Multi-modal Active Learning From Human Data: A Deep Reinforcement Learning Approach
Human behavior expression and experience are inherently multi-modal, and characterized by vast individual and contextual heterogeneity. To achieve meaningful human-computer and human-robot interactions, multi-modal models of the users states (e.g., e…
Authors: Ognjen Rudovic, Meiru Zhang, Bjorn Schuller
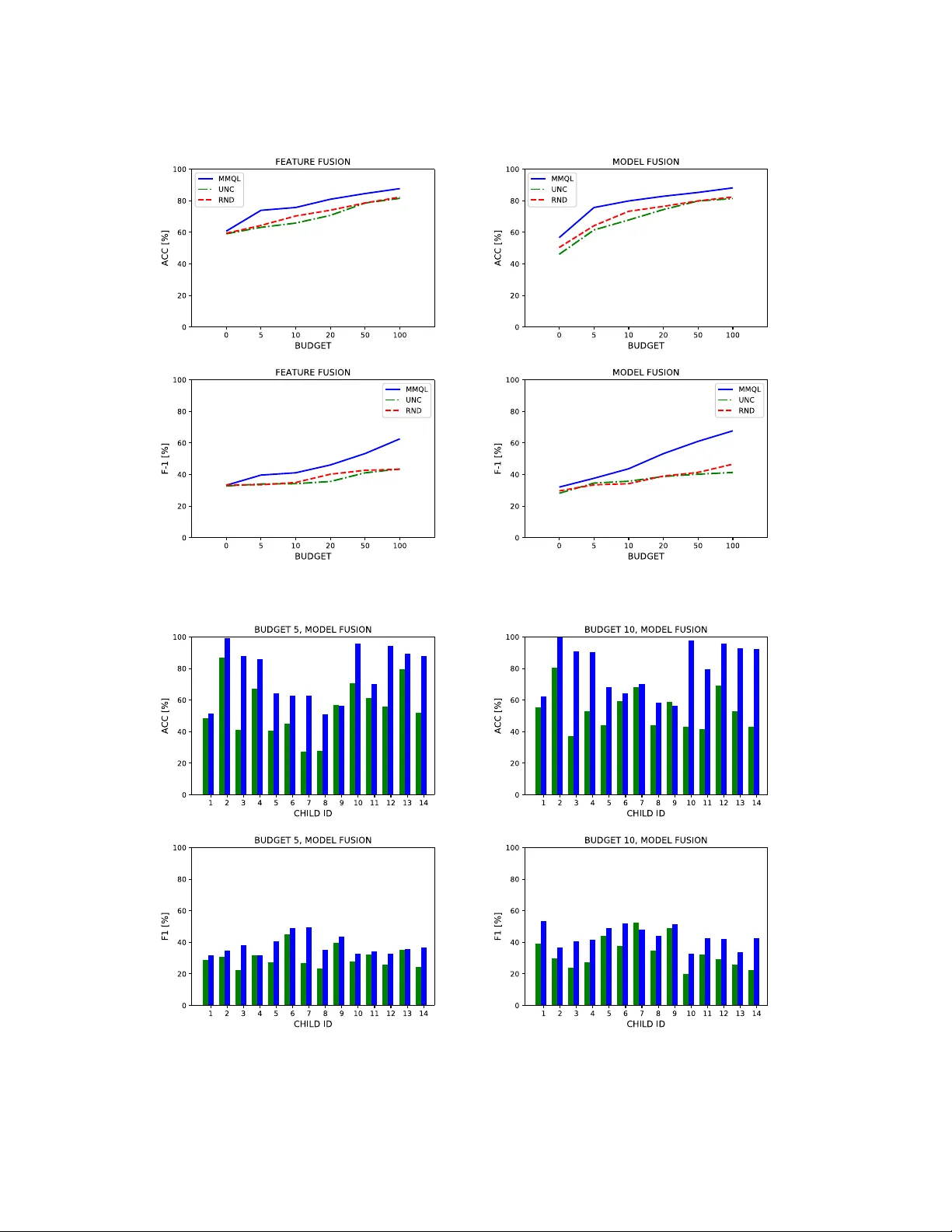
Multi-modal Activ e Learning From Human Data: A De ep Reinforcement Learning Approach Ognjen (Oggi) Rudovic 1 , Meiru Zhang 2 , Björn Schuller 2 and Rosalind W . Picard 1 1 Massachusetts Institute of T echnology , USA, 2 Imperial College London, UK {orudovic,roz}@mit.edu, {meiru.zhang18, bjoern.schuller}@imperial.ac.uk ABSTRA CT Human behavior expression and e xperience are inherently multimodal, and characterized by vast individual and contex- tual heterogeneity . T o achieve meaningful human-computer and human-robot interactions, multi-mo dal models of the user’s states ( e.g., engagement) are therefore needed. Most of the existing works that try to build classiers for the user’s states assume that the data to train the models are fully labeled. Nevertheless, data labeling is costly and tedious, and also prone to subjective interpretations by the human coders. This is even more pronounced when the data are multi-modal (e.g., some users are mor e expressive with their facial expressions, some with their voice). Thus, building models that can accurately estimate the user’s states during an interaction is challenging. T o tackle this, we propose a novel multi-modal active learning ( AL) approach that uses the notion of deep reinforcement learning (RL) to nd an optimal policy for active selection of the user’s data, needed to train the target (mo dality-specic) models. W e investi- gate dierent strategies for multi-mo dal data fusion, and show that the proposed model-level fusion coupled with RL outperforms the feature-level and modality-specic models, and the naïve AL strategies such as random sampling, and the standard heuristics such as uncertainty sampling. W e show the benets of this approach on the task of engagement estimation from real-w orld child-robot interactions during an autism therapy . Importantly , we show that the proposed multi-modal AL approach can be used to eciently p erson- alize the engagement classiers to the target user using a small amount of actively selected user’s data. 1 INTRODUCTION Human behavior is inherently multi-mo dal, and individu- als use eye gaze, hand gestures, facial expressions, bo dy posture, and tone of v oice along with speech to convey en- gagement and regulate social interactions [ 12 ]. A large body A rXiv’19, 2019, USA © 2019 of work in human-computer interaction (HCI) and human- robot interaction (HRI) explored the use of various aec- tive and social cues to facilitate and assess the user engage- ment [ 16 , 36 ]. Most of these works can be divided into those that detect the presence of a set of the engagement cues or interaction events [ 9 , 17 , 29 ], or use supervised classiers trained with social, physiological, or task-base d interaction features [ 6 , 8 , 33 ]. A detailed overview of r elated multi-modal approaches can be found in [ 2 , 28 ]. The majority of these approaches adopt either feature-level ( e.g., by simple con- catenation of the multi-modal input features) or mo del-level (e .g., by combining multiple classiers traine d for each data modality) fusion [ 4 ]. While this can improve the estima- tion of target outcomes (e.g., the user engagement) when compared to the single-modality classiers, these methods usually adopt "one-size-ts-all" learning approach where the trained models are applie d to new users without the adapta- tion to the user . Consequently , their p erformance is usually limited when the users’ data are highly heterogeneous (e.g., due to the dierences in facial expressions/body gestures as a result of individual engagement styles). Recently , sev eral works proposed models for personalized estimation of engagement in HRI. For instance, [ 31 ] proposed a multi-modal deep learning for engagement estimation that combines body , face, audio and autonomic physiology data of children with autism during the therapy sessions with a humanoid robot. Howe ver , most of multi-modal works in HCI and HRI are fully supervise d [ 4 , 20 , 23 ], i.e., they assume that the data used to train the mo dels are fully labele d. Obtaining these labels is expensive , esp ecially when dealing with a large amount of audio-visual r ecordings. Therefore, there is a need for methods that can automatically sele ct the most informative instances that ne ed to be labeled in order to train the target estimation models. More importantly , to improve the generalization of these models, we need to select the data of a new user that can b e used to p ersonalize the target mo dels. Y et, how to select the most informative instances of the multi-modal data from the target user is an open research problem that has not been investigated much. T o address this, the approach proposed here uses the no- tion of AL [ 34 ]. Central to the AL framework is the query strategy used to decide when to request a label for target ArXiv’19, 2019, USA Rudovic, et al. Majority V o te e ngagem en t leve l (lo w , me d , hi g h ) Da t a Pool u pd a t e classifiers LST M fcL LST M fcL LST M fcL LST M fcL Q-fu n ctio n a 1 , a sk o racle 0 , co n tin u e u pdate Q -fun ct io n Figure 1: Overview of the proposed multi-modal AL approach. The input are the recordings of the child-robot interactions during an autism therapy (we used the camera placed behind the robot). The image frames are rst processed using open- source tools (openFace [5] and op enPose [7]) to obtain the facial and b ody cues. Likewise, the audio recordings are processed using the op enSMILE to olkit [13]. W e also used the data collected by the E4 wristband [1] on the child’s hand (providing autonomic physiology data such as galvanic skin conductance and bo dy temperature, as well as the accelerometer data). These data are fed as input to the modality-specic engagement classiers: the LSTM models followed by fully-connected layers (fcL). The classication of the engagement levels ( low , me dium, high) is performe d by applying majority voting to the classiers’ outputs. These are also fed into the Q-function of the RL p olicy for active data-selection (also mo deled using an LSTM cell and fcL for the action sele ction: to ask or not ask for the label). If the label is requeste d, the input multi-modal data is stored in a data pool for labelling by the human expert. These data are then used to train the data-selection p olicy and target classiers. During inference of the data of a new child, the actively-selecte d data are use d to personalize the engagement classiers. data. The most commonly used quer y strategies include un- certainty sampling, entropy , or quer y-by-committee [ 34 ]. Furthermore, more advanced quer y strategies have be en proposed to adapt deep network classiers base d on the un- certainty of the network output (e .g., [ 22 , 24 , 38 ]). Y et, the candidate quer y strategies still must b e sp ecied by a human. More importantly , there is not one strategy that works the best for all users. Instead of using the heuristic strategies, recent (deep) AL approaches (e .g., [ 11 , 15 , 25 , 37 , 39 ]) have adopted a data-driven approach that learns a model-free AL o-line policy using RL [ 35 ]. For instance, [ 39 ] proposed a model where an agent makes a decision whether to request a lab el or make a prediction. The agent receives a reward related to its decision: a positive reward is given for correct predictions, and negative re wards for incorrect predictions or label requests. This can be achieved by the Q-function modeled using the notion of de ep RL [ 15 , 26 ]. The main goal of these approaches is to adapt the prediction model to new tasks, using a minimum numb er of queries. Our work is a generalization of the RL framework for AL [ 15 ] to multi- modal data, where instead of dealing with a single agent- environment, the agent deals simultaneously with multiple environments (i.e., data modalities). Note that RL has previously been applied in the tasks of multi-modal learning. For instance, [ 30 ] used RL to en- hance the machine translation fr om dier ent data modalities. Likewise, [ 21 ] used RL for image question answering, an inherently multi-modal learning problem. Also , in the con- text of visual dialogues, RL has been used with multi-mo dal learning [ 40 ]. However , none of these works explored RL for AL from multimodal data. The most related approach to ours is the multi-view AL framework [ 27 ]. It uses the standard heuristic AL strategies to select data from multi- ple views. While dierent views can b e se en as dierent modalities of the same phenomenon, like facial and b ody gestures of human behaviour , to our knowledge no previous work has attempte d multi-modal AL from the real-world human-interaction data and using RL to learn an optimal data selection policy . Moreov er , the model personalization using such approach has not been explored before. T o tackle the challenges of learning from multi-modal human data (as typically encountered in HCI and HRI), in this work we formulate a novel multi-modal AL approach. W e show that this approach can be used to personalize the data-modality-specic classiers to the target user using a small amount of labeled data of the user , which are auto- matically selected using the newly proposed multi-modal AL strategy . The main contributions of this work are: (i) W e propose a novel appr oach for multi-modal AL using RL for training a policy for active data-selection. (ii) W e propose a novel personalization strategy based on the actively-selected multi-modal data of the target user . (iii) W e show on a highly challenging dataset of child-robot interactions during an autism therapy that the propose d approach leads to large improvements in estimation of engagement (low , medium, high) from the multi-modal data, when compared to non- personalized mo dels, and heuristic AL strategies. The outline of the proposed approach is depicted in Fig. 1. Compared to traditional supervised classiers for multi-modal data, our approach provides an ecient mechanism for actively sele ct- ing the most relevant data for training the target engagement classier , thus, minimizing the human data-lab elling eorts. Multi-modal Active Learning From Human Data ArXiv’19, 2019, USA 2 PRELIMINARIES Problem Statement and Notation In our learning setting, we use multi-modal data recordings of child-robot interactions during an autism therapy [ 31 ], as described in Se c. 4. Formally , we denote our dataset as D = { D (1) , . ., D ( m ) , . ., D ( M ) } , where m = 1 , . ., M denotes the data modality (e.g., face , bo dy , etc.). This dataset comprises video recordings of target interactions of C children (later split into training and test child-independent partitions). W e assume a single recording p er child, which may vary in dura- tion. Each recording is represented with a set of multi-modal features { X , Y } , where X = [ x 1 , . ., x N ] , with x i ∈ R T × M × D M containing the collection of the multi-modal features ex- tracted every 60 ms from a sliding window of 1 second du- ration (30 image frames), resulting in T = 10 temporally correlated multi-modal feature repr esentations (the dimen- sion of modality m = 1 , . ., M is D m ). The features x i of each 1 second inter val are associated with the target engagement label y i = { 0 , 1 , 2 } (see Se c. 4 for details). Note that N can vary per child, i.e., per recording. Given these data, we ad- dress it as a multi-class multi-modal sequence classication problem, where our goal is two-fold: (i) to predict the target label given the input features extracted from the sliding win- dow within the recording, and (ii) to actively select the data of each child so that our engagement estimation model can be personalized to the target child. The Base Classification Model As the base model for the engagement classiers ( φ ) and also to implement the Q-function in the RL component of our approach, we use the Long Short- T erm Memory (LSTM) [ 19 ] model, which enables long-range learning of time-feature dependencies. This has shown great suc cess in tasks such as action recognition [ 3 , 10 ] and spe ech analysis [ 14 , 18 ], among others. Each LSTM cell has hidden states augmented with nonlinear mechanisms that allow the network state to propagate without modication, be updated, or be reset, using simple learned gating functions. More formally , a basic LSTM cell can be describe d with the following equations: ˆ д f , ˆ д i , ˆ д x , ˆ c t = W x · x t + W h · h t − 1 + b д f = σ ( ˆ д f ) , д i = σ ( ˆ д i ) , д x = σ ( ˆ д x ) c t = д f ⊙ c t − 1 + д i ⊙ tanh( ˆ c t ) , h t = д x ⊙ tanh( c t ) , (1) where ˆ д f , ˆ д i , ˆ д x are the forget gates, input gates, and output gates respectively , ˆ c t is the candidate cell state, and c t is a new LSTM cell state. W x and W h are the weights mapping from the observation ( x t ) and hidden state ( h t − 1 ), respec- tively , to the gates and candidate cell state, and b is the bias vector . ⊙ represents element-wise multiplication; σ ( · ) and tanh ( · ) are the sigmoid and hyperb olic tangent functions respectively [ 39 ]. T o model the window of T = 10 time steps in ( x , y ) data pairs, we fe ed the feature vectors from x ∈ [ x 1 , , . ., x l , . ., x T ] to the temporally unrolled LSTM cell. Then, their output-state values h t are passed through fully connected layers fcL t , t = 1 , . ., T (we use a rectied linear unit – ReLU), and average across the time steps. Finally , a sig- moid layer followed by the softmax is applied to this output to obtain the sequence label y ∗ . RL for Data-selection Policy Learning RL [ 35 ] is a framework that can be used to learn an optimal policy π for actively selecting data samples during model training and adaptation. This is a form of Markov Decision Process (MDP), which allows the learning of a p olicy that can dynamically select instances that are most informative [ 15 ]. More specically , given an input feature vector ( x i ), we rst compute a state-vector ( s i ) that is then passed to the traine d policy (Q-function), which outputs an action ( a i ). During training of the Q-function, the goal is to maximize the action- value function Q ∗ ( s i , a i ) . This is at the heart of RL, and it species the expe cted sum of discounted future rewards for taking action a i in state s i and acting optimally from then on as: a i = π ∗ ( s i ) = arg max a i Q ∗ ( s i , a i ); (2) The optimal Q function is given by the Bellman equation: Q ∗ ( s i , a i ) = E s i +1 [ r i + γ max a i +1 Q ∗ ( s i +1 , a i +1 ) | s i , a i ] , (3) where E s i +1 indicates an e xpe cted value ov er the distribution of possible next states s i +1 , r i is the reward at the current state s i (derived from the input features x i ), and γ is a discount factor , which incentivizes the model to seek reward in fewer time steps. The tuples ( a i , s i , r i , s i +1 ) represent a MDP, and they are used to train the Q-function in Eq. (3). 3 METHODOLOGY W e propose a novel appr oach for multi-modal AL that pro- vides an optimal policy for the active data-selection. These data ar e used conse quently to re-train the classication mod- els for estimation of the target output (in our case, the en- gagement level) from xed-sized video segments (1 second long). The proposed approach consists of two sequential pro- cesses: (i) the training of the classiers for the target output, and (ii) the learning of the Q-function of the RL mo del for active data selection. These two are p erformed in a loop, where rst the target classiers are trained using the data of each modality ( m = 1 , . ., M ), thus, M classiers are trained in parallel. Then, based on their outputs, we perform the model-level fusion to obtain the target label for the input. This label is use d, along with the input features and the true label, to train the Q-function for active data selection. During the models’ training, this process is repeated by re-training the classiers and the Q-function until both models have ArXiv’19, 2019, USA Rudovic, et al. converged (or for a xed number of iterations, i.e., training episodes). During inference of new data (in our case, the recording of the interactions between the new child and the robot), the learned group policy (i.e., the Q-function) is rst used to select the data samples that the model is uncertain about. Consequently , these are then used to personalize the target classiers by additionally training each classier using the actively selecte d data of the target child. The personalized classiers are then used to obtain the engagement estimates on the remaining data of the target child. Engagement Classifiers For each data modality ( m = 1 , . ., M ) we train a separate LSTM model, resulting in the following ensemble of the models: φ = { φ (1) , φ (2) , . ., φ ( M ) } . Each model is trained using the actively-selected samples from the target modality , where the numb er of possible samples is dened using a pre-dened budget ( B ) for active learning. The number of hidden states in each LSTM was set to 64 (found on a separate validation set), and the size of the fcL was then set to 64 × 3 , where the network output was 1-hot encoded (three engagement levels). Sp ecically , in the dataset use d, we have M = 4 data mo dalities, comprising of the F A CE ( m = 1 ), BODY ( m = 2 ), autonomic physiology ( A-PHYS) ( m = 3 ) and AUDIO ( m = 4 ) mo dality . Thus, for the target task, we trained four LSTM models. From each data modality , we used the feature representations extracted using the open-source codes for face and b ody processing from image data (openFace [ 5 ] and openPose [ 7 ]), as done in [ 31 ]. These provide the locations of characteristic facial points, facial action units activations (0/1) and their intensities (0-5), and locations of 18 bo dy joints and their condence. As features of A-PHYS, we use d the data collected with the E4 [ 1 ] wristband on a child’s hand, providing the galvanic skin response, heart-rate and b ody temperature, along with the 3D acelerometer data encoding the child’s movements. From the audio recordings, we used 24 low-le vel descriptors pr ovided by the op enSMILE [ 13 ], an open-source toolkit for audio-feature extraction. The feature dimension p er mo dality was: 257D (F ACE), 70D (BOD Y), 27D (A -PH YS), and 24D (A udio), thus, 378 features in total. For more details about the feature extraction, see [31]. T o obtain the engagement estimate by the proposed multi- modal approach, we perform the mo del-level fusion by com- bining the target predictions of the modality-specic LSTMs: b y i ← majorityV ote ( φ (1) ( x ( 1 ) i ) , φ (2) ( x ( 2 ) i ) , φ (3) ( x ( 3 ) i ) , φ (4) ( x ( 4 ) i )) , (4) where in the case of ties, we select the most condent esti- mate, based on the soft-max outputs of each classier . W e also tried other model-fusion schemes, such as condence- based weighting, and majority vote on the three most con- dent estimates, but the basic majority vote performed the best, and was used in the experiments reported. Algorithm 1: Multi-modal Q-learning ( MMQL ) Input : Dataset D = { D (1) , D (2) , . . . , D ( M ) } , mo dels n φ 0 = { φ (1) 0 , φ (2) 0 , . ., φ ( M ) 0 } , Q π 0 o ← rand , budget B Output : Optimized models { φ ∗ , Q π ∗ } for e := 1 to N do D ℓ 0 ← ∅ , shue D ; φ e ← φ e − 1 , Q π e ← Q π e − 1 ; for i := 1 to | D | do b y i ← majorityV ote ( φ e ( x i )) ; s i ← x i # construct a new state; a i = arg max a Q π e ( s i , a ) # make a decision; if a i == 1 then D ℓ e ← D ℓ e ∪ ( x i , y i ) # ask for label; end r i ← R ( a i , b y i , y i ) # compute reward; if | D ℓ e | == B then store ( s i , a i , r i , e nd ) → M ; break; end s i +1 ← x i + 1 # construct a new state; store ( s i , a i , r i , s i +1 ) → M ; update Q π e using a batch from M ; end update models φ e using D ℓ e ; end Return : φ ∗ ← φ e , Q π ∗ ← Q π e Group-policy Learning for Active Data-selection W e rst use the training data (i.e., recordings of the children in the training set) to learn the (initial) group-policy π д for making the de cision whether to quer y or not the label for the input features ( x ). For this, we implement the Q-function using the LSTM model, which receives in its input the states ( s ) and outputs actions ( a ), as describ ed in Sec. 2. States and Actions. W e approximate the Q -function using the LSTM model with 32 hidden units. This is followed by a ReLU layer with the weight and bias parameters { W l , b l } , and softmax in the output, i.e., actions. The actions in our model are binary (ask/ do not ask for lab el), and are 1-hot encoded using a 2D output vector a i for input states s i . For instance, if a label is requested, a i = [1 , 0] ; otherwise, a i = [0 , 1] and no data label is pr ovided by an oracle (e.g. the human expert). For training the Q-function, the design of the input states is critical. T ypically , the raw input features (in our case, x i , are considered to be the states ( s i ) of the model [ 39 ]. While this is feasible, in the case of multiple modalites, this can lead to a large state-space, which in turn can easily lead to the Multi-modal Active Learning From Human Data ArXiv’19, 2019, USA overtting of the LSTM used to implement the Q-function. Here, we pr opose a dierent approach. Instead of using the input content ( x i ) directly , we use the output of the engage- ment classiers to form the states of the Q-function. Namely , the sigmoid layer of each target classier outputs the proba- bilities for each class label in y , i.e., φ ( m ) → ( p ( m ) 1 , p ( m ) 2 , p ( m ) 3 ) . T o obtain the "content-free " 1 states for our RL mo del, for the target input x i , we concatenate these estimate d proba- bilities from each classier to form the state vector s i . Fur- thermore, w e augment this state vector by also adding the overall condence of each classier . This is compute d as C ( m ) = 1 − P | y | i =1 p ( m ) i log( p ( m ) i ) , where the sum on the right- hand side of the equation is the entropy of the classier (we bound it to [0 , 1] ). Finally , in the case of M = 4 , this results in 16D state-vectors s i . As we show in our experi- ments, such the state repr esentation leads to overall better results and learning of the Q-function than when the raw high-dimensional input features are use d to represent the states (in our case, d im ( x ) = 378 ). Reward. Another imp ortant asp ect of RL is the design of the reward function. Given the input multi-modal feature vectors x i , the active learner cho oses an action a i of either requesting the true label y i or not. If the label is requested, the model receives a negative reward to reect that obtaining labels is costly . On the other hand, if no lab el is requeste d, the model receives positive re ward if the estimation is correct; otherwise, it receives negative reward. This is enco ded by the following RL rewar d function: r i ( a i , b y i , y i ) = r r e q = − 0 . 05 , if a i = 1 r c or = +1 , if a i = 0 ∧ b y i = y i r i nc = − 1 , if a i = 0 ∧ b y i = y i , (5) where y i is the target label obtaine d by the majority vote from the modality-spe cic engagement classiers (Se c. 3). This reward is critical for training the Q -function that we use to learn the data-selection policy . Note that this type of reward has previously be en propose d in [ 39 ], however , it has not been used in the context of multi-modal AL. Optimization. Given the space-action pairs, along with the rewards, the parameters of the Q -function are optimized by minimizing the Bellman loss on the training data: L ( i ) B (Θ) = [ Q Θ ( s i , a i ) − ( r i + γ max a i +1 Q Θ ( s i +1 , a i +1 ))] 2 , (6) which encourages the model to improv e its estimate of the expected reward at each training iteration ( we set γ = 0 . 9 ). This is performed sequentially over i = 1 , . . . , N multi-modal data samples from the training children, and over a number of training episodes. The loss minimizaton is performe d using Adam optimizer with the learning rate 0.001. The training of 1 Note that this can also be termed as "meta-weights" , as in the pr eviously proposed meta-learning AL frameworks, e.g., [24]. Algorithm 2: Personalized Engagement Estimation Input : New data D = { D (1) , D (2) , . . . , D ( K ) } , mo dels n φ ∗ = { φ (1) ∗ , φ (2) ∗ , . ., φ ( M ) ∗ } , Q π ∗ o , budget B Output : labeled data in D , adapted models φ ∗ D ℓ ← ∅ , shue D for i := 1 to | D | do b y i ← majorityV ote ( φ ∗ ( x i )) ; s i ← x i # construct a new state; a i = arg max a Q π ∗ ( s i , a ) # make a decision; if a i == 1 then D ℓ ← D ℓ ∪ ( x i , y i ) # ask for label; D ← D \ x i ; end if | D ℓ | == B then break; end end update models φ ∗ using D ℓ ; make estimates b Y ← majorityV ote ( φ ∗ ( X ∈ D )) ; Return : b Y ∈ D , Y ∈ D ℓ , φ ∗ this new AL appr oach, named the Multi-modal Q-learning (MMQL), is summarized in Alg. 1. Personalized Estimation of Engagement The learned group-policy for active data selection can be applied to multi-modal recordings of previously unseen chil- dren. However , the trained multi-modal engagement clas- siers may be sub optimal due to the highly diverse styles of engagement expressions across the childr en with autism, in terms of their facial expr essions, head movements, body gestures and positions, among others. These may var y from child to child not only in their appearance but also dynamics during the engagement episo des. T o account for these in- dividual dierences, we adapt the pr oposed MMQL to each child. W e do so by additionally training (ne-tuning) the modality-specic engagement classiers using the actively selected data samples from the target child. Spe cically , we start with the group-le vel engagement classiers to obtain the initial engagement estimates, but also use the learned Q-function to select dicult data that need be expert-labeled. This is performed in an o-line manner: the requeste d sam- ples of the target child are rst annotated by an expert, and then use d to personalize the engagement classier . The main premise here is that with a small number of human-labeled videos, the engagement classiers can easily b e optimized ArXiv’19, 2019, USA Rudovic, et al. T able 1: The distribution of the engagement levels for each test child. The data samples are obtained by applying a 1-second sliding window , with a shift of 20 ms, to the original recordings of the target children. T est child ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # of samples in class 0 697 0 72 31 541 2281 3903 478 125 0 188 20 0 1134 # of samples in class 1 683 0 107 72 241 1026 1004 772 318 0 101 204 107 44 # of samples in class 2 0 2539 2095 1452 0 0 898 87 549 1689 1524 5686 2107 0 T able 2: ACC [%] of the models b efore ( left ) and after ( right ) adaptation to test children using dierent budgets (5, 10, 20, 50 and 100) for active data-selection (averaged across the children and budgets). Model F A CE BOD Y A -PH YS AUDIO FEA T URE-F MODEL-F MMQL (cont=0) 48.6 / 77.5 61.3 / 80.0 36.5 / 77.3 49.0 / 76.4 60.7 / 80.5 56.6 / 82.3 MMQL (cont=1) 51.0 / 77.4 60.1 / 80.5 30.6 / 78.9 49.1 / 74.4 58.0 / 79.6 54.6 / 82.3 UNC 48.4 / 69.1 63.5 / 74.1 19.4 / 53.5 50.2 / 69.7 59.0 / 71.9 46.1 / 72.9 RND 48.2 / 70.4 62.6 / 73.4 21.5 / 56.7 45.2 / 70.8 59.4 / 73.9 50.4 / 75.2 T able 3: F-1 [%] of the models b efore ( left ) and after ( right ) adaptation to test children using dierent budgets (5, 10, 20, 50 and 100) for active data-selection (averaged across the 14 children and 5 budgets). Model F A CE BOD Y A -PH YS AUDIO FEA T URE-F MODEL-F MMQL (cont=0) 28.9 / 42.2 33.7 / 51.8 23.2 / 44.1 24.2 / 36.2 33.2 / 48.5 32.0 / 52.6 MMQL (cont=1) 30.8 / 44.0 33.5 / 52.5 19.8 / 45.2 23.5 / 39.5 32.9 / 48.5 28.4 / 48.3 UNC 30.0 / 36.3 35.6 / 41.9 14.2 / 30.1 24.3 / 32.0 32.7 / 37.7 28.1 / 38.1 RND 29.9 / 37.0 35.0 / 41.6 16.0 / 31.1 24.2 / 32.7 33.4 / 38.9 29.6 / 38.9 for the target child as: φ n e w ∗ = max ⟨ φ (1) ∗ , φ (2) ∗ , . ., φ ( M ) ∗ ⟩ D ℓ , (7) where D ℓ are the child data-samples actively selected using the group-level Q-function, and under the budget B . This is described in detail in Alg. 2. 4 EXPERIMENTS Data and Features. T o evaluate the proposed approach, w e used the cross-cultural dataset of children with ASC attend- ing a single session (on average, 25 mins long) of a robot- assisted autism therapy [ 32 ]. During the therapy , an experi- enced educational therapist worked on teaching the children socio-emotional skills, fo cusing on r ecognition and imitation of behavioral expressions as shown by neurotypical popula- tion. T o this end, the NAO robot was used to demonstrate ex- amples of these expressions. The data comprises highly syn- chronized audio-visual and autonomic physiological record- ings of 17/18 children, ages 3-13, with Japanese/European cul- tural background, respectively . All the children have a prior medical diagnosis of ASC, var ying in its severity . The audio- visual recordings were annotated by the human experts on a continuous scale [ -1,1]. W e discretized these annotations by binning the average continuous engagement score within 1 sec intervals into: low [-1,0.5], medium (0.5,0.8], and high (0.8,1] engagement. The multi-modal features were obtained as described in Sec. 3. W e split the children into training (20) and test (14) 2 at random, and used their recordings for the evaluation of the models presented here . T able 1 shows the highly imbalanced nature of the data of the test children. Performance Metrics and Models. W e report the average accuracy (A CC) and F-1 score of the models in the task of 3-class engagement classication. The reported results are obtained by evaluating the group-le vel models and models adapted to each test child ( Alg. 2). The latter was repeated 10 times by random shuing of the test child data, and the average results ar e reported. For training/adaptation of the models, we varied the budget for active data selection as B ∈ { 5 , 10 , 20 , 50 , 100 } . The number of episo des during train- ing was set to 100, and LSTMs were trained for 10 ep ochs in each episode (and during the classier adaptation to the test child). T o evaluate dierent mo del settings, we start with the uni-modal models (thus, trained/tested using only M = 1 data modality – F ACE, BOD Y , A -PH YS or AUDIO) and the multi-modal approach with the feature le vel fusion (i.e., by concatenating the input features from modalities M = 1 , . ., 4 ). W e compare these mo dels to the proposed model-level fusion in the MMQL approach. As the baselines, w e show the per- formance achieved with alternative data-selection strategies: 2 The data of one child were discarded because of severe face occlusions. Multi-modal Active Learning From Human Data ArXiv’19, 2019, USA random sampling (RND) and the most common AL heuristic for data selection – uncertainty sampling ( UNC). In the case of multi-modal learning, the UNC scores for each sample were compute d as the sum of the classiers’ entr opy (Sec.3). Results. T ables 2&3 show the summar y of the performances achieved by the compared mo dels. W e rst note that the classiers trained on the training children have generalized poorly on the test children. This is expecte d especially when using data of children with autism, who e xhibit very dier- ent engagement patterns during their interactions. A s can be seen from the numbers on the right-hand side ( obtained after the personalization of the classiers using actively selected data of the target child), the models’ performances largely increase. This evidences the imp ortance of the model p er- sonalizion using the data of the target child. O verall, among the uni-modal models, the BODY modality achieves the best performance, followed by the F A CE, A-PHYS, and AUDIO modality , as also noted in [ 31 ]. Howev er , both multi-modal versions of the models (feature- and model-level fusion) bring gains in the performance, with the mo del-level fusion per- forming the best on average. Comparing the MMQL models with the states based on the data content (cont=1) and those constructe d from the classiers outputs (cont=0), we note that there is no large dierence in the performance for most mo dels. Y et, the F- 1 score of the MMQL with model-level fusion achieves a larger improvement (4.3%). On the other hand, by looking at Fig. 2, we note that the MMQL approach with cont=0 requires a lower search time to reach the budget, while achieving a similar performance to when the content is used. Thus, this simpler model is preferable in practice. In the rest of Figure 2: The relative number of searched data samples when the states of the Q-function in MMQL approach are: the raw input features x (cont=1), and those constructed us- ing the output of the modality-spe cic classiers (cont=0). the experiments, we show the performance of the MMQL (cont=0) only . Compared to the baselines, w e note that the proposed MMQL largely outperforms these base strategies for active data-selection, under the same budget constraints. This evidences that the proposed is able to learn a more ecient data-selection policy . By comparing the A CC and F-1 scores, we note that the proposed is able to improve the classication of each engagement level, while the RND/UNC strategies tend to overt the majority class. Similar observations can be made from Fig. 3, showing the performance of personalized models after the adaptation using dierent budgets. MMQL consistently outperforms RND and UNC sampling strategies, which we attribute again to the superior performance of the data sele ction strategy attained by the RL Q-function. This trend is even more pr o- nounced for larger budgets, evidencing that the propose d Q-function consistently selects the more informative data samples, that are used to adapt the modality-specic classi- ers to the target child. This holds for b oth, the feature- and model-level fusion within the proposed MMQL approach. Fig. 4 shows the performance of the MMQL (mo del-fusion, cont=0) approach per child before and after the model per- sonalization using data actively selected with the proposed RL approach. Note that even with 5 samples only , the engage- ment classication improv es largely and for almost all test children. Howe ver , because of the highly imbalanced nature of these data (see T able 3), F-1 scores are relativ ely low , yet, the improvements due to the active adaptation of the target classiers are evident. One of the challenges when work- ing with such imbalanced data is that the classiers tend to overt the majority class as most of the active samples come from that class. While this is much more pronounced in the RND/UNC selection strategies, it is also one of the b ottle- necks of the current approach since the target classiers are updated oine. W e plan to address this in our future work. 5 CONCLUSIONS W e proposed a novel active learning approach for multi- modal data of human behaviour . Instead of using heuristic strategies for active data-selection (such as the uncertainty sampling), our approach uses the notion of deep RL for active selection of the most informative data samples for the mo del adaptation to the target user . W e sho wed the eectiveness of this approach on a highly challenging multi-modal dataset of child-robot interactions during an autism therap y . Speci- cally , we showed that the learned data-selection policy can generalize well to new children by being able to select their data samples that allow the pr e-trained engagement classi- ers to adapt quickly to the target child. W e showed that this multi-modal model personalization can largely improve the performance of the engagement estimation for each test child using only a few expert-labeled data of the target child. ArXiv’19, 2019, USA Rudovic, et al. Figure 3: The performance of the feature- and model-level fusion with dierent active data-selection strategies. Figure 4: The performance per test child of the MMQL (model-level fusion, cont=0) before (in green ) and after (in blue ) the personalization of the engagement classiers. The results are shown for the budgets 5 and 10. Multi-modal Active Learning From Human Data ArXiv’19, 2019, USA REFERENCES [1] Empatica e4: https://w ww .empatica.com/en-eu/research/e4/, 2015. [2] X. Alameda-Pineda, E. Ricci, and N. Sebe. Multimodal behavior analysis in the wild: An introduction. In Multimodal Behavior A nalysis in the Wild , pages 1–8. Elsevier , 2019. [3] M. Baccouche, F. Mamalet, C. W olf, C. Garcia, and A. Baskurt. Se- quential deep learning for human action recognition. In International W orkshop on Human Behavior Understanding , pages 29–39. Springer , 2011. [4] T . Baltrušaitis, C. Ahuja, and L.-P. Morency . Multimodal machine learning: A survey and taxonomy . IEEE Transactions on Pattern A nalysis and Machine Intelligence , 41(2):423–443, 2019. [5] T . Baltrušaitis, P . Robinson, and L.-P. Morency . Openface: an open source facial behavior analysis toolkit. In IEEE Conference on A pplica- tions of Computer Vision , pages 1–10, 2016. [6] D. Bohus and E. Horvitz. Managing human-robot engagement with forecasts and... um... hesitations. In Pr oce edings of the 16th international conference on multimodal interaction , pages 2–9. ACM, 2014. [7] Z. Cao, T . Simon, S.-E. W ei, and Y . Sheikh. Realtime multi-person 2d pose estimation using part anity elds. In IEEE Conference on Computer Vision and Pattern Recognition , 2017. [8] G. Castellano, A. Pereira, I. Leite, A. Paiva, and P . W . McOwan. Detect- ing user engagement with a robot companion using task and social interaction-based features. In Proceedings of the 2009 international conference on Multimodal interfaces , pages 119–126. ACM, 2009. [9] C. Chang, C. Zhang, L. Chen, and Y . Liu. An ensemble model using face and bo dy tracking for engagement detection. In Procee dings of the International Conference on Multimodal Interaction , pages 616–622. A CM, 2018. [10] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. V enu- gopalan, K. Saenko , and T . Darrell. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 2625–2634, 2015. [11] Y . Duan, J. Schulman, X. Chen, P . L. Bartlett, I. Sutskever , and P . Abbeel. Rl2: Fast reinforcement learning via slow reinforcement learning. arXiv preprint arXiv:1611.02779 , 2016. [12] R. El K aliouby , R. Picard, and S. Baron-Cohen. Aective computing and autism. A nnals of the New Y ork Academy of Sciences , 1093(1):228–248, 2006. [13] F. Eyben, F . W eninger , F. Gross, and B. Schuller . Recent developments in opensmile, the munich open-source multimedia feature extractor . In A CM International Conference on Multimedia , pages 835–838, 2013. [14] F. Eyb en, F. W eninger , S. Squartini, and B. Schuller . Real-life voice activ- ity detection with lstm recurrent neural networks and an application to hollywood movies. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 483–487, 2013. [15] M. Fang, Y . Li, and T . Cohn. Learning how to active learn: A deep reinforcement learning approach. arXiv preprint , 2017. [16] M. A. Go odrich, A. C. Schultz, et al. Human–robot interaction: a survey . Foundations and Trends ® in Human–Computer Interaction , 1(3):203–275, 2008. [17] G. Gordon, S. Spaulding, J. K. W estlund, J. J. Lee, L. Plummer, M. Mar- tinez, M. Das, and C. Breazeal. Aective Personalization of a Social Robot Tutor for Children’s Second Language Skills. In Thirtieth AAAI Conference on A rticial Intelligence , 2016. [18] A. Graves and N. Jaitly . T owards end-to-end speech recognition with recurrent neural networks. In International Conference on Machine Learning , pages 1764–1772, 2014. [19] S. Hochreiter and J. Schmidhuber . Long short-term memor y . Neural computation , 9(8):1735–1780, 1997. [20] A. Jaimes and N. Sebe. Multimodal human–computer interaction: A survey . Computer vision and image understanding , 108(1-2):116–134, 2007. [21] A.- W . Jiang, B. Liu, and M.- W . W ang. Deep multimodal reinforce- ment network with contextually guided recurrent attention for image question answering. Journal of Computer Science and T echnology , 32(4):738–748, 2017. [22] C. Käding, E. Rodner , A. Freytag, and J. Denzler . Active and continuous exploration with deep neural networks and expected mo del output changes. arXiv preprint , 2016. [23] S. E. Kahou, X. Bouthillier , P. Lamblin, C. Gulcehre , V . Michal- ski, K. Konda, S. Jean, P. Froumenty , Y . Dauphin, N. Boulanger- Lewandowski, et al. Emonets: Multimodal deep learning approaches for emotion recognition in video. Journal on Multimodal User Interfaces , 10(2):99–111, 2016. [24] K. Konyushkova, R. Sznitman, and P. Fua. Learning active learning from data. In Advances in Neural Information Processing Systems , pages 4228–4238, 2017. [25] M. Liu, W . Buntine, and G. Haari. Learning to actively learn neural machine translation. In Proceedings of the 22nd Conference on Compu- tational Natural Language Learning , pages 334–344, 2018. [26] V . Mnih, K. Kavukcuoglu, D. Silver , A. Graves, I. Antonoglou, D. Wier- stra, and M. Riedmiller . Playing atari with deep r einforcement learning. arXiv preprint arXiv:1312.5602 , 2013. [27] I. Muslea, S. Minton, and C. A. Knoblock. Active learning with multiple views. Journal of A rticial Intelligence Research , 27:203–233, 2006. [28] M. Pantic and L. J. Rothkrantz. T oward an aect-sensitive multimodal human-computer interaction. Proceedings of the IEEE , 91(9):1370–1390, 2003. [29] H. W . Park, I. Grover , S. Spaulding, L. Gomez, and C. Br eazeal. A mo del- free aective reinforcement learning approach to personalization of an autonomous social robot companion for early literacy education. In Proceedings of the Thirty Third AAAI Conference on Articial Intelligence , AAAI’19. AAAI Press, 2019. [30] X. Qian, Z. Zhong, and J. Zhou. Multimo dal machine translation with reinforcement learning. arXiv preprint , 2018. [31] O. Rudovic, J. Lee, M. Dai, B. Schuller , and R. Picard. Personalize d machine learning for robot perception of aect and engagement in autism therapy . Science Rob otics , 2018. [32] O. Rudovic, J. Lee, L. Mascarell-Maricic, B. W . Schuller , and R. W . Picard. Measuring engagement in robot-assisted autism therapy: A cross-cultural study . Frontiers in Rob otics and AI , 4:36, 2017. [33] J. Sanghvi, G. Castellano, I. Leite, A. Pereira, P. W . McO wan, and A. Paiva. Automatic analysis of aective postures and body motion to detect engagement with a game companion. In Proceedings of the 6th international conference on Human-robot interaction , pages 305–312. A CM, 2011. [34] B. Settles. Active learning literature survey . University of Wisconsin, Madison , 52(55-66):11, 2010. [35] R. S. Sutton and A. G. Barto . Reinforcement learning: An introduction. MI T press Cambridge , 1998. [36] C. T siourti, A. W eiss, K. W ac, and M. Vincze. Multimodal integra- tion of emotional signals from voice , bo dy , and context: Eects of (in) congruence on emotion recognition and attitudes towards robots. International Journal of Social Rob otics , pages 1–19, 2019. [37] J. X. Wang, Z. Kurth-Nelson, D. Tirumala, H. Soyer , J. Z. Leib o, R. Munos, C. Blundell, D. Kumaran, and M. Botvinick. Learning to reinforcement learn. arXiv preprint , 2016. [38] K. W ang, D . Zhang, Y . Li, R. Zhang, and L. Lin. Cost-eective active learning for deep image classication. IEEE Transactions on Circuits ArXiv’19, 2019, USA Rudovic, et al. and Systems for Video T echnology , 2016. [39] M. W oo dward and C. Finn. Active one-shot learning. NIPS, Deep Reinforcement Learning W orkshop , 2016. [40] J. Zhang, T . Zhao, and Z. Yu. Multimodal hierarchical reinforce- ment learning policy for task-oriented visual dialog. arXiv preprint arXiv:1805.03257 , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment