A Case for Backward Compatibility for Human-AI Teams
AI systems are being deployed to support human decision making in high-stakes domains. In many cases, the human and AI form a team, in which the human makes decisions after reviewing the AI's inferences. A successful partnership requires that the hum…
Authors: Gagan Bansal, Besmira Nushi, Ece Kamar
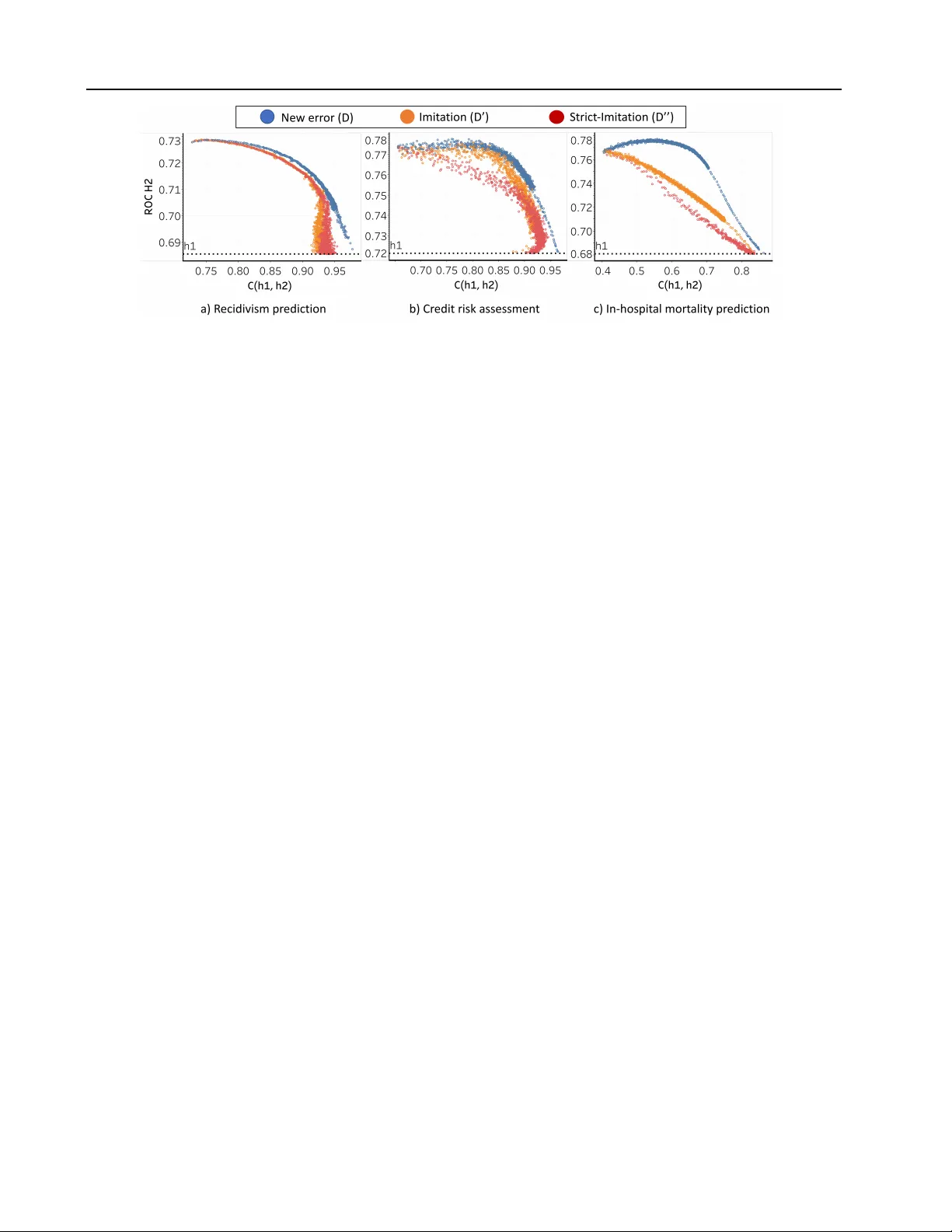
A Case f or Backward Compatibility f or Human-AI T eams Gagan Bansal 1 Besmira Nushi 2 Ece Kamar 2 Dan W eld 1 W alter Lasecki 3 Eric Horvitz 2 Abstract AI systems are being deployed to support human decision making in high-stakes domains. In many cases, the human and AI form a team, in which the human makes decisions after re viewing the AI’ s inferences. A successful partnership requires that the human de velops insights into the perfor- mance of the AI system, including its failures. W e study the influence of updates to an AI system in this setting. While updates can increase the AI’ s predictiv e performance, they may also lead to changes that are at odds with the user’ s prior experiences and confidence in the AI’ s inferences, hurting therefore the overall team performance . W e introduce the notion of the compatibility of an AI update with prior user experience and present methods for studying the role of compatibility in human-AI teams. Empirical results on three high-stakes domains show that current machine learning algorithms do not produce compatible updates. W e propose a re-training objecti ve to im- prov e the compatibility of an update by penalizing new errors. The objectiv e offers full le verage of the performance/compatibility tradeof f, enabling more compatible yet accurate updates. 1. Introduction A promising opportunity in AI is dev eloping systems that can partner with people to accomplish tasks in ways that exceed the capabilities of either individually ( W ang et al. , 2016 ; Kamar , 2016 ; Gaur et al. , 2016 ). W e see many mo- tiv ating examples: a doctor using a medical expert sys- tem ( W ang et al. , 2016 ), a judge advised by a recidi vism predictor , or a dri ver supervising a semi-autonomous ve- hicle. Despite rising interest, there is much to learn about creating effecti ve human-AI teams and what capabilities AI systems should employ to be competent partners. 1 Univ ersity of W ashington 2 Microsoft Research 3 Univ ersity of Michigan. Correspondence to: Gagan Bansal < bansalg@cs.washington.edu > . 2019 ICML W orkshop on Human in the Loop Learning (HILL 2019) , Long Beach, USA. Copyright by the author(s). W e study human-AI teams in decision-making settings where a user takes action recommendations from an AI partner for solving a complex task. The user considers the recommendation and, based on previous experience with the system, decides to accept the suggested action or take a different action. W e call this type of interaction AI-advised human decision making . The moti vation for AI-advised human decision making comes from the fact that humans and machines hav e complementary abilities ( W ang et al. , 2016 ; Kamar et al. , 2012 ) and that AI assistance can speed up decision making when humans can correctly identify when the AI can be trusted ( Lasecki et al. , 2012a ; b ). It might be expected that improv ements in the performance of AI systems lead to stronger team performance, but, as with human groups, indi vidual ability is only one of man y factors that af fect team effecti veness ( DeChurch & Mesmer- Magnus , 2010 ; Grosz , 1996 ). In f act, the success of the team hinges on the human correctly deciding when to follow the recommendation of the AI system and when to override. If the human mistakenly trusts the AI system in regions where it is likely to err , catastrophic failures may occur . Human- AI teams become especially susceptible to such failures because of discrepancies introduced by system updates that do not account for human expectations. The following example illustrates this situation. Example (P A T I E N T R E A D M I S S I O N ) . A doctor uses an AI system that is 95% accurate at predicting whether a pa- tient will be r eadmitted following their dischar ge to make decisions about enlisting the patient in a supportive post- dischar ge pr ogr am. The special pr ogram is costly but pr omises to r educe the likelihood of r eadmission. After a year of interacting with the AI, the doctor develops a clear mental model that sugg ests she can trust the AI-advised actions on elderly patients. In the meantime, the AI’ s devel- oper deploys a new 98% accurate classifier , which errs on elderly patients. While the AI has impr oved by 3%, the doc- tor is unawar e of the new err ors and might take the wr ong actions for some elderly patients. This example is motiv ated by real-world applications for reducing patient readmissions and other costly outcomes in healthcare ( Bayati et al. , 2014 ; Caruana et al. , 2015 ), and motiv ates the need for reducing the cost of disruption caused by updates that violate users’ mental models. Similar challenges are observed in other human-AI collaboration A Case for Backward Compatibility f or Human-AI T eams scenarios such as during ov er-the-air updates in the T esla autopilot ( O’Cane , 2018 ), and are present in a variety of other settings when AI services consumed by third-party ap- plications, are updated. Despite these problems, dev elopers almost exclusi vely optimize for AI performance. Retraining techniques largely ignore important details about human-AI teaming, and the mental model that humans de velop from interacting with the system. The goal of this work is to make the human factor a first-class consideration of AI updates. In summary , we make the follo wing contributions: • W e define the notion of compatibility of an AI update with the user’ s mental model created from past experi- ence. W e then propose a practical adjustment to current ML (re)training algorithms — an additional differentiable term to the logarithmic loss — that improves compatibil- ity during updates, and allo ws dev elopers to explore the performance/compatibility tradeoff. • W e introduce an open-source e xperimental platform for studying (i) ho w people model the error boundary of an AI teammate for an AI-advised decision-making task, and (ii) how the y adapt to updates. • Using the platform, we perform user studies sho wing that updating an AI to increase accuracy , at the expense of compatibility , may de grade team performance. Moreov er, experiments on three high-stakes classification tasks (re- cidivism prediction, in-hospital mortality prediction, and credit-risk assessment) demonstrate that: (i) current ML models are not inherently compatible, but (ii) flexible performance/compatibility tradeoffs can be ef fectiv ely achiev ed via a reformulated training objective. 2. AI-Advised Human Decision Making In our studies, we focus on a simple, but common, model of human-AI teamwork that abstracts man y real-world set- tings, in which ML models support a human decision-mak er . In this setting, which we call AI-advised human decision making , an AI system pro vides a r ecommendation , but the human makes the final decision . The team solves a sequence of tasks, repeating the following c ycle for each time, t . S1: The en vironment provides an input, x t . S2: The AI (possibly mistaken) suggests an action, h ( x t ) . S3: Based on this input, the human makes her decision, u t . S4: The en vironment returns a reward, r t , which is a func- tion of the user’ s action, the (hidden) best action, and other costs of the human’ s decision (e.g., time taken). While interacting over multiple tasks, the team receives repeated feedback about performance, which lets the human learn when she can trust the AI’ s answers. The cumulativ e rew ard R ov er T cycles records the team’ s performance. 2.1. T rust as a Human’ s Mental Model of the AI Just as for other automated systems ( Norman , 1988 ), hu- mans create a mental model of AI agents ( Kulesza et al. , 2012 ). In AI-advised human decision making, v alid mental models of the reliability of the AI output impro ve collabo- ration by helping the user to know when to trust the AI’ s recommendation. A perfect mental model of the AI sys- tem’ s reliability could be harnessed to achie ve the highest team performance. A simple definition for such a model would be m : x → { T , F } , indicating which inputs the human trusted the AI to solve correctly . In reality , mental models are not perfect ( Norman , 2014 ): users develop them through limited interaction with the system, and people hav e cognitiv e limitations. Despite this, users learn and ev olve a model of an AI system’ s competence over the course of many interactions. In the full version of this paper ( Bansal et al. , 2019 ), we sho w that these models can greatly improv e team performance. In this study , we focus on the problem of updating an AI system in a way that it remains compatible with users’ expectations. 3. Compatibility of Updates to Classifiers In software engineering, an update is backwar d compatible if the updated system can support legac y software. By analogy , we define that an update to an AI component is locally compatible with a user’ s mental model if it does not introduce ne w errors and the user , even after the update, can safely trust the AI’ s recommendations. Definition (L O C A L L Y - C O M PA T I B L E U P D A T E ) . Let m ( x ) denote a mental model that dictates the user’ s trust of the AI on input x . Let A ( x, u ) denote whether u is the appr opriate action for input x . An update, h 2 , to a learned model, h 1 , is locally compatible with m if f ∀ x, [ m ( x ) ∧ A ( x, h 1 ( x ))] ⇒ A ( x, h 2 ( x )) In other words, an update is compatible only if, for ev ery input where the user trusts the AI and h 1 recommends the correct action, the updated model, h 2 , also recommends the correct action. In the rest of this paper, we focus on situations where a classifier’ s predictions are actions. For instance, in the patient readmission e xample, if a classifier predicts that the patient will be readmitted in the next 30 days, the suggested action from the classifier would be to include the patient in a special post-discharge program. 3.1. Globally Compatible Updates When de velopers are b uilding an AI system that is used by many indi viduals, it may be too difficult to track indi vidual mental models or to deploy dif ferent updated models to different users. In this situation, an alternative to creating locally compatible updates, is a globally compatible update . A Case for Backward Compatibility f or Human-AI T eams Definition (G L O B A L L Y - C O M PA T I B L E U P DAT E ) . An up- dated model, h 2 , is globally compatible with h 1 , iff ∀ x, A ( x, h 1 ( x )) ⇒ A ( x, h 2 ( x )) Note that a globally compatible update is locally compatible for any mental model. While global compatibility is a nice ideal, satisfying it for all instances is difficult in practice. More realistically , we seek to minimize the number of er- rors made by h 2 that were not made by h 1 , since that will hopefully minimize confusion among users. T o mak e this precise, we introduce the notion of a compatibility scor e . Definition (C O M PA T I B I L I T Y S C O R E ) . The compatibility scor e C of an update h 2 to h 1 is given by the fraction of examples on which h 1 r ecommends the correct action, h 2 also r ecommends the corr ect action. C ( h 1 , h 2 ) = P x A ( x, h 1 ( x )) · A ( x, h 2 ( x )) P x A ( x, h 1 ( x )) (1) If h 2 introduces no new errors, C ( h 1 , h 2 ) will be 1. Con- versely , if all the errors are ne w , the score will be 0. 3.2. Dissonance and Loss T o train classifiers, ML de velopers optimize for the predic- ti ve performance of h 2 by minimizing a classification loss L that penalizes low performance. The equation below sho ws the negativ e logarithmic loss for binary classification – a commonly used training objectiv e in ML. L ( x, y, h 2 ) = y · log p ( h 2 ( x )) + (1 − y ) · log (1 − p ( h 2 ( x ))) Here, the probability p ( h ( x )) denotes the confidence of the classifier that recommendation h ( x ) is true, while y is the true label for x ( i.e. , A ( x, y ) = T rue ). The negati ve log loss, like man y other loss functions in machine learning, depends only on the true label and the confidence in prediction – it ignores the previous versions of the classifier and, hence, has no preference for compatibility . As a result, retraining using different data can lead to very different hypotheses, introduce ne w errors, and decrease the compatibility score. T o alle viate this problem, we define a new loss function L c expressed as the sum of classification loss and dissonance . Definition (D I S S O N A N C E ) . The dissonance D of h 2 to h 1 is a function D : x, y , h 1 , h 2 → R that penalizes a low compatibility scor e. Furthermor e, D is differ entiable. D ( x, y, h 1 , h 2 ) = 1 ( h 1 ( x ) = y ) · L ( x, y , h 2 ) (2) Recall that C ( h 1 , h 2 ) is high when both h 1 and h 2 are cor- rect (Eqn 1 ). Dissonance expresses the opposite notion: measuring if h 1 is correct ( 1 denotes an indicator function) and penalizing by the de gree to which h 2 is incorrect. Equa- tion 3 defines the new loss. L c = L + λ c · D (3) Figure 1. C A JA platform for studying human-AI teams. Here, λ c encodes the relativ e weight of dissonance, control- ling the additional loss to be assigned to all new errors. W e refer to this version as ne w-err or dissonance . Just as with classification loss, there are other ways to realize dissonance. W e e xplored two alternati ves, which we refer to as imitation and strict imitation dissonance. Eqn 4 describes the imita- tion dissonance which measures the log loss between the prediction probabilities of h 1 and h 2 : D 0 ( x, y, h 1 , h 2 ) = L ( x, h 1 , h 2 ) (4) Eqn 4 is used in model distillation ( Ba & Caruana , 2014 ; Hinton et al. , 2015 ), where the aim is to train a shallower , less expensi ve model by imitating the probabilities of larger , accurate model. Unfortunately , D 0 has the effect of nudging h 2 to mimic h 1 ’ s mistakes as well as its successes. Eqn 5 describes the strict imitation dissonance, which follows a similar intuition but it only adds the log loss between h 1 and h 2 when h 1 is correct. D 00 ( x, y, h 1 , h 2 ) = 1 ( h 1 ( x ) = y ) · L ( x, h 1 , h 2 ) (5) 4. Platf orm for Studying Human-AI T eams How might we study the impact of AI accuracy , updates, compatibility , and mental models on the performance of AI- advised human decision making teams? Ideally , we would conduct user studies in real-world settings, varying parame- ters like the length of interaction, task and AI complexity , rew ard function, and the AI’ s behavior . Ho wev er , testing in real settings reduces or remov es our ability to directly con- trol the performance of the AI and it may largely measure experts’ dif fering e xperience in the domain, rather than their interactions with the AI. T o control for human e xpertise and the centrality of mental modeling, we de veloped the C A JA platform, which supports parameterized user studies in an assembly line domain that abstracts away the specifics of problem solving and focuses on understanding the ef fect of mental modeling on team success. C A JA is designed A Case for Backward Compatibility f or Human-AI T eams Accept Compute AI right $0.04 0 AI wrong -$0.16 0 T able 1. Rew ard matrix for the user studies. T o mimic high-stakes domains, penalty for mistakes is set to high. such that no human is a task expert (nor can they become one). In fact, the true label of decision problems is randomly generated so that people cannot learn how to solve the task. Howe ver , humans can learn when their AI assistant, Marvin, succeeds and when it errs. Alongside, the human has access to a perfect problem-solving mechanism, which she can use (at extra cost) when she does not trust Marvin. C A JA is a web-based game, whose goal is to make classi- fication decisions for a fixed number of box-like objects. For each object, the team follo ws the steps S1-S4 to decide whether the object is “defectiv e” or not. In S1 a ne w object appears ( e.g . , blue square), in S2 the AI recommends a label ( e.g . , not-defecti ve), in S3 the player chooses an action ( e.g . , accept or reject the AI recommendation), and in S4 the UI returns a re ward and increments the game score. The objects are composed of many features, b ut only a subset of them are made human-visible . For example, visual properties lik e shape, color , and size are visible, b ut the contents are not. In contrast, the AI has access to all the features but may make errors. At the be ginning of the game, users hav e no mental model of the AI’ s error boundary . Howe ver , to achieve high scores, they must learn a model using feedback from step S4. Figure 1 sho ws a screenshot of the game at step S3. C A JA allo ws study designers to vary parameters, such as the number of objects, number human-visible features, re ward function, AI accuracy , and complexity of perfect mental model (number of clauses and literals in the error boundary and stochasticity of errors). Further , it enables one to study the effects of updates to AI by allowing changes to these parameters at any time step. In the ne xt section, we use C A JA to answer various research questions. 5. Experiments W e present e xperiments and results in two parts. First, using our platform, we conduct user studies to understand the im- pact of updates on team performance. Second, we simulate updates for three real-world, high-stakes domains and sho w how the retraining objectiv e enables an explorable tradeof f between compatibility and performance. 5.1. User Studies In user studies, we hired MT urk workers and directed them to the C A JA platform. The task of workers was to form a team with an AI, named Marvin, and label a set of objects as “defective” or “not defecti ve”. F ollowing AI-advised Cycles learning stabi lit y update dis ruption (re)learning stabi lit y Update style same error bounda ry compati ble error boun dary incompatible error boundary t "#$%&' no update Score Figure 2. T eam performance for different update settings. Com- patible updates improve team performance, while incompatible updates hurt team performance despite improv ements in AI accu- racy . human decision making, to label an object, a worker can either accept Marvin’ s recommendation, which is initially correct 80% of the time, or use the “compute” option, which is a surrogate for the human doing the task herself perfectly but incurring an opportunity cost. T able 1 summarizes the reward function used in our studies. The matrix is designed in a way that it imitates a high-stak es scenario, i.e., the monetary penalty for a wrong decision is much higher than the reward for a correct decision. Note that the expected value of a naiv e strategy ( e.g . , always “Compute” or always “ Accept, ” without considering the like- lihood of Marvin’ s correctness) is zero. The only way to get a higher score is by learning when to trust Marvin by playing the game. An error boundary , f , is expressed as a conjunction of literals. For example, one possible error boundary w ould be f = ( bl ue ∩ sq uar e ) , which means that Marvin errs at all objects that are blue and ha ve a squared shape. Since many features can be used as literals, we chose them randomly to create isomorphic error boundaries. In the full paper ( Bansal et al. , 2019 ), we show that it is easier for workers to create a mental model for boundaries that hav e fewer literals and are not stochastic . Next, we show results from experiments that introduce updates. Q1: Do mor e compatible updates lead to higher team per - formance than incompatible updates? T o study the impact of updates, we set the number of cy- cles to 150, and at the 75th c ycle, update the classifier to a version that is 5% more accurate (80% → 85%). Then, we di vide the participants into three groups: same error boundary , compatible error boundary , and incompatible er - ror boundary . The same error boundary group recei ves an update improving accuracy , but the error boundary is un- A Case for Backward Compatibility f or Human-AI T eams Classifier Dataset R OC h 1 R OC h 2 C ( h 1 , h 2 ) LR Recidivism 0.68 0.72 0.72 Credit Risk 0.72 0.77 0.66 Mortality 0.68 0.77 0.40 MLP Recidivism 0.59 0.73 0.53 Credit Risk 0.70 0.80 0.63 Mortality 0.71 0.84 0.76 T able 2. Although training on more data increases classifier per- formance, compatability can be suprisingly low . changed. For the two other groups, the number of literals (features) in the error boundary changes from tw o to three. The update for the compatible error boundary group intro- duces no ne w errors; for example, if before the update the error boundary was blue ∩ sq uare , after the update it may change to small ∩ bl ue ∩ sq uar e . For the incompatible error boundary group, the error boundary introduces new errors violating compatibility . Figure 2 summarizes our re- sults. W e also show the performance of work ers if no update was introduced (dashed line). The graph demonstrates two main findings on the importance of compatibility . First, a more accurate but incompatible classifier results in lower team performance than a less accurate but compatible class- ifier (no update) because workers have to relearn the new incompatible error boundary . Second, compatible updates improv e team performance. Moreov er , the figure shows different stages during the interaction: the user learning the original error boundary , team stabilizes, update causes disruption, and performance stabilizes again. 5.2. Experiments with High-Stakes Domains Datasets. T o inv estigate whether a tradeof f exists between performance and compatibility of an update, we simulate updates to classifiers for three domains: recidivism predic- tion (W ill a con vict commit another crime?) ( Angwin et al. , 2016 ), in-hospital mortality prediction (W ill a patient die in the hospital?) ( Johnson et al. , 2016 ; Harutyun yan et al. , 2017 ), and credit risk assessment (W ill a borrower fail to pay back?) 1 . W e selected these high-stakes domains to high- light the potential cost of mistakes caused by incompatible updates in human-AI teams. Q2: Do ML classifiers pr oduce compatible updates? For this experiment, we first train a classifier h 1 on 200 examples and note its performance. Next, we train another classifier h 2 on 5000 examples and note its performance and compatibility score. W e train both classifiers by minimizing the negati ve log loss. T able 2 shows the performance (area under R OC) and compatibility av eraged ov er 500 runs for logistic regression (LR) and multi-layer perceptron (MLP) classifiers. W e find that training h 2 by just minimizing log loss does not ensure compatibility . For e xample, for logistic regression and the in-hospital mortality prediction task, the 1 https://community.fico.com/s/ explainable- machine- learning- challenge compatibility score is as low as 40%. That is, 60% of the instances where h 1 was correct are no w violated. Q3: Is ther e a tr adeoff between the performance and the compatibility of an update to AI? For Q3 (and Q4), we learn t he second classifier h 2 by min- imizing L c . As L c depends also on the first classifier, we make its prediction av ailable to the learner . W e v ary λ c and summarize the resulting performance and compatibility scores across different datasets for the logistic re gression classifier in Figure 3 and for different definitions of disso- nance (the full paper also provides results for MLP). The figure shows that there e xists a tradeoff between the perfor - mance of h 2 and its compatibility to h 1 . This tradeoff is generally more flexible (flat) in the first half of the curves. This shows that, at the very least, one can choose to deploy a more compatible update without significant loss in accurac y . Although such updates are not fully compatible, they might still be rele vant to be picked by the dev eloper if the update is supported by efficient e xplanation techniques that can help users to better understand how the model has changed. In these cases, a more compatible update would also reduce the effort of user (re)training. In the second half, the tradeoff becomes more e vident. High compatibility can sacrifice pre- dictiv e performance. Look-up summaries similar to graphs shown in Figure 3 are an insightful tool for ML de velopers that can guide them select an accurate yet compatible model based on the specific domain requirements. Q4: What is the r elative performance of the differ ent disso- nance functions? Figure 3 compares the performance of the new-error dis- sonance function ( D ) with the imitation-based dissonances ( D 0 and D 00 ). As anticipated, D performs best on all three domains. The definitions inspired by model distillation, D 0 and D 00 , assume that h 1 is calibrated, and more accurate. Therefore, h 2 needs to remain faithful to only the correct regions of a less accurate model h 1 . If these assumptions are violated, h 2 ov erfits to non-calibrated confidence scores of h 1 , which hurts performance. 6. Discussion and Directions This work sho wed that backward compatibility is an essen- tial determinant of team performance, and dev elopers should factor it in system design supported by guiding tools e x- ploring the performance/compatibility tradeof f in a similar way as sho wn in Figure 3 . V arying λ c results in numerous models on the performance/compatibility spectrum. The decision to select the appropriate model depends on several factors, including the user ability to create a mental model, the cost of disruption, and the a vailability of other alternativ e approaches for minimizing disruption caused by updates. One such approach is to retrain the user , for example, by lev eraging mechanisms from interpretable AI to explain the A Case for Backward Compatibility f or Human-AI T eams Figure 3. Performance vs. compatibility for a logistic regression classifier . The reformulated training objective ( L c ) offers an e xplorable performance/compatibility tradeoff, generally more for giving during the first half of the curves. The training objecti ve based on new-error dissonance performs the best, whereas the ones based on imitiation and strict-imitation dissonance perform worse since they imitate probabilities of a less accurate, and less calibrated model ( h 1 ). updated model to users or to e xplain dif ferences between h 1 and h 2 . Howe ver , this may not always be practical: (1) in practice, dev elopers may push updates frequently , and since re-training requires users additional time and ef fort, it may not be practical to subject e xperts to repeated re-training; (2) updates can arbitrarily change the decision boundary of a classifier , and as a result, require the user to re-learn a large number of changes; (3) re-training requires the dev elopers to create an effecti ve curriculum or generate a change sum- mary based on the update. It is often impossible to compute such summaries in a human-interpretable way . Ne vertheless, backward compatibility does not preclude retraining; these techniques are complementary to each other . Another complementary approach is to share the AI’ s confi- dence in the prediction. W ell-calibrated confidence scores can help a user to decide when or ho w much to trust the sys- tem. Unfortunately , confidence scores of ML classifiers are often not calibrated ( Nguyen et al. , 2015 ) or a meaningful confidence definition may not exist. 7. Related W ork Prior fundamental work explored the importance of men- tal models for achie ving high performance in group work ( Grosz & Kraus , 1999 ), human-system collaboration ( Rouse et al. , 1992 ), and interface design ( Carroll & Olson , 1988 ). Our work b uilds upon these foundations and studies the problem for AI-advised human decision making. Pre vi- ous work ( Zhou et al. , 2017 ) in vestigated factors that af fect user-system trust, e.g., model uncertainty and cogniti ve load. The platform proposed in this work enables human studies that can analyze the effect of such f actors. The field of software engineering has initially studied the problem of backward compatibility , seeking to design com- ponents that remain compatible with a larger software ecosystem after updates ( Bosch , 2009 ; Spring , 2005 ). Ma- chine learning research has explored related notions. Sta- bility expresses the ability of a model to not significantly change its predictions giv en small changes in the training set ( Bousquet & Elisseef f , 2001 ). Consistency , which has ap- plication in ML fairness, is a property of smooth classifiers, which output similar predictions for similar instances ( Zhou et al. , 2004 ). Catastr ophic for getting is an anomalous be- havior of neural netw ork models that occurs when they are sequentially trained to perform multiple tasks and forget to solve earlier tasks over time ( Kirkpatrick et al. , 2017 ). While these concepts are fundamental for analyzing chang- ing trends in continuously learned models, they do not con- sider human-AI team performance nor prior user experience. Related to our proposed retraining objective is the idea of cost-sensitive learning ( Elkan , 2001 ), where dif ferent mis- takes may cost differently; for e xample, false positiv es may be especially costly . In our case, the cost also depends on the behavior of the pre vious model h 1 . 8. Conclusions W e studied how updates to an AI system can af fect human- AI team performance and introduced methods and mea- sures for characterizing and addressing the compatability of updates. W e introduced C A JA , a platform for measur- ing the effect of AI performance and the eff ect of updates on team performance. Since humans hav e no experience with C A J A ’ s abstract game, the platform controls for hu- man problem-solving skill, distilling the essence of mental models and trust in one’ s AI teammate. Using C A JA , we presented experiments demonstrating ho w an update that makes an AI component more accurate can still lead to di- minished human-AI team performance. W e introduced a practical re-training objectiv e that can improve the compati- bility of updates. Experiments across three data sets sho w that our approach creates updates that are more compatible, while maintaining high accurac y . Therefore, at the very least, a de veloper can choose to deplo y a more compatible model without sacrificing performance. A Case for Backward Compatibility f or Human-AI T eams References Angwin, J., Larson, J., Mattu, S., and Kirchner, L. Machine bias: There’ s softw are across the country to predict future criminals and its biased against blacks. Pr oPublica , 2016. Ba, J. and Caruana, R. Do deep nets really need to be deep? In NIPS , pp. 2654–2662, 2014. Bansal, G., Nushi, B., Kamar , E., W eld, D., Lasecki, W . S., and Horvitz, E. Updates in human-ai teams: Under- standing and addressing the performance/compatibility tradeoff. In Pr oceedings of the 33rd AAAI confer ence on Artificial Intelligence. AAAI , 2019. Bayati, M., Brav erman, M., Gillam, M., Mack, K. M., Ruiz, G., Smith, M. S., and Horvitz, E. Data-driv en deci- sions for reducing readmissions for heart f ailure: General methodology and case study . PloS one , 9(10):109264, 2014. Bosch, J. From softw are product lines to software ecosys- tems. In SPLC , pp. 111–119, 2009. Bousquet, O. and Elisseeff, A. Algorithmic stability and generalization performance. In NIPS , pp. 196–202, 2001. Carroll, J. M. and Olson, J. R. Mental models in human- computer interaction. In Handbook of human-computer interaction , pp. 45–65. Else vier, 1988. Caruana, R., Lou, Y ., Gehrke, J., K och, P ., Sturm, M., and Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In KDD , pp. 1721–1730. A CM, 2015. DeChurch, L. A. and Mesmer-Magnus, J. R. The cognitive underpinnings of effecti ve teamwork: A meta-analysis. Journal of Applied Psyc hology , 95(1):32, 2010. Elkan, C. The foundations of cost-sensitiv e learning. In IJCAI , volume 17, pp. 973–978. La wrence Erlbaum As- sociates Ltd, 2001. Gaur , Y ., Lasecki, W . S., Metze, F ., and Bigham, J. P . The ef fects of automatic speech recognition quality on human transcription latency . In Proceedings of the 13th W eb for All Confer ence (W4A) , pp. 23. A CM, 2016. Grosz, B. J. Collaborati ve systems (AAAI-94 presidential address). AI magazine , 17(2):67, 1996. Grosz, B. J. and Kraus, S. The ev olution of sharedplans. In F oundations of rational a gency . Springer , 1999. Harutyunyan, H., Khachatrian, H., Kale, D. C., and Gal- styan, A. Multitask learning and benchmarking with clin- ical time series data. arXiv pr eprint arXiv:1703.07771 , 2017. Hinton, G., V inyals, O., and Dean, J. Distilling the knowledge in a neural network. arXiv pr eprint arXiv:1503.02531 , 2015. Johnson, A. E., Pollard, T . J., Shen, L., Li-wei, H. L., Feng, M., Ghassemi, M., Moody , B., Szolo vits, P ., Celi, L. A., and Mark, R. G. MIMIC-III, a freely accessible critical care database. Scientific data , 3:160035, 2016. Kamar , E. Directions in hybrid intelligence: Complement- ing AI systems with human intelligence. In IJCAI , 2016. Kamar , E., Hacker , S., and Horvitz, E. Combining human and machine intelligence in large-scale crowdsourcing. In AAMAS , pp. 467–474. International Foundation for Autonomous Agents and Multiagent Systems, 2012. Kirkpatrick, J., Pascanu, R., Rabinowitz, N., V eness, J., Des- jardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T ., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Pr oceedings of the national academy of sciences , pp. 201611835, 2017. Kulesza, T ., Stumpf, S., Burnett, M., and Kwan, I. T ell me more?: the effects of mental model soundness on personalizing an intelligent agent. In CHI , pp. 1–10. A CM, 2012. Lasecki, W ., Miller , C., Sadilek, A., Abumoussa, A., Bor- rello, D., Kushalnagar , R., and Bigham, J. Real-time captioning by groups of non-experts. In Pr oceedings of the 25th annual ACM symposium on User interface softwar e and technolo gy , pp. 23–34. A CM, 2012a. Lasecki, W . S., Bigham, J. P ., Allen, J. F ., and Fer guson, G. Real-time collaborativ e planning with the crowd. 2012b. Nguyen, A., Y osinski, J., and Clune, J. Deep neural net- works are easily fooled: High confidence predictions for unrecognizable images. In CVPR , pp. 427–436, 2015. Norman, D. The psychology of everyday things . Basic Books, 1988. Norman, D. A. Some observations on mental models. In Mental models , pp. 15–22. Psychology Press, 2014. O’Cane, S. T esla can change so much with ov er-the-air updates that its messing with some owners heads. www.theverge.com/2018/6/2/17413732/ tesla- over- the- air- software- updates- brakes , 2018. Rouse, W . B., Cannon-Bo wers, J. A., and Salas, E. The role of mental models in team performance in complex systems. IEEE T ransactions on SMC , 22(6):1296–1308, 1992. A Case for Backward Compatibility f or Human-AI T eams Spring, M. J. T echniques for maintaining compatibility of a software core module and an interacting module, Nov ember 29 2005. US Patent 6,971,093. W ang, D., Khosla, A., Gargeya, R., Irshad, H., and Beck, A. H. Deep learning for identifying metastatic breast cancer . arXiv pr eprint arXiv:1606.05718 , 2016. Zhou, D., Bousquet, O., Lal, T . N., W eston, J., and Sch ¨ olkopf, B. Learning with local and global consis- tency . In NIPS , pp. 321–328, 2004. Zhou, J., Arshad, S. Z., Luo, S., and Chen, F . Effects of un- certainty and cognitiv e load on user trust in predictive de- cision making. In IFIP Conference on Human-Computer Interaction , pp. 23–39. Springer , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment