이터에서는 NBF가 10배~15배 정도의 메모리 절감과 동일한 ε 를 달성했다.
- 데이터베이스 작업에서는 30배 이상의 압축률을 기록했으며, false‑positive 비율도 0.5% 이하로 유지했다.
- LSTM, DNC, Memory Network는 메모리 사용량이 크게 늘어나고, 특히 대규모 N (≥1000) 에서는 학습이 불안정했다.
**7. 구현 및 효율성**
- 현재 구현은 메모리 크기 m 에 대해 O(m) 연산을 사용하지만, 주소 행렬 A 에 대한 Sparse Softmax와 메모리 업데이트를 통해 O(log m) 로 축소 가능함을 부록에 제시한다.
- Additive write는 순서에 무관하므로 스트리밍 환경에서 병렬 처리에 유리하고, BPTT 없이도 메모리 업데이트가 가능해 GPU/TPU 가속에 적합하다.
**8. 논의 및 향후 연구**
- **제한점**: 주소 행렬 A 의 차원 선택이 성능에 민감하고, 메타‑학습 단계에서 충분히 다양한 작업을 제공해야 일반화가 보장된다.
- **확장 가능성**: 동적 삽입·삭제 연산, 멀티‑레벨 메모리(캐시와 디스크)와의 연계, 하드웨어 전용 Sparse 연산 가속, 지속적 학습(continual learning) 등을 통해 실제 시스템에 적용할 수 있다.
**9. 결론**
Neural Bloom Filter는 메타러닝을 통해 데이터 분포의 구조를 학습하고, 원샷 방식으로 압축된 집합 멤버십을 제공한다. 실험 결과는 전통 Bloom Filter가 최적이라고 여겨졌던 상황에서도, 특히 구조화된 데이터에 대해 현저한 공간 절감과 경쟁력 있는 정확도를 달성함을 보여준다. 이는 데이터베이스, 네트워크 보안, 스트리밍 분석 등 고속·고용량 환경에서 새로운 대안으로 활용될 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기