스피커 인식 위한 결합 은닉 요인 신경망
본 논문은 화자와 세션 변동성을 모델링하기 위해 결합 은닉 변수(tied hidden factors)를 도입한 자동인코더 기반 신경망을 제안한다. 두 단계 역전파를 통해 네트워크 가중치와 은닉 요인을 동시에 학습하고, 마지막 선형 회귀 레이어를 확률 모델로 활용해 직접적인 likelihood를 산출한다. 학습된 모델은 MAP 적응을 통해 화자별 UBM을 만들고, 두 모델의 likelihood 비율로 최종 스코어를 얻는다. RSR2015 데이터베…
저자: Antonio Miguel, Jorge Llombart, Alfonso Ortega
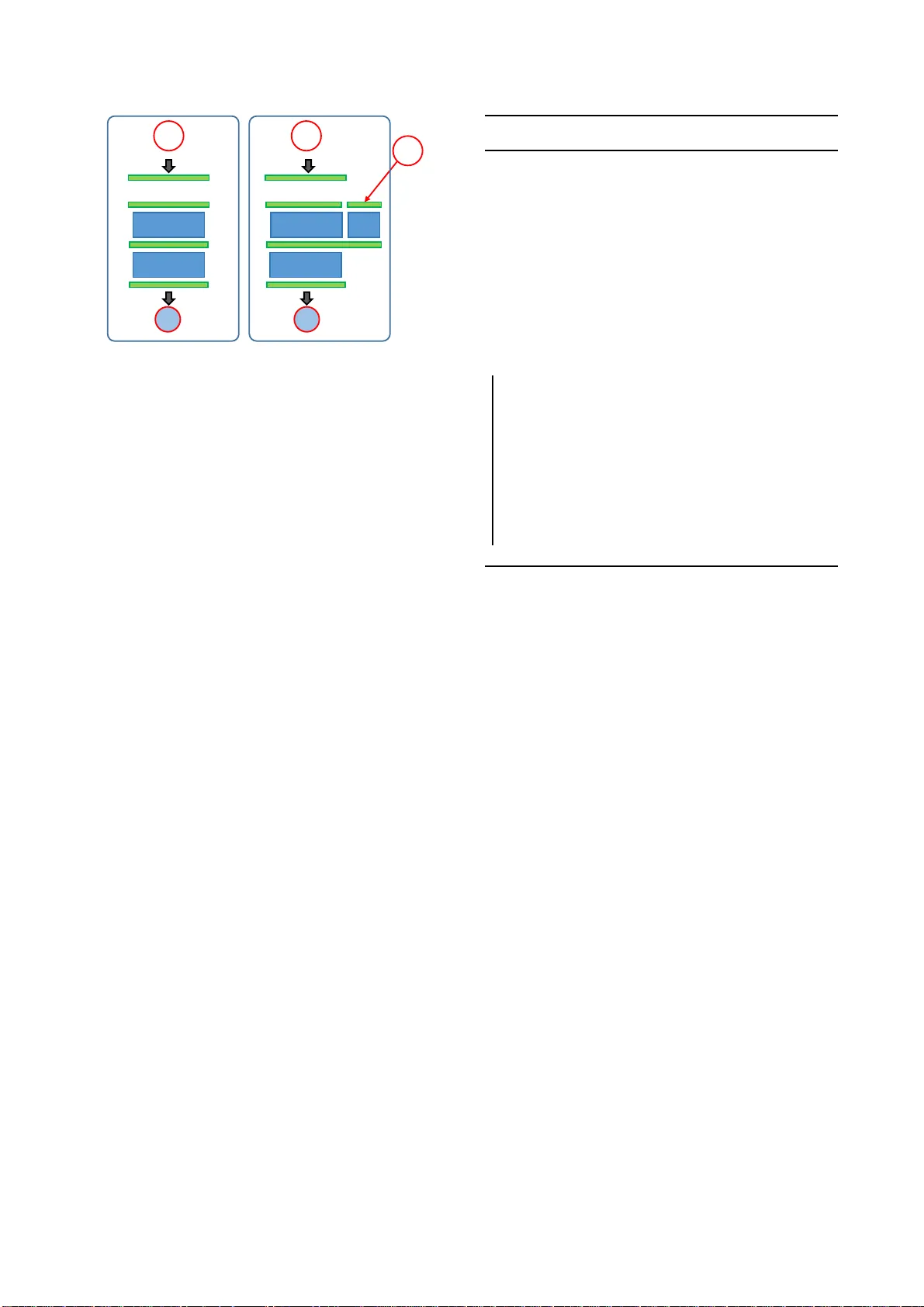
본 논문은 화자와 세션 변동성을 동시에 모델링할 수 있는 새로운 신경망 구조인 Tied Factor Deep Neural Network(TF‑DNN)를 제안한다. 기존의 Joint Factor Analysis(JFA)와 i‑vector 모델은 GMM이나 HMM을 기반으로 은닉 변수를 추정했지만, TF‑DNN은 자동인코더(autoencoder) 기반의 딥 뉴럴 네트워크에 결합 은닉 요인(tied hidden factors)을 직접 삽입한다.
먼저, 입력 특성 X={xₜ}ₜ₌₁ᵀ를 프레임 레벨에서 처리하고, 각 프레임은 세 개의 잠재 변수로 표현된다. (1) 프레임 자체를 설명하는 bottleneck 레이어 z⁽⁰⁾ₜ, (2) 세션을 설명하는 z⁽¹⁾_f, (3) 화자를 설명하는 z⁽²⁾_s이다. 세션·화자 변수는 동일 세션·화자에 속하는 모든 프레임에 대해 동일하게 공유(tied)되며, 이는 GMM‑UBM에서의 전역 변수와 유사한 역할을 한다.
네트워크 구조는 일반적인 다층 퍼셉트론과 동일하지만, TF‑2 레이어에서는 각 레이어의 선형 변환에 V⁽¹⁾·z⁽¹⁾와 V⁽²⁾·z⁽²⁾를 추가한다. 즉, xₜ,ℓ = σ(W_ℓ xₜ,ℓ₋₁ + b_ℓ + V⁽¹⁾_ℓ z⁽¹⁾_f + V⁽²⁾_ℓ z⁽²⁾_s) 형태가 된다. 여기서 σ는 비선형 활성화 함수이다.
학습은 두 단계 역전파 알고리즘으로 진행된다. 1단계에서는 현재의 은닉 요인 값을 고정하고, 미니배치 기반으로 Θ(네트워크 가중치와 편향)와 로딩 매트릭스 V를 경사 하강법으로 업데이트한다. 2단계에서는 전체 데이터셋을 사용해 각 세션·화자에 대한 그래디언트를 집계하고, 이를 통해 z⁽¹⁾와 z⁽²⁾를 업데이트한다. 은닉 요인의 그래디언트는 해당 세션·화자에 속하는 모든 프레임에 대해 합산되므로, 파라미터와 은닉 요인이 교대로 최적화되는 좌표 하강법과 유사한 수렴 특성을 가진다.
출력 레이어는 선형 회귀 확률 모델로 설계된다. 마지막 레이어의 가중치 W_L을 회귀 계수 B라고 두고, 출력 xₜ,L을 평균으로 하는 다변량 정규분포 N(Byₜ, β⁻¹I)를 가정한다. 이 구조는 B에 대해 ML, MAP, 완전 베이지안 추정이 직접 적용될 수 있게 만든다. 특히, MAP 추정 시 사전 평균을 UBM에서 얻은 B_ubm으로 설정하고, 사전 정밀도 λ₀를 이용해 B의 사후 평균을 계산한다.
시스템 구축 절차는 다음과 같다. (1) UBM 학습: 전체 훈련 데이터를 사용해 TF‑DNN을 학습하고, 마지막 레이어의 충분통계 S_yy와 S_yx를 저장한다. (2) 화자 등록: 적은 수의 등록 샘플에 대해 두 가지 적응 방식을 적용한다. 첫 번째는 은닉 요인(z⁽²⁾_s)만 업데이트하는 것이고, 두 번째는 MAP 방식으로 B를 재추정하는 것이다. 여기서는 두 번째 방식을 채택해, UBM 사전과 등록 데이터를 가중 평균(α)으로 결합한 B_spk를 얻는다. (3) 시험 평가: 테스트 샘플에 대해 UBM와 화자 적응 모델 각각의 likelihood를 계산하고, 그 비율 Λ = p(X|B_spk)/p(X|B_ubm)으로 최종 스코어를 산출한다.
실험은 RSR2015 데이터베이스의 문구‑종속 스피커 검증 시나리오에서 수행되었다. 제안된 TF‑2‑DNN은 기존 GMM‑UBM, i‑vector 및 LSTM 기반 시스템에 비해 EER이 현저히 낮았다. 또한, dropout을 결합한 베이지안 정규화가 과적합을 억제하고 모델의 불확실성을 정량화하는 데 기여함을 확인하였다.
결론적으로, 이 논문은 딥러닝 모델에 전통적인 통계적 은닉 요인을 결합함으로써, 엔드‑투‑엔드 화자 인증 시스템에서 높은 정확도와 적은 파라미터 요구량을 동시에 달성할 수 있음을 입증한다. 향후 연구에서는 다중 은닉 요인(예: 환경·채널 변수) 확장과 대규모 데이터셋에 대한 스케일링, 그리고 실시간 응용을 위한 경량화 방안을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기