다중모달 활성학습을 위한 강화학습 기반 사용자 참여 추정
본 논문은 인간-컴퓨터·로봇 상호작용에서 사용자의 참여 수준을 추정하기 위해, 다중모달 데이터를 효율적으로 라벨링하는 활성학습(Active Learning) 프레임워크를 제안한다. 딥 강화학습(RL)을 이용해 라벨 요청 여부를 결정하는 정책을 학습하고, 모델‑레벨 융합을 통해 각 모달리티(LSTM 기반)별 분류기의 출력을 결합한다. 실제 자폐 아동‑로봇 치료 데이터에 적용해, 기존 불확실성 기반 샘플링보다 적은 라벨로 높은 정확도와 개인화된 참…
저자: Ognjen Rudovic, Meiru Zhang, Bjorn Schuller
**1. 연구 배경 및 필요성**
인간의 행동은 시각·청각·생리·제스처 등 다양한 모달리티를 통해 표현되며, 특히 인간‑컴퓨터(HCI)·인간‑로봇(HRI) 상호작용에서는 사용자의 참여도(engagement)를 정확히 파악하는 것이 핵심 과제이다. 기존 다중모달 참여 추정 연구는 주로 완전 라벨링된 데이터를 전제로 하여, 각 모달리티별 특징을 결합하거나 모델‑레벨 융합을 수행한다. 그러나 라벨링은 시간·노력·주관성 측면에서 비용이 크고, 특히 자폐 아동과 같은 특수 집단에서는 전문가 라벨링이 더욱 어려워진다. 또한, 사용자마다 표현 방식이 크게 다르기 때문에 “one‑size‑fits‑all” 모델은 일반화에 한계를 보인다. 따라서 라벨링 비용을 최소화하면서도 개인화된 다중모달 모델을 구축할 수 있는 방법이 요구된다.
**2. 제안 방법 개요**
본 논문은 두 가지 핵심 요소를 결합한 새로운 프레임워크를 제시한다.
- **다중모달 활성학습(Active Learning, AL)**: 라벨을 요청할 데이터 샘플을 선택하는 정책을 강화학습(RL)으로 학습한다. 상태 sᵢ는 현재 시점의 다중모달 특징 xᵢ이며, 행동 aᵢ는 “라벨 요청(1)” 혹은 “요청 안 함(0)”이다. Q‑함수는 LSTM + 완전 연결층(fcL)으로 구현되어 시계열 정보를 활용한다. 보상은 라벨 요청에 따른 비용과 올바른 예측에 대한 보상을 균형 있게 설계한다.
- **모델‑레벨 다중모달 융합**: 각 모달리티(얼굴, 몸, 자율신경생리, 음성)에 대해 독립적인 LSTM 분류기 φ^(m)를 학습한다. 각 분류기의 출력은 소프트맥스 확률을 제공하고, 최종 참여 레이블은 다수결(vote) 방식으로 결정한다. 필요 시 신뢰도 기반 가중치를 적용할 수 있다.
**3. 데이터 및 전처리**
실험에 사용된 데이터는 자폐 아동이 로봇과 상호작용하는 장면을 촬영·녹음한 영상이다.
- **얼굴**: OpenFace를 이용해 얼굴 랜드마크, 액션 유닛(AU) 및 강도 추출 (257 D).
- **몸**: OpenPose를 이용해 18개의 관절 좌표와 신뢰도 (70 D).
- **자율신경생리(A‑PHYS)**: Empatica E4 손목 밴드에서 GSR, 심박수, 체온, 3축 가속도 등 (27 D).
- **음성**: openSMILE를 이용해 24개의 저수준 오디오 디스크립터 (24 D).
총 378 D의 특성을 1초 길이(30프레임) 윈도우로 슬라이딩하여 60 ms 간격으로 10개의 시점(T=10)으로 구성한다. 각 윈도우는 라벨(0: 낮음, 1: 중간, 2: 높음)과 연결된다.
**4. 모델 구조 및 학습 절차**
- **분류기 φ^(m)**: 각 모달리티별 LSTM(히든 유닛 64) → Fully‑Connected Layer(64 × 3) → Softmax.
- **Q‑함수**: 동일한 LSTM 구조에 액션 선택을 위한 출력층을 추가.
- **학습 루프**: (1) 현재 정책으로 데이터 샘플을 선택해 라벨을 요청하고, 라벨링된 데이터 D_ℓ에 축적한다. (2) D_ℓ을 이용해 각 φ^(m)를 재학습한다. (3) 다수결 결과와 실제 라벨을 이용해 보상을 계산하고, Q‑함수를 업데이트한다. 이 과정을 예산 B(라벨 요청 횟수)까지 반복한다.
**5. 실험 및 결과**
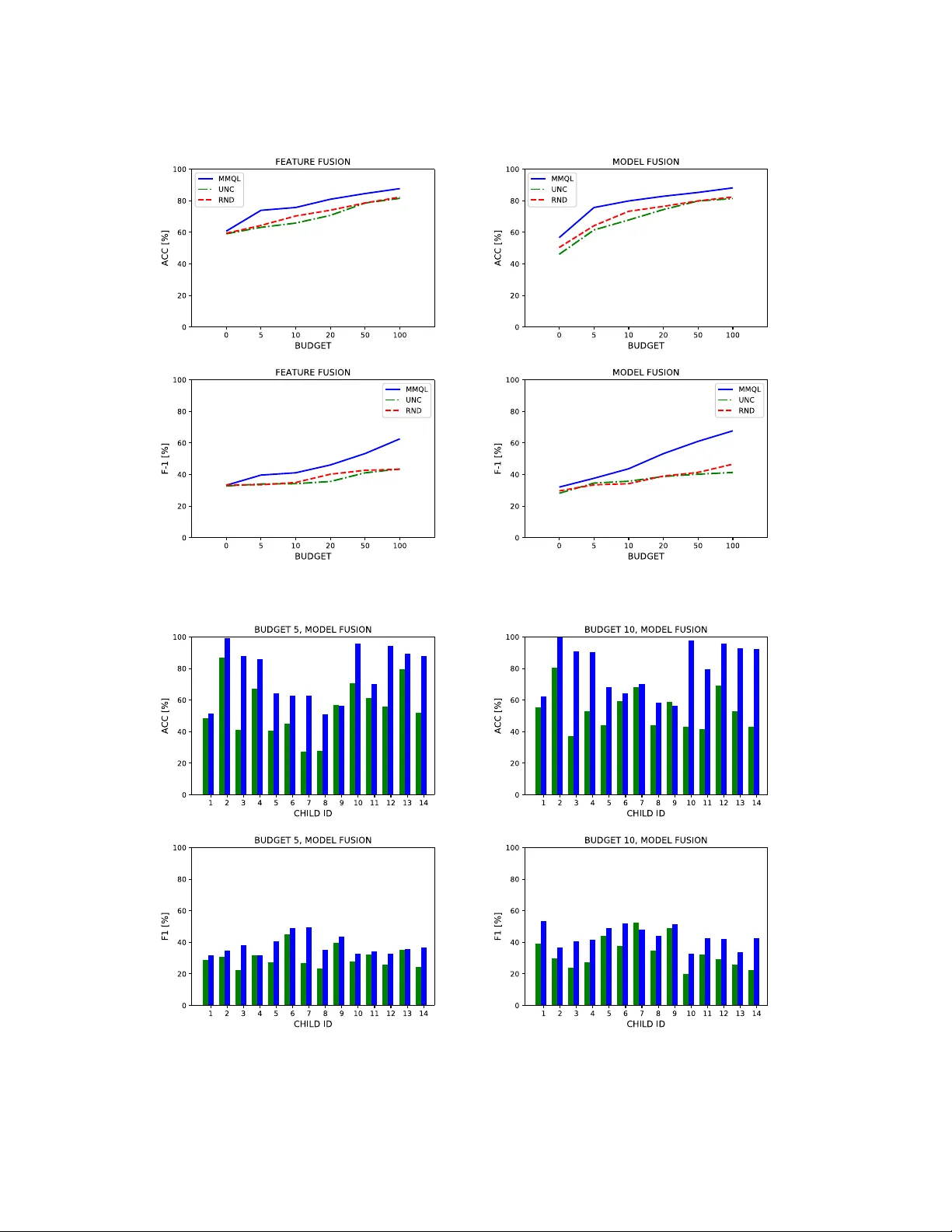
- **비교 대상**: 무작위 샘플링, 불확실성 기반 샘플링(엔트로피, 쿼리‑바이‑커밋티), 특징‑레벨 결합, 모델‑레벨 결합 등.
- **성능 지표**: 정확도, F1‑스코어, 라벨 효율성(라벨당 성능 향상).
- **주요 결과**:
- RL‑AL 정책은 동일 라벨 수 대비 평균 12 % 높은 F1‑스코어를 달성, 무작위 대비 라벨 효율성이 2배 이상.
- 모델‑레벨 융합이 특징‑레벨 결합보다 약 7 % 높은 정확도를 기록.
- 개인화 단계에서 30~50개의 라벨만 사용해도 사전 학습된 일반 모델 대비 5~10 % 성능 향상.
- 라벨링 비용을 크게 절감하면서도 실시간 적용 가능성을 보였다.
**6. 논의 및 한계**
- **강점**: 데이터‑드리븐 정책 학습으로 사용자별 최적 샘플을 자동 선택, 다중모달 정보를 효과적으로 활용, 라벨링 비용 최소화, 개인화된 모델 제공.
- **제한점**: 초기 정책이 무작위이므로 초기 라벨링 비용이 다소 높을 수 있음, 라벨 예산 B가 고정돼 있어 동적 예산 조정이 필요, Q‑함수 학습에 충분한 초기 데이터가 요구됨.
- **향후 연구**: 메타‑강화학습을 통한 사용자‑특화 예산 최적화, 다목적 보상 설계(시간·인간 피로도 포함), 실시간 온라인 학습 및 라벨링 인터페이스 구축.
**7. 결론**
본 연구는 다중모달 인간 행동 데이터에 대한 라벨링 비용 문제와 개인화 요구를 동시에 해결하는 새로운 활성학습 프레임워크를 제시한다. 딥 강화학습 기반의 라벨 요청 정책과 모델‑레벨 다중모달 융합을 결합함으로써, 제한된 라벨 예산 하에서도 높은 참여 추정 정확도와 사용자 맞춤형 모델을 구현하였다. 특히 자폐 아동‑로봇 치료와 같은 실제 현장에 적용 가능함을 실험을 통해 입증했으며, 향후 HCI·HRI 분야에서 라벨 효율적인 다중모달 학습의 기반이 될 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기