Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained com…
Authors: Ye Jia, Yu Zhang, Ron J. Weiss
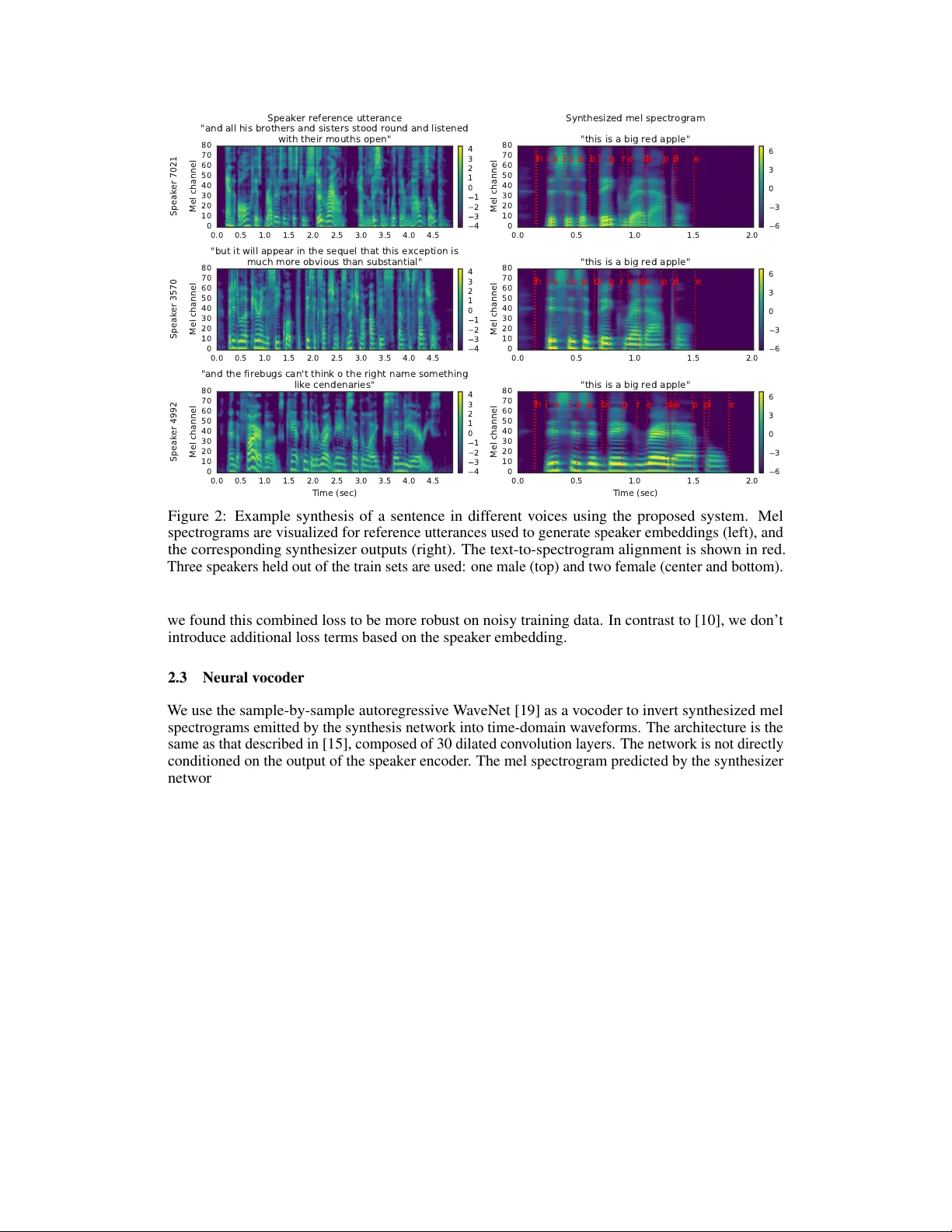
T ransfer Lear ning fr om Speaker V erification to Multispeaker T ext-T o-Speech Synthesis Y e Jia ∗ Y u Zhang ∗ Ron J. W eiss ∗ Quan W ang Jonathan Shen F ei Ren Zhifeng Chen Patrick Nguyen Ruoming P ang Ignacio Lopez Moreno Y onghui W u Google Inc. {jiaye,ngyuzh,ronw}@google.com Abstract W e describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of dif ferent speakers, including those unseen during training. Our system consists of three independently trained compo- nents: (1) a speaker encoder network , trained on a speaker verification task using an independent dataset of noisy speech without transcripts from thousands of speak ers, to generate a fixed-dimensional embedding v ector from only seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on T acotron 2 that generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressi v e W av eNet-based vocoder network that con verts the mel spectrogram into time domain wa veform samples. W e demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminati vely-trained speaker encoder to the multispeaker TTS task, and is able to synthesize natural speech from speakers unseen during training. W e quantify the importance of training the speaker encoder on a large and div erse speaker set in order to obtain the best generalization performance. Finally , we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation. 1 Introduction The goal of this work is to build a TTS system which can generate natural speech for a variety of speakers in a data efficient manner . W e specifically address a zero-shot learning setting, where a few seconds of untranscribed reference audio from a target speaker is used to synthesize ne w speech in that speaker’ s voice, without updating any model parameters. Such systems hav e accessibility applications, such as restoring the ability to communicate naturally to users who have lost their voice and are therefore unable to pro vide many new training examples. They could also enable new applications, such as transferring a voice across languages for more natural speech-to-speech translation, or generating realistic speech from text in low resource settings. Ho wever , it is also important to note the potential for misuse of this technology , for example impersonating someone’ s voice without their consent. In order to address safety concerns consistent with principles such as [ 1 ], we verify that v oices generated by the proposed model can easily be distinguished from real v oices. Synthesizing natural speech requires training on a large number of high quality speech-transcript pairs, and supporting many speakers usually uses tens of minutes of training data per speaker [ 8 ]. Recording a large amount of high quality data for man y speakers is impractical. Our approach is to decouple speaker modeling from speech synthesis by independently training a speaker -discriminati ve embedding network that captures the space of speaker characteristics and training a high quality TTS ∗ Equal contribution. 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada. model on a smaller dataset conditioned on the representation learned by the first netw ork. Decoupling the networks enables them to be trained on independent data, which reduces the need to obtain high quality multispeaker training data. W e train the speaker embedding network on a speaker verification task to determine if tw o different utterances were spoken by the same speaker . In contrast to the subsequent TTS model, this network is trained on untranscribed speech containing rev erberation and background noise from a large number of speak ers. W e demonstrate that the speaker encoder and synthesis networks can be trained on unbalanced and disjoint sets of speakers and still generalize well. W e train the synthesis network on 1.2K speakers and show that training the encoder on a much larger set of 18K speakers improv es adaptation quality , and further enables synthesis of completely nov el speakers by sampling from the embedding prior . There has been significant interest in end-to-end training of TTS models, which are trained directly from text-audio pairs, without depending on hand crafted intermediate representations [ 17 , 23 ]. T acotron 2 [ 15 ] used W aveNet [ 19 ] as a vocoder to in vert spectrograms generated by an encoder- decoder architecture with attention [ 3 ], obtaining naturalness approaching that of human speech by combining T acotron’ s [ 23 ] prosody with W aveNet’ s audio quality . It only supported a single speaker . Gibiansky et al. [ 8 ] introduced a multispeaker v ariation of T acotron which learned low-dimensional speaker embedding for each training speaker . Deep V oice 3 [ 13 ] proposed a fully conv olutional encoder-decoder architecture which scaled up to support o ver 2,400 speakers from LibriSpeech [ 12 ]. These systems learn a fixed set of speaker embeddings and therefore only support synthesis of voices seen during training. In contrast, V oiceLoop [ 18 ] proposed a no vel architecture based on a fixed size memory buf fer which can generate speech from voices unseen during training. Obtaining good results required tens of minutes of enrollment speech and transcripts for a new speak er . Recent extensions have enabled few-shot speaker adaptation where only a few seconds of speech per speaker (without transcripts) can be used to generate new speech in that speaker’ s v oice. [ 2 ] extends Deep V oice 3, comparing a speaker adaptation method similar to [ 18 ] where the model parameters (including speaker embedding) are fine-tuned on a small amount of adaptation data to a speaker encoding method which uses a neural network to predict speaker embedding directly from a spectrogram. The latter approach is significantly more data efficient, obtaining higher naturalness using small amounts of adaptation data, in as few as one or two utterances. It is also significantly more computationally efficient since it does not require hundreds of backpropag ation iterations. Nachmani et al. [ 10 ] similarly extended V oiceLoop to utilize a tar get speaker encoding network to predict a speaker embedding. This network is trained jointly with the synthesis network using a contrastiv e triplet loss to ensure that embeddings predicted from utterances by the same speaker are closer than embeddings computed from dif ferent speakers. In addition, a cycle-consistency loss is used to ensure that the synthesized speech encodes to a similar embedding as the adaptation utterance. A similar spectrogram encoder network, trained without a triplet loss, was shown to work for transferring target prosody to synthesized speech [ 16 ]. In this paper we demonstrate that training a similar encoder to discriminate between speakers leads to reliable transfer of speaker characteristics. Our work is most similar to the speaker encoding models in [ 2 , 10 ], except that we utilize a network independently-trained for a speaker verification task on a large dataset of untranscribed audio from tens of thousands of speakers, using a state-of-the-art generalized end-to-end loss [ 22 ]. [ 10 ] incorporated a similar speaker-discriminati v e representation into their model, howe ver all components were trained jointly . In contrast, we e xplore transfer learning from a pre-trained speaker v erification model. Doddipatla et al. [ 7 ] used a similar transfer learning configuration where a speaker embedding computed from a pre-trained speaker classifier was used to condition a TTS system. In this paper we utilize an end-to-end synthesis network which does not rely on intermediate linguistic features, and a substantially dif ferent speaker embedding network which is not limited to a closed set of speakers. Furthermore, we analyze how quality v aries with the number of speakers in the training set, and find that zero-shot transfer requires training on thousands of speakers, many more than were used in [7]. 2 Multispeaker speech synthesis model Our system is composed of three independently trained neural networks, illustrated in Figure 1: (1) a recurrent speaker encoder , based on [ 22 ], which computes a fixed dimensional vector from a speech 2 speaker reference wav eform Speaker Encoder grapheme or phoneme sequence Encoder concat Attention Decoder Synthesizer V ocoder wav eform speaker embedding log-mel spectrogram Figure 1: Model o vervie w . Each of the three components are trained independently . signal, (2) a sequence-to-sequence synthesizer , based on [ 15 ], which predicts a mel spectrogram from a sequence of grapheme or phoneme inputs, conditioned on the speaker embedding vector , and (3) an autoregressi ve W aveNet [ 19 ] vocoder , which con verts the spectrogram into time domain wav eforms. 1 2.1 Speaker encoder The speaker encoder is used to condition the synthesis network on a reference speech signal from the desired tar get speaker . Critical to good generalization is the use of a representation which captures the characteristics of different speakers, and the ability to identify these characteristics using only a short adaptation signal, independent of its phonetic content and background noise. These requirements are satisfied using a speaker-discriminati ve model trained on a text-independent speaker v erification task. W e follow [ 22 ], which proposed a highly scalable and accurate neural network frame work for speaker verification. The network maps a sequence of log-mel spectrogram frames computed from a speech utterance of arbitrary length, to a fix ed-dimensional embedding v ector , kno wn as d-vector [ 20 , 9 ]. The network is trained to optimize a generalized end-to-end speaker verification loss, so that embeddings of utterances from the same speaker ha ve high cosine similarity , while those of utterances from different speak ers are far apart in the embedding space. The training dataset consists of speech audio examples se gmented into 1.6 seconds and associated speaker identity labels; no transcripts are used. Input 40-channel log-mel spectrograms are passed to a network consisting of a stack of 3 LSTM layers of 768 cells, each followed by a projection to 256 dimensions. The final embedding is created by L 2 -normalizing the output of the top layer at the final frame. During inference, an arbitrary length utterance is broken into 800ms windo ws, ov erlapped by 50%. The network is run independently on each window , and the outputs are av eraged and normalized to create the final utterance embedding. Although the network is not optimized directly to learn a representation which captures speaker characteristics relev ant to synthesis, we find that training on a speaker discrimination task leads to an embedding which is directly suitable for conditioning the synthesis network on speaker identity . 2.2 Synthesizer W e extend the recurrent sequence-to-sequence with attention T acotron 2 architecture [ 15 ] to support multiple speakers follo wing a scheme similar to [ 8 ]. An embedding v ector for the tar get speaker is concatenated with the synthesizer encoder output at each time step. In contrast to [ 8 ], we find that simply passing embeddings to the attention layer, as in Figure 1, con verges across dif ferent speakers. W e compare two variants of this model, one which computes the embedding using the speaker encoder , and a baseline which optimizes a fixed embedding for each speaker in the training set, essentially learning a lookup table of speaker embeddings similar to [8, 13]. The synthesizer is trained on pairs of text transcript and target audio. At the input, we map the text to a sequence of phonemes, which leads to faster con vergence and improv ed pronunciation of rare words and proper nouns. The network is trained in a transfer learning configuration, using a pretrained speaker encoder (whose parameters are frozen) to extract a speaker embedding from the target audio, i.e. the speaker reference signal is the same as the target speech during training. No e xplicit speaker identifier labels are used during training. T arget spectrogram features are computed from 50ms windows computed with a 12.5ms step, passed through an 80-channel mel-scale filterbank followed by log dynamic range compression. W e extend [ 15 ] by augmenting the L 2 loss on the predicted spectrogram with an additional L 1 loss. In practice, 1 See https://google.github.io/tacotron/publications/speaker_adaptation for samples. 3 0.0 0.5 1.0 1.5 2.0 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e Synthesized mel spectrogram "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 0 10 20 30 40 50 60 70 80 Speaker 7021 Mel channel Speaker reference utterance "and all his brothers and sisters stood round and listened with their mouths open" 4 3 2 1 0 1 2 3 4 0.0 0.5 1.0 1.5 2.0 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 0 10 20 30 40 50 60 70 80 Speaker 3570 Mel channel "but it will appear in the sequel that this exception is much more obvious than substantial" 4 3 2 1 0 1 2 3 4 0.0 0.5 1.0 1.5 2.0 Time (sec) 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 Time (sec) 0 10 20 30 40 50 60 70 80 Speaker 4992 Mel channel "and the firebugs can't think o the right name something like cendenaries" 4 3 2 1 0 1 2 3 4 Figure 2: Example synthesis of a sentence in different voices using the proposed system. Mel spectrograms are visualized for reference utterances used to generate speaker embeddings (left), and the corresponding synthesizer outputs (right). The text-to-spectrogram alignment is shown in red. Three speakers held out of the train sets are used: one male (top) and two female (center and bottom). we found this combined loss to be more rob ust on noisy training data. In contrast to [ 10 ], we don’t introduce additional loss terms based on the speaker embedding. 2.3 Neural vocoder W e use the sample-by-sample autoregressi ve W aveNet [ 19 ] as a v ocoder to in vert synthesized mel spectrograms emitted by the synthesis network into time-domain wav eforms. The architecture is the same as that described in [ 15 ], composed of 30 dilated con volution layers. The network is not directly conditioned on the output of the speaker encoder . The mel spectrogram predicted by the synthesizer network captures all of the relev ant detail needed for high quality synthesis of a variety of voices, allowing a multispeak er v ocoder to be constructed by simply training on data from many speak ers. 2.4 Inference and zer o-shot speaker adaptation During inference the model is conditioned using arbitrary untranscribed speech audio, which does not need to match the text to be synthesized. Since the speaker characteristics to use for synthesis are inferred from audio, it can be conditioned on audio from speakers that are outside the training set. In practice we find that using a single audio clip of a few seconds duration is suf ficient to synthesize ne w speech with the corresponding speaker characteristics, representing zero-shot adaptation to novel speakers. In Section 3 we ev aluate ho w well this process generalizes to pre viously unseen speakers. An example of the inference process is visualized in Figure 2, which sho ws spectrograms synthesized using sev eral dif ferent 5 second speaker reference utterances. Compared to those of the female (center and bottom) speakers, the synthesized male (top) speak er spectrogram has noticeably lo wer fundamental frequency , visible in the denser harmonic spacing (horizontal stripes) in lo w frequencies, as well as formants, visible in the mid-frequency peaks present during vo wel sounds such as the ‘i’ at 0.3 seconds – the top male F 2 is in mel channel 35, whereas the F 2 of the middle speaker appears closer to channel 40. Similar differences are also visible in sibilant sounds, e.g. the ‘s’ at 0.4 seconds contains more energy in lower frequencies in the male v oice than in the female v oices. Finally , the characteristic speaking rate is also captured to some extent by the speaker embedding, as can be seen 4 T able 1: Speech naturalness Mean Opinion Score (MOS) with 95% confidence interv als. System VCTK Seen VCTK Unseen LibriSpeech Seen LibriSpeech Unseen Ground truth 4.43 ± 0.05 4.49 ± 0.05 4.49 ± 0.05 4.42 ± 0.07 Embedding table 4.12 ± 0.06 N/A 3 . 90 ± 0 . 06 N/A Proposed model 4.07 ± 0.06 4.20 ± 0.06 3 . 89 ± 0 . 06 4 . 12 ± 0 . 05 by the longer signal duration in the bottom row compared to the top two. Similar observ ations can be made about the corresponding reference utterance spectrograms in the right column. 3 Experiments W e used two public datasets for training the speech synthesis and vocoder networks. VCTK [ 21 ] contains 44 hours of clean speech from 109 speakers, the majority of which have British accents. W e do wnsampled the audio to 24 kHz, trimmed leading and trailing silence (reducing the median duration from 3.3 seconds to 1.8 seconds), and split into three subsets: train, validation (containing the same speakers as the train set) and test (containing 11 speakers held out from the train and validation sets). LibriSpeech [ 12 ] consists of the union of the two “clean” training sets, comprising 436 hours of speech from 1,172 speakers, sampled at 16 kHz. The majority of speech is US English, ho we ver since it is sourced from audio books, the tone and style of speech can differ significantly between utterances from the same speaker . W e resegmented the data into shorter utterances by force aligning the audio to the transcript using an ASR model and breaking se gments on silence, reducing the median duration from 14 to 5 seconds. As in the original dataset, there is no punctuation in transcripts. The speaker sets are completely disjoint among the train, validation, and test sets. Many recordings in the LibriSpeech clean corpus contain noticeable en vironmental and stationary background noise. W e preprocessed the target spectrogram using a simple spectral subtraction [ 4 ] denoising procedure, where the background noise spectrum of an utterance was estimated as the 10th percentile of the energy in each frequency band across the full signal. This process was only used on the synthesis target; the original noisy speech w as passed to the speaker encoder . W e trained separate synthesis and vocoder netw orks for each of these two corpora. Throughout this section, we used synthesis networks trained on phoneme inputs, in order to control for pronunciation in subjecti ve evaluations. F or the VCTK dataset, whose audio is quite clean, we found that the vocoder trained on ground truth mel spectrograms worked well. Ho we ver for LibriSpeech, which is noisier , we found it necessary to train the v ocoder on spectrograms predicted by the synthesizer network. No denoising was performed on the target wa v eform for vocoder training. The speaker encoder was trained on a proprietary voice search corpus containing 36M utterances with median duration of 3.9 seconds from 18K English speakers in the United States. This dataset is not transcribed, but contains anon ymized speaker identities. It is nev er used to train synthesis networks. W e primarily rely on crowdsourced Mean Opinion Score (MOS) ev aluations based on subjecti ve listening tests. All our MOS ev aluations are aligned to the Absolute Cate gory Rating scale [ 14 ], with rating scores from 1 to 5 in 0.5 point increments. W e use this framew ork to ev aluate synthesized speech along two dimensions: its naturalness and similarity to real speech from the target speaker . 3.1 Speech naturalness W e compared the naturalness of synthesized speech using synthesizers and vocoders t rained on VCTK and LibriSpeech. W e constructed an ev aluation set of 100 phrases which do not appear in any training sets, and e v aluated two sets of speak ers for each model: one composed of speakers included in the train set (Seen), and another composed of those that were held out (Unseen). W e used 11 seen and unseen speakers for VCTK and 10 seen and unseen speakers for LibriSpeech (Appendix D). F or each speaker , we randomly chose one utterance with duration of about 5 seconds to use to compute the speaker embedding (see Appendix C). Each phrase was synthesized for each speaker , for a total of about 1,000 synthesized utterances per ev aluation. Each sample was rated by a single rater , and each ev aluation was conducted independently: the outputs of different models were not compared directly . 5 T able 2: Speaker similarity Mean Opinion Score (MOS) with 95% confidence interv als. System Speaker Set VCTK LibriSpeech Ground truth Same speaker 4 . 67 ± 0 . 04 4 . 33 ± 0 . 08 Ground truth Same gender 2 . 25 ± 0 . 07 1 . 83 ± 0 . 07 Ground truth Different gender 1 . 15 ± 0 . 04 1 . 04 ± 0 . 03 Embedding table Seen 4.17 ± 0.06 3 . 70 ± 0 . 08 Proposed model Seen 4.22 ± 0.06 3 . 28 ± 0 . 08 Proposed model Unseen 3 . 28 ± 0 . 07 3 . 03 ± 0 . 09 Results are shown in T able 1, comparing the proposed model to baseline multispeaker models that utilize a lookup table of speaker embeddings similar to [ 8 , 13 ], b ut otherwise have identical architectures to the proposed synthesizer network. The proposed model achieved about 4.0 MOS in all datasets, with the VCTK model obtaining a MOS about 0.2 points higher than the LibriSpeech model when e v aluated on seen speakers. This is the consequence of two drawbacks of the LibriSpeech dataset: (i) the lack of punctuation in transcripts, which makes it dif ficult for the model to learn to pause naturally , and (ii) the higher level of background noise compared to VCTK, some of which the synthesizer has learned to reproduce, despite denoising the training targets as described abo ve. Most importantly , the audio generated by our model for unseen speakers is deemed to be at least as natural as that generated for seen speakers. Surprisingly , the MOS on unseen speakers is higher than that of seen speakers, by as much as 0.2 points on LibriSpeech. This is a consequence of the randomly selected reference utterance for each speaker , which sometimes contains uneven and non-neutral prosody . In informal listening tests we found that the prosody of the synthesized speech sometimes mimics that of the reference, similar to [ 16 ]. This effect is larger on LibriSpeech, which contains more varied prosody . This suggests that additional care must be taken to disentangle speaker identity from prosody within the synthesis network, perhaps by inte grating a prosody encoder as in [ 16 , 24 ], or by training on randomly paired reference and target utterances from the same speak er . 3.2 Speaker similarity T o ev aluate ho w well the synthesized speech matches that from the target speaker , we paired each synthesized utterance with a randomly selected ground truth utterance from the same speaker . Each pair is rated by one rater with the follo wing instructions: “Y ou should not judge the content, grammar , or audio quality of the sentences; instead, just focus on the similarity of the speakers to one another . ” Results are shown in T able 2. The scores for the VCTK model tend to be higher than those for LibriSpeech, reflecting the cleaner nature of the dataset. This is also e vident in the higher ground truth baselines on VCTK. For seen speakers on VCTK, the proposed model performs about as well as the baseline which uses an embedding lookup table for speaker conditioning. Howe ver , on LibriSpeech, the proposed model obtained a lower similarity MOS than the baseline, which is likely due to the wider degree of within-speaker v ariation (Appendix B), and background noise level in the dataset. On unseen speakers, the proposed model obtains lo wer similarity between ground truth and synthe- sized speech. On VCTK, the similarity score of 3.28 is between “moderately similar” and “very similar” on the ev aluation scale. Informally , it is clear that the proposed model is able to transfer the broad strokes of the speaker characteristics for unseen speakers, clearly reflecting the correct gender , pitch, and formant ranges (as also visualized in Figure 2). But the significantly reduced similarity scores on unseen speakers suggests that some nuances, e.g. related to characteristic prosody , are lost. The speaker encoder is trained only on North American accented speech. As a result, accent mismatch constrains our performance on speaker similarity on VCTK since the rater instructions did not specify how to judge accents, so raters may consider a pair to be from different speakers if the accents do not match. Indeed, examination of rater comments sho ws that our model sometimes produced a different accent than the ground truth, which led to lo wer scores. Howe ver , a fe w raters commented that the tone and inflection of the voices sounded v ery similar despite dif ferences in accent. As an initial e v aluation of the ability to generalize to out of domain speak ers, we used synthesizers trained on VCTK and LibriSpeech to synthesize speakers from the other dataset. W e only varied the train set of the synthesizer and vocoder networks; both models used an identical speaker encoder . As 6 T able 3: Cross-dataset e valuation on naturalness and speak er similarity for unseen speakers. Synthesizer T raining Set T esting Set Naturalness Similarity VCTK LibriSpeech 4 . 28 ± 0 . 05 1 . 82 ± 0 . 08 LibriSpeech VCTK 4 . 01 ± 0 . 06 2 . 77 ± 0 . 08 T able 4: Speaker v erification EERs of different synthesizers on unseen speak ers. Synthesizer T raining Set T raining Speakers SV -EER on VCTK SV -EER on LibriSpeech Ground truth – 1.53% 0.93% VCTK 98 10.46% 29.19% LibriSpeech 1.2K 6.26% 5.08% shown in T able 3, the models were able to generate speech with the same degree of naturalness as on unseen, but in-domain, speak ers sho wn in T able 1. Ho we ver , the LibriSpeech model synthesized VCTK speakers with significantly higher speaker similarity than the VCTK model is able to synthesize LibriSpeech speakers. The better generalization of the LibriSpeech model suggests that training the synthesizer on only 100 speakers is insuf ficient to enable high quality speaker transfer . 3.3 Speaker verification As an objecti ve metric of the degree of speaker similarity between synthesized and ground truth audio for unseen speakers, we e valuated the ability of a limited speaker v erification system to distinguish synthetic from real speech. W e trained a new eval-only speaker encoder with the same network topology as Section 2.1, but using a different training set of 28M utterances from 113K speakers. Using a different model for e valuation ensured that metrics were not only valid on a specific speaker embedding space. W e enroll the voices of 21 real speakers: 11 speakers from VCTK, and 10 from LibriSpeech, and score synthesized wa v eforms against the set of enrolled speak ers. All enrollment and v erification speakers are unseen during synthesizer training. Speaker v erification equal error rates (SV -EERs) are estimated by pairing each test utterance with each enrollment speaker . W e synthesized 100 test utterances for each speaker , so 21,000 or 23,100 trials were performed for each ev aluation. As shown in T able 4, as long as the synthesizer was trained on a sufficiently lar ge set of speakers, i.e. on LibriSpeech, the synthesized speech is typically most similar to the ground truth v oices. The LibriSpeech synthesizer obtains similar EERs of 5-6% using reference speakers from both datasets, whereas the one trained on VCTK performs much worse, especially on out-of-domain LibriSpeech speakers. These results are consistent with the subjective e valuation in T able 3. T o measure the difficulty of discriminating between real and synthetic speech for the same speaker , we performed an additional ev aluation with an expanded set of enrolled speakers including 10 synthetic versions of the 10 real LibriSpeech speakers. On this 20 v oice discrimination task we obtain an EER of 2.86%, demonstrating that, while the synthetic speech tends to be close to the target speaker (cosine similarity > 0.6, and as in T able 4), it is nearly al ways e ven closer to other synthetic utterances for the same speaker (similarity > 0.7). From this we can conclude that the proposed model can generate speech that resembles the tar get speaker , but not well enough to be confusable with a real speaker . 3.4 Speaker embedding space V isualizing the speaker embedding space further contextualizes the quantiti ve results described in Section 3.2 and 3.3. As shown in Figure 3, dif ferent speakers are well separated from each other in the speaker embedding space. The PCA visualization (left) shows that synthesized utterances tend to lie very close to real speech from the same speaker in the embedding space. Howe ver , synthetic utterances are still easily distinguishable from the real human speech as demonstrated by the t-SNE visualization (right) where utterances from each synthetic speaker form a distinct cluster adjacent to a cluster of real utterances from the corresponding speaker . 7 Female Male PCA Human Synthesized Female Male t-SNE Human Synthesized Figure 3: V isualization of speaker embeddings extracted from LibriSpeech utterances. Each color corresponds to a dif ferent speaker . Real and synthetic utterances appear nearby when the y are from the same speaker , howe ver real and synthetic utterances consistently form distinct clusters. T able 5: Performance using speaker encoders (SEs) trained on dif ferent datasets. Synthesizers are all trained on LibriSpeech Clean and ev aluated on held out speakers. LS: LibriSpeech, VC: V oxCeleb . SE T raining Set Speakers Embedding Dim Naturalness Similarity SV -EER LS-Clean 1.2K 64 3 . 73 ± 0 . 06 2 . 23 ± 0 . 08 16.60% LS-Other 1.2K 64 3 . 60 ± 0 . 06 2 . 27 ± 0 . 09 15.32% LS-Other + VC 2.4K 256 3 . 83 ± 0 . 06 2 . 43 ± 0 . 09 11.95% LS-Other + VC + VC2 8.4K 256 3 . 82 ± 0 . 06 2 . 54 ± 0 . 09 10.14% Internal 18K 256 4 . 12 ± 0 . 05 3 . 03 ± 0 . 09 5.08% Speakers appear to be well separated by gender in both the PCA and t-SNE visualizations, with all female speakers appearing on the left, and all male speakers appearing on the right. This is an indication that the speaker encoder has learned a reasonable representation of speaker space. 3.5 Number of speaker encoder training speakers It is likely that the ability of the proposed model to generalize well across a wide variety of speakers is based on the quality of the representation learned by the speaker encoder . W e therefore explored the ef fect of the speaker encoder training set on synthesis quality . W e made use of three additional training sets: (1) LibriSpeech Other , which contains 461 hours of speech from a set of 1,166 speakers disjoint from those in the clean subsets, (2) V oxCeleb [ 11 ], and (3) V oxCeleb2 [ 6 ] which contain 139K utterances from 1,211 speakers, and 1.09M utterances from 5,994 speakers, respecti vely . T able 5 compares the performance of the proposed model as a function of the number of speakers used to train the speaker encoder . This measures the importance of speaker di versity when training the speaker encoder . T o av oid ov erfitting, the speaker encoders trained on small datasets (top two rows) use a smaller network architecture (256-dim LSTM cells with 64-dim projections) and output 64 dimensional speaker embeddings. W e first e v aluate the speaker encoder trained on LibriSpeech Clean and Other sets, each of which contain a similar number of speak ers. In Clean, the speaker encoder and synthesizer are trained on the same data, a baseline similar to the non-fine tuned speaker encoder from [ 2 ], except that it is trained discriminati vely as in [ 10 ]. This matched condition gi ves a slightly better naturalness and a similar similarity score. As the number of training speakers increases, both naturalness and similarity improv e significantly . The objectiv e EER results also improv e alongside the subjecti ve e valuations. These results hav e an important implication for multispeaker TTS training. The data requirement for the speaker encoder is much cheaper than full TTS training since no transcripts are necessary , and the audio quality can be lo wer than for TTS training. W e hav e sho wn that it is possible to synthesize v ery 8 T able 6: Speech from fictitious speakers compared to their nearest neighbors in the train sets. Synthesizer was trained on LS Clean. Speaker Encoder was trained on LS-Other + VC + VC2. Nearest neighbors in Cosine similarity SV -EER Naturalness MOS Synthesizer train set 0.222 56.77% 3 . 65 ± 0 . 06 Speaker Encoder train set 0.245 38.54% natural TTS by combining a speaker encoder network trained on large amounts of untranscribed data with a TTS network trained on a smaller set of high quality data. 3.6 Fictitious speakers Bypassing the speaker encoder network and conditioning the synthesizer on random points in the speaker embedding space results in speech from fictitious speakers which are not present in the train or test sets of either the synthesizer or the speak er encoder . This is demonstrated in T able 6, which compares 10 such speakers, generated from uniformly sampled points on the surface of the unit hypersphere, to their nearest neighbors in the training sets of the component networks. SV -EERs are computed using the same setup as Section 3.3 after enrolling v oices of the 10 nearest neighbors. Even though these speakers are totally fictitious, the synthesizer and the vocoder are able to generate audio as natural as for seen or unseen real speakers. The lo w cosine similarity to the nearest neighbor training utterances and very high EER indicate that they are indeed distinct from the training speakers. 4 Conclusion W e present a neural network-based system for multispeaker TTS synthesis. The system combines an independently trained speaker encoder network with a sequence-to-sequence TTS synthesis network and neural vocoder based on T acotron 2. By le veraging the kno wledge learned by the discriminativ e speaker encoder , the synthesizer is able to generate high quality speech not only for speakers seen during training, but also for speakers nev er seen before. Through ev aluations based on a speaker verification system as well as subjecti ve listening tests, we demonstrated that the synthesized speech is reasonably similar to real speech from the target speak ers, e ven on such unseen speak ers. W e ran experiments to analyze the impact of the amount of data used to train the dif ferent components, and found that, giv en sufficient speaker di versity in the synthesizer training set, speaker transfer quality could be significantly improv ed by increasing the amount of speaker encoder training data. T ransfer learning is critical to achieving these results. By separating the training of the speaker encoder and the synthesizer , the system significantly lowers the requirements for multispeaker TTS training data. It requires neither speaker identity labels for the synthesizer training data, nor high quality clean speech or transcripts for the speak er encoder training data. In addition, training the components independently significantly simplifies the training configuration of the synthesizer network compared to [ 10 ] since it does not require additional triplet or contrastiv e losses. Howe ver , modeling speak er variation using a lo w dimensional vector limits the ability to le verage lar ge amounts of reference speech. Improving speaker similarity gi ven more than a few seconds of reference speech requires a model adaptation approach as in [2], and more recently in [5]. Finally , we demonstrate that the model is able to generate realistic speech from fictitious speakers that are dissimilar from the training set, implying that the model has learned to utilize a realistic representation of the space of speaker v ariation. The proposed model does not attain human-lev el naturalness, despite the use of a W av eNet vocoder (along with its very high inference cost), in contrast to the single speaker results from [ 15 ]. This is a consequence of the additional difficulty of generating speech for a variety of speak ers given significantly less data per speaker , as well as the use of datasets with lo wer data quality . An additional limitation lies in the model’ s inability to transfer accents. Giv en suf ficient training data, this could be addressed by conditioning the synthesizer on independent speaker and accent embeddings. Finally , we note that the model is also not able to completely isolate the speaker v oice from the prosody of the reference audio, a similar trend to that observed in [16]. 9 Acknowledgements The authors thank Heiga Zen, Y uxuan W ang, Samy Bengio, the Google AI Perception team, and the Google TTS and DeepMind Research teams for their helpful discussions and feedback. References [1] Artificial Intelligence at Google – Our Principles. https://ai.google/principles/ , 2018. [2] Sercan O Arik, Jitong Chen, Kainan Peng, W ei Ping, and Y anqi Zhou. Neural voice cloning with a few samples. arXiv pr eprint arXiv:1802.06006 , 2018. [3] Dzmitry Bahdanau, K yunghyun Cho, and Y oshua Bengio. Neural machine translation by jointly learning to align and translate. In Pr oceedings of ICLR , 2015. [4] Stev en Boll. Suppression of acoustic noise in speech using spectral subtraction. IEEE T ransac- tions on Acoustics, Speech, and Signal Pr ocessing , 27(2):113–120, 1979. [5] Y utian Chen, Y annis Assael, Brendan Shillingford, David Budden, Scott Reed, Heiga Zen, Quan W ang, Luis C Cobo, Andrew T rask, Ben Laurie, et al. Sample efficient adapti ve text-to-speech. arXiv pr eprint arXiv:1809.10460 , 2018. [6] Joon Son Chung, Arsha Nagrani, and Andre w Zisserman. V oxCeleb2: Deep speaker recognition. In Interspeech , pages 1086–1090, 2018. [7] Rama Doddipatla, Norbert Braunschweiler , and Ranniery Maia. Speaker adaptation in dnn- based speech synthesis using d-vectors. In Proc. Interspeech , pages 3404–3408, 2017. [8] Andre w Gibiansky , Sercan Arik, Gre gory Diamos, John Miller, Kainan Peng, W ei Ping, Jonathan Raiman, and Y anqi Zhou. Deep V oice 2: Multi-speaker neural te xt-to-speech. In I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30 , pages 2962–2970. Curran Associates, Inc., 2017. [9] Georg Heigold, Ignacio Moreno, Samy Bengio, and Noam Shazeer . End-to-end text-dependent speaker verification. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE Interna- tional Confer ence on , pages 5115–5119. IEEE, 2016. [10] Eliya Nachmani, Adam Polyak, Y ani v T aigman, and Lior W olf. Fitting new speak ers based on a short untranscribed sample. arXiv pr eprint arXiv:1802.06984 , 2018. [11] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. V oxCeleb: A large-scale speaker identification dataset. arXiv pr eprint arXiv:1706.08612 , 2017. [12] V assil Panayoto v , Guoguo Chen, Daniel Pove y , and Sanjeev Khudanpur . LibriSpeech: an ASR corpus based on public domain audio books. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confer ence on , pages 5206–5210. IEEE, 2015. [13] W ei Ping, Kainan Peng, Andrew Gibiansky , Sercan O. Arik, Ajay Kannan, Sharan Narang, Jonathan Raiman, and John Miller . Deep V oice 3: 2000-speaker neural te xt-to-speech. In Pr oc. International Confer ence on Learning Representations (ICLR) , 2018. [14] ITUT Rec. P . 800: Methods for subjecti ve determination of transmission quality . International T elecommunication Union, Geneva , 1996. [15] Jonathan Shen, Ruoming Pang, Ron J. W eiss, Mike Schuster , Navdeep Jaitly , Zongheng Y ang, Zhifeng Chen, Y u Zhang, Y uxuan W ang, RJ Skerry-Ryan, Rif A. Saurous, Y annis Agiomyrgiannakis, and Y onghui. W u. Natural TTS synthesis by conditioning W av eNet on mel spectrogram predictions. In Proc. IEEE International Conference on Acoustics, Speech, and Signal Pr ocessing (ICASSP) , 2018. [16] RJ Skerry-Ryan, Eric Battenber g, Y ing Xiao, Y uxuan W ang, Daisy Stanton, Joel Shor , Ron J. W eiss, Rob Clark, and Rif A. Saurous. T ow ards end-to-end prosody transfer for e xpressi ve speech synthesis with Tacotron. arXiv pr eprint arXiv:1803.09047 , 2018. 10 [17] Jose Sotelo, Soroush Mehri, Kundan Kumar , João Felipe Santos, K yle Kastner , Aaron Courville, and Y oshua Bengio. Char2W av: End-to-end speech synthesis. In Pr oc. International Confer ence on Learning Repr esentations (ICLR) , 2017. [18] Y ani v T aigman, Lior W olf, Adam Polyak, and Eliya Nachmani. V oiceLoop: V oice fitting and synthesis via a phonological loop. In Pr oc. International Conference on Learning Repr esenta- tions (ICLR) , 2018. [19] Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V in yals, Alex Grav es, Nal Kalchbrenner , Andrew Senior , and K oray Kavukcuoglu. W av eNet: A generative model for raw audio. CoRR abs/1609.03499 , 2016. [20] Ehsan V ariani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier Gonzalez- Dominguez. Deep neural networks for small footprint text-dependent speak er verification. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Conference on , pages 4052–4056. IEEE, 2014. [21] Christophe V eaux, Junichi Y amagishi, Kirsten MacDonald, et al. CSTR VCTK Corpus: English multi-speaker corpus for CSTR v oice cloning toolkit, 2017. [22] Li W an, Quan W ang, Alan Papir , and Ignacio Lopez Moreno. Generalized end-to-end loss for speaker verification. In Pr oc. IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP) , 2018. [23] Y uxuan W ang, RJ Sk erry-Ryan, Daisy Stanton, Y onghui W u, Ron J. W eiss, Navdeep Jaitly , Zongheng Y ang, Y ing Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Y annis Agiomyrgiannakis, Rob Clark, and Rif A. Saurous. T acotron: T ow ards end-to-end speech synthesis. In Pr oc. Interspeech , pages 4006–4010, August 2017. [24] Y uxuan W ang, Daisy Stanton, Y u Zhang, RJ Skerry-Ryan, Eric Battenberg, Joel Shor , Y ing Xiao, Fei Ren, Y e Jia, and Rif A Saurous. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. arXiv pr eprint arXiv:1803.09017 , 2018. 11 A ppendix A Additional joint training baselines T able 7: Speech naturalness and speaker similarity Mean Opinion Score (MOS) with 95% confidence intervals of baseline models where the speaker encoder and synthesizer networks are trained jointly (top tw o ro ws). Included for comparison are the separately trained baseline from T able 5 (middle row) as well as the embedding lookup table baseline and proposed model from T ables 1 and 2 (bottom two rows). All but the bottom row , are trained entirely on LibriSpeech. The bottom row uses a speaker encoder trained on a separate speaker corpus. All ev aluations are on LibriSpeech. Naturalness MOS Similarity MOS System Embedding Dim Seen Unseen Seen Unseen Joint training 64 3.72 ± 0.06 3.59 ± 0.07 2.47 ± 0.08 2.44 ± 0.09 Joint training + speaker loss 64 3.71 ± 0.06 3.71 ± 0.06 2.82 ± 0.08 2.12 ± 0.08 Separate training (T able 5) 64 3.88 ± 0.06 3.73 ± 0.06 2.64 ± 0.08 2.23 ± 0.08 Embedding table (T ables 1,2) 64 3 . 90 ± 0 . 06 N/A 3 . 70 ± 0 . 08 N/A Proposed model (T ables 1,2,5) 256 3 . 89 ± 0 . 06 4 . 12 ± 0 . 05 3 . 28 ± 0 . 08 3 . 03 ± 0 . 09 Although separate training of the speak er encoder and synthesizer networks is necessary if the speaker encoder is trained on a larger corpus of untranscribed speech, as described in Section 3.5, in this section we ev aluate the effecti v eness of joint training of the speaker encoder and synthesizer networks as a baseline, similar to [10]. W e train on the Clean subset of LibriSpeech, containing 1.2K speakers, and use a speaker embedding dimension of 64 following Section 3.5. W e compare tw o baseline jointly-trained systems: one without any constraints on the output of the speaker encoder , analogous to [ 16 ], and another with an additional speaker discrimination loss formed by passing the 64 dimension speaker embedding through a linear projection to form the logits for a softmax speaker classifier , optimizing a corresponding cross-entropy loss. Naturalness and speaker similarity MOS results are shown in T able 7, comparing these jointly trained baselines to results reported in previous sections. W e find that both jointly trained models obtain similar naturalness MOS on Seen speakers, with the variant incorporating a discriminativ e speaker loss performing better on Unseen speakers. In terms of both naturalness and similarity on Unseen speakers, the model which includes the speaker loss has nearly the same performance as the baseline from T able 5, which uses a separately trained speaker encoder that is also optimized to discriminate between speakers. Finally , we note that the proposed model, which uses a speaker encoder trained separately on a corpus of 18K speakers, significantly outperforms all baselines, once again highlighting the ef fecti veness of transfer learning for this task. A ppendix B Speaker v ariation The tone and style of LibriSpeech utterances v aries significantly between utterances ev en from the same speaker . In some examples, the speaker ev en tries to mimic a voice in a dif ferent gender . As a result, comparing the speaker similarity between different utterances from a same speaker (i.e. self-similarity) can sometimes be relatively lo w , and varies significantly speaker by speaker . Because of the noise le v el in LibriSpeech recordings, some speakers have significantly lo wer naturalness scores. This again varies significantly speak er by speak er . This can be seen in T able 8. In contrast, VCTK is more consistent in terms of both naturalness and self-similarity . T able 4 shows the v ariance in naturalness MOS across different speakers on synthesized audio. It compares the MOS of dif ferent speakers for both ground truth and synthesized on VCTK, re vealing that the performance of our proposed model on VCTK is also very speaker dependant. For e xample, speaker “p240” obtained a MOS of 4.48, which is very close to the MOS of the ground truth (4.57), but speak er “p260” is a full 0.5 points behind its ground truth. 12 T able 8: Ground truth MOS ev aluations breakdown on unseen speakers. Similarity ev aluations compare two utterances by the same speaker . (a) VCTK Speaker Gender Naturalness Similarity p230 F 4.22 4.65 p240 F 4.57 4.67 p250 F 4.31 4.72 p260 M 4.56 4.31 p270 M 4.29 4.77 p280 F 4.41 4.71 p300 F 4.60 4.87 p310 F 4.56 4.52 p330 F 4.34 4.77 p340 F 4.44 4.71 p360 M 4.36 4.63 (b) LibriSpeech Speaker Gender Naturalness Similarity 1320 M 4.64 4.43 2300 M 4.67 4.22 3570 F 4.31 4.38 3575 F 4.59 4.36 4970 F 3.77 4.16 4992 F 4.40 3.81 6829 F 4.24 4.39 7021 M 4.71 4.55 7729 M 4.55 4.48 8230 M 4.65 4.70 p230 p240 p250 p260 p270 p280 p300 p310 p330 p340 p360 4 4 . 2 4 . 4 4 . 6 4 . 22 4 . 57 4 . 31 4 . 56 4 . 29 4 . 41 4 . 6 4 . 57 4 . 34 4 . 44 4 . 36 4 . 21 4 . 48 4 . 09 4 . 04 4 . 15 4 . 35 4 . 28 4 . 13 4 . 09 4 . 23 4 . 13 Speaker ID Naturalness MOS Ground truth Proposed model Figure 4: Per-speak er naturalness MOS of ground truth and synthesized speech on unseen VCTK speakers. A ppendix C Impact of r eference speech duration T able 9: Impact of duration of reference speech utterance. Ev aluated on VCTK. 1 sec 2 sec 3 sec 5 sec 10 sec Naturalness (MOS) 4 . 28 ± 0 . 05 4 . 26 ± 0 . 05 4 . 18 ± 0 . 06 4 . 20 ± 0 . 06 4 . 16 ± 0 . 06 Similarity (MOS) 2 . 85 ± 0 . 07 3 . 17 ± 0 . 07 3 . 31 ± 0 . 07 3 . 28 ± 0 . 07 3 . 18 ± 0 . 07 SV -EER 17.28% 11.30% 10.80% 10.46% 11.50% The proposed model depends on a reference speech signal fed into the speaker encoder . As sho wn in T able 9, increasing the length of the reference speech significantly improv ed the similarity , because we can compute more precise speaker embedding with it. Quality saturates at about 5 seconds on VCTK. Shorter reference utterances gi ve slightly better naturalness, because the y better match the durations of reference utterances used to train the synthesizer, whose median duration is 1.8 seconds. The proposed model achiev es close to the best performance using only 2 seconds of reference audio. The performance saturation using only 5 seconds of speech highlights a limitation of the proposed model, which is constrained by the small capacity of the speaker embedding. Similar scaling was found in [ 2 ], where adapting a speaker embedding alone was shown to be effecti ve giv en limited adaptation data, ho we ver fine tuning the full model was required to improve performance if more data was a v ailable. This pattern w as also confirmed in more recent work [5]. 13 A ppendix D Evaluation speak er sets T able 10: Speaker sets used for e v aluation. (a) VCTK Seen Speaker p231 p241 p251 p261 p271 p281 p301 p311 p341 p351 p361 Gender F M M F M M F M F F F Unseen Speaker p230 p240 p250 p260 p270 p280 p300 p310 p330 p340 p360 Gender F F F M M F F F F F M (b) LibriSpeech Seen Speaker 446 1246 2136 4813 4830 6836 7517 7800 8238 8123 Gender M F M M M M F F F F Unseen Speaker 1320 2300 3570 3575 4970 4992 6829 7021 7729 8230 Gender M M F F F F F M M M A ppendix E Fictitious speakers 0.0 0.5 1.0 1.5 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 0 10 20 30 40 50 60 70 80 Mel channel t e i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 Time (sec) 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a p p l e "this is a big red apple" 6 3 0 3 6 0.0 0.5 1.0 1.5 Time (sec) 0 10 20 30 40 50 60 70 80 Mel channel t h i s i s a b i g r e d a a p p l e "this is a big red apple" 6 3 0 3 6 Figure 5: Example synthesis of a sentence conditioned on sev eral random speaker embeddings sampled from the unit hypersphere. All samples contain consistent phonetic content, b ut there is clear variation in fundamental frequenc y and speaking rate. Audio files corresponding to these utter- ances are included in the demo page ( https://google.github.io/tacotron/publications/ speaker_adaptation ). 14 A ppendix F Speaker similarity MOS e valuation interface Figure 6: Interface of MOS e valuation for speaker similarity . 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment