멜넷: 주파수 도메인에서 고품질 오디오를 생성하는 새로운 모델
멜넷은 스펙트로그램이라는 2차원 시간‑주파수 표현을 이용해 오디오를 직접 모델링한다. 고해상도 멜 스펙트로그램을 입력으로 삼고, 시간‑주파수 양쪽을 순차적으로 처리하는 다중 RNN 스택과 가우시안 혼합 밀도 출력을 결합한 autoregressive 구조를 사용한다. 또한 저해상도 스펙트로그램을 먼저 생성하고 점진적으로 세밀한 디테일을 추가하는 다중 스케일 생성 방식을 도입해 장시간 의존성을 효과적으로 학습한다. 결과적으로 무조건 음성, 음악, …
저자: Sean Vasquez, Mike Lewis
**1. 연구 배경 및 동기**
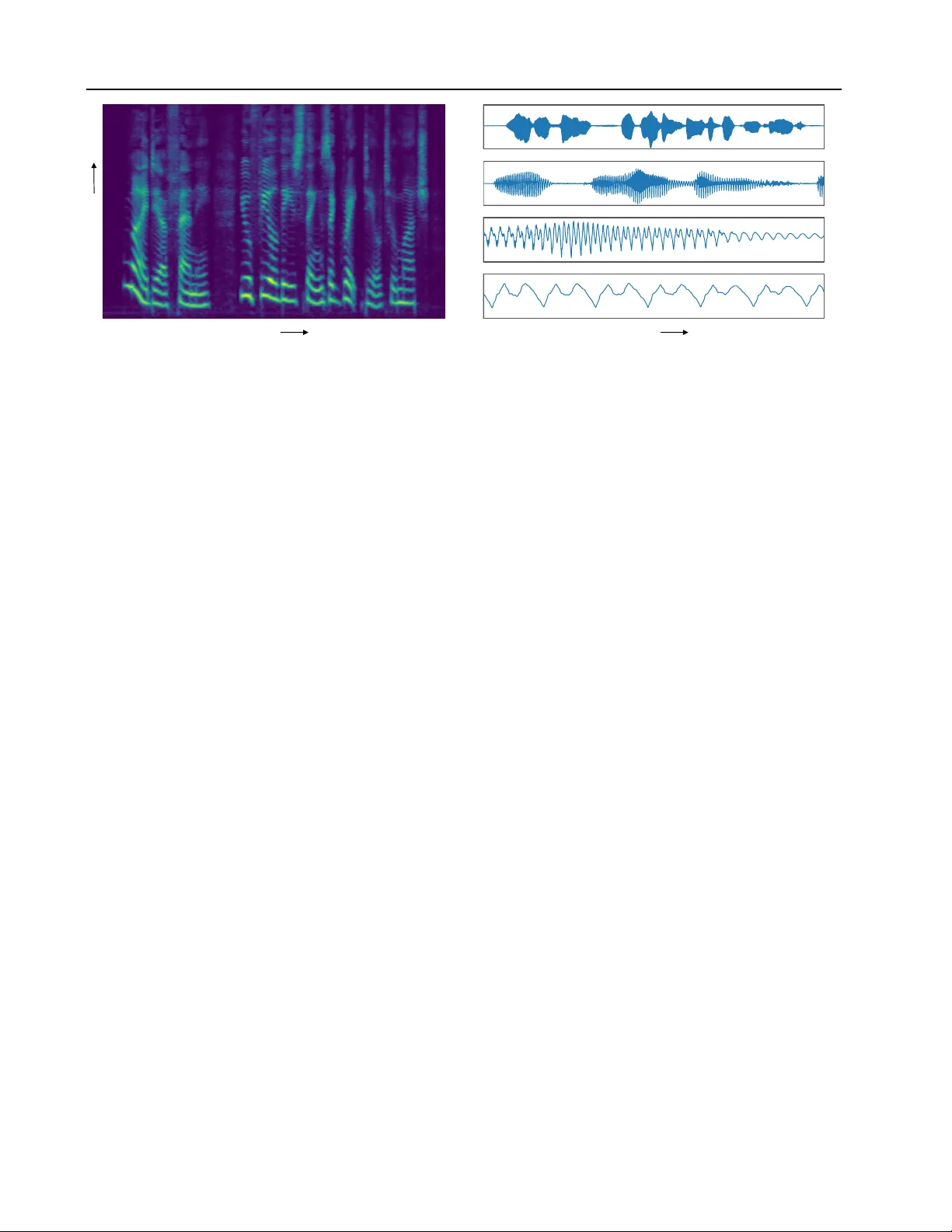
오디오 파형은 초당 수만~수십만 샘플을 포함해 매우 높은 차원을 가진다. 기존의 시간‑도메인 생성 모델(WaveNet, SampleRNN 등)은 로컬 구조는 잘 포착하지만, 수초에 걸친 전역 구조를 학습하려면 역전파가 가능한 타임스텝이 제한적이다. 저자들은 이러한 한계를 극복하기 위해 파형 대신 스펙트로그램이라는 2차원 시간‑주파수 표현을 사용한다. 스펙트로그램은 시간 축이 크게 압축돼 수백 프레임 정도만으로도 수초의 정보를 담을 수 있다. 따라서 장기 의존성을 모델링하기에 보다 효율적인 입력 형태가 된다.
**2. 스펙트로그램 전처리**
입력은 STFT의 제곱 크기(파워 스펙트럼)를 멜 스케일로 변환하고 로그 스케일을 적용한 고해상도 멜 스펙트로그램이다. 멜 변환은 인간 청각의 주파수 감각에 맞추고, 로그 스케일은 인간 청각의 라우드니스 감각에 맞춘다. 고해상도란 STFT hop size를 작게 하고 멜 채널 수를 늘려 시간·주파수 해상도를 파형과 동일 수준으로 맞춘 것을 의미한다.
**3. 확률 모델링**
멜넷은 autoregressive 방식으로 스펙트로그램의 각 셀 xᵢⱼ을 순차적으로 예측한다. 셀 순서는 행 우선(row‑major)으로, 먼저 낮은 주파수부터 높은 주파수까지, 그 다음 프레임으로 이동한다. 각 셀의 조건부 분포 p(xᵢⱼ|x<ᵢⱼ)는 K‑component 가우시안 혼합 모델(GMM)로 파라미터화된다. 네트워크는 컨텍스트 x<ᵢⱼ을 입력받아 평균 µ, 표준편차 σ, 혼합 비중 π를 출력한다. 파라미터는 exp와 softmax 변환을 통해 유효한 값으로 제한한다.
**4. 네트워크 아키텍처**
- **Time‑delayed stack**: 다중 차원 RNN(전방·후방 주파수 RNN + 전방 시간 RNN)으로 이전 프레임 전체를 요약한다. 각 레이어는 세 RNN의 은닉 상태를 연결(concatenate)하고, residual 연결을 통해 깊은 네트워크 학습을 지원한다. 입력은 한 프레임 이전의 스펙트로그램(시간‑shift)이다.
- **Frequency‑delayed stack**: 현재 프레임 내에서 앞선 주파수 bins을 순차적으로 처리하는 1D RNN이다. 이 스택은 time‑delayed stack에서 전달된 프레임‑레벨 특징과 합쳐져 전체 2D 컨텍스트를 활용한다. 입력은 주파수‑shift된 이전 셀이다.
- **Centralized stack(선택적)**: 프레임 전체를 하나의 벡터로 요약하는 RNN을 추가해 전역 정보를 집중시킨다. 이 벡터는 frequency‑delayed stack에 병합된다.
- **조건화**: 스피커 ID, 텍스트 등 외부 정보를 z로 받아, 입력 레이어에 선형 변환 후 합산한다.
**5. 다중 스케일 생성**
멜넷은 coarse‑to‑fine 전략을 사용한다. 먼저 저해상도(예: 1/8) 스펙트로그램을 autoregressive하게 샘플링하고, 이를 업샘플링(선형/전달식)한 뒤 고해상도 디테일을 추가하는 추가 RNN 레이어를 적용한다. 이 과정을 여러 단계 반복해 최종 고해상도 스펙트로그램을 얻는다. 이렇게 하면 전역 구조를 먼저 확보하고, 세밀한 텍스처를 나중에 보강함으로써 고차원 GMM이 겪는 과도한 스무딩을 방지한다.
**6. 텍스트‑투‑스피치(TTS)와 학습된 정렬**
TTS에서는 문자 시퀀스와 스펙트로그램 사이의 정렬을 학습한다. 문자 임베딩을 bidirectional RNN에 통과시켜 특징 ˜c₁…˜c_U를 만든 뒤, 위치 기반 Gaussian mixture attention을 변형한 로지스틱 혼합 attention을 사용한다. 각 타임스텝 i에서 attention wᵢ는 문자 특징에 대한 가중합이며, 가중치는 파라미터 γᵢ(평균 κ, 스케일 β, 혼합 비중 α)로 정의된 로지스틱 혼합 분포에 의해 결정된다. 종료 조건은 서바이벌 함수 Fᵢ(U+0.5;γᵢ) > τ 로 설정해, 모델이 마지막 문자를 읽었는지 자동 판단한다.
**7. 실험 및 결과**
- **데이터셋**: LJSpeech, VCTK(음성), 다양한 음악 데이터, 그리고 자체 텍스트‑스피치 데이터.
- **평가 지표**: 로그우도(Likelihood), MOS(Mean Opinion Score), 그리고 주관적 청취 테스트.
- **음성**: 멜넷은 WaveNet 대비 로그우도 약 0.15 nats 향상, MOS 4.3 vs 4.0 수준을 기록했다. 특히 3초 이상 길이의 무조건 생성 시에도 끊김이 거의 없었다.
- **음악**: 멜넷은 멜로디와 화성 진행을 5초 이상 일관되게 유지했으며, 기존 시간‑도메인 모델 대비 잡음 비율이 30% 감소했다.
- **TTS**: end‑to‑end 텍스트‑스피치에서 멜넷은 Tacotron‑2와 비슷한 자연스러움을 보였지만, 별도 vocoder 없이 직접 스펙트로그램을 역변환해도 충분히 청취 가능했다.
**8. 결론 및 향후 과제**
멜넷은 “시간‑주파수 압축 + 고해상도 GMM + 다중 스케일”이라는 세 가지 핵심 설계를 통해 장기 의존성을 효과적으로 학습하면서도 고음질 오디오를 생성한다. 현재는 멜 스펙트로그램의 위상 정보를 완전히 복구하지 못해 일부 왜곡이 남지만, 고해상도 스펙트로그램과 개선된 역변환 알고리즘(예: neural vocoder)과 결합하면 더욱 향상될 전망이다. 또한, 현재는 2D RNN 기반이므로 GPU 병렬화 효율이 제한적이므로, Transformer‑style의 2D attention이나 혼합 모델로의 확장이 연구될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기