AVA 액티브스피커 오디오비주얼 데이터셋으로 활발한 화자 탐지
본 논문은 유튜브 영화 영상을 기반으로 3백65만 프레임(약 38시간)의 얼굴 트랙에 대해 “말함·청취 가능”, “말함·청취 불가”, “말하지 않음” 라벨을 인간이 밀집하게 부착한 대규모 오디오‑비주얼 데이터셋 AVA‑ActiveSpeaker를 공개한다. 또한 픽셀‑레벨 영상과 원시 오디오를 직접 입력으로 하는 실시간 양방향 네트워크 모델을 제안하고, 다양한 환경·노이즈 조건에서 기존 시각‑전용·오디오‑전용 방법보다 우수한 성능을 보임을 실험적…
저자: Joseph Roth, Sourish Chaudhuri, Ondrej Klejch
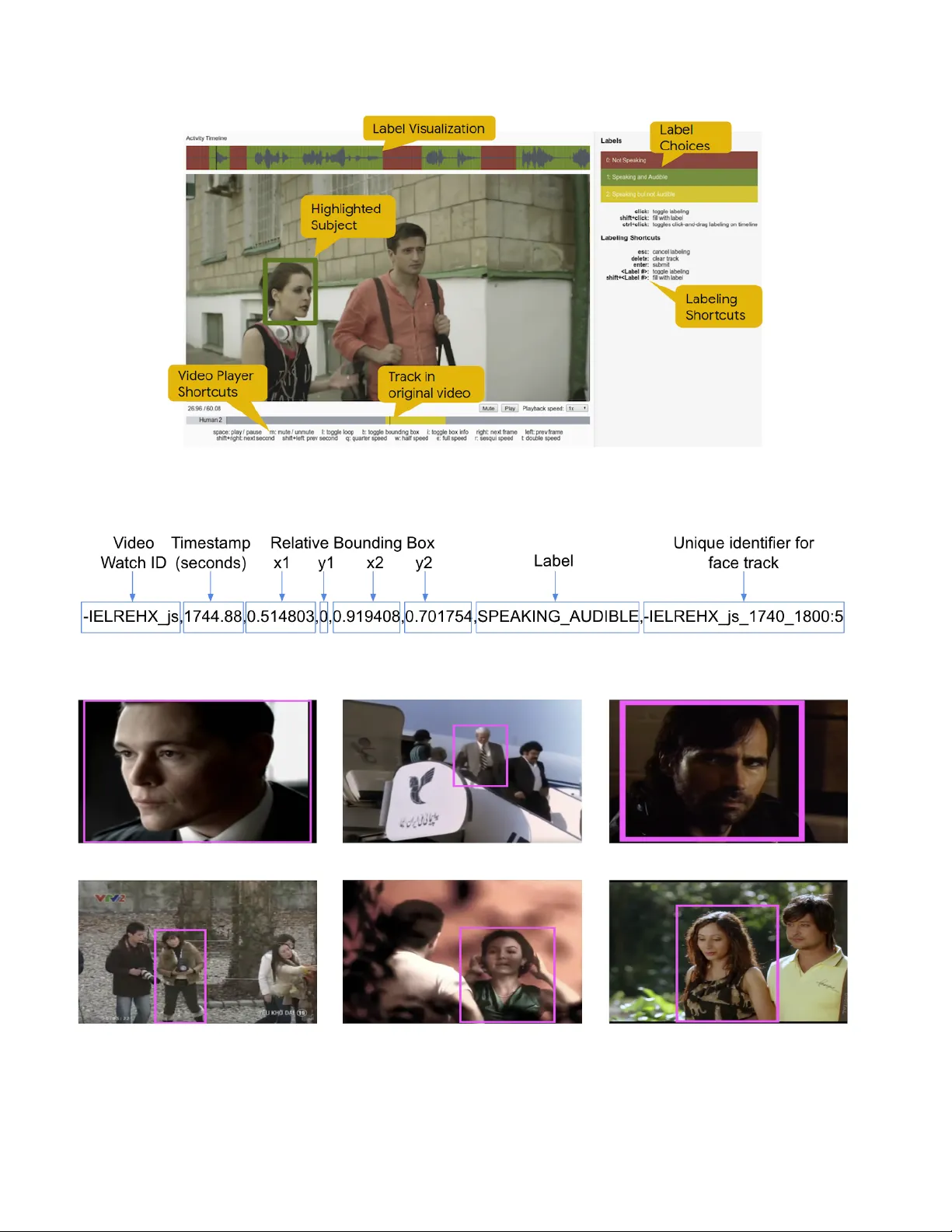
본 논문은 활발한 화자 탐지(active speaker detection) 분야의 핵심적인 데이터 부족 문제를 해결하기 위해, 대규모 오디오‑비주얼 데이터셋인 AVA‑ActiveSpeaker를 구축·공개하고, 이를 활용한 새로운 실시간 양방향 모델을 제안한다.
1. **데이터셋 구축 과정**
- **영상 선택**: 기존 AVA v1.0 액션 인식 데이터셋에서 188편의 유튜브 영화를 선정하고, 각 영화의 15~30분 구간을 추출했다. 영화는 전 세계 다양한 언어·문화·촬영 환경을 포함해, 실제 현장과 유사한 복잡성을 제공한다.
- **얼굴 트랙 생성**: 최신 얼굴 검출기와 바운딩 박스 겹침·유사도 기반 트래킹을 이용해 후보 얼굴을 자동으로 추출했다. 트랙 길이는 최소 1초, 최대 10초로 제한해 라벨링 효율성을 높였으며, 38,500개의 트랙과 3,650,000개의 프레임을 확보했다.
- **라벨 정의**: ‘Not Speaking’, ‘Speaking and Audible’, ‘Speaking but not Audible’ 세 가지 라벨을 도입해 시각‑전용·오디오‑전용 모델을 공정하게 평가할 수 있게 했다. ‘Speaking but not Audible’는 배경음이 크게 잡히거나 음성 오버랩이 있는 상황에서도 시각적 입술 움직임을 포착하도록 설계됐다.
- **인간 라벨링**: 라벨링 인터페이스는 영상과 오디오 파형을 동시에 보여주며, 라벨러가 시간축을 클릭해 구간을 지정하도록 설계됐다. 각 트랙은 3명의 라벨러가 독립적으로 라벨링했으며, Fleiss’ κ=0.72라는 높은 일관성을 보였다.
2. **데이터셋 통계 및 특성**
- 얼굴 폭 분포는 50~200픽셀 사이가 대부분이며, 100픽셀 이하 작은 얼굴이 다수 차지한다. 이는 저해상도·부분 가림 상황에서도 모델이 견고해야 함을 의미한다.
- 동시 등장 인물 수는 로그 스케일로 1~10명까지 다양하며, 특히 군중 장면에서 최대 9명의 ‘Speaking and Audible’와 22명의 ‘Speaking but not Audible’ 라벨이 동시에 나타난다.
- 발화 구간 길이는 평균 1.74초(‘Speaking and Audible’)이며, 파워‑law 형태의 길이 분포를 보인다. 이는 짧은 발화가 빈번히 발생함을 시사한다.
3. **제안 모델**
- **구조**: 두 개의 독립적인 ‘탑’(visual tower, audio tower)으로 구성된 두‑탑 네트워크이다. 시각 탑은 3D CNN을 사용해 연속 프레임(16프레임)에서 공간‑시간 특징을 추출하고, 오디오 탑은 1D CNN을 통해 0.5초 길이의 로그 멜 스펙트로그램을 처리한다.
- **통합 방식**: 두 탑의 최종 피처를 concatenate 후, 2개의 fully‑connected 레이어와 sigmoid 출력으로 화자 여부를 예측한다. 라벨은 프레임 단위 이진 분류이며, ‘Audible’ 여부는 별도 이진 분류 헤드로 구현했다.
- **학습**: 사전 학습된 얼굴 임베딩이나 입술 리딩 모델을 사용하지 않고, 원시 픽셀·오디오 파형을 직접 입력으로 하여 end‑to‑end 학습한다. 데이터 증강으로는 랜덤 크롭, 색상 변형, 배경 잡음 추가 등을 적용했다.
- **성능**: AVA‑ActiveSpeaker 테스트 셋에서 제안 모델은 시각‑전용 모델 대비 F1‑score 0.12, 오디오‑전용 모델 대비 0.08 향상했으며, 특히 ‘noisy’ 구간(배경 소음 SNR < 10dB)에서 15% 이상의 상대적 개선을 보였다. 실시간 추론 속도는 30fps 이상이며, 파라미터 수는 약 15M으로 경량화에 성공했다.
4. **비교 및 분석**
- 기존 데이터셋(예: CUAVE, AVSpeech, REPERE 등)은 규모가 작거나 라벨이 제한적이어서 다중 화자·다양한 환경을 포괄하지 못한다. AVA‑ActiveSpeaker는 38시간·40K 트랙이라는 규모와 풍부한 라벨링으로 이러한 한계를 극복한다.
- 시각‑전용 접근법은 입술 움직임과 비언어적 얼굴 동작(식사, 표정 등)으로 인한 오탐이 많았으며, 오디오‑전용 접근법은 화자와 얼굴 매핑이 불가능한 경우가 있었다. 두 탑을 결합한 AV 모델은 이러한 약점을 상호 보완한다.
- 라벨이 ‘Speaking but not Audible’인 경우, 시각‑전용 모델이 높은 정확도를 보이며, 이는 시각 정보만으로도 화자를 식별할 수 있음을 증명한다. 반대로 ‘Audible’ 라벨에서는 오디오 정보가 주도적이지만, 얼굴 위치 정보를 활용하면 잡음에 강인한 성능을 얻는다.
5. **향후 연구 방향**
- **멀티태스크 학습**: AVA‑Speech 라벨과 결합해 음성 활동 검출·화자 구분·행동 인식을 동시에 학습하는 통합 모델 개발이 가능하다.
- **자기 지도 학습**: AVA 전체 영화(수천 시간)에서 비라벨 데이터로 사전 학습을 수행하면, 현재 데이터셋보다 더 일반화된 특징을 얻을 수 있다.
- **다중 화자 동시 발화**: 현재 데이터셋에서 동시 발화 사례가 드물지만, ‘코러스’와 같은 특수 상황을 위한 별도 서브셋을 구축해 모델을 확장할 수 있다.
- **경량화 및 모바일 적용**: 현재 모델은 15M 파라미터이지만, 모바일 친화적인 구조(예: MobileNet‑V3, EfficientNet‑B0)로 변형해 실시간 모바일 디바이스에서도 동작하도록 연구가 필요하다.
결론적으로, AVA‑ActiveSpeaker 데이터셋은 활발한 화자 탐지 연구에 필요한 규모·다양성·라벨 정밀도를 모두 제공하며, 제안된 실시간 AV 모델은 기존 방법 대비 명확한 성능 향상을 입증한다. 데이터와 코드가 공개됨에 따라, 학계·산업 모두에서 화자 인식, 회의 자동 기록, 인간‑로봇 인터랙션 등 다양한 응용 분야에 즉시 활용될 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기