Decompose-and-Integrate Learning for Multi-class Segmentation in Medical Images
Segmentation maps of medical images annotated by medical experts contain rich spatial information. In this paper, we propose to decompose annotation maps to learn disentangled and richer feature transforms for segmentation problems in medical images.…
Authors: Yizhe Zhang, Michael T. C. Ying, Danny Z. Chen
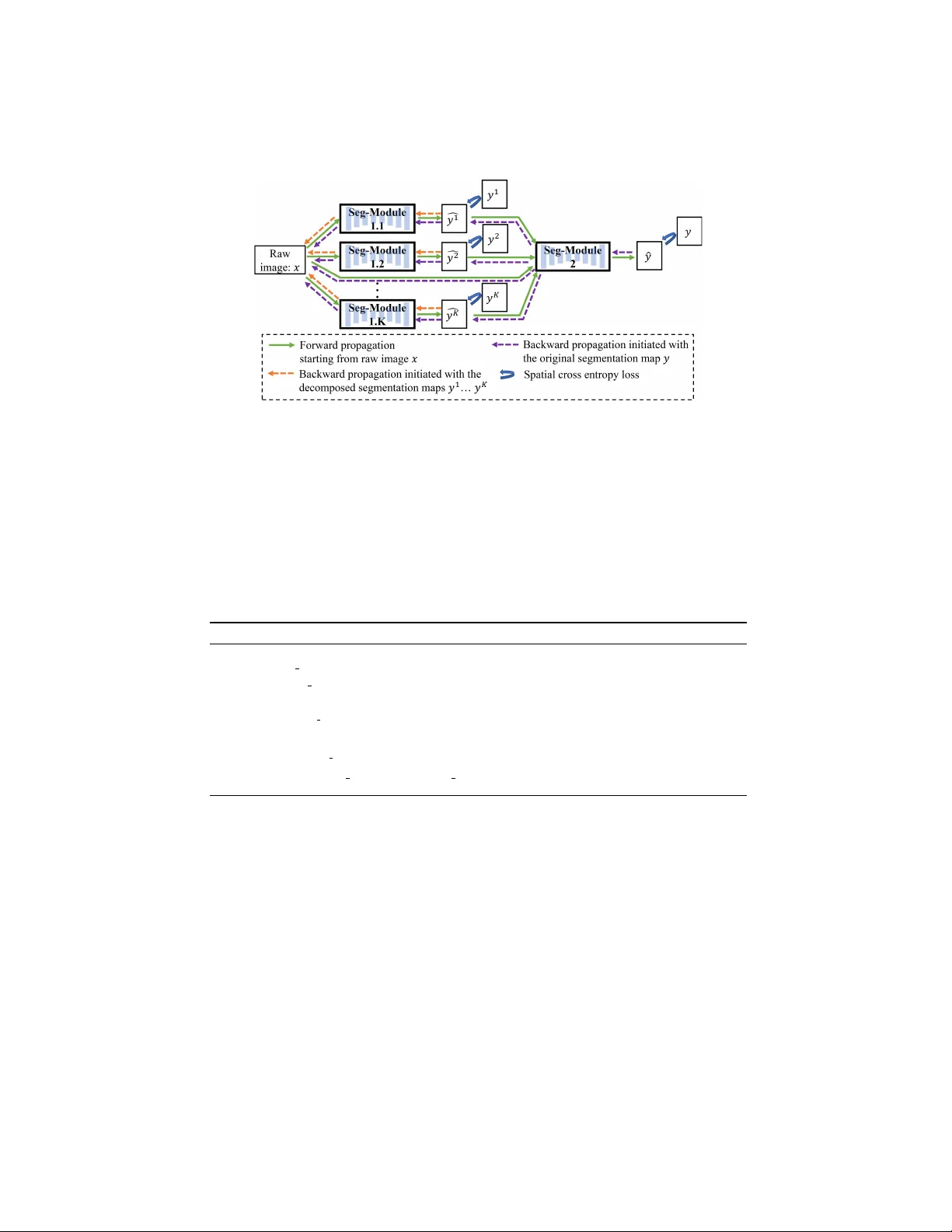
Decomp ose-and-In tegrate Learning for Multi-class Segmen tation in Medical Images Yizhe Zhang 1 , Mic hael T. C. Ying 2 , Dann y Z. Chen 1 1 Departmen t of Computer Science and Engineering, Universit y of Notre Dame, Notre Dame, IN 46556, USA 2 Departmen t of Health T ec hnology and Informatics, The Hong Kong P olytechnic Univ ersity , Hung Hom, Hong Kong Abstract. Segmen tation maps of medical images annotated by medical exp erts con tain rich spatial information. In this paper, we propose to de- comp ose annotation maps to learn disen tangled and richer feature trans- forms for segmen tation problems in medical images. Our new scheme consists of t wo main stages: dec omp ose and integr ate . De comp ose : by annotation map decomposition, the original segmen tation problem is decomp osed into multiple segmentation sub-problems; these new seg- men tation sub-problems are mo deled b y training multiple deep learning mo dules, each with its o wn set of feature transforms. Inte gr ate : a proce- dure summarizes the solutions of the mo dules in the previous stage; a final solution is then formed for the original segmentation problem. Mul- tiple w ays of annotation map decomp osition are presen ted and a new end-to-end trainable K -to-1 deep net work framew ork is dev elop ed for implemen ting our prop osed “decompose-and-integrate” learning sc heme. In exp erimen ts, we demonstrate that our decompose-and-integrate seg- men tation sc heme, utilizing state-of-the-art fully conv olutional net works (e.g., DenseV o xNet in 3D and CUMedNet in 2D), impro ves segmen tation p erformance on m ultiple 3D and 2D datasets. Ablation study confirms the effectiveness of our proposed learning scheme for medical images. 1 In tro duction Segmen tation annotation maps are crucial for supervised training a deep learning based segmentation model. F or segmentation annotation maps, b esides the class lab el dimension, there are spatial dimensions that contain ric h information of ob ject size, shap e, and betw een-ob ject/b etw een-class relations. Previous work has prop osed some methods for modifying annotation maps for training b etter deep learning based segmentation mo dels. Directional map [10] was proposed to generate additional training loss based on the relative posi- tions of the pixels to the centers of their corresponding ob jects. Deep watershed transform [1] provided a similar approach that con verts an annotation map to a w atershed energy map to guide the training of a segmentation mo del. These efforts demonstrated that c hanging segmen tation annotation maps to include ad- ditional information (e.g., relative p osition, stronger instance-level information) can help train b etter deep learning mo dels for segmen tation tasks. 2 Fig. 1. Segmentation annotation map decomposition based on ob ject classes. In medical image segmen tation, different classes of ob jects often ha ve strong m utual locations and spatial correlations. Due to these correlations, learning represen tation and feature transform for one ob ject class can often indicate the existence of some other ob ject classes (possibly nearb y). A conv entional w ay of using m ulti-class annotation maps is to treat a full annotation map as a whole sub ject and use spatial cross-en tropy loss function to compare it with the mo del’s outputs in back propagation [8,3,13]. Due to spatial correlations among different ob ject classes, directly using annotations of all ob ject classes to train a deep net work may cause a deep net work not to b e able to fully exploring its repre- sen tation learning ability for ev ery ob ject class, esp ecially for those classes with small sizes and unclear/confusing app earance. F urthermore, there ma y be mul- tiple distinct structures/clusters under one class of ob jects, and eac h sub-class structure may b etter utilize a unique set of feature representations. In principle, w e believe that modeling individual classes and sub-classes of structures or ob- jects can encourage deep learning models to learn richer and more comprehensive feature transforms and data represen tations for segmentation problems. In this paper, we propose to systematically decompose the original annotation maps to encourage deep netw orks to learn richer and possibly more disentangled feature transforms and representations. Our new scheme consists of t wo main stages: de c omp ose and inte gr ate . De c omp ose : b y annotation map decomp osition, the original segmen tation problem is decomp osed into multiple segmen tation sub-problems (e.g., see Fig. 1); these new segmen tation sub-problems are mod- eled by training multiple deep learning mo dules, each with its own set of feature transforms. Inte gr ate : a pro cedure summarizes the solutions of the mo dules in the previous stage; a final solution is then formed for the original segmenta- tion problem. This decompose-and-integrate sc heme allows to explicitly enforce a deep learning mo del to learn representations for ev ery ob ject class. Besides, it can also be applied to learn feature transforms and represen tations for (h uman exp ert defined) meaningful sub-class data clusters and structures (see Fig. 2). In Section 2, w e presen t differen t w ays to decomp ose annotation maps for dif- feren t scenarios, and develop a new K -to-1 deep net work mo del for implementing our new learning scheme. In Section 3, w e ev aluate our decomp ose-and-in tegrate learning scheme utilizing m ultiple state-of-the-art fully conv olutional net works (F CNs) on three medical image segmen tation datasets, and examine several pro- p osed annotation decomp osition (AD) metho ds. 3 Fig. 2. Segmentation annotation map decomposition based on ob ject shap e prop ert y . 2 Decomp ose-and-In tegrate Learning Consider a K -class segmen tation training dataset { ( x i , y i ), i = 1 , 2 , . . . , h } , x i ∈ R m × n is a raw image, and y i ∈ { 1 , 2 , . . . , K } m × n is a segmentation annota- tion map con taining all the annotations of the K classes of interest. Sup ervised learning for K -class segmentation tasks aims to learn a function f ∈ F that transforms x to y . Note that eac h y i can b e denoted as { y 1 i , y 2 i , . . . , y K i } , where y k i ∈ { 0 , 1 } m × n is an annotation map for ob ject class k , for k = 1 , 2 , . . . , K . F or a segmentation problem with t wo foreground ob ject classes A and B , supp ose mo deling p ( y B | x ) for class B is more difficult than mo deling p ( y A | x ) for class A . This means that learning a robust laten t representation R B ( x ) for class B takes more computational effort (e.g., more training iterations/gradien t descen t effort) than learning a robust latent represen tation R A ( x ) for class A . Note that R B ( x ) and R A ( x ) are not necessarily disjoin t. When p ( y A ) and p ( y B ) ha ve mo derate or high spatial correlations, using joint annotations of these tw o classes for training a deep learning mo del can lead to: (1) p ( y A | x ) is quite lik ely to b e mo deled using R A ( x ); (2) p ( y B | x ) would be modeled with help from R A ( x ), and not mainly by using R B ( x ); (3) R B ( x ) is not fully explored during model training, due to the “help” of the annotations from class A . F or a b etter rep- resen tation and feature learning p erformance, such “help” is undesired. Besides m ulti-class segmentation scenarios, when an ob ject class has distinct meaningful underlining sub-class structures/clusters, having a separate modeling for each individual structure/cluster enforces a deep net work to learn more meaningful and useful data represen tations and feature transforms for such a class. 2.1 Segmen tation annotation map decomposition Based on ob ject classes. F or a K -class segmentation problem, we can de- comp ose y i in to K binary annotation maps y k i , k = 1 , 2 , . . . , K . Algorithm 1 giv es the exact pro cedure. Fig. 1 shows an image illustration of the effect of this annotation decomp osition (AD). In medical image segmentation problems, the n umber of ob ject classes is usually small, and is muc h smaller than in natural scene images. A general guideline is that the decomposed segmentation maps and their asso ciated extra computational costs should be under a manageable lev el. T able 1 shows that ob ject-class based AD can effectively impro ve segmentation p erformance for segmentation problems with multiple foreground classes. 4 Algorithm 1 Ob ject-class based annotation decomp osition 1: function Annot a tionDecomposition1 ( y i ∈ { 1 , 2 , . . . , K } m × n ) 2: for k ← 1 to K do 3: y k i = a new array of size m × n with all 0; 4: y k i [where( y i == k )] ← 1; 5: return y 1 i , y 2 i , . . . , y K i Based on ob ject shap es. Annotation maps can also b e decomp osed based on differen t shape structures in the annotation maps. This type of decomposition can b e applied to 2-class segmentation or ev en K -class segmen tation for K > 2. Shap e information contains v aluable cues for segmen tation tasks. Decom- p osing annotation maps based on differen t ob ject shap es can encourage a deep learning mo del to learn feature transforms that enco de the raw images in to dif- feren t shape-guided represen tations. In histology image analysis, morphological features such as shape con vexit y pla y an imp ortan t role in ob ject detection, segmen tation, and diagnosis. Thus, w e propose to decomp ose segmen tation an- notation maps based on shap e conv exity of ob jects in the annotation maps. Sp ecifically , tw o sub-segmentation maps are generated from an original segmen- tation annotation map, one containing con vex-lik e shape ob jects and the other con taining concav e-lik e shap e ob jects. This decomposition provides additional information that directly helps a learning mo del to p erceiv e ob ject information at a higher (ob ject shap e) level. The detailed procedure and image illustration are provided in Algorithm 2 and Fig. 2. In practice, w e set T shape as 0.9. T able 2 demonstrates the usefulness of shape based AD when segmen tation problems con tain ob jects with sev eral shap e t yp es. Algorithm 2 Ob ject-shap e based annotation decomp osition 1: function Annot a tionDecomposition2 ( y i ∈ { 1 , 2 , . . . , K } m × n , T shape ) 2: y convex i ← a new array of size m × n with all 0; 3: y concave i ← a new array of size m × n with all 0; 4: for every ob ject p in y i do 5: Compute the conv ex hull p convex of p 6: r atio = size( p )/size( p convex ) 7: if ratio > T shape ( p is of a con vex-lik e shap e) then 8: Add ob ject p to y convex i 9: else 10: Add ob ject p to y concave i 11: return y convex i and y concave i Based on image-lev el information. Image-lev el information, statistics, and cues can b e utilized for annotation map decomp osition. F or example, if images con tain one or multiple foreground ob jects, we can decomp ose the segmentation maps based on the num b er of ob jects app eared in an image. As the n umber of ob jects could only b e revealed at a global lev el or deep er lay er in a deep learning 5 Fig. 3. The K -to-1 deep netw ork framew ork for our new decomp ose-and-in tegrate learning sc heme. y k , k = 1 , 2 , . . . , K , are decomp osed segmentation annotation maps, and y is the original segmentation annotation map. mo del, this decomp osition metho d pushes a learning model to be more a ware of global and higher-level information when generating segmentation results. An exact annotation decomp osition procedure based on the image-level num b er of ob jects is giv en in Algorithm 3. In T able 3, w e sho w the effectiveness of image- lev el information based AD for lymph no de segmentation in ultrasound images. Algorithm 3 Image-level information based annotation decomp osition 1: function Annot a tionDecomposition3 ( y i ∈ { 1 , 2 , . . . , K } m × n ) 2: y single obj i ← a new array of size m × n with all 0; 3: y multiple obj i ← a new array of size m × n with all 0; 4: if y i con tains only one ob ject then 5: y single obj i ← y i 6: if y i con tains m ultiple ob jects then 7: y multiple obj i ← y i 8: return y single obj i and y multiple obj i 2.2 The K -to-1 deep netw ork for decompose-and-integrate learning Supp ose every original annotation map y i , i = 1 , 2 , . . . , h , is decomp osed into K annotation maps y k i , i = 1 , 2 , . . . , h and k = 1 , 2 , . . . , K . W e aim to model eac h sub-segmen tation problem using a deep learning segmentation module with its o wn set of parameters. Then another mo deling pro cedure is applied on top of these K mo dules to form the final solution of the original segmen tation problem. Th us, w e propose a new K -to-1 deep net work framew ork for implemen ting our ab o ve decompose-and-integrate learning scheme. Fig. 3 shows an ov erview of our K -to-1 deep net work. The mo dules (e.g., Seg-Mo dule 1.1, Seg-Mo dule 2) used in this netw ork can b e changed according to the type of images (e.g., 2D or 3D images) of the sp ecific segmentation problem. The full mo del can b e trained 6 T able 1. Comparison of segmentation results on the HVSMR dataset. Method Myocardium Bloo d p ool Overall score Dice ADB Hausdorff Dice ADB Hausdorff 3D U-Net [5] 0 . 694 1 . 461 10 . 221 0 . 926 0 . 940 8 . 628 − 0 . 419 V oxResNet [2] 0 . 774 1 . 026 6 . 572 0 . 929 0 . 981 9 . 966 − 0 . 202 DenseV oxNet [12] 0 . 821 0 . 964 7 . 294 0 . 931 0 . 938 9 . 533 − 0 . 161 Ensemble Meta-learner [13] 0.823 0.685 3.224 0.935 0.763 5.804 0.215 Class-AD + K -to-1 DenseV oxNet ( ours ) 0 . 839 0 . 744 3 . 500 0 . 941 0 . 658 5 . 973 0 . 223 Ablation Study: Large DenseV oxNet 0 . 804 0 . 847 3 . 980 0 . 935 0 . 756 7 . 706 0 . 079 2-stack ed DenseV oxNet 0 . 837 0 . 797 3 . 405 0 . 939 0 . 629 7 . 529 0 . 167 K -to-1 DenseV oxNet w/o AD 0 . 824 0 . 776 3 . 619 0 . 940 0 . 677 6 . 632 0 . 177 in end-to-end manner. Let the function of the o v erall K -to-1 net work be denoted as f complete , and the function of Seg-Mo dule 1 .k be denoted as f 1 .k . The o verall loss for the decomp ose-and-in tegrate learning sc heme is defined as: 1 h h X i =1 ( L ( f complete ( x i ) , y i ) + λ K X k =1 L ( f 1 .k ( x i ) , y k i )) (1) where L is the spatial cross entrop y loss, and λ is set as simple as a nor- malization term 1 K . W e aim to minimize the ab o ve function with resp ect to the parameters of f complete and f 1 .k for k = 1 , 2 , . . . , K . 3 Exp erimen ts and Results W e conduct exp erimen ts on three datasets. The 3D cardiov ascular segmentation dataset [7] contains t wo classes of foreground ob jects (my o cardium and great v essels), which ha v e close spatial relations. Thus, w e apply ob ject-class based annotation decomposition (AD) to this dataset. The gland segmen tation dataset [9] con tains glands that ha ve quite different shapes (from concav e shap e to con vex shap e); hence shap e conv exity based annotation decomp osition (AD) is applied to this dataset. Our in-house lymph no de dataset contains the lymph node areas of 237 patients in ultrasound images (one image may con tain one or more lymph no des). Thus, image-level information based AD is applied to this dataset. Implemen tation details. The input window size of the deep learning seg- men tation mo dels w e use is set as 64 × 64 × 64 for 3D exp eriments and 192 × 192 for 2D exp erimen ts. During training, random cropping, rotation, and flipping are applied. Since the images in each dataset are larger than the mo del windo w size, there are virtually many more samples for mo del training than the num b er of images in each dataset. The Adam optimizer is used for mo del training. The mini-batc h size is set as 8. The maximum n umber of training iteration is set to 60000. W e find that usually 60000 iterations using Adam are sufficient for an F CN-type mo del to con verge for a mo derate sized training set. The learning rate is set as 0.0005 initially , and decreased to 0.00005 after 30000 iterations. 3D cardio v ascular segmen tation in MR images. The HVSMR dataset [7] seeks to segment m yocardium and great vessels (bloo d p ool) in 3D cardio v as- 7 T able 2. Comparison of segmentation results on the gland segmentation dataset. Method F 1 Score Ob jectDice Ob jectHausdorff part A part B part A part B part A part B CUMedVision [4] 0.912 0.716 0.897 0.718 45.418 160.347 Multichannel2 [11] 0.893 0.843 0.908 0.833 44.129 116.821 MILD-Net [6] 0.914 0.844 0.913 0.836 41.54 105.89 CUMedNet [3] + 0.907 ± 0.007 0.835 ± 0.009 0.893 ± 0.007 0.832 ± 0.008 49.97 ± 2.12 113.40 ± 7.22 Shape-AD + K -to-1 (ours) 0.923 ± 0.002 0.861 ± 0.004 0.910 ± 0.004 0.846 ± 0.001 40.79 ± 1.72 101.42 ± 1.49 Ablation Study: Large CUMedNet + 0.918 ± 0.005 0.817 ± 0.021 0.903 ± 0.002 0.827 ± 0.012 43.81 ± 1.39 109.43 ± 5.39 2-stack ed CUMedNet + 0.914 ± 0.002 0.830 ± 0.009 0.908 ± 0.001 0.844 ± 0.002 45.32 ± 1.05 101.43 ± 2.25 K -to-1 w/o AD 0.915 ± 0.007 0.829 ± 0.008 0.898 ± 0.007 0.831 ± 0.004 45.23 ± 3.71 108.92 ± 4.74 cular MR images. The ground truth of the test data is not av ailable to the public; the ev aluations are done by submitting segmentation results to the organizers’ serv er. W e exp erimen t with the ob ject class based AD for this dataset. T able 1 sho ws that our AD combined with K -to-1 netw ork (utilizing DenseV o xNets) ac hieves state-of-the-art p erformance on this dataset. In the ablation study part of T able 1, we compare our full mo del with K-to-1 netw ork without AD (where y k i = y i , i = 1 , 2 , . . . , h , and k = 1 , 2 , . . . , K ), a 2-stac ked DenseV oxNets, and a large-size DenseV oxNet that uses a similar amount of parameters as the K - to-1 DenseV oxNets. The ablation study results confirm the effectiveness of our decomp ose-and-in tegrate learning sc heme. Gland segmentation in H&E stained images. This dataset [9] contains 85 training images (37 b enign (BN), 48 malignan t (MT)), 60 testing images (33 BN, 27 MT) in part A, and 20 testing images (4 BN, 16 MT) in part B. W e mo dify the original CUMedNet [3] to mak e it deeper with t wo more enco ding and deco ding blo c ks (denoted as CUMedNet + ). W e run all the experiments for the K -to-1 netw ork and ablation study 5 times. T able 2 sho ws the mean p erformance and standard deriv ations. Compared with the state-of-the-art models, our AD + K -to-1 net work (utilizing CUMedNet + ) yields considerably b etter segmentation results. In ablation study (the b ottom part of T able 2), we compare AD + K - to-1 netw ork with K -to-1 netw ork without AD, a 2-stac ked CUMedNet + , and a large-size CUMedNet + . Lymph node segmentation in ultrasound images. W e collected pa- tien ts’ lymph node ultrasound images. W e use 137 images for mo del training, and 100 images for mo del testing. The image size is 1080 × 768. There is no iden tity ov erlap betw een the training data and testing data. The AD proce- dure follows Algorithm 3. T able 3 demonstrates that AD + K -to-1 net work can effectiv ely improv e lymph node segmentation performance in ultrasound images. 4 Conclusions In this pap er, we developed a new decomp ose-and-integrate learning sc heme for medical image segmen tation. Our new learning scheme is well motiv ated, sound, and quite flexible. Comprehensiv e exp erimen ts on m ultiple datasets sho w that our new learning sc heme is effective in improving segmen tation p erformance. 8 T able 3. Comparison of segmen tation results on the lymph no de segmentation dataset. Method IoU Precision Recall F 1 Score U-Net [8] 0.661 0.834 0.7607 0.7957 Deeper U-Net 0.7369 0.8555 0.8416 0.8485 CUMedNet [3] + 0.7595 0.8472 0.8801 0.8633 Image-level-AD + K -to-1 ( ours ) 0.8102 0.9012 0.8893 0.8952 Ablation Study: Large CUMedNet + 0.7795 0.8808 0.8714 0.8761 2-stack ed CUMedNet + 0.7759 0.876 0.8716 0.8738 K -to-1 w/o AD 0.7842 0.8798 0.8783 0.8790 References 1. Bai, M., Urtasun, R.: Deep w atershed transform for instance segmen tation. In: CVPR. pp. 5221–5229 (2017) 2. Chen, H., Dou, Q., Y u, L., Qin, J., Heng, P .A.: V oxResNet: Deep v oxelwise residual net works for brain segmen tation from 3D MR images. NeuroImage 170, 446–455 (2018) 3. Chen, H., Qi, X., Cheng, J.Z., Heng, P .A.: Deep contextual netw orks for neuronal structure segmentation. In: AAAI. pp. 1167–1173 (2016) 4. Chen, H., Qi, X., Y u, L., Heng, P .A.: DCAN: Deep con tour-aw are net works for accurate gland segmentation. In: CVPR. pp. 2487–2496 (2016) 5. C ¸ i¸ cek, ¨ O., Ab dulk adir, A., Lienk amp, S.S., Bro x, T., Ronneberger, O.: 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In: MICCAI. pp. 424–432 (2016) 6. Graham, S., Chen, H., Dou, Q., Heng, P .A., Ra jpo ot, N.: MILD-Net: Minimal information loss dilated net work for gland instance segmen tation in colon histology images. arXiv preprint arXiv:1806.01963 (2018) 7. P ace, D.F., Dalca, A.V., Gev a, T., Po well, A.J., Moghari, M.H., Golland, P .: In- teractiv e whole-heart segmen tation in congenital heart disease. In: MICCAI. pp. 80–88 (2015) 8. Ronneb erger, O., Fisc her, P ., Brox, T.: U-Net: Con volutional net works for biomed- ical image segmentation. In: MICCAI. pp. 234–241 (2015) 9. Sirin ukunw attana, K., Pluim, J.P ., Chen, H., Qi, X., Heng, P .A., Guo, Y.B., W ang, L.Y., Matuszewski, B.J., Bruni, E., et al.: Gland segmentation in colon histology images: The GlaS challenge con test. Medical Image Analysis 35, 489–502 (2017) 10. Uhrig, J., Cordts, M., F ranke, U., Bro x, T.: Pixel-lev el encoding and depth la yering for instance-lev el seman tic labeling. In: German Conference on Pattern Recogni- tion. pp. 14–25 (2016) 11. Xu, Y., Li, Y., Liu, M., W ang, Y., F an, Y., Lai, M., Chang, E.I., et al.: Gland instance segmentation by deep m ultichannel neural net works. arXiv preprin t arXiv:1607.04889 (2016) 12. Y u, L., Cheng, J.Z., Dou, Q., Y ang, X., Chen, H., Qin, J., Heng, P .A.: Automatic 3D cardio v ascular MR segmen tation with densely-connected v olumetric ConvNets. In: MICCAI. pp. 287–295 (2017) 13. Zheng, H., Zhang, Y., Y ang, L., Liang, P ., Zhao, Z., W ang, C., Chen, D.Z.: A new ensemble learning framework for 3D biomedical image segmen tation. arXiv preprin t arXiv:1812.03945 (2018)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment