Training Multi-Task Adversarial Network for Extracting Noise-Robust Speaker Embedding
Under noisy environments, to achieve the robust performance of speaker recognition is still a challenging task. Motivated by the promising performance of multi-task training in a variety of image processing tasks, we explore the potential of multi-ta…
Authors: Jianfeng Zhou, Tao Jiang, Lin Li
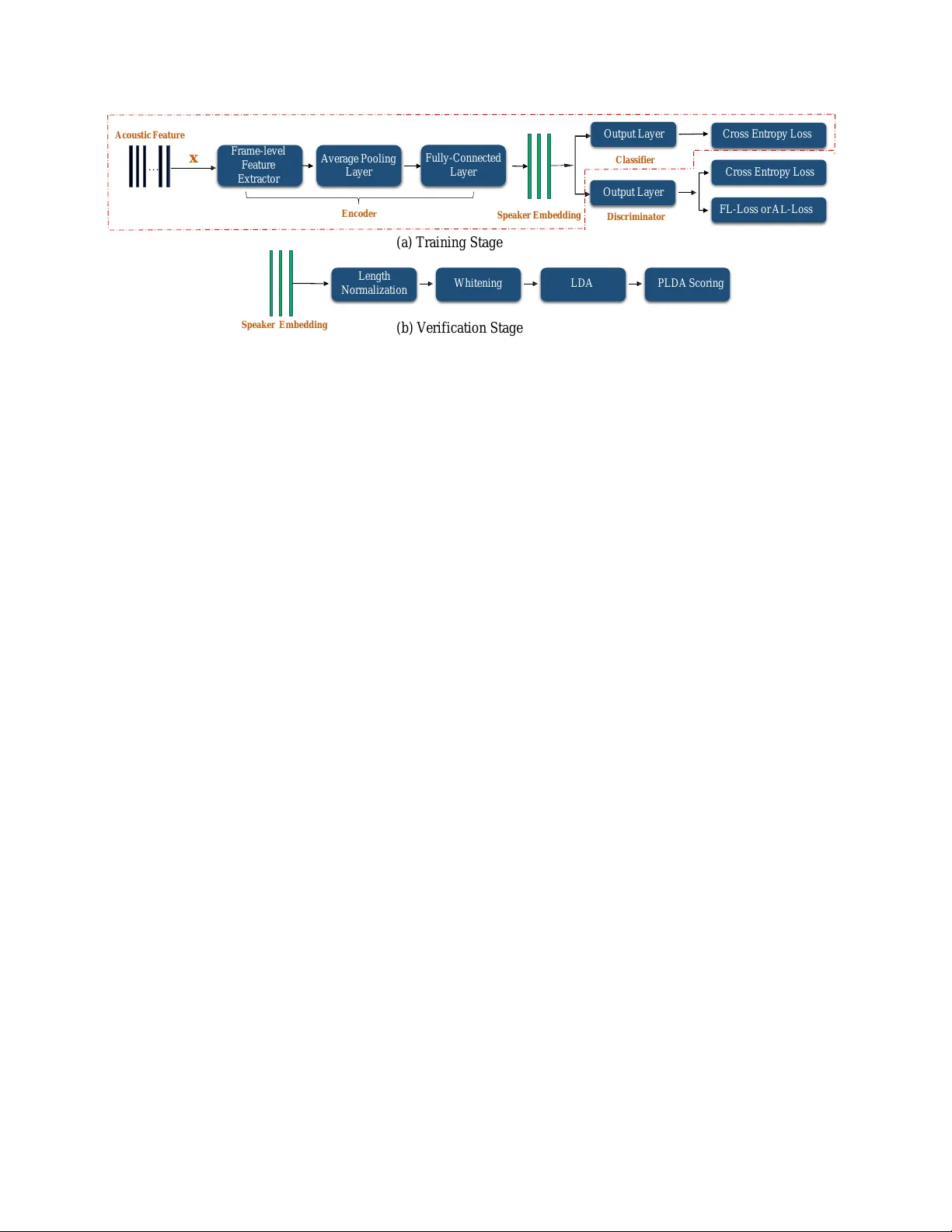
TRAINING MUL TI-T ASK AD VERSARIAL NETWORK FOR EXTRA CTING NOISE-R OBUST SPEAKER EMBEDDING Jianfeng Zhou 1 , T ao Jiang 2 , Lin Li ∗ 1 , Qingyang Hong ∗ 2 , Zhe W ang 3 , Bingyin Xia 3 1 College of Electronic Science and T echnology , Xiamen Univ ersity , China 2 School of Information Science and Engineering, Xiamen Uni versity , China 3 Media Coding T echnology Lab, Huawei Media T echnology Institute lilin@xmu.edu.cn, qyhong@xmu.edu.cn ABSTRA CT Under noisy en vironments, to achiev e the robust performance of speaker recognition is still a challenging task. Moti vated by the promising performance of multi-task training in a variety of image processing tasks, we explore the potential of multi- task adversarial training for learning a noise-rob ust speaker embedding. In this paper , we present a no vel framework that consists of three components: an encoder that extracts the noise-robust speaker embeddings; a classifier that classifies the speak ers; a discriminator that discriminates the noise type of the speak er embeddings. Additionally , we propose a train- ing strategy using the training accuracy as an indicator to sta- bilize the multi-class adversarial optimization process. W e conduct our experiments on the English and Mandarin cor- puses and the experimental results demonstrate that our pro- posed multi-task adversarial training method could greatly outperform the other methods without adversarial training in noisy en vironments. Furthermore, the experiments indicate that our method is also able to improve the speaker v erifica- tion performance under the clean condition. Index T erms — multi-task, speaker embedding, adversar - ial training, speaker verification 1. INTR ODUCTION The task of speaker verification is to verify the identity of speaker from a gi ven speech utterance. In the past decade, the i-vector system has achieved significant success in mod- eling speaker identity and channel variability in the i-vector space [1], which maps variable-length utterances into fixed- length vectors. Then the fixed-length vectors will be fed to a back-end classifier such as probabilistic linear discriminant analysis (PLD A) [2]. Recently , with the rise of deep learning [3] in various machine learning applications, the works [4, 5, 6] focused on using neural network to verify speakers ha ve explored its potential capability in speaker recognition tasks. More re- cently , man y studies [7, 8, 9] hav e concentrated on extract- ing utterance-le vel representation, which is known as speaker embedding, using neural networks combined with a pooling layer . This utterance-level representation can be further pro- cessed by fully-connected layers. Since proposed by Goodfellow et al. [10], generativ e ad- versarial networks (GAN) hav e become the focus of many studies in recent years. Its great success in image processing has inspired people to consider whether it can also be applied into the field of speech processing. In the paper [11], Zhang et al. attempted to use conditional GAN to solve the impact of performance degradation caused by the variable-duration of utterances. Ding et al. [12] proposed a multi-tasking GAN framew ork to extract the more distinctive speaker represen- tation. And Y u et al. [13] proposed to train an adversarial network for front-end denoising. In the field of speaker recognition, there is a large quantity of literature concerning the sharp de gradation of performance in the noisy environments. A common way to improve the robustness of the system is to train the system using a dataset consisting of clean and noisy data [14]. Speech enhancement is another way of denoising such as short-time spectral am- plitude minimum mean square error (STSA-MMSE) [15] and many DNN-based enhancement methods [16, 17, 18]. Unlike previous works denoising in the front-end, we plan to use a multi-task adversarial framework to extract the noise-robust speaker representation directly . In this paper , we borrow the adversarial training idea of GAN [10] and use the multi-task adv ersarial network (MT AN) structure to extract a noise-robust speaker embed- ding. The entire framew ork consists of three parts: an encoder that extracts the noise-rob ust speaker embeddings; a classifier that classifies the speak ers; a discriminator that discriminates the noise type of the speaker embeddings, which also plays the adversarial role combined with the encoder . In addition, we propose a new loss function, namely AL-Loss (anti-label loss), to realize the multi-class adversarial training. Further- more, in order to balance the adversarial training process, a new training strategy has been presented by employing the training accuracy as an indicator to judge whether the adversarial training has reached a balance. F r a m e - l ev el F e a t u r e E x t r a c t o r … Acousti c F e a t u r e A v e r a g e Po ol i ng L a y e r O ut pu t L a y e r C ro ss E n t r o p y L os s FL -Loss or A L -Loss C ro ss E n t r o p y L os s O ut pu t L a y e r S p e a k e r E m b e d d in g Encode r C la s s if ie r D is c r im in a to r S p e a k e r E m b e d d in g L e n g t h Norm aliza tio n W hi t e ni ng L D A P L D A S c o r i n g x F u l l y - C o n n e c t e d L a y e r (a) T raini ng Stage (b) V erific ati on Stage Fig. 1 . The frame work of our proposed multi-task adversarial network. 2. MUL TI-T ASK ADVERSARIAL NETWORK 2.1. CNN Based Embedding Learning CNN-based neural network architecture has proved its supe- rior performance in speaker verification tasks [7, 12]. In this work, we use the CNN-based architecture for speaker embed- ding learning which includes the encoder and classifier of the framew ork shown in the dotted line of Fig. 1 (a). The de- tails of the architecture are as follow . F our one-dimensional con volutional layers with 1*1 filter , 1 stride and 256 chan- nels follo wed by an av erage pooling layer which maps the frame-lev el feature to an utterance-lev el representation. Then, the speaker representation will be fed to the next two fully- connected layers with 256 and 1024 nodes in sequence. Fi- nally , the output layer with N s (the number of speakers in training data) nodes will take the speaker embeddings as in- put. The output of last hidden layer is extracted as utterance- lev el speaker embedding. Besides, batch normalization and RELU activ ation function are applied to all layers except the output layer . And the verification back-ends are sho wn in Fig.1 (b). 2.2. Multi-T ask Adversarial Network The entire architecture of MT AN is shown in Fig.1 (a). And the implementation details of the encoder and classifier ha ve been demonstrated in Section 2.1. As to the discriminator , it is just an output layer with M (the number of noise types in training data) nodes. The arro ws indicate the forward propa- gation direction. Giv en an input x ∈ R t ∗ m where t and m refer to the frame number and acoustic feature dimension of the utter - ance respectiv ely , the encoder maps it to a speaker embed- ding E ( x ) ∈ R n , where n is the dimension of latent embed- ding. Then the classifier and the discriminator try to predict the classes of E ( x ) . Since our goal is to encode speaker in- formation while eliminating performance degradation caused by noise, the encoder should extract a latent representation that is more discriminativ e for speaker and robust for noise. In order to achieve this goal, we use the multi-task adversarial network to learn discriminativ e speaker feature and simulta- neously improve its noise robustness. Specifically , we train the classifier cooperated with the encoder to extract discrimi- nativ e speak er feature. Besides, we play a minimax game by training discriminator to maximize the probability of assign- ing the correct noise label to the embedding extracted from the encoder and simultaneously training the encoder to maxi- mize the probability of assigning the wrong noise label to the embedding. 2.3. Loss Function In this work we consider cross entropy loss function and its two v ariants. For the cooperativ e training of the classifier and encoder , we directly minimize the cross entropy loss l C s (the superscript C means classifier). For multi-class adversarial training, the output of the discriminator will be fed to a cross entropy loss function l D s (the superscript D means for discrim- inator) and its v ariants including FL-Loss (fixed label loss) proposed in [13] and AL-Loss. The details of loss functions will be addressed in Section 2.3.1 and Section 2.3.2. Then a minimax game will be ex ecuted with the value function l adv , which can be formulated as follow: max E min D l adv = γ l D s − β l var (1) where γ and β are scale parameters and l var could be FL-Loss or AL-Loss. When training an adversarial network, rather than directly using the minimax loss, we split the optimiza- tion into two independent objecti ves, one for encoder and one for discriminator . Therefore, we train the encoder, discrimi- nator and classifier by min E ( l C s + β l var ) , min D γ l D s and min C l C s respectiv ely . 2.3.1. FL-Loss Compared with the cross entrop y loss function, FL-Loss uses the fixed label “clean speech” [13] for all inputs to train the encoder . It can be formulated as follow: l f l = − 1 N N X i =1 log e W T y c y i + b yc M P j =1 e W T j y i + b j (2) where N is the training batch size, y c is the label of clean speech and y i is the output of discriminator corresponding to y c . Besides, W and b are the weights and biases of the output layer . By assigning all data to clean speech label, the embed- ding from noisy speech will be close to the embedding from clean speech, since the constraint of FL-Loss will regularize the encoder to learn a map function from noisy data distribu- tion to clean data distribution. 2.3.2. AL-Loss Inspired by the FL-Loss function, we propose the AL-Loss function combined with the cross entropy loss function for the multi-class adversarial task, which is formulated as follo w: l al = − 1 N N X i =1 M X j =1 ,j 6 = m c log e W j T y j + b j M P k =1 e W T k y j + b k (3) where m c is the corresponding ground truth label of the i th sample. Unlik e FL-Loss, we use the anti-label to calculate the loss value, where the anti-label means flipping the value of each bit in one hot vector of the ground truth label. min E l anti means that the encoder would be trained to assign the output of encoder to a wrong noise label equally , i.e., after adver- sarial training, the embedding extracted from encoder will be in variant to the clean and noisy speech. 3. EXPERIMENTS 3.1. Dataset and Experimental Setting T o ev aluate the effecti ve performance of the proposed frame- work under the noisy en vironments, text-independent speaker verification (SV) experiments were conducted based on Aishell-1 [19] (a Mandarin corpus) and Librispeech [20] (an English corpus). The details of the two datasets are given as follows: • Aishell-1 : W e use the data of all three sets of Aishell-1 as the training data which contains about 141,600 utter- ances from 400 speakers and use another corpus named King-ASR-L-057 1 as the test data which contains 6,167 recordings from 20 speakers. 1 King-ASR-L-057: A Chinese Mandarin speech recognition database, which is av ailable at http://kingline.speechocean.com • Librispeech : In our experiments, we use the train- clean-500 part of Librispeech as training data which contains about 148,688 utterances from 1,166 speak- ers and the test-clean part as test data, which includes 2,020 recordings from 40 speakers. W e have made a noise corrupted version of the training data mentioned above by artificially adding different types of noise at different SNR lev els. The original training data was divided into two parts with scale of 1:5, in which fi ve out of six samples were added by the random noise. Speci- cally , the noisy utterances for training were made by adding one of the five noise types (white, babble, mensa, cafeteria, callcener) 2 randomly on the SNR levels of 10dB or 20dB. Howe ver , the noisy utterances for the speaker verification test were obtained by adding one of the fi ve noise types on the SNR lev els of 0dB, 5dB, 10dB, 15dB and 20dB respectiv ely . All audios were conv erted to the features of 23-dimensional MFCC with a frame-length of 25 ms and the frame shift of 10 ms. Then, a frame-lev el energy-based voice activity detector (V AD) selection w as conducted to the features. Our implementation was based on the T ensorflow toolkit. In our experiments, Adam optimizer with a learning rate of 0.01 was used for the back propagation. W e alternate between one step of optimizing the classifier and discriminator , and three steps of optimizing the encoder . 3.2. T raining Stability In this work, we use the training accuracy as an indicator to balance multi-class adversarial training. Specifically , we train the encoder to maximize the probability of assigning a speaker embedding to a wrong noise label, which means de- creasing the training accurac y . Howe ver , we also train the discriminator to correctly assign the embedding to the ground truth label, which means increasing the training accuracy . So the accurac y could indicate the situation of adv ersarial train- ing. The training accuracy k eeping in high or low all means adversarial training doesn’t get a balance. In addition, we set a lo wer threshold α and an upper threshold θ . When the av- erage of the training accuracy of the latest K iterations is less than the lower threshold or higher than the upper threshold, we adjust the loss proportional f actor of β l v ar and γ l s during the training. In our experiments, the encoder is trained better than discriminator , so we just set a lower threshold ( α = 0 . 4 ) to balance the adversarial training process. 3.3. Results and Comparisons In order to ev aluate the performance of our proposed multi- task adv ersarial network, fi ve systems were inv estigated: the 2 white and babble were collected by Guoning Hu, and could be downloaded at http://web .cse.ohio-state.edu/pnl. Besides, cafeteria noise, callcener , and mensa were provided by HUA WEI TECHNOLOGIES CO., L TD. T able 1 . EER(%) of the SV system using four methods for different noise types and SNRs (dB) on Librispeech. NOISE SNR Baseline MIX FL AL Fusion Clean - 6.49 7.08 5.54 5.89 5.15 White 00 39.95 30.74 30.30 30.64 27.77 05 38.42 21.68 18.91 19.36 16.39 10 35.69 15.25 12.23 13.07 10.35 15 29.50 12.23 9.90 10.35 8.71 20 24.26 10.89 8.86 9.46 7.77 mean 33.56 18.16 16.04 16.58 14.20 Babble 00 30.74 20.05 20.00 18.71 17.72 05 25.05 12.72 11.09 11.19 10.30 10 19.46 10.00 8.07 8.32 7.77 15 14.41 8.91 7.53 7.72 6.93 20 11.09 8.07 6.49 6.54 6.09 mean 20.10 11.95 10.64 10.50 9.76 Cafeteria 00 32.52 19.80 20.30 18.91 17.18 05 26.73 14.36 12.03 12.72 10.74 10 21.24 10.99 9.26 9.41 8.27 15 16.14 8.91 7.48 7.62 6.83 20 12.03 8.37 6.24 6.93 6.09 mean 21.73 12.49 11.06 11.12 9.82 Callcener 00 28.81 15.79 14.85 14.31 13.27 05 23.12 10.00 9.21 10.00 8.76 10 17.28 8.71 7.48 7.33 6.63 15 12.67 7.97 6.24 6.63 5.89 20 9.90 7.72 6.49 6.29 5.89 mean 18.36 10.04 8.85 8.91 8.09 Mensa 00 35.89 21.14 20.05 20.30 18.56 05 31.14 14.16 11.68 13.12 10.64 10 25.10 9.75 9.11 9.31 8.07 15 19.21 8.71 7.23 7.67 6.68 20 14.11 7.87 6.14 6.68 6.04 mean 25.09 12.33 10.84 11.42 10.00 CNN-based architecture trained using clean data (Baseline); the CNN-based architecture trained using the noise corrupted version of training data (MIX), which is a common method to improv e the performance under noisy en vironments; MT AN trained using FL-Loss (FL); MT AN trained using AL-Loss (AL); the fusion system of FL and AL (Fusion). Specifically , the stabilization strate gy proposed in this paper has been ap- plied to both FL system and AL system. The equal error rate (EER) values of dif ferent methods are shown in T able 1 and T able 2. The results show that our proposed methods achiev ed the best performance across all of the SNR le vels on Librispeech corpus and the lowest EERs across the majority of the SNR lev els on Aishell-1 corpus. W e can find that both FL sys- tem and AL system outperform the baseline and MIX system which indicates the adversarial training framework truly im- prov es the performance of SV task under the noisy environ- ments. Besides, we have conducted score-le vel fusion using the weights learned by linear re gression algorithm to make full use of complementary information between FL system and AL system, which could further improv e the discrimi- nativ e ability of the system. In addition, the results on two T able 2 . EER(%) of the SV system using four methods for different noise types and SNRs (dB) on Aishell-1. NOISE SNR Baseline MIX FL AL Fusion Clean - 7.33 10.39 4.63 4.64 3.82 White 00 41.66 29.52 36.01 34.60 33.82 05 39.54 26.51 30.83 27.42 27.03 10 36.14 24.28 24.23 21.52 21.14 15 31.88 20.72 19.02 17.75 16.02 20 26.30 17.90 14.86 13.03 12.14 mean 35.10 23.79 24.99 22.86 22.03 Babble 00 28.48 24.49 25.73 25.55 22.93 05 22.54 18.87 17.71 17.56 15.44 10 17.76 15.59 12.72 12.51 10.94 15 14.10 13.64 9.35 9.81 8.86 20 11.90 12.36 7.25 7.41 7.11 mean 18.96 16.99 14.55 14.57 13.02 Cafeteria 00 29.24 24.75 25.15 25.64 22.58 05 23.58 19.19 17.92 17.27 15.41 10 18.60 15.86 12.54 12.14 10.62 15 14.16 13.64 9.01 8.92 8.04 20 11.44 12.23 7.17 6.88 6.62 mean 19.40 17.13 14.36 14.17 12.65 Callcener 00 27.24 22.71 23.48 22.95 20.47 05 21.48 17.95 15.94 15.88 13.61 10 16.72 14.87 11.75 11.56 10.02 15 13.16 13.11 8.50 8.42 7.83 20 10.79 12.22 6.77 6.68 6.49 mean 17.88 16.17 13.29 13.10 11.68 Mensa 00 33.53 25.1 26.2 25.89 23.16 05 27.84 20.07 18.76 18.43 16.23 10 21.90 16.59 14.24 13.69 12.07 15 16.90 14.26 10.55 9.89 9.10 20 13.61 12.61 8.12 7.56 7.59 mean 22.76 17.73 15.57 15.09 13.63 corpuses in clean condition show that MT AN could outper- form the Baseline system and MIX system even in the clean condition. 4. CONCLUSIONS In this paper , we have e xplored the potential advantage of MT AN in extracting noise-robust speaker representation. The framew ork consists of three components: an encoder that extracts a noise-robust speaker embedding, a classifier and a discriminator that classifies the speaker and noise type of the speaker embedding respectively . Unlik e the traditional multi-task learning where the encoder is trained to maximize the classification accuracy of the classifier and discrimina- tor , MT AN is trained adv ersarially to the noise classification task, so that the embedding becomes speaker-discriminati ve and noise-robust. Experimental results on the Aishell-1 and Librispeech corpuses hav e sho wn that the proposed method could achiev e dominant results in clean condition and the most noisy en vironments. In the future, we will conduct the experiments in lower SNR condition and other related applications. 5. A CKNO WLEDGEMENTS This work was supported by the National Natural Science Foundation of China (Grant No.61876160). 6. REFERENCES [1] N. Dehak, P . J. K enny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verifi- cation, ” IEEE T ransactions on Audio, Speech, and Lan- guage Processing , v ol. 19, no. 4, pp. 788–798, 2011. [2] S. J. D Prince and J. H Elder , “Probabilistic linear discriminant analysis for inferences about identity , ” in Computer V ision, 2007. ICCV 2007. IEEE 11th Interna- tional Confer ence on . IEEE, 2007, pp. 1–8. [3] Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning, ” natur e , vol. 521, no. 7553, pp. 436, 2015. [4] E. V ariani, X. Lei, E. McDermott, I. Lopez-Moreno, and J. Gonzalez-Dominguez, “Deep neural networks for small footprint text-dependent speak er v erification., ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , 2014, vol. 14, pp. 4052–4056. [5] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer, “End-to-end text-dependent speaker verification, ” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on . IEEE, 2016, pp. 5115–5119. [6] K. Chen and A. Salman, “Learning speaker-specific characteristics with a deep neural architecture, ” IEEE T ransactions on Neural Networks , v ol. 22, no. 11, pp. 1744–1756, 2011. [7] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kannan, and Z. Zhu, “Deep speaker: an end-to- end neural speaker embedding system, ” arXiv pr eprint arXiv:1705.02304 , 2017. [8] K. Okabe, T . K oshinaka, and K. Shinoda, “ Attentiv e statistics pooling for deep speaker embedding, ” arXiv pr eprint arXiv:1803.10963 , 2018. [9] D. Snyder , D. Garcia-Romero, D. Pov ey , and S. Khu- danpur , “Deep neural network embeddings for text- independent speaker verification, ” in Pr oc. Interspeech , 2017, pp. 999–1003. [10] I. Goodfello w , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farle y , S. Ozair , A. Courville, and Y . Bengio, “Generativ e adversarial nets, ” in Advances in neur al in- formation pr ocessing systems , 2014, pp. 2672–2680. [11] J. Zhang, N. Inoue, and K. Shinoda, “I-vector trans- formation using conditional generati ve adversarial net- works for short utterance speaker verification, ” arXiv pr eprint arXiv:1804.00290 , 2018. [12] W . Ding and L. He, “Mtgan: Speaker verification through multitasking triplet generativ e adversarial net- works, ” arXiv pr eprint arXiv:1803.09059 , 2018. [13] H. Y u, Z. H. T an, Z. Ma, and J. Guo, “ Adversarial net- work bottleneck features for noise robust speaker verifi- cation, ” . [14] Y . Lei, L. Burget, and N. Schef fer, “ A noise robust i- vector e xtractor using vector taylor series for speaker recognition, ” in Acoustics, Speech and Signal Pr ocess- ing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 6788–6791. [15] J. S. Erkelens, R. C. Hendriks, R. Heusdens, and J. Jensen, “Minimum mean-square error estimation of discrete fourier coefficients with generalized gamma priors, ” IEEE T ransactions on Audio, Speec h, and Lan- guage Processing , v ol. 15, no. 6, pp. 1741–1752, 2007. [16] Y . Xu, J. Du, L. R. Dai, and C. H. Lee, “ A regression approach to speech enhancement based on deep neural networks, ” IEEE/ACM T ransactions on Audio, Speech and Language Processing (T ASLP) , vol. 23, no. 1, pp. 7–19, 2015. [17] O. Plchot, L. Burget, H. Aronowitz, and P . Matejka, “ Audio enhancing with dnn autoencoder for speaker recognition, ” in Acoustics, Speech and Signal Pr ocess- ing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 5090–5094. [18] F . W eninger, H. Erdogan, S. W atanabe, E. V incent, J. Le Roux, J. R. Hershey , and B. Schuller , “Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr , ” in International Confer- ence on Latent V ariable Analysis and Signal Separation . Springer , 2015, pp. 91–99. [19] H. Bu, J. Du, X. Na, B. W u, and H. Zheng, “ Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline, ” in 2017 20th Conference of the Oriental Chapter of the International Coor dinating Committee on Speec h Databases and Speech I/O Sys- tems and Assessment (O-COCOSD A) . IEEE, 2017, pp. 1–5. [20] V . Panayotov , G. Chen, D. Pov ey , and S. Khudanpur , “Librispeech: an asr corpus based on public domain au- dio books, ” in Acoustics, Speec h and Signal Pr ocess- ing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 5206–5210.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment