비대칭 신경망을 이용한 노드별 가변 활성화 함수와 효율적 프루닝
본 논문은 노드 인덱스에 따라 활성화 함수의 기울기를 다르게 설정함으로써 각 뉴런의 학습 민감도를 차등화하는 ‘비대칭 신경망’을 제안한다. 작은 인덱스의 뉴런은 높은 민감도를 갖게 되어 중요한 특징을 먼저 학습하고, 인덱스가 큰 뉴런은 덜 중요한 특징을 담당한다. 이러한 특성 정렬(feature‑sorting) 덕분에 중요도가 낮은 뉴런을 순차적으로 제거해도 성능 저하가 거의 없으며, 프루닝 후 재학습을 통해 원래의 정확도를 회복할 수 있다. …
저자: Jinhyeok Jang, Hyunjoong Cho, Jaehong Kim
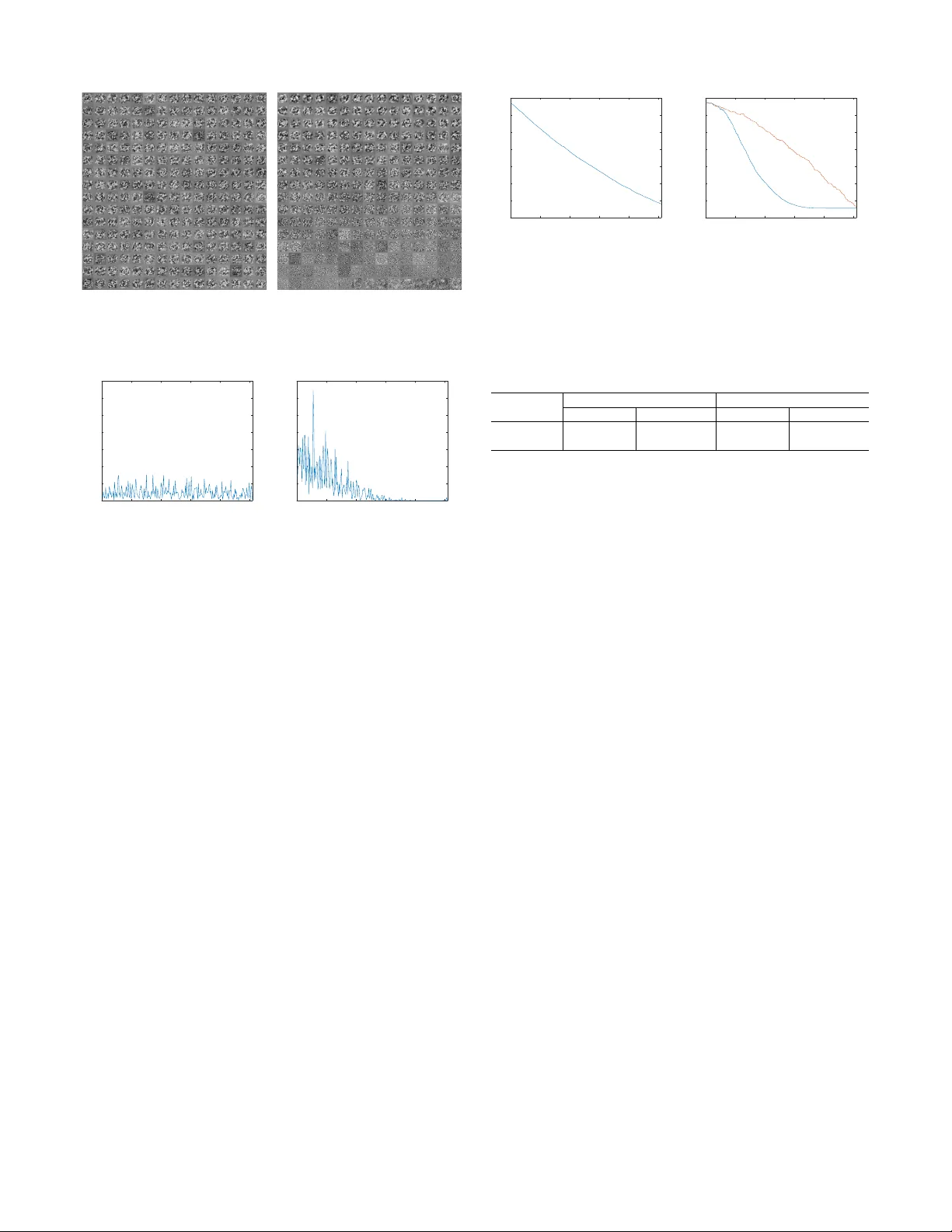
본 논문은 신경망의 모든 뉴런이 동일한 학습 능력을 갖는 전통적인 가정에 도전한다. 저자들은 각 레이어 내에서 뉴런마다 다른 활성화 함수를 적용함으로써, 뉴런별 민감도를 조절하는 ‘비대칭 신경망(asymmetric network)’을 설계한다. 구체적으로, 활성화 함수는 fᵢ(u)=sᵢ·f₀(u) 형태로 정의되며, 여기서 sᵢ는 1 ≥ s₁ ≥ s₂ ≥ … > 0인 감소하는 스칼라 파라미터이다. sᵢ가 클수록 함수의 기울기가 커져 역전파 시 가중치 업데이트가 크게 일어나며, 이는 해당 뉴런이 입력 특징을 더 빠르고 강하게 학습하도록 만든다.
수식 (8)–(13)에서 제시된 가중치 업데이트는 대각선 스케일링된 최급강하법으로 해석될 수 있다. 즉, 민감도가 높은 뉴런 방향으로는 비용 함수가 급격히 감소하고, 민감도가 낮은 방향으로는 완만하게 감소한다. 이로 인해 학습 과정에서 작은 인덱스 뉴런이 먼저 수렴하고, 큰 인덱스 뉴런은 뒤처지는 ‘학습 순서’가 자연스럽게 형성된다.
이론적 분석은 하나의 은닉층을 가진 선형 근사 모델을 이용해 수행된다. 입력‑출력 공분산 행렬 Σₓₓ, Σᵧᵧ와 교차공분산 Σᵧₓ를 정의하고, 비용 함수 E=‖Y−W₂DW₁X‖²를 최소화한다. 최소화 조건에서 네트워크 연산은 Σ의 고유벡터를 정렬된 형태로 근사한다. 특히, sᵢ가 1과 0 사이의 극단값을 가질 경우, 첫 번째 뉴런은 가장 큰 고유값에 대응하는 주성분을, 두 번째 뉴런은 두 번째 고유값에 대응하는 주성분을 학습한다는 점을 보인다. 이러한 ‘극단 경우’를 일반화하면, 비대칭 네트워크는 고유값이 큰 순서대로 특징을 학습한다는 ‘특징 정렬(feature‑sorting)’ 특성을 갖는다.
실험은 네 가지 주요 시나리오로 구성된다. 첫 번째는 Gaussian 데이터와 MNIST를 이용한 얕은 자동인코더 실험으로, 노드 인덱스가 낮은 뉴런이 재구성 오류에 큰 영향을 미치는 것을 확인한다. 두 번째는 CIFAR‑10 이미지 분류를 위한 깊은 CNN 실험으로, 비대칭 네트워크가 동일한 정확도를 유지하면서 40 % 이상의 파라미터를 제거할 수 있음을 보인다. 세 번째는 NTU RGB‑D 액션 인식 데이터셋을 사용한 3D CNN 실험으로, 프루닝 후에도 원본 모델 대비 1 % 미만의 정확도 손실만을 보였다. 네 번째는 VGG와 ResNet을 CK+ 얼굴 표정 데이터에 전이한 경우이며, 전이된 가중치를 비대칭 구조에 매핑한 뒤 프루닝을 수행했을 때, 파라미터 수가 50 % 이상 감소하면서도 원본 성능을 유지했다.
프루닝 절차는 매우 직관적이다. 먼저 검증 데이터셋을 이용해 목표 정확도를 설정한다. 그 후, 각 레이어를 노드 수가 많은 순서대로 선택하고, 해당 레이어에서 인덱스가 큰 뉴런부터 하나씩 제거한다. 제거 후 정확도가 목표 이하로 떨어지면 그 레이어의 프루닝을 중단하고, 이전 레이어로 이동한다. 최종적으로 남은 네트워크를 전체 데이터셋으로 재학습하면, 손실된 성능을 복구하면서도 훨씬 경량화된 모델을 얻는다. 이 과정은 별도의 중요도 지표(L1, L2, 헷시안 등)를 필요로 하지 않으며, 노드 인덱스 자체가 중요도 순서를 제공한다는 점에서 기존 프루닝 기법보다 구현이 간단하고 효율적이다.
비대칭 네트워크와 프루닝 기법을 기존 L1/L2 기반 방법과 비교했을 때, 동일한 압축률에서 정확도 저하가 현저히 적었다. 특히, 고차원 특징을 많이 포함하는 깊은 네트워크일수록 비대칭 구조가 제공하는 ‘우선순위 학습’ 효과가 두드러졌다.
하지만 몇 가지 한계도 존재한다. 첫째, sᵢ 파라미터를 사전에 설계해야 하며, 그 선택이 모델 성능에 큰 영향을 미친다. 둘째, 매우 깊은 네트워크에서는 초기 단계에서 민감도 차이가 과도하면 일부 뉴런이 거의 학습되지 않아 표현력이 제한될 수 있다. 셋째, 활성화 함수 f₀의 형태에 따라 기울기 소실 문제가 발생할 가능성이 있다. 향후 연구에서는 sᵢ를 학습 가능한 파라미터로 두어 자동 최적화를 시도하거나, 다양한 비선형 변환과 결합해 보다 유연한 비대칭 구조를 탐색할 필요가 있다.
결론적으로, 본 논문은 노드별 가변 활성화 함수를 통한 비대칭 학습 메커니즘을 제안하고, 이를 기반으로 한 프루닝 전략이 기존 방법보다 효율적이며 손실이 적은 모델 압축을 가능하게 함을 실험적으로 입증하였다. 이는 경량화가 요구되는 임베디드 시스템이나 모바일 디바이스에 적용할 수 있는 실용적인 접근법으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기