Tied Hidden Factors in Neural Networks for End-to-End Speaker Recognition
In this paper we propose a method to model speaker and session variability and able to generate likelihood ratios using neural networks in an end-to-end phrase dependent speaker verification system. As in Joint Factor Analysis, the model uses tied hi…
Authors: Antonio Miguel, Jorge Llombart, Alfonso Ortega
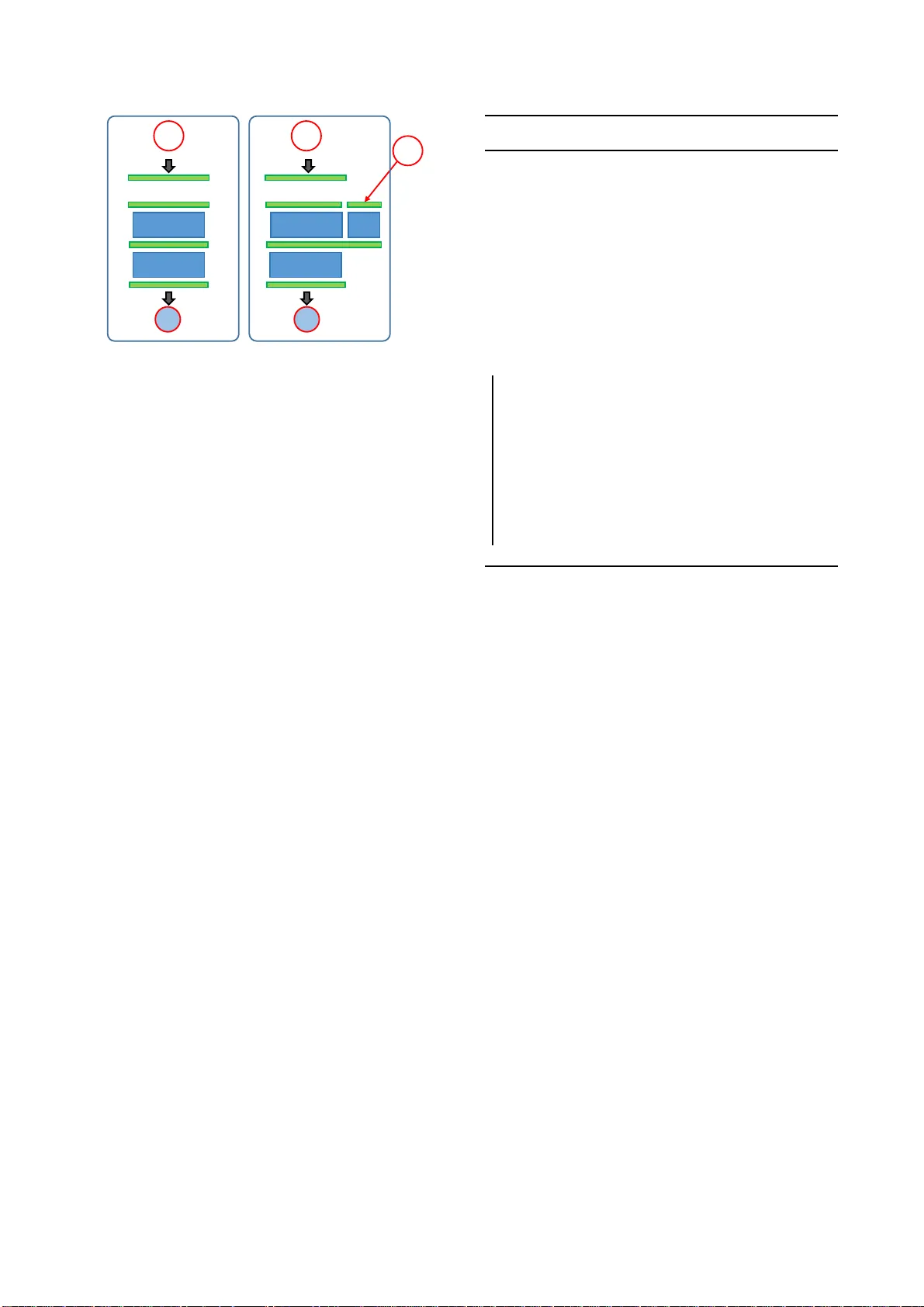
Tied Hidden F actors in Neural Networks f or End-to-End Speaker Recognition Antonio Miguel, J or ge Llombart, Alfonso Orte ga, Eduar do Lleida V iV oLAB, Aragon Inst i tute for Eng ineering Research (I3A), University of Zaragoza, Spain { amiguel,jllombg ,ortega,lleida } @unizar.es Abstract In this paper we propose a method to model speaker and ses- sion v ariability and able to generate likeliho od ratios using neu- ral network s in an end-to-end phrase dependent speaker veri- fication system. As in Joint Factor Analysis, the model uses tied hidden variables t o model speaker and session variability and a MAP adaptation of some of the parameters of the model. In the trai ning procedure our method jointly estimates t he net- work parameters and the values of the speaker and channel hid- den v ariables. This is done in a two-step backpropagation al- gorithm, fi rst the network weights and factor loading matrices are updated and t hen the hidden variables, whose gradients are calculated by aggregating the corresponding speaker or session frames, since these hidden v ariables are tied. The last layer of the netwo rk is defined as a linear re gression probabilistic model whose inpu ts are the pre vious layer ou tputs. This choice has the adv antage that it produces likelihoods an d additionally it can be adapted during the enrolment using MAP wi thout the need of a gradient optimization. The decisions are made based on the ratio of the output likelihoods of two neural network models, speak er adapted and univ ersal background model. The method was ev aluated on the RSR 2015 database. 1 Index T erms : Neural Networks, Joint Factor Analysis, T ied Factor Analysis, Speaker variability , S ession variability , Linear Regression Models. 1. Intr oduction Deep neural networks (DNNs) have been successfully applied in many speech and speak er recognition tasks in r ecent years, provid ing ou tstanding performanc es. In spee ch t echnologies most of the DNN solutions hav e used them as classifiers or fea- ture extractors, but in this work we propose to apply them in an end-to-end detection task, where the output of the system is a likelihood score ratio, which after applying a threshold provides good performance without the need of further calibration. Un- fortunately , the high number of parameters of DNNs and their tendenc y to ov erfit data make that type of detection t ask difficult to approach. In this work we try to take advantag e of the high flexibility of these models and their capacity to learn nonlinear patterns from the input signals. This has required to provide solutions to decrease t he overfitting problems and their l ack of a measure of uncertainty by adding external control variables to model session and speaker variability , and also proposing Bayesian adaptation and ev aluation mechanisms. Recent approache s to speaker recognition use Joint Factor Analysis (JF A) [1, 2, 3, 4, 5] with GMMs or HMMs as base distributions, i-vector systems [6, 7, 8 ], neural networks as bot- tleneck feature extractors for JF A or i-vector systems [9, 10], or neural networks as classifiers to produce posterior probabili- ties for JF A or i-vector extractors [11, 10, 12]. There have been other approaches to create speaker verification using neural net- works by means of LSTM networks [13 ] to provid e sequence 1 Cite a s: A. Migue l, J. Llombart, A. Ort ega, E. Lleida, “T ied Hidden Fact ors in N eural Networks for E nd-to-End Speake r Recognition. ” In Proc. Interspeec h, pp 2819–2823, Stockholm, Sweden, 2017. to vector compression or to extract total variability latent fac- tors (similar to i-vector) directly from a neural network in [14], in that case a PLDA backend was used in a text independe nt speak er recognition task. The proposed method has several par- allelisms to JF A models since we also encode speake r and ses- sion information using latent v ariables, and the model proba- bility distribution can also be adapted to the speaker data using MAP or Bayesian techniques, but in this paper the model is built on top of an autoencoder neural network as an alternative to other models like GMMs or HMMs. The proposed method is an end-to-end solution since the neural network performs all the processing steps and it prov ides the likelihood ratio. The autoencod er [15] is a generati ve model that is trained to pre- dict its input with the restriction that the network has a bottle- neck l ayer of smaller dimension. Its training is unsupervised in terms of frame lev el phoneme labels, what makes it a candi- date to substitute GMMs as the underlying model of the system. In addition, it can be robustly trained using Bayesian methods and its output layer can be probabilistic, as it has been shown in recent works [15, 16, 17 ] . As we show later in the paper , we can build a system using these probabilistic autoencoders, but performance can be improv ed by using tied hidden variables to model speaker and session variability . Speaker factors hav e been used as a source of additional in- formation for neural networks in speech recognition to improve the performance of speaker independent recognizers [18, 19]. In many cases the latent variables were obtained by using an exter- nal system like a GMM based JF A or i-vector extractor , and the network is then retrained to capture this extra information [20]. There hav e been works were speaker factors or speak er codes are used to enhance speech recognition systems and t hey were optimized by gradient optimization [20, 21] or initialized using Singular V alue Decomposition [22]. W e propose a j oint factor approach for neural networks to model speaker and session va ri- ability , sho wing that effecti ve improvements can be obtained by using the latent factors with respect to a reference network . A modified two-step backpropagation algorithm is proposed t o train the model parameters and the latent factors, first the net- work weights and factor loading matrices are updated give n the current value of t he latent variables and then the latent variables are updated. T o calculate the gradients of the cost f unction with respect to the network weights the minibatch samples can be randomly permuted to facilitate con ve rgence, but the gradients with respect to the hidden factors are calculated by aggregat- ing all t he corresponding speaker or session frames, since these hidden variables are tied. This paper is organized as follows. In Section 2 t he tied factor analysis model for neural network s is presented. S ecti on 3 discusses the use of autoencod er neural networks for speake r verification. Section 4 presents an experimen tal study to show the accuracy of the models in phrase dependent speaker recog- nition. Conclusions are presented in Section 5. W ž ç Y 6 : 5 á 6 ; W W ž ç Y 6 ç : 4 ; W V ç : 4 ; Figure 1: Decoder in an autoencoder for DNNs and TF-DNN 2. T ied Hidden Factors in Neural Networks The concept of tied hidden factors to model contextual or se- quence information has appeared in man y dif ferent conte xts like face recognition [23], speech recognition [ 24, 25 ] , language recognition [26, 27], speaker diarization [28] or audio segmen - tation [29], but their most prominent field has been speaker recognition with JF A or i-vector approaches [30 , 2, 3, 4, 5, 6] The use of these type of global variables has been defined in more general approaches as hierarchical models [31] and more recently in the contex t of DNNs in [32]. W e propose to use t wo types of tied hidden factors in neural networks to extend pre vi- ous works with a general algorithm to estimate them. W e refer to this model in general as Tied Factor Deep Neural Network (TF-DNN), and for the special case of two factors speaker and session, TF 2-DNN. In Figure 1 it is depicted the conceptual dif- ference of the decoder part of a standard DNN autoencoder and a TF-DNN, where z (0) t is the bottleneck layer which changes for ev ery frame t , but there are tied variab les that affect the out- put of many samples x t of the same session (or fi le in databases like R S R2015) z (1) f and same speaker z (2) s , displaying a similar the idea to [3, 4] for GMMs. T o define the model, first we need to describe the observed data, X = { x t } T t =1 as a sequence of feature vectors x t ∈ R D with D the feature dimension. In t he proposed TF2-DNN ap- proach we assume that a set of hidden variab les encode speak er and session information. The session and speak er latent factors are denoted as Z (1) = { z (1) f } F f =1 and Z (2) = { z (2) s } S s =1 with z (1) f ∈ R R (1) and z (2) s ∈ R R (2) , where F and S are the number of sessions and speake rs and R (1) and R (2) are the dimension of their respectiv e subspaces. The complete set of hidden v ari- ables i s denoted as Z = ( Z (1) , Z (2) ) , they encode speaker and session information, and since t hey are unkno wn we need to es- timate them using a labeled dataset. T he training data are typi- cally organized by sessions. If sessions are labeled by speaker , then it is straightforward to obtain frame le vel session labels φ (1) t ∈ { 1 , . . . , F } , and speake r labels as φ (2) t ∈ { 1 , . . . , S } , so that the training dataset is defined as D = { x t , φ (1) t , φ (2) t } T t =1 , for each data sample we need it s speaker and session label. The TF2-DNN is built on top of a regular neural net- work whose parameters are the weights W l and biases b l of all the layers l = 1 , . . . , L . W e denote them by ¯ W = { W 1 , b 1 , . . . , W L , b L } for a NN with L layers. The layers of the network which are connected to t he latent variab les are Algorithm 1 T raining algorithm for two tied hidden factor neu- ral network (TF 2-DNN) Input: D : Acoustic features X , frame level session labels and frame level speaker labels φ (1) , φ (2) , and prior values for the initialization λ , learning r ate values for the un- kno wn parameters α , and number of epochs N Output: Estimations for hidden factors Z = ( Z (1) , Z (2) ) and the network parameters Θ = ( ¯ W , ¯ V ) : the neural net- work weighs and factor loading matrices 1. Initialization Initialize all the unkno wn weights and latent factors randomly follo wing their prior distribution: Θ ∼ N ( 0 , λ 1 I ) , z (1) ∼ N ( 0 , λ 2 I ) , z (2) ∼ N ( 0 , λ 3 I ) 2. T wo step backpropagation fo r n ← 1 to N do 2.1 Step 1, backp ropaga tion p arameters: Θ : Minibatch b updates: frames t b are selected randomly: D b ← { x t , φ (1) t , φ (2) t | t ∈ t b } , Z b ← { z (1) f , z (2) s | t ∈ t b , f = φ (1) t , s = φ (2) t } Θ ← Θ − α 1 ∇ Θ J ( D b , Z b , Θ ) 2.2 Step 2, backpropagation hidden variables z (1) , z (2) Using expressions ( 2), (3) for all speaker s and sessions f z (1) f ← z (1) f − α 2 ∇ z (1) f J ( D , Z , Θ ) z (2) s ← z (2) s − α 3 ∇ z (2) s J ( D , Z , Θ ) end called TF2 layers and have additional parameters and a different output than a standard network. In Figure 1, we sho w a simpli- fied model of a DNN wit h standard layers and T F-DNN w i th a TF2 layer . In the case of linear embedding, a factor loading matrix V l is required for each factor and the layer l output is defined as x t,l = σ ( W l x t,l − 1 + b l + V (1) l z (1) f + V (2) l z (2) s ) , (1) where x t,l − 1 and x t,l are the prev ious layer output and the cur- rent layer output, the function σ () is t he layer nonlinearity , z (1) f is the session factor corresponding to the frame x t , and f is the correspondin g file label f = φ (1) t , and z (2) s is the corresponding speak er factor and s is the speaker label s = φ (2) t . The set of all the network parameters is denoted as Θ = ( ¯ W , ¯ V ) . Giv en a cost f unction J ( D , Z , Θ ) that can be ev aluated for some training data, D , and an instance of the unknown param- eters Z and Θ , we can define an optimization method to min- imize the cost. In this work we hav e used gradient based op- timization since it can be scaled to larger datasets and still be tractable. T o estimate both the network weights and the ti ed la- tent factors A l gorithm 1 is proposed. This algorithm optimizes both sets of variab les in an alternate way like in coordinate de- scent type algorithms. In [4] the alternate E and M steps had the same moti vation, since the E step considered t he likelihood as the objective and the latent variables were optimized in a search process given the other parameters fixed. The gradients with respect to the network parameters Θ in the step 2 . 1 are com- puted as usual gradients since the hidden v ariables are giv en as argume nt with their current va lue and they can be interpreted as external information to t he network . The gradients with re- spect to the tied hidden variables have to be considered more carefully , since they have to be calculated by aggregating all the corresponding speaker or session frames since they are tied. Then the gradients for session f and speaker s factors are ∇ z (1) f J ( D , Z , Θ ) = X t | φ (1) t = f ∇ z (1) J ( x t , z (1) φ (1) t , z (2) φ (2) t , Θ ) (2) ∇ z (2) s J ( D , Z , Θ ) = X t | φ (2) t = s ∇ z (2) J ( x t , z (1) φ (1) t , z (2) φ (2) t , Θ ) . (3) 3. Neural network end-to-end speaker verification sy stem The autoencod er [15, 16] i s a generativ e model that is trained to predict its input with the restriction that the network has a bottleneck layer of smaller dimension. Then, the system has two parts: the first part, encoder , l earns how to compress the information and the second part, decoder , learns how to recon- struct the signal. T o adapt this type of network to the task of speak er recognition we need to compute likelihoods of the ob- served data x t . In [15] the bottleneck layer of the autoencoder was considered analogous to the hidden v ariable z t in a factor analysis model [33] . Then, the encoder part was associated to a v ariational approximation to the posterior distribution q ( z t | x t ) , and the decoder part could be associated to the l ikelihood of the observed data giv en the hidden v ariable by parametrizing a probabilistic model using the network outputs p ( x t | z t ) . T o fol- lo w with the prev ious section notation for the latent factors, [4], the bottleneck layer of the autoencoder is denoted as z (0) t , since it encodes intra-frame information [34, 33] and it is t he lowest lev el in the hierarchy: frame (0), session (1), speaker (2). W e can see t hat other le vels could be added easily . 3.1. Linear Regression p robability model In this paper we use the same parametrization mechanism as in [15, 17] to define that the last layer provid es the mean vector of a Gaussian distribution, which we combine with the following idea: if the last layer is a linear function, x t,L = W L x t,L − 1 + b L , t he likelihood can also be interpreted as a l i near regression probability model whose r egression coefficient matrix B is the last layer weight matrix W L as p ( x t | z (0) t ) = N ( x t,L , Ψ ) = N ( W L x t,L − 1 + b L , Ψ ) , (4) where the output x t,L acts as mean and we can define an arbi- trary cov ariance matrix Ψ . The following steps could be carried out for the bias param- eter b L and the cov ariance matrix Ψ as wel l , but t o keep the notation simpler [35], and focus on the most important param- eters, the weigths B = W L , we deri ve the network adaptation mechanism for this simpler distr i bution p ( x t | y t ) = N ( By t , β − 1 I ) , (5) where β − 1 I is the cov ariance matrix, no w controlled by a single parameter and we denote the outputs of the previou s layer as y t for simplicity , with y t = x t,L − 1 = f ( z (0) t ) using t he decoder part of the network except the last l ayer . The analogy in expressions (4) and ( 5 ) allows to estimate the value of W L using a probabilistic approach if we let the rest of the network parameters and hidden variab les unchanged , what makes easy to apply ML, MAP or Bayesian estimation techniques. Gi ven some training data X organ ized by ro ws, and the output previou s to t he l ast layer Y , the ML estimator is equi va lent to minimize square error , MSE, and is obtained as B M L = ( Y ⊺ Y ) − 1 Y ⊺ X . (6) The ML estimator can have problems when inv erting the matrix i f it is il l-conditioned. T o solve that we can impose a penalty to the weights B by assuming a Gaussian prior for t hem B ∼ N ( B 0 , λ − 1 0 I ) , which makes the optimization of the pos- terior distribution p ( B | X ) equiv alent to an L 2 regularization [17], this i s the MAP estimator B M AP = ( β Y ⊺ Y + λ 0 I ) − 1 ( β Y ⊺ X + λ 0 B 0 ) , (7) which in t he case the prior mean is zero it is usually expresse d as B M AP = ( Y ⊺ Y + λ 0 β I ) − 1 Y ⊺ X . (8) The fully Bayesian approach [35] provides a posterior dis- tribution for the weights given the priors and the observed data that follows a normal distribution, whose mean has the same v alue as the MAP estimation i n (7) p ( B | Y ) = N ( B N , Σ N ) (9) B N = Σ N ( β Y ⊺ X + λ 0 B 0 ) (10) Σ − 1 N = ( β Y ⊺ Y + λ 0 I ) . (11) 3.2. UBM training, speaker enrolment and trial evaluation Once the building blocks of the model hav e been established, we describe all the basic steps in volv ed in a speaker r ecognition system: UBM training, speake r enrolment, and trial ev aluation. The uni versal background model (UBM) is trained using Algorithm 1 after a random initialization of all the unknown pa- rameters and latent factors. The labels to assign training frames to the speak er and latent factors must be supplied to the algo- rithm. When t he UBM is trained we extract the sums S y y = Y ⊺ Y = X t y t y ⊺ t , S y x = Y ⊺ X = X t y t x ⊺ t , (12) which are the sufficient statistics needed to make adaptations at enrolment time without the need of processing the whole database each ti me. y t and x t are column vectors correspond- ing to frame t . Then, B ubm can be obtained from the stats. T o enrol a speaker in the system in the contex t of the pro- posed method requires t o create an adapted network to the sam- ples used for enrolment, which are a small number compared to the UBM. T wo mechanism are av ailable in this model for this. The first one is t o adapt the speaker latent factor by us- ing step 2 . 2 of the algorithm for a number of iterations using the enrolment data and using as initial values the UBM param- eters. In this case step 2 . 1 would not be applied since the net- work weights hav e to remain fixed. T he second mechanism is more si milar to MAP in JF A systems, two possible adaptations are proposed giv en the previo us linear regression expression s. One option is to consider t he prior mean as the UBM value B 0 = B ubm , then using expression (10 ) the maximum of the posterior distribution p ( B spk | Y spk , B 0 = B ubm ) B spk = ( β S spk y y + λ 0 I ) − 1 ( β S spk y x + λ 0 B ubm ) . (13) Other option is t o consider the posterior distribution giv en both the enrolment and the UBM data p ( B spk | Y ubm , Y spk ) , with the prior mean equal to zero. T o control the w ei ght of the UBM samples wi t h respect to the enrolment we introduce an interpo- lation factor α B spk = (14) ( αS ubm y y + (1 − α ) S spk y y + λ 0 β I ) − 1 ( αS ubm y x + (1 − α ) S spk y x ) . Finally for trial ev aluation we e valua te the likelihoo d ratio Λ = p ( X | Y ubm , Y spk ) p ( X | Y ubm ) , (15) where l ikelihood s are calculated using expre ssion (4), B ubm in the denominator is estimated using (10) and the sufficient stats, (12), for all the UBM data Y ubm . B spk in the numerator is esti - mated using (14) and the speaker and UBM data, Y spk , Y ubm , (since it performed better than (13) in preliminary experiments). 3.3. Bayesian inf erence Recent advan ces on applying Bayesian estimation techniques to DNNs hav e been shown to be ef fectiv e against overfitting and to deal with uncertainty [36, 15, 17]. T o avoid ov erfitting when data size is small, we propose t o use dropout layers, [37], interleav ed with the TF A2 layers, as an alternativ e t o the varia- tional approach [16]. W e train the network using the proposed algorithm with the dropout Bernoulli distribution, ξ ∼ B e ( p ) , which switches off some of the layer outputs wit h probability p . Then we perform the t r ial ev aluation by sampling p ( x t | z (0) t ) = Z p ( x t | z (0) t , ξ ) p ( ξ ) dξ ≃ 1 L X ξ l ∼ Be ( p ) p ( x t | z (0) t , ξ l ) . (16) 4. Experiments The exp eriments have been conducted on t he RSR 2015 part I text dependent speaker recognition database [38]. The speak- ers are distributed in three subsets: bkg, dev and ev al. W e have only used background data (bkg) to train the UBMs, which can be phrase i ndependent or phrase dependen t, as i n [8, 3, 4]. T he e valuation part is used for enrolment and trial ev aluation. The de v part was not used in these exp eriments and files were not rejected because of l o w quality . Speaker models are build using 3 utterances for each combination of speak er and phrase (1708 for males and 1470 for females). For testing we hav e selected the tri als using the same phrase as the model, called impostor- correct in [38]: 10244(tgt) + 573664(n on) = 583908 male trials; 8810(tgt) + 422880(n on) = 431690 f emale trials. W e use the database 16kHz signals to extract 20 MFCCs and their first and second deriv ativ es. Then, an energy based voice activity detec- tor is used and data are normalized using short term Gaussian- ization. In the experiments in this work the speak er factor is a speak er-phrase combination as in [3]. T o train the autoencoders in this work we used the same DNN architecture in all of the ex- periments of 4 hidden layers of 500 units, softplus nonlinearities [17] and a bottleneck layer of 15 units, which makes the dimen- sion R (0) four times smaller than t he feature dimension of 60, and finally the linear regression layer . The weight and factor loading matrices were updated using Adam [39] and the cost function was the MSE. The likelihood (4) in the experiments was calculated using bias and diagonal cov ariance matrix. A set of experiments was performed using Theano [40] to e valuate the model using gender dependent and phrase inde- pendent UB Ms. W e compared the DNN which updates the last layer using (14) to the TF 2-DNN which also updates the l ast layer and in addition includes speaker and session factors. The results i n T able 1 sho w both DNN systems performing under 1% EER for the male and female tasks, but the performance is greater in the case of models using tied factors in the model. In the paper we expo sed some parallelism between the DNN and a GMM both adapted with MAP . W e can see in the experimen ts T able 1: Expe rimental r esults on R SR2015 part I [38] impostor- corr ect, showing EER % and NIST 2008 and 2010 min costs. Male System R (1) R (2) EER % det08 det10 DNN - - 0.65 0.037 0.155 TF2-DNN 15 50 0.25 0.016 0.086 75 0.31 0.017 0.080 100 0.30 0.017 0.085 25 50 0.29 0.016 0.075 75 0.25 0.015 0.075 100 0.31 0.017 0.069 Female R (1) R (2) EER % det08 det10 DNN - - 0.50 0.021 0.084 TF2-DNN 15 50 0.17 0.006 0.019 75 0.16 0.006 0.026 100 0.17 0.006 0.030 25 50 0.15 0.007 0.028 75 0.13 0.006 0.028 100 0.19 0.007 0.021 that the range of E ER achiev ed is also comparable to GMMs in other works [10]. And the relative i mprov ement provided by the T F 2-DNN with respect to the DNN system is also similar to [4], although in that case the fil es were processed at 8kHz. In RSR2015, phrase dependent UBMs can be more specific, but there are less data ava ilable for the UBM, which makes dif- ficult to train a DNN with many layers. For that scenario we propose the use of dropout [37] and to approximate t he likeli- hoods using (16). W e performed some experiments using the female subset and phrase dependent UBMs. A dropout layer was interleaved in the encoder and the decoder , with p = 0 . 05 . The TF2-DNN had as dimensions R (1) = 5 and R (2) = 20) and the system provided a 0 . 11% of EER. This preliminary ex- periment showed us that dropout and other Bayesian techniques can mitigate part of the effect of ove rfitti ng of l arge DNNs when learning small datasets, and t he system st i ll can provide well calibrated scores in the context of these models. 5. Conclusions In t his paper we present an end-to-end method for speaker recognition based on neural networks, using tied hidden vari- ables to model speak er and session variability and a MAP and Bayesian techniques to enrol and e valua te trials. T he last layer of the network is defined as a linear regressio n prob abilistic model t hat can be adapted during the enro lment so that the model can calculate likelihood ratios to decide the trial ev al- uations. T o estimate the model parameters and the hidden vari- ables a two-step backpropagation algorithm is used. W e have tested the models in the t ext dependent speaker recognition database RSR2015 part I provid ing competitiv e r esults with re- spect to pre vious approaches. 6. Ackno wledgements This work i s supported by the Spanish Gov ernment and Eu- ropean Union (project TIN2014–542 88–C4–2–R), and by the European Commission FP7 IAPP Marie Curie Action GA– 610986 . W e gratefully ackno wledge the support of NVIDIA Corporation with the donation of a Titan X GPU used for this research. 7. Refer ences [1] S. -C. Y in, R. Rose, and P . K enn y , “A Joint Fac tor Analysis Approach to Progressi ve Model Adaptation in T ext-In dependent Speak er V erification, ” IEEE T ransactions on Audio, Speech and Languag e P r ocessing , vol. 15, no. 7, pp. 1999–2010, Sep. 2007. [2] P . Kenn y , P . Ouellet , N. Dehak, V . Gupta, and P . Dumouchel, “A Study of Inter speaker V ariabil ity in Speake r V erification, ” IEEE T ransactio ns on Audio, Speec h, and Languag e Proc essing , vol. 16, no. 5, pp. 980–988, Jul. 2008. [3] P . Ken ny , T . Stafylaki s, J. Alam, P . Ouellet, and M. Kockman n, “Joint fact or analysis for text-de pendent speaker veri fication, ” in Pr oc. Odysse y W orkshop , 2014, pp. 1–8. [4] A. Miguel , A. Ortega, E. Lleida, and C. V aquero, “Fact or analysis with sampling methods for text dependent speaker recogniti on. ” Singapore : Proc. Interspe ech, 2014, pp. 1342–1346. [5] T . Stafylakis, P . Kenn y , M. J. Alam, and M. Kockmann, “Speaker and Channel Factors in T ext- Dependent Speak er Recognit ion, ” IEEE/ACM T ransactions on Audio, Speec h, and Languag e Pr ocessing , vol. 24, no. 1, pp. 65–78, 1 2016. [6] N. Dehak, P . Kenn y , R. Dehak, P . Dumouch el, and P . Ouel- let, “Front-End Factor Analysis For Speake r V erificatio n, ” Audio, Speec h, and Languag e Pr ocessing , IEEE T ransactions o n , vol. 19, no. 14, pp. 788–798, May 2010. [7] J. V illalba and N. Br ¨ ummer , “T owar ds Fully Bayesian Speaker Recogni tion: Inte gratin g Out the Between -Speake r Cova riance, ” in Interspeec h 2011 , Florence, 2011, pp. 28–31. [8] T . Stafyla kis, P . Kenn y , P . Ouellet, J. Perez, M. Koc kmann, and P . Dumouchel, “T ext-depende nt speak er recogntion using plda with uncerta inty propagation, ” in Proc. Interspeec h , L yon, France , August 2013. [9] Y . Liu, Y . Qian, N. Chen, T . Fu, Y . Zhang, and K. Y u, “Deep feature for text- dependent speaker verific ation, ” Speec h Communicat ion , vol. 73, no. C, pp. 1–13, 10 2015. [10] H. Zeinali, L. Bur get, H. Sameti, O. Glembek, and O. Pl- chot, “Dee p neural netwo rks and hidden m arko v models in i- vec tor-based te xt-depende nt speaker verificat ion, ” in Odysse y-The Speak er and Language Recogni tion W orkshop , 2016. [11] S. Dey , S. Madikeri , M. Ferras, and P . Motlic ek, “Deep neural netw ork based posteriors for text-dep endent speake r verificat ion, ” in 2016 IEEE International Confer ence on Acoustics, Speec h and Signal Proc essing (ICASSP) . IEEE, 3 2016, pp. 5050–5054. [12] H. Zeinali, H. Sameti, L . Burget , J. Cernoc ky , N. Maghsoodi, and P . Matejka , “i-v ector/hmm based te xt-depende nt s peaker ver ifica- tion system for reddots challenge , ” in Proc . Interspeec h . ISCA, 2016. [13] G. Heigold, I. Moreno, S. Bengio, and N. M. Shazeer , “End-to- end te xt-depende nt speaker ver ification, ” in Proc . ICASSP , 2016. [14] S. Garimel la and H. Hermansk y , “F actor a nalysis of auto- associat iv e neural netw orks with applic ation in speaker ver ifica- tion, ” IEEE transaction s on neural networks and learning sys- tems , vol. 24, no. 4, pp. 522–528, 2013. [15] D. P . Kingma and M. W ellin g, “ Auto-encodin g vari ational bayes, ” in Proc. ICLR , no. 2014, 2013. [16] D. P . Kingma, T . Salimans, and M. W elling, “V ariati onal dropout and the local reparamet erizati on trick, ” in Pr oc. NIPS , 2015. [17] C. Blu ndell, J. Cornebise, K. Kavukcuog lu, and D. W ierstr a, “W eight uncertain ty in neural network, ” in Proc . ICML , 2015, pp. 1613–1622. [18] A. Senior and I. Lopez-More no, “Improving dnn speak er indepen - dence with i-vec tor inputs, ” in Proc. ICASSP , 2014. [19] S. Xue, O. Abdel-Hamid, H. Jiang, L. Dai, and Q. Liu, “Fast adap- tatio n of deep neural network based on discrimina nt codes for speech recogniti on, ” IEEE/ACM T ransacti ons on Audio, Speec h and Langua ge Processi ng , vol. 22, no. 12, pp. 1713–1725, 2014. [20] L. Samarakoon and K. C. Sim, “Fa ctorize d hidde n la yer adapta tion for deep neural network based acoustic modeling, ” IEEE/ACM T ransacti ons on Audio, Speech, and Language Pro- cessing , vol. 24, no. 12, pp. 2241–2250, 2016. [21] Z. Huang, J. T ang, S. Xue, and L. Dai, “Speak er adaptation of rnn-blstm for speech recogniti on based on speak er code, ” in Pr oc. ICASSP . IEEE, 2016, pp. 5305–5309. [22] S. Xue, H. Jiang, L. Dai, and Q. L iu, “Unsupervised speaker adap- tatio n of deep neural network based on the combination of speaker codes and singular va lue decomposition for speech recogn ition, ” in Proc. ICASSP . IEEE, 2015, pp. 4555–4559. [23] S. Prince, J. W arrell, J. Elder , and F . Felisberti, “Tie d Factor Analysis for Face Recogni tion across Large Pose Dif ference s, ” IEEE T ransacti ons on P attern Analysi s and Mac hine Intel lige nce , vol. 30, no. 6, pp. 970–984, 6 2008. [24] R. Kuhn, J . -C. Junqua, P . Nguyen, and N. Niedziel ski, “Ra pid speak er adaptati on in eigen voice space, ” IE EE T ransactions on Speec h and Audio Pr ocessing , vol. 8, no. 6, pp. 695–707, 2000. [25] P . Ken ny , G. Boul ianne, and P . Dumouchel, “Eigen voi ce modeling with spar se training data , ” IEEE T ransac tions on Speec h and Audio Proc essing , vol. 13, no. 3, pp. 345–354, May 2005. [26] D. Mart ´ ınez, O. Plchot, L. Burget, G. Ondrej, and P . Matejka, “Language Recogniti on in iV ectors Space, ” in Proc. Interspee ch , Florence , Italy , 2011. [27] D. Mart´ ı nez, E. Lleida, A. Orte ga, and A. Miguel , “Prosodi c Feature s and Formant Modeli ng for an iV ector-Based Language Recogni tion System, ” in ICASSP , V ancouv er , Canada, 2013. [28] C. V aquero, A. Orte ga, A. Miguel , and E. Lleida , “ Quality Assessment for Speake r Diari zation and It s Appl ication in Speak er Character ization, ” IEEE T ransacti ons on Audio, Speech, and Langua ge Pr ocessing , vol. 21, no. 4, pp. 816–827, Apr . 2013. [29] D. Castan, A. Orte ga, J. V illalba , A. Miguel, and E. Lleida, “SEGMENT A T ION-BY -CLASSIFICA T ION SYST EM B ASED ON F A CTOR ANAL YSIS, ” in IEEE Internati onal Confer ence on Acoustics, Speec h, and Signal Proce ssing (ICASSP) , 2013. [30] P . Kenn y , “Joint Factor Analysis of Speaker and Session V ariabil- ity : Theory and Algorithms, ” CRIM, Montreal, CRIM-06/08-13, T ech. Rep., 2005. [31] A. Gelman and J. Hill, Data Analysi s Using Re gr ession and Multil evel /Hierar ch ical Model s , ser . Analytic al Meth ods for Social Research. Cambridge Uni versity Press, 2006. [32] D. Tran, R. Ranganath, and D. M. Ble i, “Deep and Hi- erarchi cal Implicit Models, ” Feb . 2017 . [Onl ine]. A va ilable: http:/ /arxi v . org/ abs/1702.08896 [33] Z. Ghahramani and M. J. Be al, “V ariation al Inferen ce for Bayesia n Mixture s of Factor Analysers. ” [34] Z. Ghahramani and G. Hinton, “The EM algorit hm for mixtures of f actor analyzers, ” Dept. of Comp. Sci ., Uni v . of T oronto, T oronto , T ech. Rep. 1, 1996. [Online]. A vaila ble: http:/ /www .learni ng.eng.cam.ac.uk/zoubin/papers/tr - 96- 1.pdf [35] C. M. Bishop, “A New Frame work for Machine Learning, ” pp. 1–24, 2008. [36] M. W ellin g and Y . W . T eh, “Bayesian learning via stochastic gra- dient lange vin dynamics, ” in Proc. ICML , 2011, pp. 681–688. [37] N. Sriv asta va , G. Hinton, A. Krizhe vsky , I. Sutske ver , and R. Salakhu tdinov , “Dropout: A simple way to pre vent neural netw orks from overfit ting, ” Journal of Mac hine Learning Resear ch , vol. 15, pp. 1929–1958, 2014. [38] A. Larcher , K. A. Lee, B. Ma, and H. Li, “T ext-de pendent Speaker V erification : Classifiers, databa ses and RSR2015, ” Speec h Com- municati on , vol . 60, pp. 56–77, 2014. [39] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mizatio n, ” in Pr oc. ICLR , 2014. [40] F . Bastien, P . Lamblin, R. Pascan u, J. Ber gstra, I. J. Goodfello w , A. Berge ron, N. Bouchard, and Y . Bengio, “Theano: ne w features and speed improvement s, ” Deep Learning and Unsupervised Fea- ture L earnin g NIPS 2012 W orkshop, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment