Meta-Learning Neural Bloom Filters
There has been a recent trend in training neural networks to replace data structures that have been crafted by hand, with an aim for faster execution, better accuracy, or greater compression. In this setting, a neural data structure is instantiated b…
Authors: Jack W Rae, Sergey Bartunov, Timothy P Lillicrap
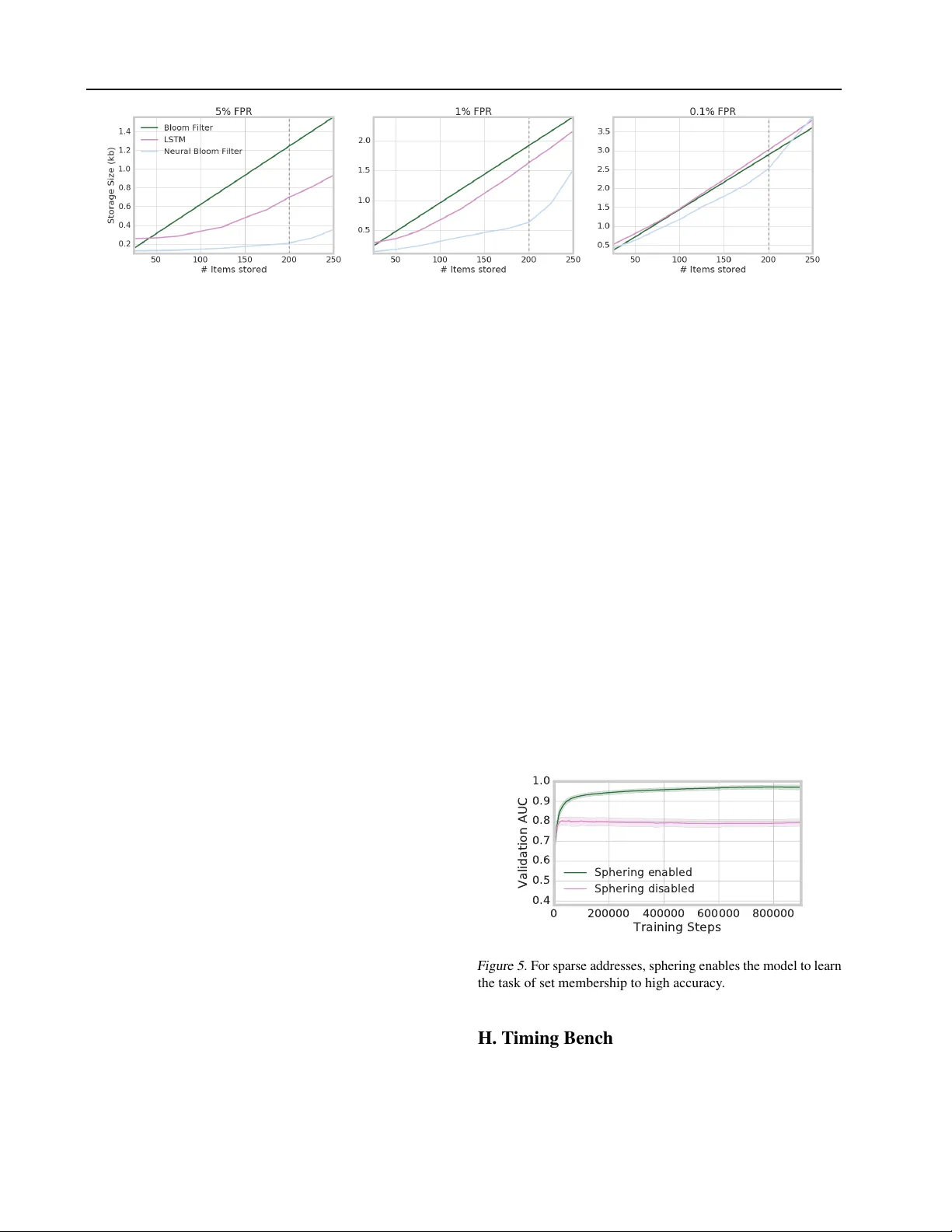
Meta-Learning Neural Bloom Filters Jack W Rae 1 2 Sergey Bartunov 1 Timoth y P Lillicrap 1 2 Abstract There has been a recent trend in training neural networks to replace data structures that hav e been crafted by hand, with an aim for faster execution, better accuracy , or greater compression. In this setting, a neural data structure is instantiated by training a network ov er many epochs of its inputs until conv ergence. In applications where inputs arriv e at high throughput, or are ephemeral, train- ing a network from scratch is not practical. This motiv ates the need for few-shot neural data struc- tures. In this paper we explore the learning of approximate set membership ov er a set of data in one-shot via meta-learning. W e propose a no vel memory architecture, the Neural Bloom Filter , which is able to achie ve significant compression gains over classical Bloom Filters and existing memory-augmented neural networks. 1. Introduction One of the simplest questions one can ask of a set of data is whether or not a gi ven query is contained within it. Is q , our query , a member of S , our chosen set of observ ations? This set membership query arises across many computing domains; from databases, network routing, and firewalls. One could query set membership by storing S in its entirety and comparing q against each element. Howe ver , more space-efficient solutions e xist. The original and most widely implemented appr oximate set membership data-structure is the Bloom Filter ( Bloom , 1970 ). It works by storing sparse distributed codes, pro- duced from randomized hash functions, within a binary vector . The Bloom-filter trades off space for an allowed false positi ve rate, which arises due to hash collisions. Ho w- ev er its error is one-sided; if an element q is contained in S then it will always be recognized. It nev er emits false nega- 1 DeepMind, London, UK 2 CoMPLEX, Computer Science, Univ ersity College London, London, UK. Correspondence to: Jack W Rae < jwrae@google.com > . Pr oceedings of the 36 th International Conference on Machine Learning , Long Beach, California, PMLR 97, 2019. Copyright 2019 by the author(s). tiv es. One can find Bloom Filters embedded within a wide range of production systems; from network security ( Ger- av and & Ahmadi , 2013 ), to block malicious IP addresses; databases , such as Google’ s Bigtable ( Chang et al. , 2008 ), to av oid unnecessary disk lookups; cryptocurrency ( Hearn & Corallo , 2012 ), to allow clients to filter irrelev ant transac- tions; sear ch , such as Facebook’ s typeahead search ( Adams , 2010 ), to filter pages which do not contain query prefix es; and pr ogram verification ( Dillinger & Manolios , 2004 ), to av oid recomputation over pre viously observed states. While the main appeal of Bloom Filters is fa vourable com- pression, another important quality is the support for dy- namic updates. Ne w elements can be inserted in O (1) time. This is not the case for all approximate set membership data structures. For e xample, perfect hashing saves ≈ 40% space o ver Bloom Filters b ut requires a pre-processing stage that is polynomial-time in the number of elements to store ( Dietzfelbinger & Pagh , 2008 ). Whilst the static set mem- bership problem is interesting, it limits the applicability of the algorithm. For e xample, in a database application that is serving a high throughput of write operations, it may be intractable to regenerate the full data-structure upon each batch of writes. W e thus focus on the data stream computation model ( Muthukrishnan et al. , 2005 ), where input observations are assumed to be ephemeral and can only be inspected a con- stant number of times — usually once. This captures many real-world applications: network traf fic analysis, database query serving, and reinforcement learning in complex do- mains. Devising an approximate set membership data struc- ture that is not only more compressi ve than Bloom Filters, but can be applied to either dynamic or static sets, could hav e a significant performance impact on modern computing applications. In this paper we inv estigate this problem using memory-augmented neural networks and meta-learning. W e b uild upon the recently growing literature on using neu- ral networks to replace algorithms that are configured by heuristics, or do not take adv antage of the data distrib ution. For example, Bloom Filters are indifferent to the data dis- tribution. They have near-optimal space efficiency when data is drawn uniformly from a uni verse set ( Carter et al. , 1978 ) (maximal-entropy case) but (as we shall sho w) are sub-optimal when there is more structure. Prior studies on Meta-Learning Neural Bloom Filters this theme ha ve in vestigated compiler optimization ( Cum- mins et al. , 2017 ), computation graph placement ( Mirho- seini et al. , 2017 ), and data index structures such as b-trees ( Kraska et al. , 2018 ). In the latter work, Kraska et al. ( 2018 ) explicitly consider the problem of static set membership. By training a neural network over a fixed S (in their case, string inputs) along with held-out ne gative e xamples, the y observe 36% space reduction over a conv entional Bloom Filter 1 . Crucially this requires iterating ov er the storage set S a large number of times to embed its salient information into the weights of a neural network classifier . For a new S this process would ha ve to be repeated from scratch. Instead of learning from scratch, we draw inspiration from the fe w-shot learning advances obtained by meta-learning memory-augmented neural networks ( Santoro et al. , 2016 ; V inyals et al. , 2016 ). In this setup, tasks are sampled from a common distribution and a network learns to specialize to (learn) a gi ven task with few examples. This matches very well to applications where many Bloom Filters are instantiated ov er different subsets of a common data distri- bution. For e xample, a Bigtable database usually contains one Bloom Filter per SST able file. For a large table that contains Petabytes of data, say , there can be o ver 100 , 000 separate instantiated data-structures which share a common row-k ey format and query distrib ution. Meta-learning al- lows us to exploit this common redundancy . W e design a database task with similar redundancy to in vestigate this exact application in Section 5.4 . The main contrib utions of this paper are (1) A ne w memory- augmented neural network architecture, the Neur al Bloom F ilter , which learns to write to memory using a distributed write scheme, and (2) An empirical ev aluation of the Neu- ral Bloom Filter meta-learned on one-shot approximate set membership problems of v arying structure. W e compare with the classical Bloom Filter alongside other memory- augmented neural networks such as the Dif ferentiable Neu- ral Computer ( Grav es et al. , 2016 ) and Memory Netw orks ( Sukhbaatar et al. , 2015 ). W e find when there is no structure, that differentiates the query set elements and queries, the Neural Bloom Filter learns a solution similar to a Bloom Filter deriv ativ e — a Bloom-g filter ( Qiao et al. , 2011 ) — but when there is a lot of structure the solution can be con- siderably more compressiv e (e.g. 30 × for a database task). 2. Background 2.1. Appr oximate Set Membership The problem of exact set membership is to state whether or not a given query q belongs to a set of n distinct observa- 1 The space sa ving increases to 41% when an additional trick is incorporated, in discretizing and re-scaling the classifier outputs and treating the resulting function as a hash function to a bit-map. tions S = { x 1 , . . . , x n } where x i are drawn from a univ erse set U . By counting the number of distinct subsets of size n it can be sho wn that any such e xact set membership tester re- quires at least log 2 | U | n bits of space. T o mitigate the space dependency on | U | , which can be prohibitiv ely large, one can relax the constraint on perfect correctness. Appr oximate set membership allows for a false positive rate of at most . Specifically we answer q ∈ A ( S ) where A ( S ) ⊇ S and p ( q ∈ A ( S ) − S ) ≤ . It can be sho wn 2 the space require- ment for approximate set membership of uniformly sampled observations is at least n log 2 ( 1 ) bits ( Carter et al. , 1978 ) which can be achie ved with perfect hashing. So for a false positi ve rate of 1% , say , this amounts to 6 . 6 bits per element. In contrast to storing raw or compressed elements this can be a huge space saving, for example ImageNet images re- quire 108 KB per image on av erage when compressed with JPEG, an increase of ov er four orders of magnitude. 2.2. Bloom Filter The Bloom Filter ( Bloom , 1970 ) is a data structure which solves the dynamic approximate set membership problem with near-optimal space complexity . It assumes access to k uniform hash functions h i : U → { 1 , . . . , m } , i = 1 , . . . , k such that p ( h i ( x ) = j ) = 1 /m independent of prior hash values or input x . The Bloom Filter’ s mem- ory M ∈ [0 , 1] m is a binary string of length m which is initialized to zero. Writes are performed by hashing an input x to k locations in M and setting the correspond- ing bits to 1 , M [ h i ( x )] ← 1; i = 1 , . . . , k . For a given query q the Bloom Filter returns true if all corresponding hashed locations are set to 1 and returns false otherwise: Quer y ( M , q ) := M [ h 1 ( q )] ∧ M [ h 2 ( q )] ∧ . . . ∧ M [ h k ( q )] . This incurs zero false negati ves, as an y previously observed input must hav e enabled the corresponding bits in M , how- ev er there can be f alse positi ves due to hash collisions. T o achie ve a false positi ve rate of with minimal space one can set k = log 2 (1 / ) and m = n log 2 (1 / ) log 2 e , where e is Euler’ s number . The resulting space is a factor of log 2 e ≈ 1 . 44 from the optimal static lower bound gi ven by Carter et al. ( 1978 ). 2.3. Memory-A ugmented Neural Networks Recurrent neural networks such as LSTMs retain a small amount of memory via the recurrent state. Howe ver this is usually tied to the number of trainable parameters in the model. There has been recent interest in augmenting neural networks with a larger e xternal memory . The method for do- ing so, via a dif f erentiable write and read interf ace, was first popularized by the Neural T uring Machine (NTM) ( Graves et al. , 2014 ) and its successor the Differentiable Neural 2 By counting the minimal number of A ( S ) sets required to cov er all S ⊂ U . Meta-Learning Neural Bloom Filters Computer (DNC) ( Graves et al. , 2016 ) in the context of learning algorithms, and by Memory Networks ( Sukhbaatar et al. , 2015 ) in the context of question answering. Memory Networks store embeddings of the input in separate rows of a memory matrix M . Reads are performed via a dif- ferentiable content-based addr essing operation. Giv en a query embedding q we take some similarity measure D (e.g. cosine similarity , or negati ve euclidean distance) against each row in memory and apply a softmax to obtain a soft address vector a ∝ e D ( q ,M ) . A read is then a weighted sum over memory r ← a T M . The NTM and DNC use the same content-based read mechanism, but also learns to write. These models can arbitrate whether to write to slots in memory with similar content (content-based writes), temporally ordered locations, or unused memory . When it comes to capacity , there has been consideration to scaling both the DNC and Memory Networks to very large sizes using sparse read and write operations ( Rae et al. , 2016 ; Chandar et al. , 2016 ). Howe ver another way to in- crease the capacity is to increase the amount of compression which occurs in memory . Memory Nets can create com- pressiv e representations of each input, but cannot compress jointly ov er multiple inputs because they are hard-wired to write one slot per timestep. The NTM and DNC can compress ov er multiple slots in memory because they can arbitrate writes across multiple locations, but in practice seem to choose very sharp read and write addresses. The Kanerva Machine ( W u et al. , 2018a ; b ) tackles memory-wide compression using a distributed write scheme to jointly com- pose and compress its memory contents. The model uses content-based addressing ov er a separate learnable address- ing matrix A , instead of the memory M , and thus learns wher e to write. W e take inspiration from this scheme. 3. Model One approach to learning set membership in one-shot would be to use a recurrent neural network, such as an LSTM or DNC. Here, the model sequentially ingests the N elements to store, answers a set of queries using the final state, and is trained by BPTT . Whilst this is a general training approach, and the model may learn a compressiv e solution, it does not scale well to larger number of elements. Even when N = 1000 , backpropagating ov er a sequence of this length induces computational and optimization challenges. For larger v alues this quickly becomes intractable. Alternatively one could store an embedding of each element x i ∈ S in a slot-based Memory Netw ork. This is more scalable as it av oids BPTT , because the gradients of each input can be calculated in parallel. Ho we ver Memory Networks are not a space efficient solution (as sho wn in in Section 5 ) because there is no joint compression of inputs. This motiv ates the proposed memory model, the Neural Algorithm 1 Neural Bloom Filter 1: def controller(x): 2: z ← f enc ( x ) // Input embedding 3: q ← f q ( z ) // Query word 4: a ← σ ( q T A ) // Memory address 5: w ← f w ( z ) // Write word 6: def write(x): 7: a, w ← controller ( x ) 8: M t +1 ← M t + w a T // Additiv e write 9: def read(x): 10: a, w , z ← controller ( x ) 11: r ← flatten ( M a) // Read words 12: o ← f out ([ r , w , z ]) // Output logit Bloom Filter . Briefly , the network is augmented with a real-valued memory matrix. The network addr esses mem- ory by classifying which memory slots to read or write to via a softmax, conditioned on the input. W e can think of this as a continuous analogue to the Bloom Filter’ s hash function; because it is learned the network can co-locate or separate inputs to improve performance. The network up- dates memory with a simple additive write operation — i.e. no multiplicativ e gating or squashing — to the addressed locations. An additi ve write operation can be seen as a con- tinuous analogue to the the Bloom Filter’ s logical OR write operation. Crucially , the additi ve write scheme allo ws us to train the model without BPTT — this is because gradients with respect to the write words ∂ L/∂ w = ( ∂ L/∂ M ) T a can be computed in parallel. Reads in volv e a component- wise multiplication of address and memory (analogous to the selection of locations in the Bloom Filter via hashing), but instead of projecting this do wn to a scalar with a fix ed function, we pass this through an MLP to obtain a scalar familiarity logit. The network is fully dif ferentiable, allows for memories to be stored in a distrib uted fashion across slots, and is quite simple e.g. in comparison to DNCs. The full architecture depicted in Figure 1 consists of a contr oller network which encodes the input to an embed- ding z ← f enc ( x ) and transforms this to a write word w ← f w ( z ) and a query q ← f q ( z ) . The address over memory is computed via a softmax a ← σ ( q T A ) ov er the content-based attention between q and a learnable address matrix A . Here, σ denotes a softmax. The network thus learns where to place elements or overlap elements based on their content, we can think of this as a soft and dif ferentiable relaxation of the uniform hashing families incorporated by the Bloom Filter (see Appendix A.3 for further discussion). A write is performed by running the controller to obtain a write word w and address a , and then additi vely writing w to M , weighted by the address a , M t +1 ← M t + wa T . The Meta-Learning Neural Bloom Filters M q A w x a o w r z z w Figure 1. Overvie w of the Neural Bloom Filter architecture. simple additi ve write ensures that the resulting memory is in variant to input ordering (as addition is commutativ e) and we do not ha ve to backpropagate-through-time (BPTT) o ver sequential writes — gradients can be computed in parallel. A r ead is performed by also running the controller network to obtain z , w , and a and component-wise multiplying the address a with M , r ← M a . The read words r are fed through an MLP along with the residual inputs w and z and are projected to a single scalar logit, indicating the familiarity signal. W e found this to be more powerful than the con ventional read operation r ← a T M used by the DNC and Memory Networks, as it allo ws for non-linear interactions between ro ws in memory at the time of read. See Algorithm 1 for an ov erview of the operations. T o giv e an example network configuration, we chose f enc to be a 3-layer CNN in the case of image inputs, and a 128 - hidden-unit LSTM in the case of te xt inputs. W e chose f w and f q to be an MLP with a single hidden layer of size 128 , followed by layer normalization, and f out to be a 3-layer MLP with residual connections. W e used a leaky ReLU as the non-linearity . Although the described model uses dense operations that scale linearly with the memory size m , we discuss how the model could be implemented for O (log m ) time reads and writes using sparse attention and read/write operations, in Appendix A.1 . Furthermore the model’ s rela- tion to uniform hashing is discussed in Appendix A.3 . 4. Space Complexity In this section we discuss space lower bounds for the approx- imate set membership problem when there is some structure to the storage or query set. This can help us formalise why and where neural networks may be able to beat classical lower bounds to this problem. The n log 2 (1 / ) lower bound from Carter et al. ( 1978 ) as- sumes that all subsets S ⊂ U of size n , and all queries q ∈ U hav e equal probability . Whilst it is instructiv e to bound this maximum-entropy scenario, which we can think of as ‘worst case’, most applications of approximate set membership e.g. web cache sharing, querying databases, or spell-checking, in volv e sets and queries that are not sampled uniformly . For example, the elements within a gi ven set may be highly dependent, there may be a power -law distrib ution ov er queries, or the queries and sets themselves may not be sampled independently . A more general space lo wer bound can be defined by an information theoretic argument from communication com- plexity ( Y ao , 1979 ). Namely , approximate set membership can be framed as a two-party communication problem be- tween Alice, who observes the set S and Bob, who observes a query q . The y can agree on a shared policy Π in which to communicate. F or giv en inputs S, q they can produce a transcript A S,q = Π( S, q ) ∈ Z which can be processed g : Z → 0 , 1 such that P ( g ( A S,q ) = 1 | q 6∈ S ) ≤ . Bar- Y ossef et al. ( 2004 ) shows that the maximum transcript size is greater than the mutual information between the inputs and transcript: max S,q | A S,q | ≥ I ( S, q ; A S,q ) = H ( S, q ) − H ( S, q | A S,q ) . Thus we note problems where we may be able to use less space than the classical lo wer bound are cases where the entropy H ( S, q ) is small, e.g. our sets are highly non-uniform, or cases where H ( S, q | A S,q ) is large, which signifies that many query and set pairs can be solved with the same transcript. 5. Experiments Our experiments explore scenarios where set membership can be learned in one-shot with improved compression ov er the classical Bloom Filter . W e consider tasks with v ary- ing lev els of structure in the storage sets S and queries q . W e compare the Neural Bloom Filter with three memory- augmented neural networks, the LSTM, DNC, and Memory Network, that are all able to write storage sets in one-shot. The training setup follows the memory-augmented meta- learning training scheme of V inyals et al. ( 2016 ), only here the task is familiarity classification versus image classifica- tion. The network samples tasks which in volve classifying familiarity for a given storage set. Meta-learning occurs as a two-speed process, where the model quickly learns to recognize a gi ven storage set S within a training episode via writing to a memory or state, and the model slo wly learns to improv e this fast-learning process by optimizing the model parameters θ ov er multiple tasks. W e detail the training routine in Algorithm 2 . Meta-Learning Neural Bloom Filters Class-Based Familiarity Uniform Instance-Based Familiarity Non-Uniform Instance-Based Familiarity (a) (b) (c) — Memory Network — Bloom Filter — DNC — LSTM — Neural Bloom Filter Failed at task for lar ger no. items Figure 2. Sampling strategies on MNIST . Space consumption at 1% FPR. Algorithm 2 Meta-Learning T raining 1: Let S train denote the distribution o ver sets to store. 2: Let Q train denote the distribution o ver queries. 3: for i = 1 to max train steps do 4: Sample task: 5: Sample set to store: S ∼ S train 6: Sample t queries: x 1 , . . . , x t ∼ Q train 7: T argets: y j = 1 if x j ∈ S else 0; j = 1 , . . . , t 8: Write entries to memory: M ← f wr ite θ ( S ) 9: Calculate logits: o j = f read θ ( M , x j ); j = 1 , . . . , t 10: XE loss: L = P t j =1 y j log o j + (1 − y j )(1 − log o j ) 11: Backprop through queries and writes: dL/dθ 12: Update parameters: θ i +1 ← Optimizer ( θ i , dL/dθ ) 13: end for For the RNN baselines (LSTM and DNC) the write opera- tion corresponds to unrolling the network ov er the inputs and outputting the final state. For these models, the query network is simply an MLP classifier which recei ves the con- catenated final state and query , and outputs a scalar logit. For the Memory Network, inputs are stored in indi vidual slots and the familiarity signal is computed from the max- imum content-based attention value. The Neural Bloom Filter read and write operations are defined in Algorithm 1 . 5.1. Space Comparison W e compared the space (in bits) of the model’ s memory (or state) to a Bloom Filter at a giv en false positiv e rate and 0% false negati ve rate. The false positiv e rate is mea- sured empirically over a sample of 50 , 000 queries for the learned models; for the Bloom Filter we employ the ana- lytical false positiv e rate. Beating a Bloom Filter’ s space usage with the analytical false positiv e rate implies better performance for any gi ven Bloom Filter library v ersion (as actual Bloom Filter hash functions are not uniform), thus the comparison is reasonable. For each model we sweep ov er hyper-parameters relating to model size to obtain their smallest operating size at the desired false positiv e rate (for the full set, see Appendix D ). Because the neural models can emit false ne gati ves, we store these in a (ideally small) backup Bloom Filter , as proposed by Kraska et al. ( 2018 ); Mitzenmacher ( 2018a ). W e account for the space of this backup Bloom Filter, and add it to the space usage of the model’ s memory for parity (See Appendix B for further dis- cussion). The neural netw ork must learn to output a small state in one-shot that can serve set membership queries at a giv en false positi ve rate, and emit a small enough number of false negati ves such that the backup filter is also small, and the total size is considerably less than a Bloom Filter . 5.2. Sampling Strategies on MNIST T o understand what kinds of scenarios neural networks may be more (or less) compressi ve than classical Bloom Filters, we consider three simple set membership tasks that have a graded lev el of structure to the storage sets and queries. Concretely , they dif fer in the sampling distribution of stor- age sets S train and queries Q train . Ho we ver all problems are approximate set membership tasks that can be solved by a Bloom Filter . The tasks are (1) Class-based familiarity , a highly structured task where each set of images is sampled with the constraint that they arise from the same randomly- selected class. (2) Non-uniform instance-based familiarity , a moderately structured task where the images are sam- pled without replacement from an exponential distrib ution. (3) Uniform instance-based familiarity , a completely un- structured task where each subset contains images sampled uniformly without replacement. For each task we v aried the size of the sample set to store, and calculated the space (in bits) of each model’ s state at a fixed false positi ve rate of 1% and a false negati ve rate of 0% . W e used relatively small storage set sizes (e.g. 100 − 1000 ) to start with, as this highlights that some RNN-based approaches struggle to train ov er larger set sizes, before progressing to lar ger sets in subsequent sections. See Appendix E for further details on the task setup. In the class-based sampling task we see in Figure 2 a that the DNC, LSTM and Neural Bloom Filter are Meta-Learning Neural Bloom Filters Addr ess Memor y Contents (a) (b) (c) Full Model Constant write words: Figure 3. Memory access analysis. Three different learned solutions to class-based familiarity . W e train three Neural Bloom Filter variants, with a succession of simplified read and write mechanisms. Each model contains 10 memory slots and the memory addressing weights a and contents ¯ M are visualised, broken down by class. Solutions share broad correspondence to known algorithms: (a) Bloom-g filters, (b) Bloom Filters, (c) Perfect hashing. able to significantly outperform the classical Bloom Filter when images are sampled by class. The Memory Network is able to solve the task with a word size of only 2 , howe ver this corresponds to a far greater number of bits per element, 64 versus the Bloom Filter’ s 9 . 8 (to a total size of 4 . 8 kb), and so the ov erall size was prohibiti ve. The DNC, LSTM, and Neural Bloom Filter are able to solve the task with a storage set size of 500 at 1 . 1 kb , 217 b, and 382 b; a 4 . 3 × , 22 × , and 12 × saving respectiv ely . For the non-uniform sampling task in Figure 2 b we see the Bloom Filter is prefer - able for less than 500 stored elements, b ut is ov ertaken thereafter . At 1000 elements the DNC, LSTM, and Neural Bloom Filter consume 7 . 9 kb, 7 . 7 kb, and 6 . 8 kb respectiv ely which corresponds to a 17 . 6% , 19 . 7% , and 28 . 6% reduction ov er the 9 . 6 kb Bloom Filter . In the uniform sampling task shown in Figure 2 c, there is no structure to the sampling of S . The two architectures which rely on BPTT essentially fail to solv e the task at some threshold of storage size. The Neural Bloom Filter solv es it with 6 . 8 kb (using a memory size of 50 and word size of 2 ). The ov erall conclusion from these sets of e xperiments is that the classical Bloom Filter works best when there is no structure to the data, ho wev er when there is (e.g. skewed data, or highly dependent sets that share common attributes) we do see significant space savings. 5.3. Memory Access Analysis W e wanted to understand how the Neural Bloom Filter uses its memory , and in particular how its learned solutions may correspond to classical algorithms. W e inspected the mem- ory contents (what w as stored to memory) and addressing weights (where it was stored) for a small model of 10 mem- ory slots and a word size of 2 , trained on the MNIST class- based familiarity task. W e plot this for each class label, and compare the pattern of memory usage to tw o other models that use increasingly simpler read and write operations: (1) an ablated model with constant write words w ← 1 , and (2) an ablated model with w ← 1 and a linear read operator r ← a T M . The full model, shown in Figure 3 a learns to place some classes in particular slots, e.g. class 1 → slot 5 , howev er most are distrib uted. Inspecting the memory contents, it is clear the write word encodes a unique 2 D token for each class. This solution bears resemblance with Bloom-g Fil- ters ( Qiao et al. , 2011 ) where elements are spread across a smaller memory with the same hashing scheme as Bloom Filters, but a unique token is stored in each slot instead of a constant 1 -bit value. W ith the model ablated to store only 1 s in Figure 3 b we see it uses semantic addressing codes for some classes (e.g. 0 and 1 ) and distributed addresses for other classes. E.g. for class 3 the model prefers to uniformly spread its writes across memory slot 1 , 4 , and 8 . The model solution is similar to that of Bloom Filters, with distributed addressing codes as a solution — but no information in the written words themselv es. When we force the read op- eration to be linear in Figure 3 c, the network maps each input class to a unique slot in memory . This solution has a correspondence with perfect hashing. In conclusion, with small changes to the read/write operations we see the Neural Bloom Filter learn different algorithmic solutions. 5.4. Database Queries W e look at a task inspired by database interactions. NoSQL databases, such as Bigtable and Cassandra, use a single string-valued ro w-key , which is used to index the data. The Meta-Learning Neural Bloom Filters 5% 1% 0.1% Neural Bloom Filter 871b 1.5kb 24.5kb Bloom Filter 31.2kb 47.9kb 72.2kb Cuckoo Filter 33.1kb 45.3kb 62.6kb T able 1. Database task . Storing 5000 row-k ey strings for a target false positi ve rate. database is comprised of a union of files (e.g. SST ables) stor- ing contiguous ro w-key chunks. Bloom Filters are used to determine whether a given query q lies within the stored set. W e emulate this setup by constructing a universe of strings, that is alphabetically ordered, and by sampling contiguous ranges (to represent a giv en SST able). Queries are sampled uniformly from the univ erse set of strings. W e choose the 2 . 5 M unique tokens in the GigaW ord v5 news corpus to be our uni verse as this consists of structured natural data and some noisy or irregular strings. W e consider the task of storing sorted string sets of size 5000 . W e train the Neural Bloom Filter to several desired false positiv e rates ( 5% , 1% , 0 . 1% ) and used a backup Bloom Filter to guarantee 0% false ne gati ve rate. W e also trained LSTMs and DNCs for comparison, b ut they f ailed to learn a solution to the task after sev eral days of training; optimizing insertions via BPTT ov er a sequence of length 5000 did not result in a remotely usable solution. The Neural Bloom Filter av oids BPTT via its simple additiv e write scheme, and so it learned to solve the task quite naturally . As such, we compare the Neural Bloom Filter solely to classical data structures: Bloom Filters and Cuckoo Filters. In T able 1 we see a significant space reduction of 3 − 40 × , where the margin grows with increasing permitted false positiv e rates. Since memory is an expensi ve component within production databases (in contrast to disk, say), this memory space saving could translate to a non-tri vial cost reduction. W e note that a storage size of 5000 may appear small, but is relevant to the NOSQL database scenario where disk files (e.g. SST ables) are typically sharded to be several megabytes in size, to avoid issues with compaction. E.g. if the stored values were of size 10 kB per row , we would expect 5000 unique keys or less in an a verage Bigtable SST able. One further consideration for production deployment is the ability to extrapolate to larger storage set sizes during e valu- ation. W e in vestigate this for the Neural Bloom Filter on the same database task, and compare it to an LSTM. T o ensure both models train, we set the maximum training storage set size to 200 and ev aluate up to sizes 250 , a modest 25% size increase. W e find that the Neural Bloom Filter uses up to 3 × less space than the LSTM and the neural models are able to extrapolate to lar ger set sizes than those observed during training (see Appendix F Figure 4 ). Whilst the performance ev entually degrades when the training limit size is e xceeded, it is not catastrophic for either the LSTM or Neural Bloom Filter . 5.5. Timing benchmark W e hav e principally focused on space comparisons in this paper , we now consider speed for the database task de- scribed in the prior section. W e measure latency as the wall-clock time to complete a single insertion or query of a row-k ey string of length 64 . W e also measure throughput as the reciprocal wall-clock time of inserting or querying 10 , 000 strings. W e use a common encoder architecture for the neural models, a 128-hidden-unit character LSTM. W e benchmark the models on the CPU (Intel(R) Xeon(R) CPU E5-1650 v2 @ 3.50GHz) and on the GPU (NVIDIA Quadro P6000) with models implemented in T ensorFlow without any model-specific optimizations. W e compare to empir- ical timing results published in a query-optimized Bloom Filter variant ( Chen et al. , 2007 ). W e include the Learned Index from ( Kraska et al. , 2018 ) to contrast timings with a model that is not one-shot. The architecture is simply the LSTM character encoder; inserts are performed via gradient descent. The number of gradient-descent steps to obtain con vergence is domain-dependent, we chose 50 steps in our timing benchmarks. The Learned Index queries are obtained by running the character LSTM ov er the input and classify- ing familiarity — and thus query metrics are identical to the LSTM baseline. W e see in T able 2 . that the combined query and insert latency of the Neural Bloom Filter and LSTM sits at 5 ms on the CPU, around 400 × slower than the classical Bloom Filter . The Learned Inde x contains a much lar ger latency of 780 ms due to the sequential application of gradients. For all neural models, latency is not improved when operations are run on the GPU. Ho we ver when multiple queries are recei ved, the throughput of GPU-based neural models surpasses the classical Bloom Filter due to ef ficient concurrency of the dense linear algebra operations. This leads to the conclusion that a Neural Bloom Filter could be deployed in scenar- ios with high query load without a catastrophic decrease in throughput, if GPU devices are a vailable. For insertions we see a bigger separation between the one-shot models: the LSTM and Neural Bloom Filter . Whilst all neural models are uncompetitiv e on the CPU, the Neural Bloom Filter sur- passes the Bloom Filter’ s insertion throughput when placed on the GPU, with 101 K insertions per second (IPS). The LSTM runs at 4 . 6 K IPS, one order of magnitude slower , because writes are serial, and the Learned Index structure is two orders of magnitude slo wer at 816 IPS due to sequential gradient computations. The benefits of the Neural Bloom Filter’ s simple write scheme are apparent here. Meta-Learning Neural Bloom Filters Query + Insert Latency Query Throughput (QPS) Insert Throughput (IPS) CPU GPU CPU GPU CPU GPU Bloom Filter* 0.02ms - 61K - 61K - Neural Bloom Filter 5.1ms 13ms 3.5K 105K 3.2K 101K LSTM 5.0ms 13ms 3.1K 107K 2.4K 4.6K Learned Index ( Kraska et al. , 2018 ) 780ms 1.36s 3.1K 107K 25 816 T able 2. Latency for a single query , and throughput for a batch of 10,000 queries. *Query-efficient Bloom Filter from Chen et al. ( 2007 ). 6. Related W ork There have been a large number of Bloom Filter v ariants published; from Counting Bloom Filter s which support dele- tions ( Fan et al. , 2000 ), Bloomier F ilters which store func- tions vs sets ( Chazelle et al. , 2004 ), Compressed Bloom F ilters which use arithmetic encoding to compress the stor- age set ( Mitzenmacher , 2002 ), and Cuckoo Filter s which use cuckoo hashing to reduce redundancy within the storage vector ( F an et al. , 2014 ). Although some of these v ariants focus on better compression, they do not achiev e this by specializing to the data distribution. One of the few w orks which address data-dependence are W eighted Bloom F ilters ( Bruck et al. , 2006 ; W ang et al. , 2015 ). They w ork by modulating the number of hash func- tions used to store or query each input, dependent on its stor - age and query frequency . This requires estimating a large number of separate storage and query frequencies. This approach can be useful for imbalanced data distributions, such as the non-uniform instance-based MNIST familiar - ity task. Ho we ver it cannot take adv antage of dependent sets, such as the class-based MNIST familiarity task, or the database query task. W e see the Neural Bloom Filter is more compressiv e in all settings. Sterne ( 2012 ) proposes a neurally-inspired set membership data-structure that works by replacing the randomized hash functions with a randomly-wired computation graph of OR and AND gates. The false positiv e rate is controlled analyt- ically by modulating the number of gates and the overall memory size. Howe ver there is no learning or specialization to the data with this setup. Bogacz & Brown ( 2003 ) in vesti- gates a learnable neural familiarity module, which serves as a biologically plausible model of familiarity mechanisms in the brain, namely within the perirhinal cortex. Howe ver this has not shown to be empirically ef fectiv e at exact matching. Kraska et al. ( 2018 ) consider the use of a neural network to classify the membership of queries to a fixed set S . Here the network itself is more akin to a perfect hashing setup where multiple epochs are required to find a succinct holis- tic representation of the set, which is embedded into the weights of the network. In their case this search is per- formed by gradient-based optimization. W e emulate their experimental comparison approach but instead propose a memory architecture that represents the set as activ ations in memory , versus weights in a network. Mitzenmacher ( 2018a ) discusses the benefits and draw- backs of a learned Bloom Filter; distinguishing the empirical false positi ve rate o ver the distribution of sets S versus the conditional false positi ve rate of the model gi ven a particular set S . In this paper we focus on the empirical false positiv e rate because we wish to exploit redundancy in the data and query distribution. Mitzenmacher ( 2018b ) also considers an alternate way to combine classical and learned Bloom Fil- ters by ‘sandwiching’ the learned model with pre-filter and post-filter classical Bloom Filters to further reduce space. 7. Conclusion In many situations neural networks are not a suitable replace- ment to Bloom Filters and their variants. The Bloom Filter is robust to changes in data distrib ution because it deli vers a bounded false positi ve rate for an y sampled subset. Ho w- ev er in this paper we consider the questions, “When might a single-shot neural network provide better compression than a Bloom Filter?”. W e see that a model which uses an external memory with an adaptable capacity , avoids BPTT with a feed-forward write scheme, and learns to address its memory , is the most promising option in contrast to popular memory models such as DNCs and LSTMs. W e term this model the Neural Bloom Filter due to the analogous incor- poration of a hashing scheme, commutati ve write scheme, and multiplicativ e read mechanism. The Neural Bloom Filter relies on settings where we ha ve an of f-line dataset (both of stored elements and queries) that we can meta-learn o ver . In the case of a large database we think this is warranted, a database with 100 K separate set membership data structures will benefit from a single (or periodic) meta-learning training routine that can run on a single machine and sample from the currently stored data, generating a large number of ef ficient data-structures. W e en visage the space cost of the network to be amortized by sharing it across man y neural Bloom Filters, and the time- cost of executing the network to be of fset by the continuous acceleration of dense linear algebra on modern hardware, and the ability to batch writes and queries ef ficiently . A promising future direction would be to in vestig ate the feasi- bility of this approach in a production system. Meta-Learning Neural Bloom Filters Acknowledgments W e thank Peter Dayan, Y ori Zwols, Y an W u, Joel Leibo, Greg W ayne, Andras Gyorgy , Charles Blundell, Daan W eirstra, Pushmeet K ohli, and T or Lattimor for their in- sights during this project. References Adams, K. The life of a typeahead query , 2010. URL https://www.facebook.com/Engineering/ videos/432864835468/ . [Online, accessed 01-August-2018]. Bar-Y ossef, Z., Jayram, T . S., Kumar , R., and Si v akumar , D. An information statistics approach to data stream and communication complexity . Journal of Computer and System Sciences , 68(4):702–732, 2004. Bloom, B. H. Space/time trade-offs in hash coding with allow able errors. Communications of the A CM , 13(7): 422–426, 1970. Bogacz, R. and Brown, M. W . Comparison of computational models of familiarity discrimination in the perirhinal cor- tex. Hippocampus , 13(4):494–524, 2003. Bruck, J., Gao, J., and Jiang, A. W eighted bloom filter . In Information Theory , 2006 IEEE International Symposium on , pp. 2304–2308. IEEE, 2006. Carter , L., Floyd, R., Gill, J., Marko wsky , G., and W egman, M. Exact and approximate membership testers. In Pr o- ceedings of the tenth annual ACM symposium on Theory of computing , pp. 59–65. A CM, 1978. Chandar , S., Ahn, S., Larochelle, H., V incent, P ., T esauro, G., and Bengio, Y . Hierarchical memory networks. arXiv pr eprint arXiv:1605.07427 , 2016. Chang, F ., Dean, J., Ghemaw at, S., Hsieh, W . C., W allach, D. A., Burro ws, M., Chandra, T ., Fikes, A., and Gruber , R. E. Bigtable: A distributed storage system for structured data. A CM T ransactions on Computer Systems (TOCS) , 26(2):4, 2008. Chazelle, B., Kilian, J., Rubinfeld, R., and T al, A. The bloomier filter: an efficient data structure for static sup- port lookup tables. In Pr oceedings of the fifteenth an- nual A CM-SIAM symposium on Discr ete algorithms , pp. 30–39. Society for Industrial and Applied Mathematics, 2004. Chen, Y ., Kumar , A., and Xu, J. J. A ne w design of bloom filter for packet inspection speedup. In Global T elecom- munications Confer ence, 2007. GLOBECOM’07. IEEE , pp. 1–5. IEEE, 2007. Cummins, C., Petoumenos, P ., W ang, Z., and Leather , H. End-to-end deep learning of optimization heuristics. In P arallel Ar chitectur es and Compilation T echniques (P A CT), 2017 26th International Conference on , pp. 219– 232. IEEE, 2017. Datar , M., Immorlica, N., Indyk, P ., and Mirrokni, V . S. Locality-sensitiv e hashing scheme based on p-stable dis- tributions. In Pr oceedings of the twentieth annual sym- posium on Computational geometry , pp. 253–262. ACM, 2004. Dietzfelbinger , M. and Pagh, R. Succinct data structures for retriev al and approximate membership. In International Colloquium on Automata, Languag es, and Pr ogramming , pp. 385–396. Springer , 2008. Dillinger , P . C. and Manolios, P . Bloom filters in proba- bilistic verification. In International Conference on F or- mal Methods in Computer-Aided Design , pp. 367–381. Springer , 2004. Fan, B., Andersen, D. G., Kaminsk y , M., and Mitzenmacher , M. D. Cuckoo filter: Practically better than bloom. In Pr o- ceedings of the 10th ACM International on Confer ence on emer ging Networking Experiments and T echnologies , pp. 75–88. A CM, 2014. Fan, L., Cao, P ., Almeida, J., and Broder , A. Z. Summary cache: a scalable wide-area web cache sharing protocol. IEEE/A CM T ransactions on Networking (TON) , 8(3):281– 293, 2000. Gerav and, S. and Ahmadi, M. Bloom filter applications in network security: A state-of-the-art survey . Computer Networks , 57(18):4047–4064, 2013. Grav es, A., W ayne, G., and Danihelka, I. Neural turing machines. arXiv pr eprint arXiv:1410.5401 , 2014. Grav es, A., W ayne, G., Reynolds, M., Harle y , T ., Dani- helka, I., Grabska-Barwi ´ nska, A., Colmenarejo, S. G., Grefenstette, E., Ramalho, T ., Agapiou, J., et al. Hybrid computing using a neural network with dynamic external memory . Natur e , 538(7626):471, 2016. Hearn, M. and Corallo, M. BIPS: Connection Bloom filter- ing, 2012. URL https://github.com/bitcoin/ bips/blob/master/bip- 0037.mediawiki . [Online; accessed 01-August-2018]. Jouppi, N. P ., Y oung, C., Patil, N., Patterson, D., Agraw al, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., et al. In-datacenter performance analysis of a tensor processing unit. In Computer Ar chitectur e (ISCA), 2017 A CM/IEEE 44th Annual International Symposium on , pp. 1–12. IEEE, 2017. Meta-Learning Neural Bloom Filters Kaiser , Ł ., Nachum, O., Roy , A., and Bengio, S. Learning to remember rare ev ents. In International Conference on Learning Repr esentations , 2017. Kraska, T ., Beutel, A., Chi, E. H., Dean, J., and Polyzotis, N. The case for learned index structures. In Pr oceedings of the 2018 International Confer ence on Manag ement of Data , pp. 489–504. A CM, 2018. Mirhoseini, A., Pham, H., Le, Q. V ., Steiner , B., Larsen, R., Zhou, Y ., Kumar , N., Norouzi, M., Bengio, S., and Dean, J. Device placement optimization with reinforcement learning. In Pr oceedings of the 34th International Confer- ence on Machine Learning , v olume 70, pp. 2430–2439. PMLR, 2017. Mitzenmacher , M. Compressed bloom filters. IEEE/ACM T ransactions on Networking (TON) , 10(5):604–612, 2002. Mitzenmacher , M. A model for learned bloom filters and re- lated structures. arXiv pr eprint arXiv:1802.00884 , 2018a. Mitzenmacher , M. Optimizing learned bloom filters by sandwiching. arXiv pr eprint arXiv:1803.01474 , 2018b. Muthukrishnan, S. et al. Data streams: Algorithms and appli- cations. F oundations and T rends in Theor etical Computer Science , 1(2):117–236, 2005. Qiao, Y ., Li, T ., and Chen, S. One memory access bloom filters and their generalization. In INFOCOM, 2011 Pro- ceedings IEEE , pp. 1745–1753. IEEE, 2011. Rae, J. W ., Hunt, J. J., Danihelka, I., Harley , T ., Senior , A. W ., W ayne, G., Gra ves, A., and Lillicrap, T . P . Scaling memory-augmented neural networks with sparse reads and writes. In Advances in Neural Information Processing Systems , pp. 3621–3629, 2016. Santoro, A., Bartunov , S., Botvinick, M., W ierstra, D., and Lillicrap, T . Meta-learning with memory-augmented neu- ral networks. In Pr oceedings of the 33rd International Confer ence on Machine Learning , pp. 1842–1850, 2016. Shazeer , N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer . arXiv pr eprint arXiv:1701.06538 , 2017. Sterne, P . Efficient and rob ust associativ e memory from a generalized bloom filter . Biological cybernetics , 106 (4-5):271–281, 2012. Sukhbaatar , S., Szlam, A., W eston, J., and Fergus, R. End- to-end memory networks. In Pr oceedings of the 28th International Confer ence on Neural Information Pr ocess- ing Systems-V olume 2 , pp. 2440–2448. MIT Press, 2015. V inyals, O., Blundell, C., Lillicrap, T ., Kavukcuoglu, K., and Wierstra, D. Matching networks for one shot learning. In Pr oceedings of the 30th International Confer ence on Neural Information Pr ocessing Systems , pp. 3637–3645. Curran Associates Inc., 2016. W ang, X., Ji, Y ., Dang, Z., Zheng, X., and Zhao, B. Im- prov ed weighted bloom filter and space lo wer bound anal- ysis of algorithms for approximated membership query- ing. In International Conference on Database Systems for Advanced Applications , pp. 346–362. Springer , 2015. W u, Y ., W ayne, G., Gra ves, A., and Lillicrap, T . The kanerv a machine: A generativ e distributed memory . In Interna- tional Confer ence on Learning Repr esentations , 2018a. W u, Y ., W ayne, G., Gregor , K., and Lillicrap, T . Learning attractor dynamics for generative memory . In Advances in Neural Information Pr ocessing Systems , pp. 9401–9410, 2018b. Y ao, A. C.-C. Some complexity questions related to dis- tributi ve computing (preliminary report). In Pr oceedings of the eleventh annual A CM symposium on Theory of computing , pp. 209–213. A CM, 1979. Meta-Learning Neural Bloom Filters A. Further Model Details A.1. Efficient addressing W e discuss some implementation tricks that could be em- ployed for a production system. Firstly the original model description defines the addressing matrix A to be trainable. This ties the number of parameters in the network to the memory size. It may be preferable to train the model at a giv en memory size and ev aluate for larger memory sizes. One way to achiev e this is by allowing the addressing matrix A to be non-trainable. W e experiment with this, allowing A ∼ N ( 0 , I ) to be a fixed sample of Gaussian random variables. W e can think of these as point on a sphere in high dimensional space, the controller network must learn to org anize inputs into separate buckets across the surface of the sphere. T o make the addressing more efficient for larger memory sizes, we experiment with sparsification of the addressing softmax by preserving only the top k components. W e denote this sparse softmax σ k ( · ) . When using a sparse address, we find the network can fixate on a subset of rows. This observ ation is common to prior sparse addressing work ( Shazeer et al. , 2017 ). W e find sphering the query vector , often dubbed whitening, remedies this (see Appendix G for an ablation). The modified sparse architecture variant is illustrated in Algorithm 3 . Algorithm 3 Sparse Neural Bloom Filter 1: def sparse controller(x): 2: z ← f enc ( x ) 3: s ← f q ( z ) // Raw query word 4: q ← mov ing z ca ( q ) // Spherical query 5: a ← σ k ( q T A ) // Sparse address 6: w ← f w ( z ) 7: def sparse write(x): 8: a, w ← sparse controller ( x ) 9: M t +1 [ a idx ] ← M t [ a idx ] + w a T v al 10: def sparse read(x): 11: a, w , z ← sparse controller ( x ) 12: r ← M [ a idx ] a v al 13: o ← f out ([ r , w , z ]) One can av oid the linear-time distance computation q T A in the addressing operation σ k ( q T A ) by using an approximate k-nearest neighbour index, such as locality-sensitiv e hashing ( Datar et al. , 2004 ), to e xtract the nearest neighbours from A in O (log m ) time. The use of an approximate nearest neighbour index has been empirically considered for scal- ing memory-augmented neural networks ( Rae et al. , 2016 ; Kaiser et al. , 2017 ) ho wev er this was used for attention on M directly . As M is dynamic the knn requires frequent re-building as memories are stored or modified. This archi- tecture is simpler — A is fixed and so the approximate knn can be built once. T o ensure the serialized size of the network (which can be shared across many memory instantiations) is independent of the number of slots in memory m we can av oid storing A . In the instance that it is not trainable, and is simply a fixed sample of random v ariables that are generated from a deterministic random number generator — we can instead store a set of integer seeds that can be used to re-generate the ro ws of A . W e can let the i -th seed c i , say represented as a 16-bit integer , correspond to the set of 16 rows with indices 16 i, 16 i + 1 , . . . , 16 i + 15 . If these rows need to be accessed, they can be regenerated on-the-fly by c i . The total memory cost of A is thus m bits, where m is the number of memory slots 3 . Putting these two together it is possible to query and write to a Neural Bloom Filter with m memory slots in O (log m ) time, where the network consumes O (1) space. It is worth noting, howe ver , the Neural Bloom Filter’ s memory is of- ten much smaller than the corresponding classical Bloom Filter’ s memory , and in many of our experiments is ev en smaller than the number of unique elements to store. Thus dense matrix multiplication can still be preferable - espe- cially due to its acceleration on GPUs and TPUs ( Jouppi et al. , 2017 ) - and a dense representation of A is not in- hibitory . As model optimization can become application- specific, we do not focus on these implementation details and use the model in its simplest setting with dense matrix operations. A.2. Moving ZCA The mo ving ZCA w as computed by taking moving averages of the first and second moment, calculating the ZCA matrix and updating a mo ving a verage projection matrix θ z ca . This is only done during training, at ev aluation time θ z ca is fixed. W e describe the update below for completeness. Input: s ← f q ( z ) (1) µ t +1 ← γ µ t + (1 − γ )¯ s 1st moment EMA (2) Σ t +1 ← γ Σ t + (1 − γ ) s T s 2nd moment EMA (3) U, s, ← svd (Σ − µ 2 ) Singular values (4) W ← U U T / p ( s ) ZCA matrix (5) θ z ca ← η θ z ca + (1 − η ) W ZCA EMA (6) q ← s θ z ca Projected query (7) In practice we do not compute the singular value decompo- sition at each time step to save computational resources, b ut 3 One can replace 16 with 32 if there are more than one million slots Meta-Learning Neural Bloom Filters instead calculate it and update θ e very T steps. W e scale the discount in this case η 0 = η /T . A.3. Relation to uniform hashing W e can think of the decorrelation of s , along with the sparse content-based attention with A , as a hash function that maps s to several indices in M . For moderate dimension sizes of s ( 256 , say) we note that the Gaussian samples in A lie close to the surface of a sphere, uniformly scattered across it. If q , the decorrelated query , were to be Gaussian then the marginal distribution of nearest neighbours ro ws in A will be uniform. If we chose the number of nearest neighbours k = 1 then this implies the slots in M are selected independently with uniform probability . This is the exact hash function specification that Bloom Filters assume. Instead we use a continuous (as we choose k > 1 ) approximation (as we decorrelate s → q vs Gaussianize) to this uniform hashing scheme, so it is differentiable and the network can learn to shape query representations. B. Space Comparison For each task we compare the model’ s memory size, in bits, at a given false positi ve rate — usually chosen to be 1% . For our neural networks which output a probability p = f ( x ) one could select an operating point τ such that the false positi ve rate is . In all of our e xperiments the neural network outputs a memory (state) s which characterizes the storage set. Let us say SPACE(f, ) is the minimum size of s , in bits, for the network to achiev e an average false positiv e rate of . W e could compare SPACE(f, ) with SPACE(Bloom Filter, ) directly , but this would not be a fair comparison as our network f can emit false negati ves. T o remedy this, we employ the same scheme as Kraska et al. ( 2018 ) where we use a ‘backup’ Bloom Filter with false positi ve rate δ to store all false neg ativ es. When f ( x ) < τ we query the backup Bloom Filter . Because the overall false positiv e rate is + (1 − ) δ , to achieve a false positive rate of at most α (say 1% ) we can set = δ = α/ 2 . The number of elements stored in the backup bloom filter is equal to the number of false neg- ativ es, denoted n f n . Thus the total space can be calcu- lated, TOTAL SPACE(f, α ) = SPACE(f, α 2 ) + n f n * SPACE(Bloom Filter, α 2 ) . W e compare this quan- tity for different storage set sizes. C. Model Size For the MNIST experiments we used a 3 -layer con volutional neural network with 64 filters followed by a two-layer feed- forward network with 64&128 hidden-layers respectively . The number of trainable parameters in the Neural Bloom Filter (including the encoder) is 243 , 437 which amounts to 7 . 8 Mb at 32 -bit precision. W e did not optimize the encoder architecture to be lean, as we consider it part of the library in a sense. For e xample, we do not count the size of the hashing library that an implemented Bloom Filter relies on, which may have a chain of dependencies, or the package size of T ensorFlow used for our experiments. Nev ertheless we can reason that when the Neural Bloom Filter is 4 kb smaller than the classical, such as for the non-uniform instance- based familiarity in Figure 2 b, we would expect to see a net gain if we ha ve a collection of at least 1 , 950 data-structures. W e imagine this could be optimized quite significantly , by using 16 -bit precision and perhaps using more con volution layers or smaller feed-forward linear operations. For the database experiments we used an LSTM character encoder with 256 hidden units followed by another 256 feed-forward layer . The number of trainable parameters in the Neural Bloom Filter 419 , 339 which amounts to 13 Mb . One could imagine optimizing this by switching to a GR U or in vestigating temporal con volutions as encoders. D. Hyper -Parameters W e swept ov er the following hyper-parameters, ov er the range of memory sizes displayed for each task. W e com- puted the best model parameters by selecting those which resulted in a model consuming the least space as defined in Appendix B . This depends on model performance as well as state size. The Memory Networks memory size was fixed to equal the input size (as the model does not arbitrate what inputs to av oid writing). Memory Size (DNC, NBF) { 2, 4, 8, 16, 32, 64 } W ord Size (MemNets, DNC, NBF) { 2, 4, 6, 8, 10 } Hidden Size (LSTM) { 2, 4, 8, 16, 32, 64 } Sphering Decay η (NBF) { 0.9, 0.95, 0.99 } Learning Rate (all) { 1e-4, 5e-5 } T able 3. Hyper-parameters considered E. Experiment Details For the class-based f amiliarity task, and uniform sampling task, the model was trained on the training set and ev aluated on the test set. For the class-based task sampling, a class is sampled at random and S is formed from a random subset of images from that class. The queries q are chosen uniformly from either S or from images of a dif ferent class. For the non-uniform instance-based familiarity task we sam- pled images from an e xponential distribution. Specifically we used a fix permutation of the training images, and from that ordering chose p ( i th image ) ∝ 0 . 999 i for the images to store. The query images were selected uniformly . W e used Meta-Learning Neural Bloom Filters Figure 4. Database extrapolation task . Models are trained up to sets of size 200 (dashed line). W e see extrapolation to larger set sizes on test set, but performance de grades. Neural architectures perform best for larger allo wed false positi ve rates. a fix ed permutation (or shuf fle) of the images to ensure most probability mass was not placed on images of a certain class. I.e. by the natural ordering of the dataset we would hav e otherwise almost always sampled 0 images. This would be confounding task non-uniformity for other latent structure to the sets. Because the network needed to relate the im- age to its frequency of occurence for task, the models were ev aluated on the training set. This is reasonable as we are not wishing for the model to visually generalize to unseen elements in the setting of this e xact-familiarity task. W e specifically want the network weights to compress a map of image to probability of storage. For the database task a univ erse of 2 . 5 M unique tokens were extracted from Gig aW ord v5. W e shuffled the tok ens and placed 2 . 3 M in a training set and 250 K in a test set. These sets were then sorted alphabetically . A random sub- set, representing an SST able, was sampled by choosing a random start inde x and selecting the ne xt n elements, which form our set S . Queries are sampled uniformly at random from the univ erse set. Models are trained on the training set and ev aluated on the test set. F . Database Extrapolation T ask W e in vestigate whether neural models are able to extrapolate to larger test sizes. Using the database task setup, where each set contains a contiguous set of sorted strings; we train both the Neural Bloom Filter and LSTM on sets of sizes 2 - 200. W e then ev aluate on sets up to 250, i.e. a 25% increase ov er what is observed during training. This is to emulate the scenario that we train on a selection of databse tablets, but during e valuation we may observe some tablets that are slightly larger than those in the training set. Both the LSTM and Neural Bloom Filter are able to solve the task, with the Neural Bloom Filter using significantly less space for the larger allowed false positive rate of 5% and 1%. W e do see the models’ error increase as it surpasses the maximum training set size, howev er it is not catastrophic. Another interesting trend is noticeable; the neural models hav e higher utility for larger allowed false positiv e rates. This may be because of the difficulty in training the models to an extremely lo w accuracy . G. Effect of Sphering W e see the benefit of sphering in Figure 5 where the con- ver ged validation performance ends up at a higher state. In vestig ating the proportion of memory filled after all ele- ments hav e been written in Figure 6 , we see the model uses quite a small proportion of its memory slots. This is likely due to the network fixating on ro ws it has accessed with sparse addressing, and ignoring rows it has otherwise nev er touched — a phenomena noted in Shazeer et al. ( 2017 ). The model finds a local minima in continually storing and accessing the same rows in memory . The effect of sphering is that the query now appears to be Gaussian (up to the first two moments) and so the nearest neighbour in the address matrix A (which is initialized to Gaussian random v ariables) will be close to uniform. This results in a more uniform memory access (as seen in Figure 6 ) which significantly aids performance (as seen in Figure 5 ). 0 200000 400000 600000 800000 Training Steps 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Validation AUC Sphering enabled Sphering disabled Figure 5. For sparse addresses, sphering enables the model to learn the task of set membership to high accuracy . H. Timing Benchmark W e use the Neural Bloom Filter netw ork architecture for the large database task (T able 1 ). The network uses an encoder LSTM with 256 hidden units over the characters, and feeds Meta-Learning Neural Bloom Filters 0 200000 400000 600000 800000 Training Steps 15 20 25 30 35 40 45 50 % Memory used Sphering enabled Sphering disabled Figure 6. For sparse addresses, sphering the query v ector leads to fewer collisions across memory slots and thus a higher utilization of memory . this through a 256 fully connected layer to encode the input. A two-layer 256 -hidden-unit MLP is used as the query archi- tecture. The memory and word size is 8 and 4 respectiv ely , and so the majority of the compute is spent in the encoder and query network. W e compare this with an LSTM con- taining 32 hidden units. W e benchmark the single-query latency of the netw ork alongside the throughput of a batch of queries, and a batch of inserts. The Neural Bloom Filter and LSTM is implemented in T ensorFlow without an y cus- tom kernels or specialized code. W e benchmark it on the CPU (Intel(R) Xeon(R) CPU E5-1650 v2 @ 3.50GHz) and a GPU (NVIDIA Quadro P6000). W e compare to empirical timing results published in a query-optimized Bloom Filter variant ( Chen et al. , 2007 ). It is worth noting, in se veral Bloom Filter applications, the actual query latency is not in the critical path of computation. For e xample, for a distributed database, the network latency and disk access latency for one tablet can be orders of mag- nitude greater than the in-memory latency of a Bloom Filter query . For this reason, we ha ve not made run-time a point of focus in this study , and it is implicitly assumed that the neural network is trading of f greater latency for less space. Howe ver it is worth checking whether run-time could be prohibitiv e.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment