노이즈에 강한 화자 임베딩을 위한 다중작업 적대적 네트워크
본 논문은 화자 인증 시스템을 노이즈 환경에서도 견고하게 만들기 위해, 화자 임베딩을 추출하는 인코더와 화자 분류기, 그리고 노이즈 유형을 구분하는 판별기로 구성된 다중작업 적대적 네트워크(MT‑AN)를 제안한다. 인코더는 화자 정보를 보존하면서 노이즈 정보를 억제하도록 학습되며, 이를 위해 기존 교차 엔트로피 손실에 반대 라벨 손실(AL‑Loss)과 고정 라벨 손실(FL‑Loss)을 결합한 새로운 손실 함수를 사용한다. 또한 학습 정확도를 기…
저자: Jianfeng Zhou, Tao Jiang, Lin Li
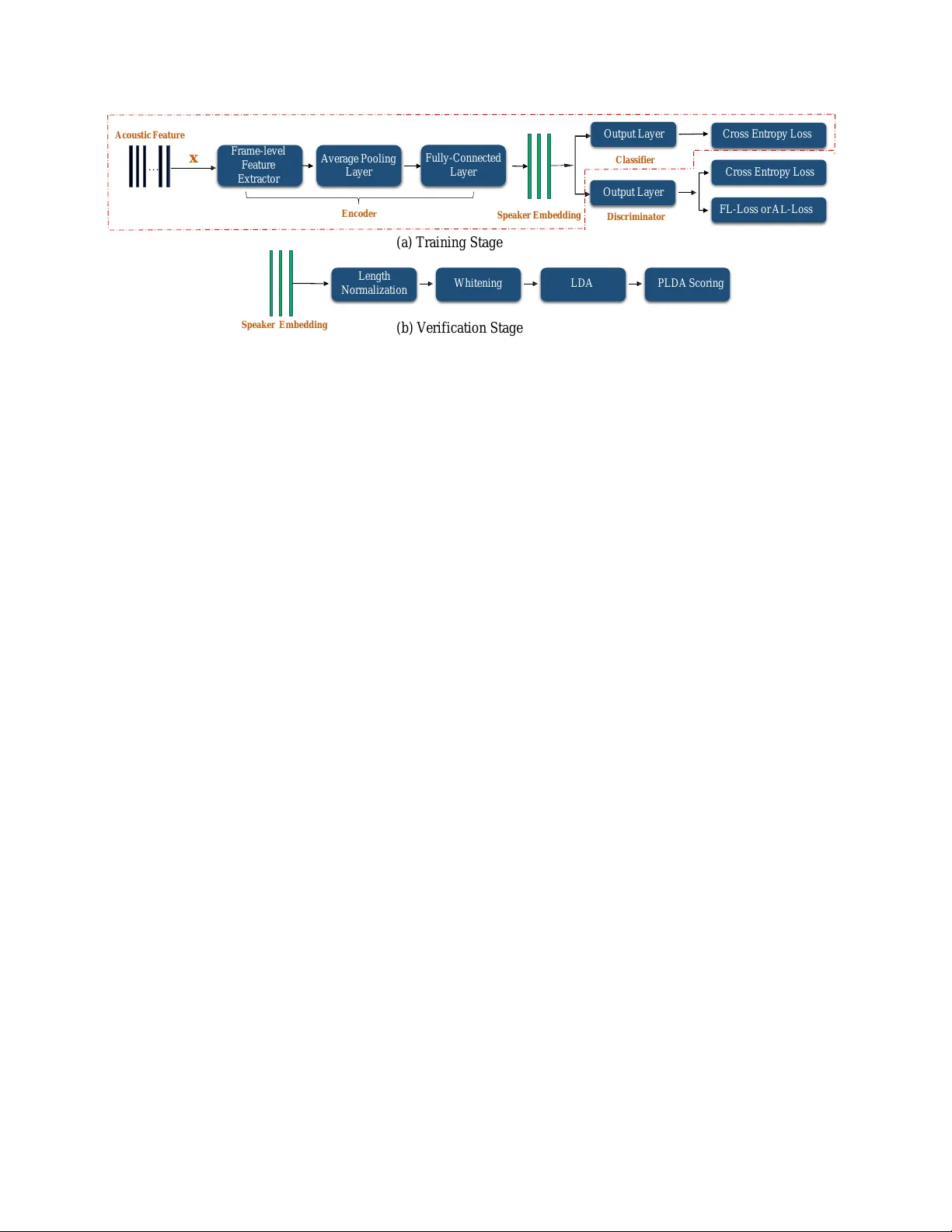
본 논문은 화자 인증 시스템이 실제 서비스 환경에서 마주하는 잡음에 대한 취약성을 극복하고자, 다중작업 적대적 네트워크(Multi‑Task Adversarial Network, MT‑AN)를 제안한다. MT‑AN은 크게 세 부분으로 구성된다. 첫 번째는 인코더(Encoder)로, 입력 음성의 23‑dimensional MFCC 프레임을 1‑D CNN을 통해 처리하고 평균 풀링을 거쳐 발화‑레벨 임베딩을 생성한다. 이 임베딩은 화자 정보를 최대한 보존하면서 잡음 정보를 억제하도록 학습된다. 두 번째는 화자 분류기(Classifier)이며, 인코더가 만든 임베딩을 받아 화자 라벨을 예측한다. 세 번째는 잡음 판별기(Discriminator)로, 동일 임베딩을 입력받아 잡음 종류(white, babble, cafeteria, callcenter, mensa)를 구분한다.
핵심 아이디어는 인코더가 잡음 판별기에 대해 적대적 학습을 수행한다는 점이다. 구체적으로, 화자 분류기와 인코더는 공동으로 화자 라벨에 대한 교차 엔트로피 손실(l_Cs)을 최소화한다. 반면, 잡음 판별기 D는 실제 잡음 라벨에 대한 교차 엔트로피 손실(l_Ds)을 최소화하지만, 인코더는 D가 잡음 라벨을 틀리게 예측하도록 손실을 최대화한다. 이를 위해 두 가지 변형 손실을 설계하였다.
첫 번째는 Fixed‑Label Loss(FL‑Loss)이다. FL‑Loss는 모든 입력을 “clean speech” 라벨에 고정시켜, 인코더가 잡음이 섞인 음성을 깨끗한 임베딩으로 매핑하도록 강제한다. 수식적으로는 기존 교차 엔트로피에 clean 라벨을 고정시킨 형태이며, 잡음 억제 효과가 강하다.
두 번째는 Anti‑Label Loss(AL‑Loss)이다. AL‑Loss는 원‑핫 잡음 라벨을 반전시킨 “반대 라벨”을 사용한다. 즉, 인코더는 D가 실제 라벨이 아닌 반대 라벨을 예측하도록 학습한다. 이 방식은 다중 클래스 잡음 상황에서도 균형 잡힌 적대적 압력을 제공한다.
전체 목표 함수는 l_adv = γ·l_Ds – β·l_var (var는 FL‑Loss 혹은 AL‑Loss) 형태이며, γ와 β는 각각 D와 인코더에 대한 스케일 파라미터이다. 최적화는 인코더와 D를 별개의 목표로 분리해 각각 최소화한다: 인코더는 l_Cs + β·l_var를 최소화하고, D는 γ·l_Ds를 최소화한다.
적대적 학습은 종종 불안정성을 초래한다. 저자들은 이를 해결하기 위해 학습 정확도(Training Accuracy)를 실시간 지표로 활용한다. 인코더가 잡음 라벨을 틀리게 만들수록 정확도가 낮아지고, D가 정확히 맞출수록 정확도가 높아진다. 일정 구간(K) 동안 평균 정확도가 사전에 정의한 하한 α(=0.4) 이하로 떨어지면 β를 감소시켜 인코더의 압력을 완화하고, 상한을 초과하면 γ를 감소시켜 D의 압력을 완화한다. 이렇게 동적 가중치 조절을 통해 적대적 게임이 한쪽으로 치우치는 현상을 방지하고, 전체 네트워크가 안정적으로 수렴하도록 만든다.
실험은 두 대규모 코퍼스, 영어 Librispeech와 중국어 Aishell‑1을 사용했다. 각각 5가지 잡음(white, babble, cafeteria, callcenter, mensa)과 0, 5, 10, 15, 20 dB SNR을 조합해 25개의 테스트 시나리오를 구성하였다. 학습 데이터는 원본을 1:5 비율로 나누어, 5/6에 잡음을 인위적으로 추가한 “noisy‑train”과 나머지 1/6의 깨끗한 데이터로 구성했다.
비교 대상은 (1) Clean‑trained CNN 베이스라인, (2) Noise‑mixed 학습(MIX) – 일반적인 데이터 증강 방식, (3) FL‑Loss 기반 MT‑AN, (4) AL‑Loss 기반 MT‑AN, (5) FL과 AL을 선형 회귀 기반 가중치 합성한 Fusion이다. 결과는 모든 잡음·SNR 조합에서 FL·AL 두 모델이 베이스라인과 MIX보다 현저히 낮은 EER을 기록했으며, 특히 저 SNR(0 dB)에서 평균 EER 감소율이 30% 이상이었다. Fusion 모델은 두 손실의 상보성을 활용해 추가적인 성능 향상을 보였다. 흥미롭게도 깨끗한 조건에서도 MT‑AN이 베이스라인보다 낮은 EER을 달성했는데, 이는 인코더가 잡음 억제 특성을 학습하면서 화자 구분 능력도 동시에 강화되었기 때문이다.
결론적으로, 이 연구는 (1) 다중작업 구조와 적대적 학습을 결합해 잡음에 강인한 화자 임베딩을 직접 학습한다는 새로운 패러다임을 제시하고, (2) 반대 라벨을 이용한 다중클래스 적대적 손실(AL‑Loss)을 설계했으며, (3) 학습 정확도 기반 동적 가중치 조절을 통해 훈련 안정성을 확보했다는 점에서 의미가 크다. 이러한 접근은 전통적인 전처리 기반 잡음 억제와 달리 프론트엔드 임베딩 자체를 잡음 불변 특성으로 만들기 때문에 실시간 서비스나 저전력 디바이스에 적용하기에 유리하다. 향후 연구에서는 더 낮은 SNR, 실시간 스트리밍, 그리고 화자 다중화, 감정 인식 등 다른 음성 처리 태스크로 확장할 가능성이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기