스피커 검증을 활용한 다중 화자 텍스트투스피치 전이 학습
본 논문은 화자 검증용으로 사전 학습된 스피커 인코더를 TTS 시스템에 전이시켜, 텍스트만으로도 훈련에 포함되지 않은 새로운 화자의 목소리를 몇 초의 참조 음성만으로 자연스럽게 합성할 수 있음을 보인다. 스피커 인코더, Tacotron‑2 기반 합성기, WaveNet 보코더를 각각 독립적으로 학습하고, 대규모(18 천명) 화자 데이터로 훈련된 인코더가 제로샷 화자 적응 성능을 크게 향상시킨다.
저자: Ye Jia, Yu Zhang, Ron J. Weiss
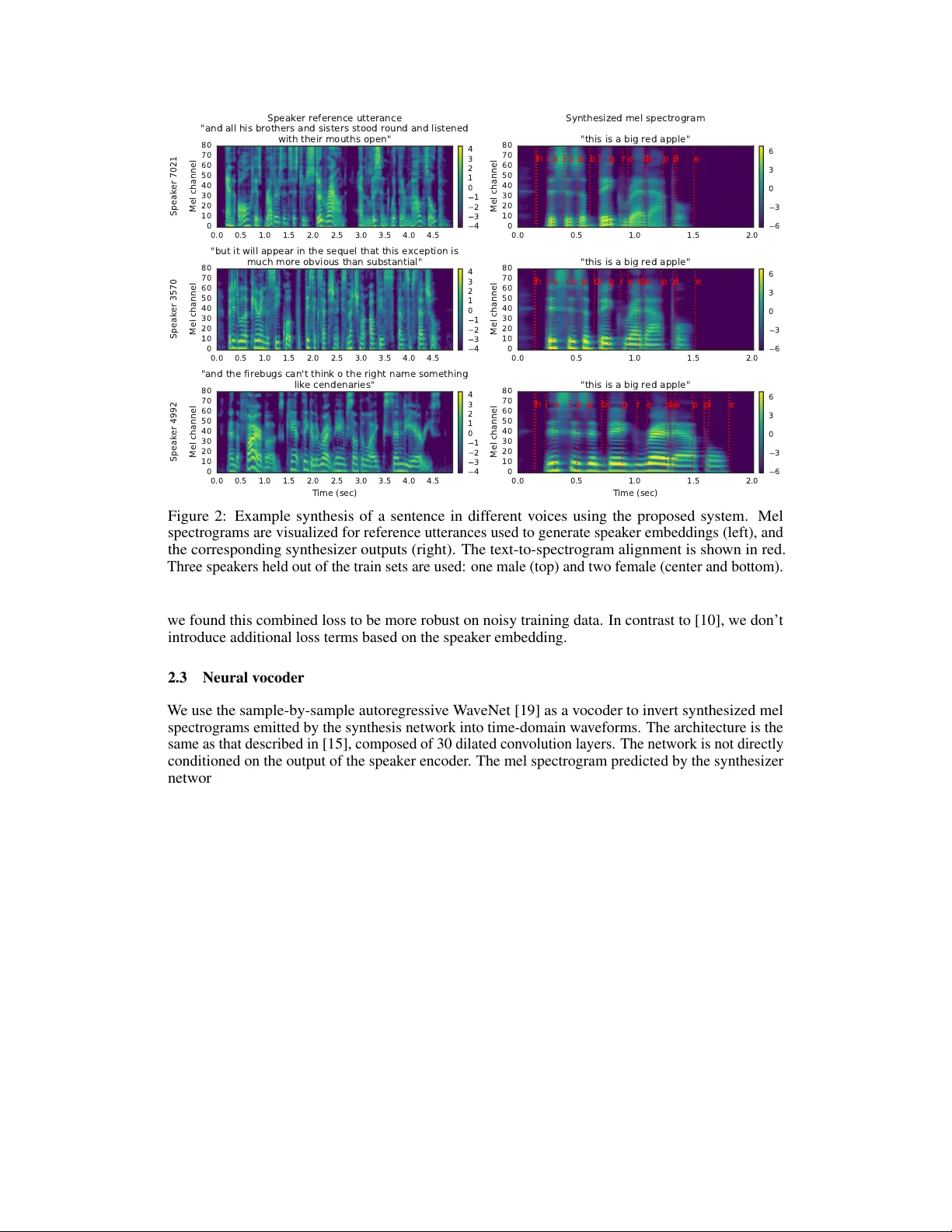
본 논문은 “Transfer Learning from Speaker Verification to Multispeaker Text‑to‑Speech Synthesis”라는 제목으로, 화자 검증용으로 사전 학습된 스피커 인코더를 활용해 다중 화자 TTS 시스템을 구축하고, 훈련에 포함되지 않은 새로운 화자에 대해 몇 초 정도의 참조 음성만으로 자연스러운 합성을 가능하게 하는 방법을 제시한다. 시스템은 크게 세 부분으로 구성된다. 첫 번째는 화자 인코더 네트워크로, 이는 텍스트와 무관하게 화자 검증(speaker verification) 과제에 최적화된 모델이다. 1.6초 길이의 로그‑멜 스펙트로그램을 입력받아 3개의 LSTM 레이어와 256차원 투사층을 거쳐 256차원 d‑vector를 출력한다. 학습은 generalized end‑to‑end loss를 사용해 동일 화자 간 코사인 유사도를 높이고, 서로 다른 화자 간 거리를 멀게 만든다. 이 인코더는 18 천명의 화자, 36 M 발화가 포함된 비전사 음성 검색 코퍼스에서 사전 학습되며, 텍스트 라벨이 전혀 필요하지 않다.
두 번째는 Tacotron‑2 기반의 시퀀스‑투‑시퀀스 합성기이다. 텍스트를 음소 시퀀스로 변환한 뒤 인코더에 입력하고, 화자 인코더에서 얻은 임베딩을 인코더 출력에 concat 형태로 결합한다. 이렇게 결합된 특징은 attention 메커니즘을 통해 디코더에 전달되어 멜 스펙트로그램을 예측한다. 손실 함수는 기존 L2 손실에 L1 손실을 추가해 잡음에 강인한 학습을 유도한다. 학습 과정에서 목표 음성의 동일 발화를 스피커 인코더에 통과시켜 얻은 임베딩을 사용하므로, 별도의 화자 라벨이 필요 없으며, 화자와 텍스트가 완전히 분리된 두 네트워크를 독립적으로 학습할 수 있다.
세 번째는 WaveNet 기반의 자동 회귀 보코더이다. 합성기가 생성한 멜 스펙트로그램만을 입력으로 받아 시간 도메인 파형을 생성한다. 보코더는 화자 임베딩을 직접 받지 않으며, 멜 스펙트로그램에 포함된 모든 화자 정보를 활용한다. 이를 통해 하나의 보코더가 다양한 화자의 음성을 고품질로 재현한다.
실험은 두 공개 데이터셋을 사용해 진행되었다. VCTK(44 시간, 109명, 영국식 영어)와 LibriSpeech(436 시간, 1 172명, 미국식 영어) 각각에 대해 합성기와 보코더를 별도로 학습하였다. VCTK는 깨끗한 음성이라 보코더를 실제 멜 스펙트로그램에 대해 학습했지만, LibriSpeech는 잡음이 포함돼 보코더를 합성기가 예측한 스펙트로그램에 대해 학습하였다. 스피커 인코더는 전용 음성 검색 코퍼스에서 사전 학습되었으며, 이는 TTS 훈련 데이터와 전혀 겹치지 않는다.
평가에서는 주관적 MOS(Mean Opinion Score)와 객관적 스피커 유사도 측정을 사용했다. 제안 모델은 기존 ‘embedding table’ 방식(각 화자마다 고정 임베딩을 학습)보다 unseen 화자에 대해 평균 0.2~0.3점 높은 MOS를 기록했으며, 특히 18 천명 규모의 화자 데이터로 사전 학습된 인코더를 사용할 경우 제로샷 적응 성능이 크게 향상되었다. 또한 임베딩을 무작위로 샘플링해도 인간 청취자가 구분 가능한 새로운 화자를 생성할 수 있음을 확인했다.
논문의 주요 기여는 다음과 같다. 첫째, 대규모 비전사 화자 데이터로 학습된 스피커 인코더가 TTS에 효과적으로 전이될 수 있음을 실증하였다. 둘째, 화자와 텍스트를 완전히 분리된 두 네트워크로 독립 학습함으로써 데이터 요구량을 크게 감소시켰다. 셋째, 제로샷 화자 적응을 위해 몇 초 정도의 참조 음성만 필요하도록 하여, 새로운 화자에 대한 빠르고 저비용의 합성을 가능하게 했다. 넷째, 임베딩 공간을 활용해 완전히 새로운 화자를 생성할 수 있는 가능성을 제시했다. 이러한 접근은 음성 합성 서비스의 확장성을 높이고, 저자원 언어·화자에 대한 접근성을 크게 개선할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기