의료 영상 다중 클래스 분할을 위한 분해‑통합 학습
본 논문은 의료 영상의 다중 클래스 세그멘테이션을 위해 주석 맵을 여러 하위 문제로 분해하고, 각각을 독립적인 딥러닝 모듈로 학습한 뒤 결과를 통합하는 K‑to‑1 네트워크 프레임워크를 제안한다. 클래스 기반, 형태 기반, 이미지 레벨 기반 등 세 가지 주석 분해 방식을 제시하고, DenseVoxNet·CUMedNet 등 최신 FCN에 적용해 3D·2D 데이터셋에서 성능 향상을 입증한다.
저자: Yizhe Zhang, Michael T. C. Ying, Danny Z. Chen
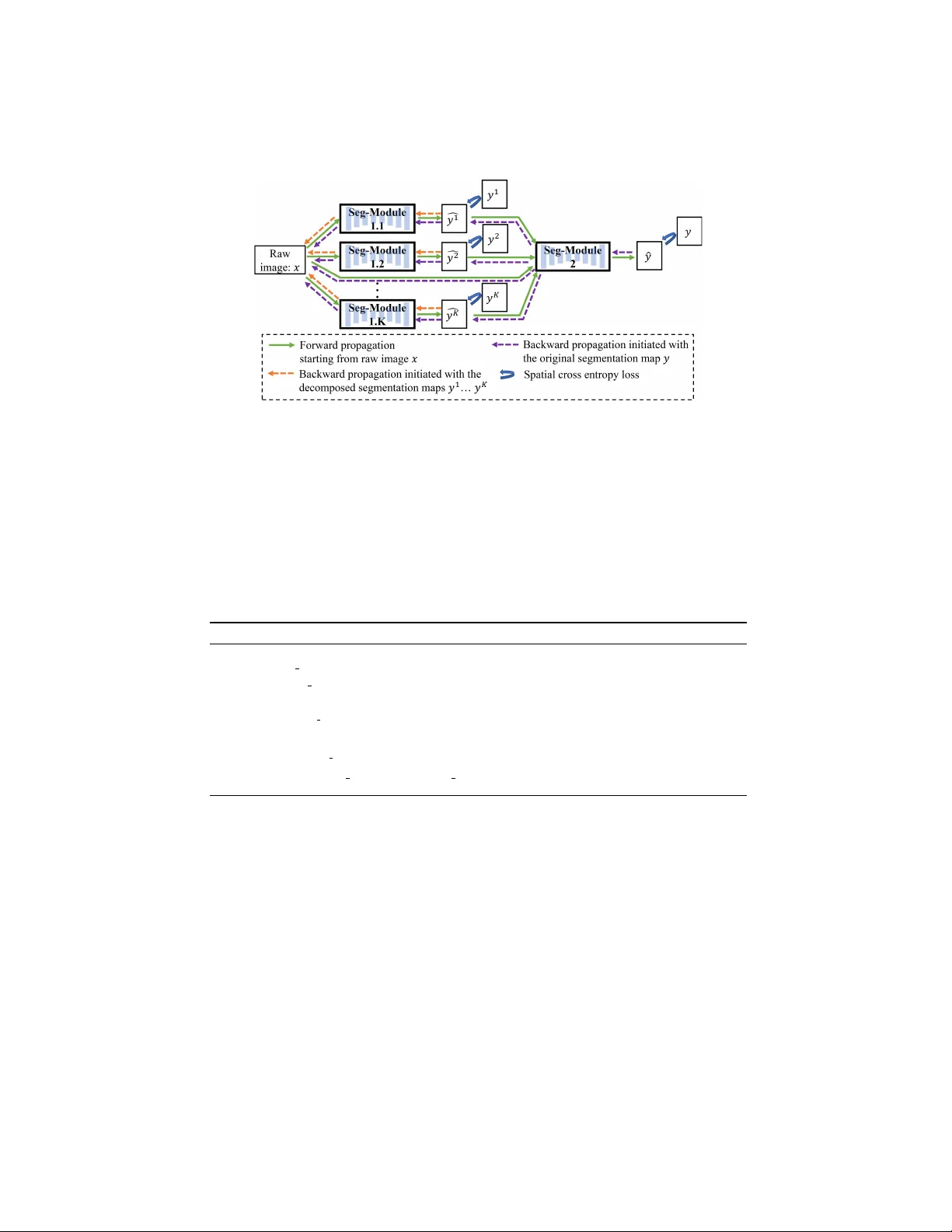
본 논문은 의료 영상에서 다중 클래스 세그멘테이션을 수행할 때, 주석 맵이 단순히 클래스 라벨을 나타내는 것 이상으로 객체의 크기·형태·상호 위치 관계 등 풍부한 공간 정보를 담고 있다는 점에 주목한다. 이러한 정보를 효과적으로 활용하기 위해 저자들은 ‘분해‑통합(Decompose‑and‑Integrate)’ 학습 체계를 제안한다.
첫 번째 단계인 ‘분해(Decompose)’에서는 원본 주석 맵을 여러 개의 서브 맵으로 나눈다. 구체적인 분해 방법은 세 가지로 제시된다. (1) 클래스 기반 분해: K‑class 문제를 K개의 이진 주석 맵(y₁,…,y_K)으로 분리한다. (2) 형태 기반 분해: 객체의 형태를 convex와 concave 두 종류로 구분해 각각의 서브 맵을 만든다. 형태는 convex hull을 이용해 비율을 계산하고, 임계값 T_shape(=0.9)보다 크면 convex, 작으면 concave로 분류한다. (3) 이미지 레벨 기반 분해: 이미지에 포함된 객체 수에 따라 ‘단일 객체’와 ‘다중 객체’ 맵으로 나눈다. 이러한 분해는 각 서브 문제에 특화된 특징 학습을 가능하게 하며, 특히 클래스 간 강한 공간 상관관계가 존재하거나 작은 객체가 희소한 경우에 유리하다.
두 번째 단계인 ‘통합(Integrate)’에서는 분해된 K개의 서브 문제를 각각 독립적인 딥러닝 세그멘테이션 모듈에 입력해 학습한다. 각 모듈은 동일한 네트워크 구조(예: DenseVoxNet, CUMedNet)지만 파라미터는 별도로 최적화된다. 이후 K개의 모듈 출력을 하나의 ‘통합’ 네트워크에 연결해 원래의 다중 클래스 맵을 재구성한다. 이를 구현한 것이 K‑to‑1 딥 네트워크 프레임워크이다. 전체 손실 함수는
L_total = Σ_i
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기