MelNet: A Generative Model for Audio in the Frequency Domain
Capturing high-level structure in audio waveforms is challenging because a single second of audio spans tens of thousands of timesteps. While long-range dependencies are difficult to model directly in the time domain, we show that they can be more tr…
Authors: Sean Vasquez, Mike Lewis
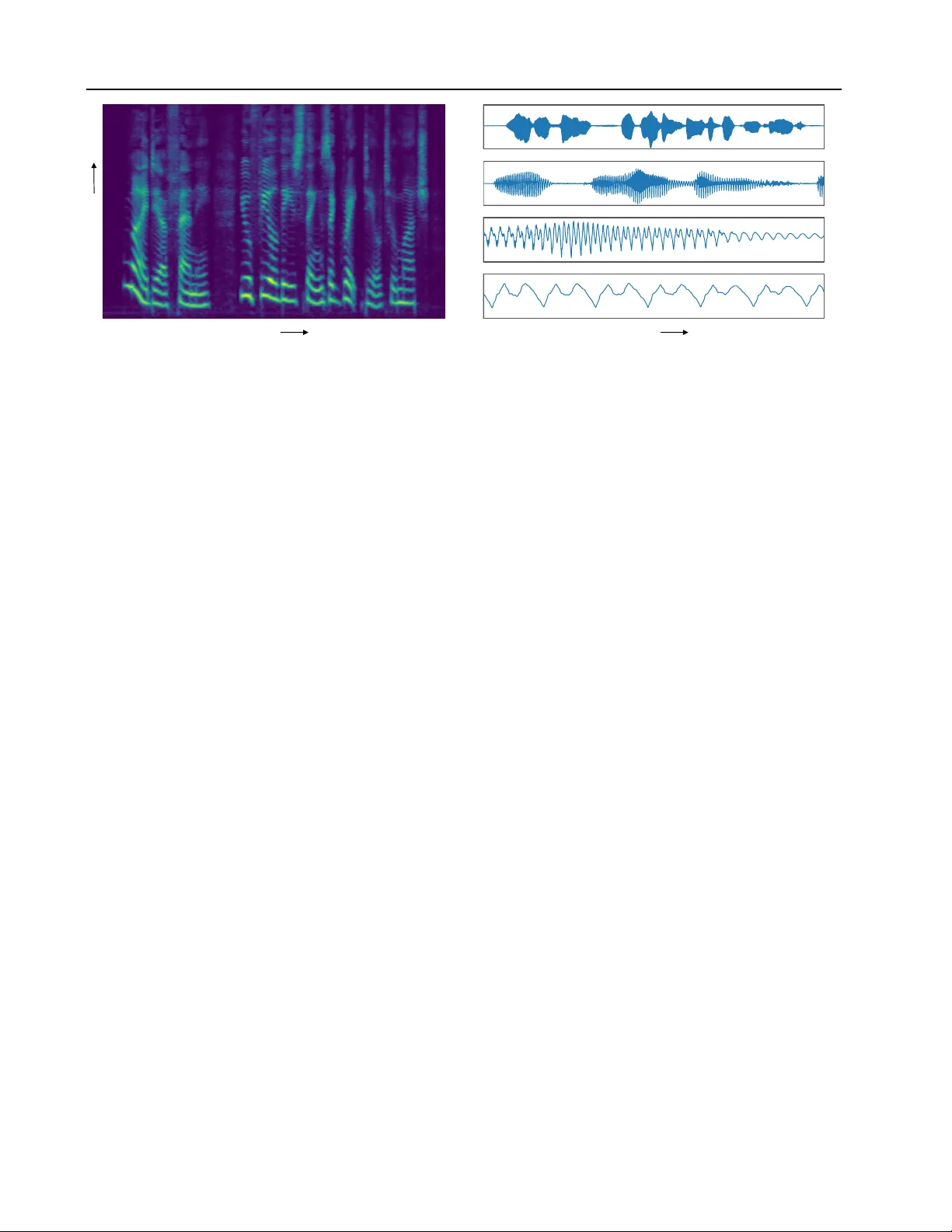
MelNet: A Generativ e Model f or A udio in the Fr equency Domain Sean V asquez 1 Mike Lewis 1 Abstract Capturing high-lev el structure in audio wa v e- forms is challenging because a single second of audio spans tens of thousands of timesteps. While long-range dependencies are dif ficult to model directly in the time domain, we show that they can be more tractably modelled in two-dimensional time-frequenc y representations such as spectrograms. By lev eraging this rep- resentational advantage, in conjunction with a highly expressi v e probabilistic model and a multiscale generation procedure, we design a model capable of generating high-fidelity audio samples which capture structure at timescales that time-domain models hav e yet to achiev e. W e apply our model to a v ariety of audio generation tasks, including unconditional speech generation, music generation, and text-to-speech synthesis— showing impro v ements ov er previous approaches in both density estimates and human judgments. 1. Introduction Audio wa veforms hav e complex structure at drastically vary- ing timescales, which presents a challenge for generativ e models. Local structure must be captured to produce high- fidelity audio, while long-range dependencies spanning tens of thousands of timesteps must be captured to generate au- dio which is globally consistent. Existing generati v e models of wa veforms such as W a veNet [ 47 ] and SampleRNN [ 34 ] are well-adapted to model local dependencies, b ut as these models typically only backpropagate through a fraction of a second, they are unable to capture high-le v el structure that emerges on the scale of se v eral seconds. W e introduce a generati ve model for audio which captures longer-range dependencies than existing end-to-end models. W e primarily achiev e this by modelling 2D time-frequency representations such as spectrograms rather than 1D time- domain wa veforms (Figure 1 ). The temporal axis of a spec- trogram is orders of magnitude more compact than that of a wa veform, meaning dependencies that span tens of thou- sands of timesteps in wav eforms only span hundreds of 1 Facebook AI Research. timesteps in spectrograms. In practice, this enables our spec- trogram models to generate unconditional speech and music samples with consistency over multiple seconds whereas time-domain models must be conditioned on intermediate features to capture structure at similar timescales. Addition- ally , it enables fully end-to-end text-to-speech—a task which has yet to be prov en feasible with time-domain models. Modelling spectrograms can simplify the task of capturing global structure, b ut can weaken a model’ s ability to capture local characteristics that correlate with audio fidelity . Pro- ducing high-fidelity audio has been challenging for existing spectrogram models, which we attribute to the lossy nature of spectrograms and ov ersmoothing artifacts which result from insuf ficiently expressi ve models. T o reduce informa- tion loss, we model high-resolution spectrograms which hav e the same dimensionality as their corresponding time- domain signals. T o limit oversmoothing, we use a highly expressi v e autoregressi ve model which f actorizes the distri- bution o ver both the time and frequenc y dimensions. Modelling both fine-grained details and high-level structure in high-dimensional distrib utions is kno wn to be challeng- ing for autoregressiv e models. T o capture both local and global structure in spectrograms with hundreds of thousands of dimensions, we employ a multiscale approach which generates spectrograms in a coarse-to-fine manner . A low- resolution, subsampled spectrogram that captures high-le v el structure is generated initially , followed by an iterati ve up- sampling procedure that adds high-resolution details. Combining these representational and modelling techniques yields a highly expressi v e, broadl y applicable, and fully end- to-end generativ e model of audio. Our contrib utions are: • W e introduce MelNet, a generati v e model for spec- trograms which couples a fine-grained autoregressi v e model and a multiscale generation procedure to jointly capture local and global structure. • W e show that MelNet is able to model longer-range dependencies than existing time-domain models. • W e demonstrate that MelNet is broadly applicable to a variety of audio generation tasks—capable of un- conditional speech generation, music generation, and text-to-speech synthesis, entirely end-to-end. MelNet: A Generative Model for Audio in the Frequency Domain Ti m e Frequency (a) Spectrogram representation Ti m e (b) W aveform representation (1x, 5x, 25x, 125x magnifications) Figure 1. Spectrogram and wa veform representations of the same four-second audio signal. The w av eform spans nearly 100,000 timesteps whereas the temporal axis of the spectrogram spans roughly 400. Complex structure is nested within the temporal axis of the wav eform at various timescales, whereas the spectrogram has structure which is smoothly spread across the time-frequenc y plane. 2. Preliminaries W e briefly present background regarding spectral represen- tations of audio. Audio is represented digitally as a one- dimensional, discrete-time signal y = ( y 1 , . . . , y n ) . Exist- ing generative models for audio hav e predominantly focused on modelling these time-domain signals directly . W e in- stead model spectrograms, which are two-dimensional time- frequency representations which contain information about how the frequenc y content of an audio signal v aries through time. Spectrograms are computed by taking the squared magnitude of the short-time Fourier transform (STFT) of a time-domain signal, i.e. x = k STFT ( y ) k 2 . The value of x ij (referred to as amplitude or ener gy) corresponds to the squared magnitude of the j th element of the frequency re- sponse at timestep i . Each slice x i, ∗ is referred to as a fr ame . W e assume a time-major ordering, b ut following con vention, all figures are displayed transposed and with the frequency axis in v erted. T ime-frequency representations such as spectrograms high- light how the tones and pitches within an audio signal v ary through time. Such representations are closely aligned with how humans perceiv e audio. T o further align these repre- sentations with human perception, we con vert the frequency axis to the Mel scale and apply an elementwise logarith- mic rescaling of the amplitudes. Roughly speaking, the Mel transformation aligns the frequency axis with human per- ception of pitch and the logarithmic rescaling aligns the amplitude axis with human perception of loudness. Spectrograms are lossy representations of their correspond- ing time-domain signals. The Mel transformation discards frequency information and the remo v al of the STFT phase discards temporal information. When recovering a time- domain signal from a spectrogram, this information loss manifests as distortion in the recovered signal. T o minimize these artifacts and improv e the fidelity of generated audio, we model high-resolution spectrograms. The temporal res- olution of a spectrogram can be increased by decreasing the STFT hop size, and the frequency resolution can be increased by increasing the number of mel channels. Gener- ated spectrograms are conv erted back to time-domain sig- nals using classical spectrogram in v ersion algorithms. W e experiment with both Grif fin-Lim [ 18 ] and a gradient-based in v ersion algorithm [ 10 ], and ultimately use the latter as it generally produced audio with fewer artif acts. 3. Probabilistic Model W e use an autore gressi ve model which factorizes the joint distribution over a spectrogram x as a product of conditional distributions. Gi v en an ordering of the dimensions of x , we define the context x τ . W e compute an estimate for τ after the netw ork is trained, using the empirical mean ˆ τ = 1 N P N n =1 F T n ( U n + 0 . 5; γ T n ) . that we mother nature thank yo u Figure 4. Learned alignment between a spectrogram and the char - acter sequence that we mother natur e thank you . Column i corre- sponds to the learned attention distribution φ i ( · ; γ i ) . The text is read with long, deliberate pauses ( that we / mother / nature / thank you ) which appear as flat regions in the alignment. 6. Multiscale Modelling T o improv e audio fidelity , we generate high-resolution spec- trograms which ha ve the same dimensionality as their cor - responding time-domain representations. Under this regime, a single training example has sev eral hundreds of thousands of dimensions. Capturing global structure in such high- dimensional distributions is challenging for autore gressiv e models, which are biased tow ards capturing local dependen- cies. T o counteract this, we utilize a multiscale approach which effecti vely permutes the autoregressi ve ordering so that a spectrogram is generated in a coarse-to-fine order . The elements of a spectrogram x are partitioned into G tiers x 1 , . . . , x G , such that each successi ve tier contains higher - resolution information. W e define x
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment