인간 AI 팀을 위한 역호환성 확보
본 논문은 인간‑AI 협업에서 AI 모델이 업데이트될 때 사용자가 기존에 형성한 신뢰 모델과의 일치성을 ‘호환성’이라고 정의하고, 호환성을 고려한 재학습 손실 함수를 제안한다. 실험을 통해 호환성이 낮은 업데이트가 팀 성과를 저하시킬 수 있음을 확인하고, 새로운 손실을 적용하면 성능과 호환성 사이의 트레이드오프를 조절할 수 있음을 보인다.
저자: Gagan Bansal, Besmira Nushi, Ece Kamar
본 논문은 인간‑AI 팀이 고위험 의사결정 상황에서 어떻게 협업해야 하는지를 탐구한다. 인간은 AI가 제시한 예측을 검토하고 최종 행동을 선택하는 “AI‑advised human decision making” 구조를 가정한다. 이때 인간은 반복적인 피드백을 통해 AI의 신뢰 구역을 학습하고, 어느 상황에서 AI를 따르고 언제 오버라이드할지를 판단한다. 그러나 AI 모델이 업데이트될 경우, 이전에 신뢰를 얻었던 구역에서 새로운 오류가 발생하면 인간의 정신 모델이 깨져 팀 성과가 급격히 떨어질 위험이 있다.
이를 해결하기 위해 저자는 **호환성(compatibility)** 개념을 도입한다. **지역적 호환성**은 특정 사용자의 정신 모델 m(x) 에 기반해, 사용자가 이전 모델 h₁ 을 신뢰하고 올바른 행동을 기대한 입력 x 에 대해 업데이트된 모델 h₂ 도 동일하게 올바른 행동을 제공해야 함을 의미한다. **전역적 호환성**은 모든 입력에 대해 h₁ 이 올바른 행동을 제시하면 h₂ 도 반드시 동일하게 행동해야 하는 강력한 조건이다. 전역적 호환성을 만족하기는 현실적으로 어렵기 때문에, 저자는 **호환성 점수(C)** 를 정의해 h₁ 이 맞춘 사례 중 h₂ 가 그대로 맞춘 비율을 측정한다. C=1이면 완전 호환, C=0이면 전부 새로운 오류를 만든다.
전통적인 교차 엔트로피 손실 L 은 라벨 y 와 예측 확률 p(h(x)) 만을 고려해, 이전 모델과의 관계를 전혀 반영하지 않는다. 따라서 재학습 시 새로운 오류가 쉽게 발생한다. 이를 보완하기 위해 **불협화음(dissonance) 손실 D** 를 도입한다. D는 h₁ 이 정답인 경우에만 h₂ 의 손실을 가중치 λ_c 와 함께 추가한다. 즉, h₁ 이 맞춘 입력에서 h₂ 가 틀리면 큰 페널티를 부과한다. 전체 손실 L_c = L + λ_c·D 을 최소화하면, 모델은 기존에 올바르게 동작하던 영역을 유지하면서 새로운 데이터를 학습한다.
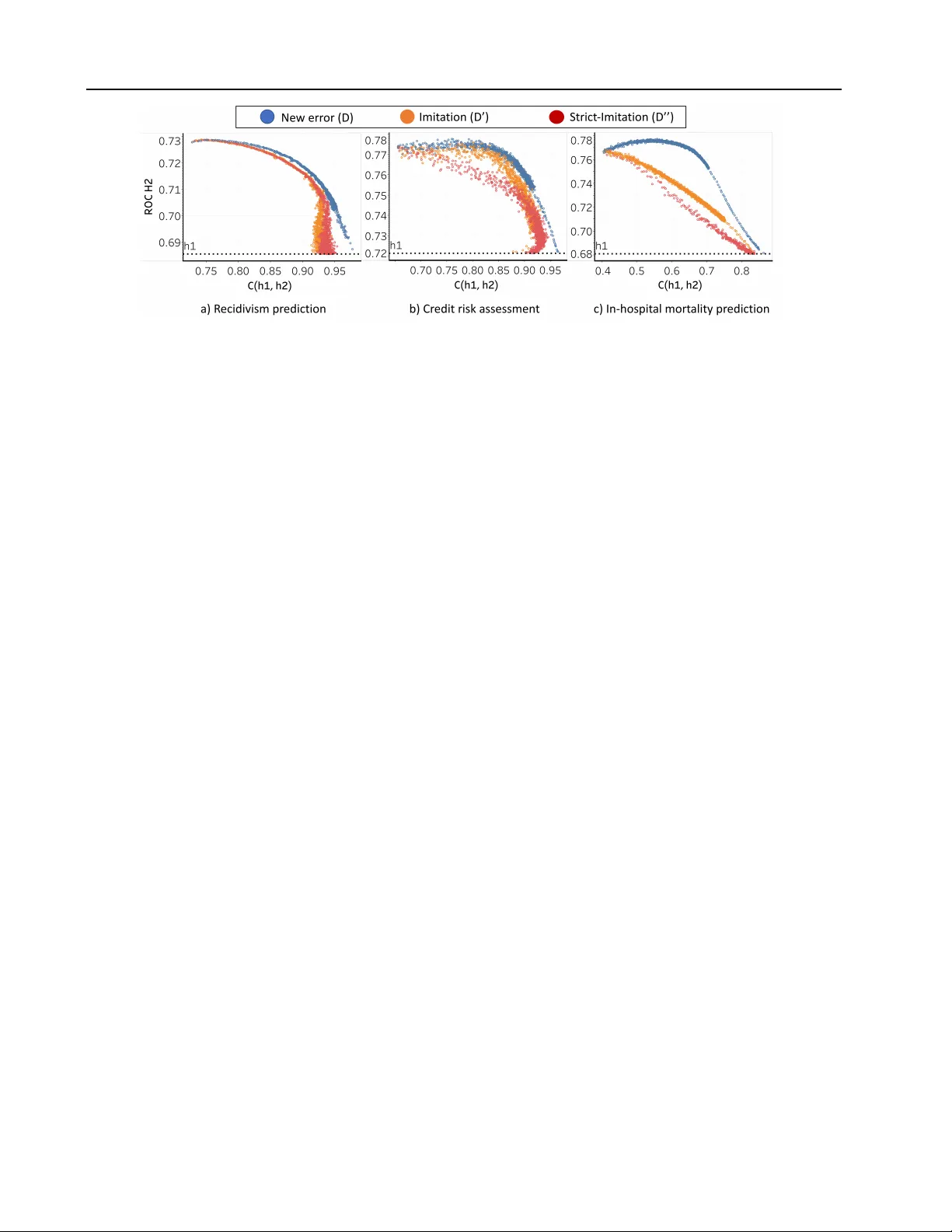
불협화음의 변형으로 **모방(imitation) 불협화음** 과 **엄격 모방(strict imitation) 불협화음** 을 제시한다. 전자는 h₁ 과 h₂ 의 확률 분포 전체를 최소화해 h₁ 의 실수까지 모방할 위험이 있다. 후자는 h₁ 이 정답인 경우에만 확률 차이를 최소화해, 호환성을 보다 정확히 보장한다.
실험은 두 단계로 진행된다. 첫 번째는 MTurk 작업자를 대상으로 만든 **CAJA** 라는 웹 기반 게임에서, 초기 AI 정확도 80% → 85% 로 상승시키는 업데이트를 적용하고, 오류 경계(error boundary)를 동일, 호환, 비호환 세 조건으로 나누어 팀 점수를 측정했다. 결과는 호환 업데이트가 팀 성과를 크게 향상시킨 반면, 비호환 업데이트는 정확도 상승에도 불구하고 팀 점수를 감소시켰다. 이는 인간이 기존 모델에 대한 신뢰를 잃고 잘못된 결정을 내리게 함을 보여준다.
두 번째 실험에서는 실제 고위험 데이터셋(재소자 재범 예측, 병원 내 사망률 예측, 신용 위험 평가)을 사용해 기존 모델 h₁ 과 새 모델 h₂ 사이의 호환성 점수를 계산하고, λ_c 값을 조절한 L_c 학습을 수행했다. 호환성을 강조한 학습은 약간의 정확도 손실을 감수하면서도 새로운 오류를 현저히 줄였으며, 사용자가 기존 모델에 대한 신뢰를 유지할 수 있게 했다.
결론적으로, AI 시스템을 업데이트할 때는 **성능 향상만을 목표로 하지 말고, 인간 사용자가 이미 구축한 신뢰 모델과의 호환성을 함께 고려해야** 한다는 점을 강조한다. 제안된 L_c 손실은 기존 딥러닝 프레임워크에 쉽게 통합 가능하며, λ_c 조정을 통해 성능‑호환성 트레이드오프를 자유롭게 탐색할 수 있다. 이는 의료, 법률, 자율주행 등 인간‑AI 협업이 필수적인 분야에서 안전하고 신뢰성 있는 시스템 배포에 중요한 설계 원칙을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기