AVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled …
Authors: Joseph Roth, Sourish Chaudhuri, Ondrej Klejch
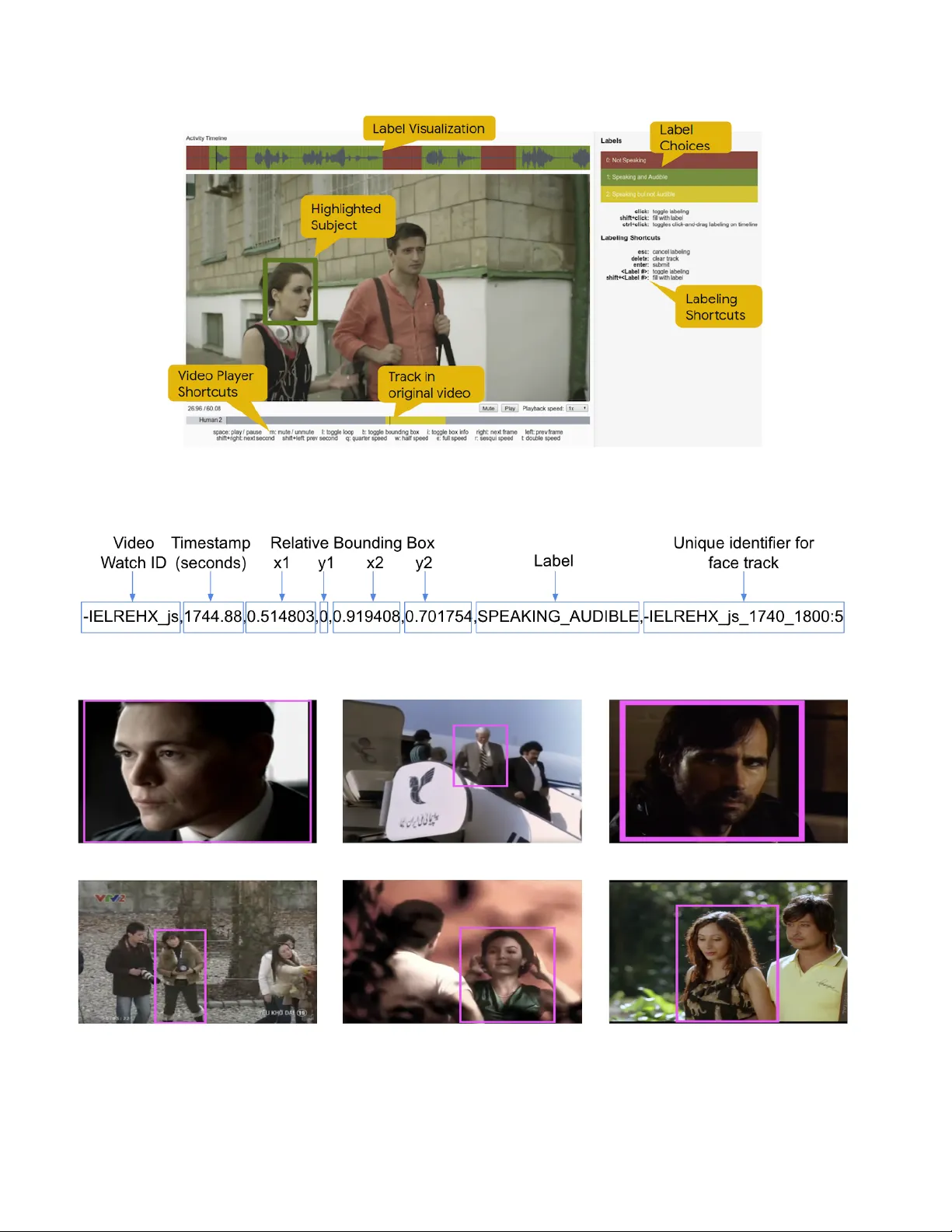
A V A-ActiveSpeak er: An A udio-V isual Dataset for Acti ve Speak er Detection Joseph Roth, Sourish Chaudhuri, Ondrej Klejch, Radhika Marvin, Andre w Gallagher , Liat Kaver , Sharadh Ramaswamy , Arkadiusz Stopczynski, Cordelia Schmid, Zhonghua Xi, Caroline P antofaru Google AI Perception { josephroth, sourc, klejcho, radahika, agallagher, lkaver, sharadh, astopczynski, cordelias, zxi, cpantofaru } @google.com Abstract Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video r e-tar g eting for meetings, speech en- hancement, and human-r obot inter action. The absence of a lar ge , car efully labeled audio-visual dataset for this task has constrained algorithm evaluations with r espect to data diversity , en vir onments, and accuracy . This has made comparisons and impr o vements difficult. In this pa- per , we pr esent the A V A Active Speaker detection dataset (A V A-ActiveSpeaker) that will be r eleased publicly to facili- tate algorithm development and enable comparisons. The dataset contains temporally labeled face trac ks in video, wher e eac h face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tr acks, and the corresponding audio. W e also pr esent a new audio-visual appr oach for active speaker de- tection, and analyze its performance, demonstrating both its str ength and the contrib utions of the dataset. 1. Introduction Con v ersational content in videos has received signifi- cant attention in the literature, with audio-only , visual-only , and joint audio visual modeling approaches applied to ap- plications such as human-robot interactions, speech recog- nition and analysis, and video re-targeting. Active speaker detection— detecting which (if any) of the visible people in a video are speaking at any giv en time— is a core com- ponent in many of these applications. In this paper, we present the A V A Active Speaker detection dataset (A V A- Activ eSpeaker) as a benchmark dataset, which we will re- lease publicly . Alongside the dataset, we present a state-of- the-art audiovisual algorithm for activ e speaker detection and a detailed analysis of its performance. Figure 1: The annotation interface for A V A-Activ eSpeaker . Giv en its surrounding video and audio (wa veform visual- ized above the frame), each face is annotated with whether it is speaking and whether the speech is audible. Annotations are continuous in time. Details in Sec. 3 . Activ e speaker detection in volv es classifying a giv en face at a given time as speaking or not. Activ e speaker detection has multiple applications, such as in interactive systems that identify the speaker and per- sonalize responses [ 44 , 45 ], in speech transcription, speaker diarization and speech enhancement systems [ 1 , 9 , 12 , 26 , 41 , 42 ], and for tracking storylines and characters in narra- tiv e content [ 10 , 14 ]. It is also used to facilitate the mining of training data for modeling these tasks [ 12 , 35 , 41 ]. When activ e speaker detection is used to mine task-relev ant data, prior work often takes an approach biased to wards high pre- cision when finding video clips of likely speakers. As a re- sult, many of the trained models hav e not been exposed to difficult data, and are at risk of failing to generalize to real- world applications. The challenges to robust acti ve speaker detection model- ing come from two sources. The first is the intrinsic dif- ficulty of the task. V isual-only approaches are confused by other face/mouth motions: eating, expressions, holding a hand up to the mouth, or yawning. Audio-only speech detection cannot be associated with a visual person detec- 1 tion without constraining assumptions ( e.g. speaker is al- ways visible) that do not generalize. The second is that web video content comes from div erse demographics, recording device resolution, contain occlusions and varied illumina- tion settings. Robust modeling for acti ve speaker detection requires joint audiovisual models trained from a large and div erse dataset. Such a dataset did not pre viously exist. The closest re- lated work is that of Chakrav arty et al. [ 5 , 6 , 7 ], and their entire experimental data includes sev en 30 -min PhD thesis presentations and segments of a single video with a panel discussion from Y ouT ube. W e expect the broader commu- nity to benefit significantly from scaling up the training and ev aluation corpus to a much lar ger and more di verse dataset. The A V A-ActiveSpeak er dataset fills this need. V ideos in the dataset are from the diverse A V A v1.0 action recognition dataset of Y ouT ube movies [ 24 ]. Giv en the audio and video, each face in each frame is labeled as speaking or not, and whether the speech is audible. Fig. 1 shows the annotation interface, with dense temporal annotation of the highlighted face shown on the wa veform abov e. The dataset contains about 3.65 million labeled frames, about 38 hours of face tracks, and the corresponding audio. W e describe the process of obtaining annotations in de- tail in Section 3 , and present an analysis of the annotated data, including its relationship to past labels released on A V A in Section 4 . A sample of labeled face frames is shown in Figure 2 , which includes partial occlusion, a variety of face sizes, activities, demographics and lighting conditions. Alongside the dataset, we present an audiovisual model for activ e speaker detection in Section 5 . The model is real-time, and is trained directly from the pixels and audio without any pre-trained embeddings. A detailed analysis of model performance is presented in Section 6 . The analy- sis shows the v alue of the label ecosystem on the A V A cor- pus; speech activity labels from A V A-Speech [ 8 ] allow us to ev aluate performance in the presence of different back- ground noise conditions, the temporal extent of labels in A V A-Acti veSpeak er enable fully supervised ev aluation of recurrent models, and the multimodal nature of the dataset enables broader model exploration. W e summarize our contrib utions as follows: • A large-scale, human-annotated, diverse, end- application agnostic, public benchmark dataset, with dense, spatio-temporal labels for activ e speaker detec- tion. This additionally builds upon the increasingly rich ecosystem of labels on the A V A corpus, enabling deeper analysis and label sharing across tasks. • A real-time, joint audiovisual model for this task, end- to-end trained directly off of the pix els and audio with- out the use of any pre-trained networks. • State-of-the-art benchmark results for various models, Figure 2: Examples of labeled faces in A V A-Acti veSpeak er . A green box implies “Speaking and Audible” label, while red implies “Not Speaking”. along with a careful analysis of model performance, and the ef fect of conditions that inform downstream application-specific modeling choices. 2. Related work In this section, we group related literature into 3 broad groups— applications that make use of activ e speaker de- tection, prior work on dev eloping datasets, and prior work with multimodal modeling. Applications using active speaker detection: The ac- tiv e speaker detection module is often handled via heuris- tics in the context of larger end-applications. For example: Everingham et al. [ 13 ] assume motion in the lip area im- plies speech, Chung et al. [ 9 ] and Nagrani et al. [ 35 ] as- sume a single visible face is the speaker, and Shillingford et al. [ 41 ] use a combination of both. All of these works in v olve applications tolerant to biasing the acti ve speaker detection module toward precision, and the last 3 use it to mine and label datasets. As discussed in Sec. 1 , this may result in reduced effecti veness since the training data does not include difficult conditions ( e .g. narrations, v oice ov ers, ov erlapping sounds, challenging illumination, non-speech mouth motion). Recent ef forts using heuristics to mine web video with imputed labels [ 1 , 12 , 37 ] are similarly limited. The approaches in the literature that directly tackle activ e speaker detection [ 5 , 11 , 32 , 45 ] all present ev aluations on task-specific datasets of less than an hour . In contrast, the A V A-Acti veSpeak er dataset provides sev eral distinct bene- fits. This dataset contains realistic video with a wide di- versity of recording conditions (background noise, illumi- nation, etc. ), speaker demographics, and temporally dense labels for each face. In addition, these are added to A V A ’ s preexisting action and speech activity labels to further en- rich the dataset, enabling cross-task analysis. Datasets: A number of ef forts around de veloping au- diovisual datasets with ground-truth labels are related. Early corpora were designed for speech (digit) recogni- tion with high-resolution, frontal facing speaking faces, such as CU A VE [ 38 ] and A VTIMIT [ 25 ]. The UT -CRSS- 4EnglishAccent corpus for voice activity detection [ 46 ] and the A VDIAR corpus [ 20 ] for diarization are recent corpora, but are limited in subject div ersity and recording conditions. Meetings data [ 2 , 34 ] contain spontaneous speech, and non- frontal and occluded faces. Howe ver , not all datasets con- tain video, or they hav e limited diversity due to high col- lection cost. Also, speaker labels are not associated with a visual person. Broadcast news corpora [ 19 , 49 ] contain a larger speaker diversity fixed genre, due to being recorded in-studio. Datasets deriv ed from movies and TV shows are also popular but are rarely more than a few hours and limited to a fe w shows and characters. For example, the REPERE corpus [ 22 ] is 3 hours, Ren et al [ 39 ] ev aluate on a single TV show with 5 characters, Everingham et al [ 13 ] use 2 episodes, Hu et al [ 28 ] use 3 hours from 2 TV sho ws. In contrast, A V A-ActiveSpeak er contains ∼ 40 K labeled face tracks totaling 38 hours, includes a variety of spoken languages, is task-agnostic, and we had no influence over recording conditions, production or narrativ e structures. Multimodal appr oaches: Early multimodal approaches on speech (digit) recognition tasks projected the modali- ties into lo w dimensional subspaces that maximize the mu- tual information (MI) between the signals [ 15 , 36 , 40 , 43 ], with differences in feature representations and modelling paradigms. Howe ver , MI-based approaches do not perform well in unconstrained en vironments [ 47 ]. There exist a variety of approaches for con v ersation analysis in videos. While some use only visual informa- tion [ 44 , 45 ], many can be considered “multimodal”: some incorporate audio and whole body information [ 17 , 29 , 48 ], some add localization signals obtained from a known mi- crophone array configuration [ 21 , 50 ], others utilize script and subtitle information [ 3 , 13 , 14 ]. All of these per- form late fusion with heuristics, typically assuming non- ov erlapping speech, and that the application is permissive to operating at high precision with lo w ( ∼ 30% ) or unknown (since ground-truth is not av ailable) recall. Recent work jointly models audiovisual data, without handcrafted heuristics for late fusion, and two-tower neu- ral network architectures (with a tower per modality). Hu et al. [ 28 ] and Ren et al. [ 39 ] use audio and visual sig- nals for automatic speaker naming. Hu et al. assumes non- ov erlapping speech, while Ren et al. [ 39 ]’ s relaxes that as- sumption. Due to the absence of a dataset with dense, tem- poral labels, both ev aluate over specified duration se gments with model predictions treated as v otes to ward segment la- bel prediction. In contrast, the densely labeled tracks in A V A-Acti veSpeak er allow more fine-grained analysis. Re- cent work in speech enhancement [ 1 , 9 , 12 , 18 , 37 ] use two- tower neural networks; ho we ver , they also process the vi- sual modality with pre-trained networks: using keypoints to isolate the mouth region [ 9 ], computing identity embed- dings from detected faces [ 12 ], and computing word-le v el lip reading embeddings [ 1 ]. These require additional tech- nology and add computation. While the broader architecture choice for our audiovi- sual model resembles the general space of tw o-to wer archi- tectures, our models are trained on the detected face pixels directly and do not require any pre-trained networks. W e present results on the A V A-ActiveSpeak er dataset with this multimodal network trained from scratch, and compare with visual-only and audiovisual models, as well as in v arious background noise conditions. Our experimental results de- scribe the tradeoffs between model accuracy , latency and computational complexity . This modeling approach could be supplemented in the future with additional pre-trained embeddings if desired. In addition, it could be augmented by utilizing the rest of the A V A dataset movies to provide large amounts of unsupervised or semi-supervised data in conjunction with curriculum learning [ 4 , 23 ] or reinforce- ment learning [ 30 , 31 ]. 3. Dataset Construction Creating the A V A-Activ eSpeaker dataset consisted of four stages: video selection, label vocab ulary definition, face track detection, and human annotation, producing the dense, spatio-temporal annotations that we refer to as the A V A-Acti veSpeak er dataset and which we will release pub- licly . A CSV file indicates face bounding boxes ov er time for each track and corresponding temporal labels. W e pro- vide examples of the spatio-temporal labeled tracks in Ap- pendix A , including e xamples of the actual CSV of track annotations. The dataset url, which will be used for do wn- load, is not included here due to the double-blind re vie w process. V ideo selection W e labeled all a v ailable videos from v1.0 A V A dataset [ 24 ], each a continuous segment from min- utes 15 to 30 from 188 movies on Y ouT ube. See Section 3 of [ 24 ] for details on the video selection process. While movies are not a perfect representation of in-the-wild data, this dataset was compelling for a few reasons: it contains movies from film industries around the world, leading to di- versity in languages, recording conditions, and speaker de- mographics; the synchronized audio and visual streams en- able de velopment of joint audio visual models; the dataset is already popular for action recognition and speech detection tasks, and enriching the dataset further provides the oppor- tunity for cross-task modeling; finally , the structured nar- rativ e of movies provides the potential for extension to ap- plications such as speaker diarization, a task made simpler by the presence of A V A-Speech labels, or plot or narrative structure analyses. Label V ocabulary Definition The label v ocabulary pro- vided as part of the rating interface contains three options: Not Speaking , Speaking and Audible , and Speaking but not Audible . The Speaking label is broken into two categories depending on the audio modality . Speaking but not Audi- ble cov ers cases where someone may visually appear to be speaking, e.g . in the background, ev en though their speech is not audible in the soundtrack. This allows for fairer e v al- uation of visual-only approaches that should classify these instances as speech. Face track generation As the example in Figure 1 shows, the speaker annotations are spatio-temporal and dense. Peo- ple in the video are annotated by face bounding box tracks, and the synchronous audio wav eform is shown above the video player . Since manual bounding box annotation is ex- pensiv e, we use automatic f ace detection and tracking. Can- didate faces are detected via a face detector similar to [ 33 ], and tracked over time based on bounding box ov erlap and similarity , with gaps less than 0 . 2 seconds within a track filled via Gaussian kernel smoothing of box corners. Tracks for labeling are required to be at least 1 second long to pro- vide sufficient context and remove spurious false positiv es, and no more than 10 seconds to provide suf ficient resolu- tion on the audio wa v eform and prevent annotator fatigue. The occasional occurrence of merging of tw o identities into a single track or a false positi v e track generated by this pro- cess are both discarded by human annotators. This process produced 38 , 500 tracks and 3 . 65 million faces in the A V A- Activ eSpeaker dataset. Active Speaker Annotation The active speaker labels are generated by human annotators using the interf ace in Fig. 1 . Each rating task contains a video clip with a bounding box around a single face, and the process is repeated for all visible faces in the clip. The activity timeline above the player depicts the audio wav eform; it be gins colorless and is filled with color coded labeled segments as the labeling progresses. The timeline beneath the video depicts the face track time within the full video clip. Both timelines may be clicked to seek to the corresponding time in the video. W e provided detailed guidance to the annotators regarding various edge cases, which are discussed in Appendix A . 4. Labeled Dataset Figure 3 a shows the distribution of face width ov er the detected face tracks. A significant portion of labeled faces are smaller than 100 pixels wide and likely to be challeng- ing. Fig. 3 b shows the distribution by time of the number of concurrently present face tracks (note: y-axis is loga- rithmic). The higher end is crowded scenes with ele vated Label T ime # Segments Mean Duration NS 28 . 10 hours 58 , 171 1 . 74 seconds S&A 9 . 46 hours 30 , 623 1 . 11 seconds S&N A 0 . 35 hours 1 , 547 0 . 83 seconds T able 1: Aggregate statistics over the A V A-ActiveSpeak er dataset for the three labels: Not Speaking (NS), Speaking and Audible (S&A), Speaking but Not Audible (S&N A). lev els of audio and visual activity , thereby making accurate predictions harder . Even with only two people, li vely con- versation and shot changes make classification dif ficult. In total, the annotators labeled ∼ 40 K face tracks from 160 videos. Each track was manually labeled by three an- notators, and the Fleiss’ kappa [ 16 ] value over the dataset was 0.72 indicating a high inter -annotator agreement. Most disagreements were near the temporal boundaries of speech segments, and due to perceptual dif ferences. T able 1 contains the summary statistics for the three la- bels. W e see that the av erage duration of speaking f ace se g- ments is surprisingly short. Although the av erage duration of continuous speech segments is higher (as reported in [ 8 ]), speaking faces do not stay on screen through each utterance. In movies, the shot may pan the scene while speech is ac- tiv e, or visually cut to other scene elements; as a result, the face track is broken when the shot moves away from the speaker . W e include video examples and discuss them in Appendix A . As Figure 3 c sho ws, the distribution of audible activ e speaker segment lengths appears to follow a power law . W e analyzed the labeled tracks to determine how fre- quently activ e speakers overlapped in this dataset, i.e. mul- tiple people were labeled as speaking at the same instant. While multiple co-occurring active speakers are uncommon at ∼ 500 instances spanning ∼ 3 minutes, the number of faces in a single frame labeled as “Speaking and Audible” is as high as 9, and labeled as “Speaking but not Audible” faces is as high as 22. These appear to occur in group con- texts, such as choruses. W e note that while the face detection system used to generate candidate tracks for labeling is state-of-the-art and remarkably robust to a variety of conditions, it is still not perfect, and the challenging conditions such as illumination and partial occlusion do result in some missed detections. Appendix A contains screenshots of some examples. Previous annotations released on the videos in the A V A dataset hav e contributed action recognition (associated with a bounding box entity) [ 24 ] and audio speech acti vity labels (not associated with specific entities) [ 8 ]. In the follo wing two subsections, we discuss the relationships between the activ e speaker labels that we produce and those label sets. Figure 3: (a) Distribution of detected face widths that were labeled. (b) Distribution of total duration (log-scale) correspond- ing to the number of concurrently present faces. (c) Distribution of segment lengths for each label. Figure 4: (a) Intersection between speech activity and activ e speaker labels. (b) Distribution of noise conditions when a speaker is visible. (c) Distribution of noise conditions when a speaker is not visible. 4.1. A V A action labels The A V A corpus [ 24 ] was originally released for visual action recognition research. A pair of labels— “talk-to” and “sing-to”— in the set of actions in A V A are relev ant to activ e speaker detection focused exclusi v ely in this work. There are two k ey differences in the processes to collect ac- tion labels and active speaker detection labels. First, the action labeling process was exclusi v ely visual, whereas in our work the annotators had audio av ailable. Second, the action labels were applied to the single middle frame of a 3-second context, thus providing annotators with limited context, whereas our labeling process makes entire tracks av ailable to annotators resulting in densely annotated tem- poral label segments over the entire track. W e computed the overlap between these A V A action labels and the ac- tiv e speaker labels in this dataset. Since A V A action labels are provided at a 1-second granularity and are not densely labeled, we can only determine how often the action label co-occurs with each acti ve speaker labels (shown in T able 2 , but cannot compute a similar number in the other direction. T able 2 indicates that the annotators for the action labels and the active speaker disagree quite a bit. An examination of a sample of instances where the “talk-to” labels appeared as “Not Speaking” indicates man y are near (b ut outside) the beginning or end of an actual speaking segment, while the Label “talk-to” “sing-to” Not Speaking 17.05% 12.95% Speaking & Audible 81.09% 71.07% Speaking but Not Audible 1.86% 15.98% T able 2: Co-occurrence of a pair of A V A action labels with the activ e speaker labels. rest are distributed over harder negati ves, such as laughing, crying, yawning, etc. The correspondence with “Speaking but not Audible” labels are as one would expect, covering instances where access to the audio would ha ve allowed de- termining audibility . The “sing-to” labels corresponding to inaudible or not speaking labels occur in clearly musical contexts, but also show similar sources of confusion; e .g. words mouthed by a dancer , or a conductor , or frames near (but outside) bound- aries of singing segments, where audio would hav e helped determine if someone was singing or not. W e provide some illustrativ e e xamples in Appendix A . 4.2. A V A speech activity labels Previous work has made speech activity labels - occur- rence speech without any attrib ution to a specific visual en- tity - av ailable on the A V A dataset [ 8 ]. The labels released as part of this work extends this further to enable explicit attribution of speech to a visible f ace, when possible. Since the labeling process relies on faces, it will not cover cases where the speaker’ s face was not visible ( e.g. offscreen speaker , back to the camera). So we do not expect to be able to attrib ute all the speech to visible speaking entities. Here, we quantify the proportion of speech activity that has been explicitly labeled with acti v e speakers. The speech acti vity labels indicate whether speech activ- ity was present in the video at each instant in time. There are four speech activity types: “No Speech”, “Clean Speech”, “Speech with Music”, “Speech with Noise”. W e com- bine the three dif ferent speech types into a single label and consider the binary condition: speech is occurring or not. Computing the ov erlap between Speech Activity and Ac- tiv e Speaker labels allows us to consider the following four cases: 1. Speech without Speaker : Duration of speech heard, but not attrib uted to a visible speaker . 2. Speaker without Speech : Duration of visible speaker , but no corresponding Speech Acti vity label recorded. 3. Speech with Speaker : Duration of ov erlapping speech and visible speaker audibly speaking. 4. No Speech/No audible speaker : Duration with no ac- tiv e speech and no audible acti ve speak er . The left panel in Figure 4 shows the total durations for with the four cases. As expected, the speaker without speech case only occurs due to frame-le vel disagreements at se gment boundaries. The cases where acti ve speech is at- tributed to an activ e speaker and cases where it is not are particularly interesting, and provides an insight into pro- duction effects in the movies genre: it is significantly due to the use of artistic narrative de vices; e.g. the camera pans the scene as the vie wer kno ws the speaker from a previous shot, speech ov erlaid on a “dream” sequence in the video; some other cases consist of contextual speech that can be considered “background”; e.g . in a crowded mark et scene . Since the pre viously released speech activity labels contain information about background noise (whether the speech is clean, or there is background music or other noises) when speech is present, we plotted the distribution of the speech condition information for the “Speech with- out Speaker” and the “Speech with Speaker” cases, shown in the middle and right panels of Figure 4 . W e notice that the proportion of “Clean Speech” increases by 12% in the “Speech with Speaker” case: since the shot makes an effort to focus on the speaker , it is reasonable that a lar ger propor - tion would contain clean speech. 5. Multimodal active speak er detection As discussed in Section 1 , robust acti ve speaker de- tection requires the joint analysis of the audio and visual Figure 5: End-to-end multimodal activ e speaker detection framew ork. modalities. While this can be done using a late fusion of predictions from state-of-the-art single-modality models, we expect that a joint model that optimizes on the end-task will improv e performance while being more ef ficient by re- ducing modeling redundancies across the single-modality models, and the need to train indi vidual models as well as the combination model. For the acti ve speaker detection task, we desire to learn a mapping from a face track and audio signal to the proba- bility of the face speaking at each time instant. That is, we want to learn p = f ( I , a ; w ) , where I = [ I 1 , I 2 , . . . , I N ] is a track of face thumbnails, a = [ a 1 , a 2 , . . . , a T ] is a wav e- form (or a frequency-domain representation of the wav e- form), p = [ p 1 , p 2 , . . . , p N ] is the sequence of speech prob- abilities, and w is the parameters to be trained to determine the mapping. The function f can be realized by any re gres- sor , including a deep neural network. In practice, we decompose f (as shown in Fig. 5 ) into a set of DNNs to be jointly trained. That is, f ( I , a ; w ) = p ( e a ( a ; w a ) , e v ( I ; w v ); w p ) , where e a ∈ R d is an audio em- bedding network, e v ∈ R d is a visual embedding network, and p is a prediction network that fuses the low dimensional audio and visual embeddings. The audio or visual networks could be initialized with pre-trained networks, if desired, but in this work, we train from scratch with the pixels in- put directly to the visual network and the Mel-spectrogram representation of the audio is input to the audio network. During training, each training example i contains a se- quence of face images I i = [ I i 1 , I i 2 , . . . I iN sampled at 20 FPS, a corresponding audio representation a i = [ a i 1 , a i 2 , . . . , a iT ] at 100 FPS, where T = N / 20 ∗ 100 , and a sequence of ground-truth labels y i = [ y i 1 , . . . , y iN ] , where y ij = 1 if the face I ij is speaking and y ij = 0 otherwise. W e define the loss function l ( w ) as a cross entropy loss be- tween the predictions and labels: l ( w ) = − X j y ij log( p ij ) + λ k w k 2 , (1) where λ is a regularization hyperparameter . Further - more, to encourage the prediction network to make use of T ype / Stride Filter Shape Input Size Con v / s2 3 × 3 × M × 32 128 × 128 × M Con v dw / s1 3 × 3 × 32 dw 64 × 64 × 32 Con v / s1 1 × 1 × 32 × 64 dw 64 × 64 × 32 Con v dw / s2 3 × 3 × 32 dw 64 × 64 × 64 Con v / s1 1 × 1 × 32 × 64 dw 32 × 32 × 64 Con v dw / s2 3 × 3 × 32 dw 32 × 32 × 64 Con v / s1 1 × 1 × 32 × 64 dw 16 × 16 × 64 Con v dw / s2 3 × 3 × 32 dw 16 × 16 × 64 Con v / s1 1 × 1 × 32 × 64 dw 8 × 8 × 64 Con v dw / s2 3 × 3 × 32 dw 8 × 8 × 64 Con v / s1 1 × 1 × 32 × 64 dw 4 × 4 × 64 Con v dw / s2 3 × 3 × 32 dw 4 × 4 × 64 Con v / s1 1 × 1 × 32 × 64 dw 2 × 2 × 64 A vg Pool / s1 Pool 2 × 2 2 × 2 × 64 FC / s1 64 × 128 1 × 1 × 64 T able 3: V isual embedding network architecture. The audio embedding network only dif fers in the input sizes. both the audio and visual embeddings, we add independent auxiliary classification networks on each modality with cor- responding cross entropy loss. Our final loss is then a com- bination of all terms: l ( w ) = L av + λ a L a + λ v L v , (2) where L av is Eq. 1 , L a and L v are the cross entropy of audio-only and visual-only networks, and λ a = λ v = 0 . 4 places a lower weight on the individual modality perfor- mance. A wide variety of network choices can be explored for each network, but that is beyond the scope of this work. In particular , we expect that reasonable choices for the network will show that the joint audiovisual (A V , hence- forth) models can significantly improv e ov er visual-only (V , henceforth; and A for audio-only) models, and that these improv ements hold up across a variety of conditions. While more sophisticated models will undoubtedly further push performance, we expect that the delta between the V and A V models will remain. For the A and V networks, e a ( a ; w a ) and e v ( I ; w v ) , we use a CNN employing the depthwise separable technique introduced by MobileNets [ 27 ]; our implementation uses fewer layers than the canonical MobileNet (since we use smaller images), and does not increase the number of 1 × 1 filters with network depth (to pre vent overfitting on the relativ ely smaller dataset compared to ImageNet). Details of the network are in T able. 3 . The input to the visual network is a stack of M consec- utiv e 128 × 128 grayscale face thumbnails. By varying M , we can explore the ef fect of temporal information in the de- cision making process. The Mel-spectrogram input to the audio network is 64 × 48 × 1 and is computed o ver the pre- ceding 0 . 5 seconds of audio, using a 25 ms analysis windo w . Static GR U # frames V VV A V V A V f1 0 . 68 0 . 69 0 . 83 0 . 76 0 . 86 f2 0 . 74 0 . 73 0 . 86 0 . 86 0 . 91 f3 0 . 77 0 . 76 0 . 87 0 . 86 0 . 92 f5 0 . 79 0 . 79 0 . 89 0 . 86 0 . 91 f7 0 . 81 0 . 82 0 . 89 f10 0 . 82 0 . 82 0 . 90 f15 0 . 82 0 . 83 0 . 90 T able 4: auR OC: Higher is better . GR U models start over - fitting in 5 frames or fe wer , so we omit the f7, f10, f15. For the prediction network, we explore two possibilities in this work. (1) A static model, where each set of M con- secutiv e face frames are trained independently; and (2) a r ecurr ent model, where state from the previous timestep contributes to the determination of the current timestep’ s label. The static model consists of two fully connected lay- ers of 128 -dim and 2 -dim follo wed by a softmax to con v ert to probabilities. The recurrent model consists of two 100 - dim Gated Recurrent Units (GRU) (as GR Us outperformed LSTMs, in our e xperiments) followed by a 2 -dim fully con- nected and softmax layers. 6. Evaluation and Analysis In this section, we present the results of ev aluating the models described in Section 5 on the test split of the A V A- Activ eSpeaker dataset, and present an extended analysis of model performance. All models were trained under the same conditions: we cropped the labeled tracks using a 3 - second ( 60 -frame) sliding window with 1 -second overlap; we used an AD A GRAD optimizer with a learning rate of 2 − 6 for 10 epochs. Metrics: T o compare model performances, we use area under the Recei ver Operating Characteristic curv e (auR OC) as a holistic measure of performance. T o slice a single model’ s performance across partitions of the data, we use balanced accuracy at a fixed p = 0 . 5 threshold, chosen to remov e bias from the number of positi ve labels in each par - tition. The fixed operating point ensures an equitable com- parison. Results: T able 4 displays the overall results for the ma- jority of experiments performed. W e discuss them in detail below using the following abbreviations: visual-only as V , audio-visual as A V , and f M as the number of stacked faces used in the visual embedding network. First, we look at visual-only model performances. W e expect that an f1-V model should be able to detect speak- ing faces; e.g ., humans can look at a photograph and guess if someone is speaking. Indeed, “V Static f1” performs better than random chance. T emporal information, how- ev er , should improve significantly over f 1 models. For all Figure 6: Sample ground truth speaking with frames: cross (predicted non-speech) and checkmark (predicted speech) for V Static f1 (top-right) and A V GRU f2 (bottom-right). The audiovisual model is able to handle occlusions and profile faces. Figure 7: ROC curve for the best static and recurrent models with V and A V . ‘x’ represents the balanced accuracy point. model types, performance jumps from f1 to f2. Static mod- els show continued improvement saturating around f10 or 0 . 5 sec of visual information. Howe v er , the GR U saturates at f2, which indicates that only short temporal motion is nec- essary to b uild visual embeddings, as the recurrent structure can use history from the beginning of the track. A V models, howe ver , should significantly outperform their corresponding V counterparts. It is difficult for a V model to disambiguate speech from hard negati v es that con- tain mouth motions, b ut an A V model can learn the relation- ship between the motions and audio signal for these chal- lenging situations. Indeed, static A V models show > 40% reduction in error over V models, and the GR U models show > 30% reduction. Further , the A V static models re- quire fewer visual frames before saturating, indicating that audio contributes significantly . T o ensure the improv ement from A V models is not sim- ply due to twice the model parameters and embedding di- mensions, we train a visual-visual (VV) model with tw o in- dependent visual towers. VV is within hundredths of all V models, indicating that visual performance has indeed sat- urated, and that audio is key to performance improv ement. Figure 7 shows the full R OC curve for the best performing Model Clean Noise Music V Static f10 76 . 3% 75 . 5% 75 . 4% A V Static f10 78 . 9% 78 . 2% 77 . 7% V GR U f2 79 . 2% 78 . 8% 78 . 1% A V GRU f2 81 . 9% 81 . 5% 79 . 8% T able 5: Balanced accuracy across sound conditions. Model Small Medium Large V Static f10 70 . 5% 77 . 6% 82 . 2% A V Static f10 77 . 7% 85 . 6% 89 . 0% V GR U f2 74 . 5% 81 . 3% 84 . 2% A V GRU f2 78 . 7% 87 . 1% 89 . 4% T able 6: Balanced accuracy by face size. V A V Static f1 0 . 412 0 . 656 Static f10 0 . 564 0 . 738 GR U f2 0 . 711 0 . 821 T able 7: mAP of A V A Activ eSpeaker models on the held- out ActivityNet Challenge data. static and RNN settings for V and A V . T able 5 shows performance broken down by the back- ground sound conditions, using information from the A V A- Speech labels [ 8 ]. Unlike audio-based speech detection performance reported in [ 8 ], V and A V models both show resilience to background sound. V models show similar performance regardless of the en vironment, while the A V model performance drops in the presence of background music (although still abov e V). T able 6 shows performance by face size, where small is [0 , 64) pixels, medium is [64 , 128) , and large is [128 , ∞ ) . As expected, both V and A V models perform better with larger faces; for V models, the false positive rate increases at a fixed threshold whereas it decreases for A V models. W e provide the full R OC plots for the different back- ground sound and face size cases, as well as more e xamples and commentary on model performance in Appendix B . 6.1. ActivityNet Challenge The A V A Activ eSpeaker dataset is part of the 4th Ac- tivityNet challenge at CVPR 2019. Details on the task can be found in guest task B: Spatio-T emporal Action Localiza- tion . The analysis of performance of models for this task is done on a held-out test set labeled separately for the chal- lenge, which is av ailable on the A V A Acti veSpeaker Do wn- load page . T able 7 reports the performance of a selected set of mod- els computed through the ActivityNet ev aluation server us- ing the mean av erage precision metric. The models used here are the same ones whose performance was reported in T able 4 . 7. Conclusion This paper introduces the A V A-Acti veSpeaker dataset with dense, spatio-temporal annotations of spoken activity across 15 -min movie clips from the 160 videos in the A V A v1.0 dataset, creating the first publicly a vailable, large-scale benchmark for the acti ve speaker detection task. While the presence of face-associated speaking annotations already make this dataset interesting for various multimodal tasks, such as speaker identification, it also provides the opportu- nity for future work to de velop the annotations further to extend to tasks such as speaker diarization, or e ven more holistic analyses tasks around plot and narrative structures. W e also present a joint audiovisual modeling approach for the active speaker detection task, which reduces the errors in visual-only approaches by 36%, and present an analysis of model performance across sev eral conditions. References [1] T . Afouras, J. S. Chung, and A. Zisserman. The con versation: Deep audio-visual speech enhancement. In INTERSPEECH , 2018. [2] X. Anguera, C. W ooters, and J. Hernando. Robust speaker diarization for meetings: ICSI R T06s ev aluation system. In Pr oc. Interspeec h , 2006. [3] M. B ¨ auml, M. T apaswi, and R. Stiefelhagen. Semi- supervised learning with constraints for person identification in multimedia data. In Pr oc. IEEE Conf. Computer V ision and P attern Recognition , pages 3602–3609, 2013. [4] Y . Bengio, J. Louradour, R. Collobert, and J. W eston. Cur- riculum learning. In Pr oc. International Conference on Ma- chine Learning , 2009. [5] P . Chakrav arty , S. Mirzaei, T . T uytelaars, and H. V anhamme. Who’ s speaking? audio-supervised classification of activ e speakers in video. In Pr oc. ACM Int. Conf. Multimodal In- teraction , pages 1–5, 2015. [6] P . Chakravarty and T . T uytelaars. Cross-modal supervision for learning activ e speaker detection in video. In Pr oc. Eu- r opean Confer ence on Computer V ision , pages 1–5, 2016. [7] P . Chakravarty , J. Zegers, T . T uytelaars, and H. V . Hamme. Activ e speaker detection with audio-visual co-training. In Pr oc. A CM Int. Conf. Multimodal Inter action , 2016. [8] S. Chaudhuri, J. Roth, D. Ellis, A. C. Gallagher , L. Kav er , R. Marvin, C. Pantof aru, N. C. Reale, L. G. Reid, K. W ilson, and Z. Xi. A V A-Speech: A densely labeled dataset of speech activity in mo vies. In Pr oc. Interspeech , 2018. [9] J. S. Chung and A. Zisserman. Out of time: Automated lip sync in the wild. In Proc. W orkshop Multi-V iew Lip Reading , Asian Confer ence on Computer V ision , 2016. [10] T . Cour, C. Jordan, E. Miltsakaki, and B. T askar . Movie/script: Alignment and parsing of video and text tran- scription. In Proc. Eur opean Confer ence on Computer V i- sion , 2008. [11] R. Cutler and L. Davis. Look whos talking: Speaker de- tection using video and audio correlation. In Proc. IEEE Int. Conf. Multimedia and Expo (ICME) , pages 1589–1592, 2000. [12] A. Ephrat, I. Mosseri, O. Lang, T . Dekel, K. W ilson, A. Has- sidim, W . T . Freeman, and M. Rubinstein. Looking to lis- ten at the cocktail party: A speak er-independent audio-visual model for speech separation. ACT T rans. Graph. , 37(112), 2018. [13] M. Everingham, J. Sivic, and A. Zisserman. “Hello! my name is... buffy” automatic naming of characters in TV video. In Pr oc. British Mac hine V ision Confer ence , 2006. [14] M. Everingham, J. Sivic, and A. Zisserman. T aking the bite out of automatic naming of characters in TV video. Image and V ision Computing , 27(5), 2009. [15] J. W . Fisher III, T . Darrell, W . T . Freeman, and P . A. V iola. Learning joint statistical models for audio-visual fusion and segre gation. In Advances in neural information pr ocessing systems , pages 772–778, 2001. [16] J. L. Fleiss. Measuring nominal scale agreement among many raters. Psychological Bulletin , 76:378382, 1971. [17] G. Friedland, C. Y eo, and H. Hung. V isual speaker local- ization aided by acoustic models. In Pr oc. A CM Int. Conf. Multimedia , pages 195–202. A CM, 2009. [18] A. Gabbay , A. Shamir , and S. Peleg. V isual speech enhance- ment. In Pr oc. Interspeec h , 2018. [19] S. Galliano, G. Gravier , and L. Chaubard. The ESTER-2 ev aluation campaign for the rich transcription of french radio broadcasts. In Pr oc. Interspeec h , 2009. [20] I. D. Gebru, S. Ba, X. Li, and R. Horaud. Audio-visual speaker diarization based on spatiotemporal bayesian fusion. IEEE T rans. P attern Anal. Mach. Intell. , 39, 2017. [21] I. D. Gebru, S. Ba, X. Li, and R. Horaud. Audio-visual speaker diarization based on spatiotemporal bayesian fusion. IEEE T rans. P attern Anal. Mach. Intell. , 40(5):1086–1099, 2018. [22] A. Giraudel, M. Carre, V . Mapelli, J. Kahn, O. Galibert, and L. Quintard. The REPERE corpus : a multimodal corpus for person recognition. In Proc. Int. Conf. Language Resour ces and Evaluation , 2012. [23] A. Graves, M. G. Bellemare, J. Menick, R. Munos, and K. Kavukcuoglu. Automated curriculum learning for neu- ral networks. In Proc. International Confer ence on Machine Learning , 2017. [24] C. Gu, C. Sun, D. A. Ross, C. V ondrick, C. Pantofaru, Y . Li, S. V ijayanarasimhan, G. T oderici, S. Ricco, R. Sukthankar , C. Schmid, and J. Malik. A V A: A video dataset of spatio- temporally localized atomic visual actions. In Pr oc. IEEE Conf. Computer V ision and P attern Recognition , 2018. [25] T . J. Hazen, K. Saenko, C.-H. La, and J. R. Glass. A segment- based audio-visual speech recognizer: Data collection, de- velopment, and initial experiments. In Pr oc. Int. Conf. Mul- timodal Interfaces , pages 235–242. A CM, 2004. [26] K. Hoover , S. Chaudhuri, C. Pantofaru, M. Slaney , and I. Sturdy . Putting a face to the voice: Fusing audio and vi- sual signals across a video to determine speakers. In Proc. ICASSP , 2018. [27] A. G. Ho w ard, M. Zhu, B. Chen, D. Kalenichenko, W . W ang, T . W eyand, M. Andreetto, and H. Adam. Mobilenets: Ef fi- cient conv olutional neural networks for mobile vision appli- cations. CoRR , abs/1704.04861, 2017. [28] Y . Hu, J. S. Ren, J. Dai, C. Y uan, L. Xu, and W . W ang. Deep multimodal speaker naming. In Pr oc. A CM Int. Conf. on Multimedia , pages 1107–1110. A CM, 2015. [29] H. Hung and S. O. Ba. Speech/non-speech detection in meet- ings from automatically extracted low resolution visual fea- tures. T echnical Report Idiap-RR-20-2009, Idiap, 2009. [30] S. Levine, C. Finn, T . Darrell, and P . Abbeel. End-to-end training of deep visuomotor policies. JMLR , 17:1–40, 2016. [31] S. Le vine, P . Pastor , A. Krizhevsky , and D. Quillen. Learning hand-eye coordination for robotic grasping with deep learn- ing and large-scale data collection. In Proc. ISER , 2016. [32] D. Li, C. M. T askiran, N. Dimitrova, W . W ang, M. Li, and I. K. Sethi. Cross-modal analysis of audio-visual programs for speaker detection. In Pr oc. IEEE W orkshop Multimedia Signal Pr ocessing , 2005. [33] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua. A con v o- lutional neural network cascade for face detection. In Proc. IEEE Conf. Computer V ision and P attern Recognition , pages 5325–5334, 2015. [34] I. McCow an, J. Carletta, W . Kraaij, S. Ashby , S. Bourban, M. Flynn, M. Guillemot, T . Hain, J. Kadlec, V . Karaiskos, M. Kronenthal, G. Lathoud, M. Lincoln, A. Lisowska, W . Post, D. Reidsma, and P . W ellner . The AMI meeting cor- pus. In Pr oc. Measuring Behavior , 2005. [35] A. Nagrani, J. S. Chung, and A. Zisserman. V oxceleb: a large-scale speaker identification dataset. In Pr oc. Inter- speech , 2018. [36] H. J. Nock, G. Iyengar , and C. Neti. Speaker localisation us- ing audio-visual synchrony: An empirical study . In Int. Conf . Image V ideo Retrie val , pages 488–499. Springer , 2003. [37] A. Owens and A. A. Efros. Audio-visual scene analysis with self-supervised multisensory features. In Proc. Eur opean Confer ence on Computer V ision , 2018. [38] E. K. Patterson, S. Gurbuz, Z. Tufekci, and J. N. Gowdy . CU A VE: A new audio-visual database for multimodal human-computer interface research. In Pr oc. Int. Conf. Acoustics, Speech, and Signal Pr ocessing , pages 2017–2020. IEEE, 2002. [39] J. S. Ren, Y . Hu, Y .-W . T ai, C. W ang, L. Xu, W . Sun, and Q. Y an. Look, listen and learn-a multimodal lstm for speaker identification. In Pr oc. AAAI Conf. Artificial Intelligence , pages 3581–3587, 2016. [40] K. Saenko, K. Li v escu, M. Siracusa, K. W ilson, J. Glass, and T . Darrell. V isual speech recognition with loosely synchro- nized feature streams. In Pr oc. Int. Conf. Computer V ision , volume 2, pages 1424–1431. IEEE, 2005. [41] B. Shillingford, Y . Assael, M. W . Hoffman, T . Paine, C. Hughes, U. Prabhu, H. Liao, H. Sak, K. Rao, L. Ben- nett, M. Mulville, B. Coppin, B. Laurie, A. Senior, and N. de Freitas. Large-scale visual speech recognition. In arxiv .or g/abs/1807.05162 , 2018. [42] K. Shinoda. Speaker adaptation techniques for automatic speech recognition. In Pr oc. APSIP A ASC , 2011. [43] M. Slaney and M. Covell. Facesync: A linear operator for measuring synchronization of video facial images and audio tracks. In Advances in Neural Information Pr ocessing Sys- tems , pages 814–820, 2001. [44] K. Stefanov , J. Besko w , and G. Salvi. V ision-based activ e speaker detection in multiparty interaction. In Pr oc. Int. W orkshop Grounding Language Understanding , pages 47– 51, 2017. [45] K. Stefanov , A. Sugimoto, and J. Beskow . Look who’ s talking: V isual identification of the acti ve speaker in multi- party human-robot interaction. In Pr oc. W orkshop Advance- ments in Social Signal Pr ocessing for Multimodal Interac- tion , pages 22–27. A CM, 2016. [46] F . T ao and C. Busso. Bimodal recurrent neural network for audiovisual voice acti vity detection. In Pr oc. Interspeech , pages 1938–1942, 2017. [47] H. V ajaria, T . Islam, S. Sarkar, R. Sankar , and R. Kas- turi. Audio se gmentation and speaker localization in meeting videos. In P attern Recognition, 2006. ICPR 2006. 18th Inter - national Confer ence on , volume 2, pages 1150–1153. IEEE, 2006. [48] H. V ajaria, S. Sarkar , and R. Kasturi. Exploring co- occurence between speech and body movement for audio- guided video localization. IEEE T rans. Circuits Syst. V ideo T echnol. , 18(11):1608–1617, 2008. [49] M. Zelenak, H. Schulz, and J. Hernando. Speaker diarization of broadcast ne ws in albayzin 2010 ev aluation campaign. EURASIP J. on Audio, Speech and Music Pr ocessing , 1:1– 9, 2012. [50] C. Zhang, P . Y in, Y . Rui, R. Cutler, P . V iola, X. Sun, N. Pinto, and Z. Zhang. Boosting-based multimodal speaker detec- tion for distributed meeting videos. IEEE T rans. Multimedia , 10(8):1541–1552, 2008. A ppendix Section A contains additional information on the dense, spatio-temporal labels in the A V A-ActiveSpeak er dataset that we will release and the labeling process, and Section B adds supplementary information related to model perfor- mance on this dataset. A. Dataset Inf ormation Rating Interface: A larger image of the rating interface (Figure 1 in the main paper) is in Figure 8 , with UI com- ponents highlighted. Raters can jump to any point in the track using the timeline, modify the label, view the track in the context of the video, use keyboard shortcuts to view at different speeds. V ideos with labels visualized: A pair of clips with Ac- tiv eSpeaker labels visualized are in the video files linked below . The bounding box color indicates the label at each instant: red for “Not Speaking”, green for “Speaking and Audible”, and yellow for “Speaking b ut Not Audible”. 1. speaker-labeled-1 : A ”con versation” between 3 peo- ple. Near the end of this clip, the spoken content is replaced with music as an illustrativ e example for the “Speaking but not Audible” label. 2. speaker-labeled-2 : Audible speech between the two participants. Note that one of them speaks (“Mark me”) before entering the visual scene, and that por- tion of speech is not part of the labeled data, since the speaker was not visible. Release Data Format: Figure 9 shows an example entry and the interpretation of the comma-separated values. The full CSV file will be av ailable on the A V A website soon. Rating Guidance: Detailed instructions for a variety of cases were provided to raters. T able. 8 summarizes guid- ance used to decide what should be considered speaking. Additionally , speaking faces are audible if raters could as- certain that the subject’ s speech was audible in the audio; clearly dubbed speech, speakers not heard due to overlap- ping sounds, or if the audio had music (or other sounds) ov erlaid for cinematic effect should be labeled “Speaking but not Audible”. Raters had access to audio and video while making all decisions. A V A Action Label Differences The choice of the A V A corpus allo ws us to correlate ActiveSpeak er labels with previously-released action labels [ 24 ] (where annotators only had access to the visual modality) and speech activity Speaking Not Speaking • Short utterances ( e.g ., “Y es. ”, “Go. ” or “Hmm”) • Sighs, coughs, laughs, groans, grunts • Singing (with or with- out music) • Mouthing along with music • V ocalized communica- tion intent ( e.g ., scream to attract attention) • Non-spoken communi- cation (e.g. gesturing, wa ving) • Fillers (“um”, “ah”) • Humming T able 8: Rater guidance indicating to identify speaking in- stances. labels [ 8 ]. T able 2 notes that ∼ 17% of “talk-to” labels and ∼ 13% of “sing-to” in the A V A actions dataset were errors that do not correspond to someone speaking (audible or in- audible) in the Activ eSpeaker dataset. Belo w , we describe three conditions in the A V A actions dataset discov ered by cross-checking the action labels with our speaker labels. • Incorrect “talk-to” labels : Figure 10 sho ws instances where a face was not speaking but was labeled “talk- to”. These usually occur just outside the boundaries of a speaking segment. The A V A action annotators were misled by the lack of audio while labeling and proxim- ity to speaking frames. • Inaudible “talk-to” labels : Here, true semantics can- not be ascertained from visual-only labeling: the face looks like its speaking, but it is not heard in the audio which often contains ov erlaid music for cinematic ef- fect. e.g . the section starting at 23 seconds in speaker- labeled-1 . • Incorrect “sing-to” labels : Figure 12 shows cases where the specified entity was not actually singing; once again, the absence of audio makes it hard for the annotators to accurately determine when someone is singing or just lip-syncing along with the music. A V A Speech Label Differences: Section 4.2 of the main paper discusses the A V A-Activ eSpeaker labels in the con- text of the previously released speech activity labels [ 8 ]. One surprising observation was that a significant amount of time labeled as containing speech in A V A-Speech did not hav e an acti ve speak er at that instant in A V A-ActiveSpeak er (Figure 4 in main paper). A sampling of such cases sho ws that the shot often does not directly focus on the activ e speaker in movies for cinematic effect; viewers have enough context and voice recognition to know the speaker , any- way . Background music with vocals are labeled as contain- ing speech, b ut naturally cannot be associated with a visible speaker . This clip from the A V A dataset contains an illustra- tiv e example. It begins with off-screen speech, transitions Figure 8: The annotation interface for A V A-ActiveSpeak er , with the interface components marked with yellow boxes. As rating progresses, the labels are overlaid on the audio wa veform timeline - the snapshot here shows a fully labeled timeline. Raters can skip to any point in the video and the box around the subject’ s face corresponds to the color of the label at that instant. Raters can modify labels as necessary . Figure 9: A single line illustrating the format of the released CSV data, with the annotations indicating the function of each of the eight comma separated v alues. ( x 1 , y 1 ) and ( x 2 , y 2 ) are the normalized locations of the top left and bottom right of the bounding box. Figure 10: Frames with incorrect A V A action label “talk-to” when the subject (in the pink bounding box) wasn’t speaking. Figure 11: Frames with “talk-to” A V A action label where the subject appears to be speaking but their speech is not in the audio track, instead ov erlaid with music or sound ef fects for cinematic effect. Figure 12: Frames of “sing-to” A V A action labels where the subject was not actually singing. All examples have a musical context. (Left & Center) The subjects were dancing to music. (R) Subject is a conductor directing the musicians, with emphatic mouth (and body) motions. Figure 13: V isualizations of overlapping speaker instances. A green bounding box represents speaking and audible, yellow represents speaking and inaudible, red represents not speaking. Figure 14: (Left) Missed face detections in backlit conditions; (Center) A few missed detections in the back of a crowd; (Right) Missed detections as faces get smaller . to a scene with background music with vocals, and finally the riders of the car speak with their faces not visible. Overlapping Speakers: The detailed per-person labels allow us to identify segments with overlapping speakers, potentially interesting for audiovisual speech separation ef- forts. Figure 13 shows snapshots from such segments iden- tified with the dense labels in A V A-Acti veSpeak er . Missed Face T racks: Section 3 of the paper describes the automated process for obtaining the face tracks which form the basis of the labels in A V A-Activ eSpeaker . While the de- tection and tracking pipeline is state-of-the-art, the videos in this dataset contain a number of challenging cases such as crowded scenes, small faces, challenging lighting condi- tion, partially occluded faces, etc. , in conjunction with the varied resolutions of the video itself, many of them lower than the production quality of movies and TV sho ws of to- day . This leads to some missed face track detection which are not labeled. Figure 14 contains a sample of instances where faces were missed. B. Supplementary Results W e use the same abbreviations to denote model types here as in the main paper; V : visual-only model, A V : au- diovisual model, GR U: gated recurrent unit models, f M : number of frames in the stack input to the visual network. Model Comparison: Figure 15 contains the full R OC curves for T able 4 from the paper . In static models, per- formance keeps improving till M = 10 , and for each M , the corresponding A V curve is considerably better than V ; A V -GR U is ∼ 10% better TPR than V -GR U and ∼ 5% Figure 15: ROC curves for V and A V static and recurrent models, corresponding to T able 4 from the paper .; From left to right, (a) static V models, (b) static A V models, (c) recurrent V models, (d) recurrent A V models (f2 , f3 and f5 are on top of each other for recurrent models). Figure 16: ROC curves partitioned by background sound determined by A V A-Speech labels. From left to right, (a) static V models, (b) static A V models, (c) recurrent V models, (d) recurrent A V models. The × represents the p = 0 . 5 balanced accuracy point. Figure 17: R OC curv es for partitioned by face sizes, corresponding to T able 6 from the paper . From left to right, (a) static V models, (b) static A V models, (c) recurrent V models, (d) recurrent A V models. The × on each curve represents the p = 0 . 5 balanced accuracy point. better TPR than A V -static at 10% FPR. The same pat- tern holds with recurrent models, although performance im- prov ements saturate at 2 frames, indicating that only a short amount of history is needed. Effect of background noise: Figure 16 shows the full R OC curves for T able 5 from the paper . Unlike audio-based speech detectors’ performance reported in [ 8 ], both V and A V models show resilience to background sound. While V models are not af fected at all, A V models’ performance slightly dips in ov erlapping music and noise, although still outperforming V models. Effect of face size: Figure 17 sho ws R OC curves for T a- ble 6 of the paper , partitioned by face size: small ( < 64 pixels wide), medium ( > 64 , < 128 px) and large ( > 128 px, lar ger than model input). A V models clearly outperform V models: for GR U, absolute improv ement in TPR at 10% FPR is ∼ 10% for small faces, ∼ 15% for medium, ∼ 13% for large. The biggest dif ference in “medium” suggests that Figure 18: Frames where V model predictions were incorrect, while A V -GR U were correct. A V models can use audio to know if speech is occurring to correct f alse positi ves from V when there is no speech. Figure 19: Frames where A V -static-f10 models made errors, b ut A V -GRU-f2 got them right; GR U models seem to be captur - ing synchronization information beyond detecting speech. Figure 20: Frames where A V -GR U-f2 made errors; Left 2: small faces; Right 2: challenging overlaid speaking while other faces made lip mov ements with v ocalized sounds. this might be the sweet spot for the combined adv antage of recurrence and A V : for smaller faces, the visual information is harder to leverage for all models, while for larger faces, visual information is enough for V to close the gap. For A V models, FPR at the balanced accuracy point is nearly constant, while for V , they are more variable. For applications that mine data corresponding to speaking f aces (for tasks like synchronization [ 9 ], visual speech recogni- tion [ 41 ], enhancement [ 1 ]), these models can be deployed without needing additional calibration and hand-tuning. Examples of model predictions: Figure 18 shows frames where V model made errors while A V -GR U-f2 were correct. A V models appear more robust to pan angles and profiles (left two panels), can use audio context to kno w speech isn’t occurring (second from right), and are more robust to partial occlusions and motion around the face (right panel). Figure 19 shows frames where A V static models were wrong b ut A V GR U got them right. Improvements from static to GR U within A V models appear to be dri ven by an enhanced ability to understand synchronization between the audio and visuals, even though the models were not explic- itly trained for it. This makes the better models robust to noise in the audio domain (background music) as well as visual domain (partial occlusions). Figure 20 shows frames where A V -GR U models made the wrong prediction. Based on our sampling, there appear to be 2 clear modes of failure. One occurs when the faces are small and there is motion in more than one face (left 2 panels), where the model will pick both as speaking possi- bly due to not having a clear enough visual signal for who to associate the speech with. The other is when multiple sources are v ocal but only one is speaking and others are,. e.g ., laughing (right 2 panels). One way to alleviate some of these issues would be to explicitly add in augmentation at training time geared to ward enabling the model to learn explicit synchronization.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment